
分支预测 - TAGE 预测器
早期全局预测器(如 GShare)只利用固定长度的历史模式,难以同时捕捉短期与长期相关性。随后出现的 O‑GEHL 用“几何级数”长度表来改善覆盖面,但仍缺少应对历史冲突的机制。而 TAGE 预测器则综合了 O‑GEHL 与 PPM-like 预测器的设计,可以获得更高的准确率与芯片面积效率。现代处理器中使用的分支预测器大多数也是 TAGE 预测器的变体。
TAGE 预测器的结构
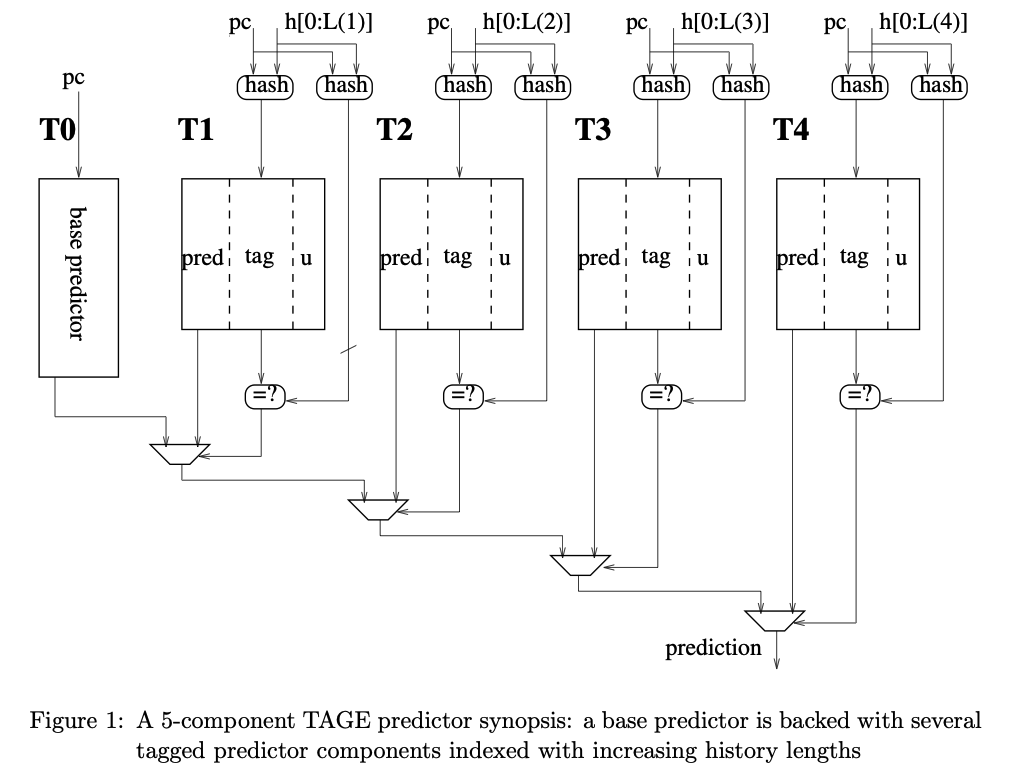
TAGE 预测器的基本结构如下:
- T0 表项:即传统的 PHT,只包含 2-bit 饱和计数器,由 PC 值直接索引;
- T1-T4 表项:不同跳转历史长度对应的 PHT,由 PC 值与全局历史部分异或后进行索引,具体表项包括:
- 1 bit valid 有效位;
- 3 bit pred 饱和计数器;
- 8-12 bit tag 标签,用于判断与当前分支指令是否命中;
- 1 bit usefulness counter 有用计数器,用于提供当前预测的置信度。
TAGE 预测器的预测过程
TAGE 预测器的预测一般在两个流水线阶段中进行:第一级计算 PHT 的索引,第二级读取各个 PHT 表中的结果。
计算索引
对于 T0 表,直接使用 PC 值进行索引。
对于 T1-T4 表,由 PC 的值与 GHR 中存储的全局历史进行哈希后作为索引。在处理器中,GHR 一般存储了较长的全局历史信息,而 PHT 并没有这么多的表项,因此需要对 GHR 中存储的历史信息处理后再进行索引计算,这一过程被称作折叠。根据 TAGE 预测器的设计,不同的表项所需的历史信息长度不同,现在假设 Ti 表所需的历史长度为 n,索引的基本长度为 x,那么历史长度就会被拆分为 ceil(n/x) 个长为 x 的数,这些数与 PC 按位异或就可以作为 PHT 索引。一般而言,Ti 表越大,其用到的历史信息越长。
对比标签
从 SRAM 中读出表项后,首先与 tag 标签进行对比,以判断当前表项是否为当前分支指令的预测内容(减少哈希冲突)。tag 标签的生成与索引生成的过程类似,也是根据不同的表、不同的历史长度、不同的基本长度进行折叠,接着按位异或生成 tag 标签。
查看有用计数器
有用计数器会比较当前的分支预测结果与次一级表项的分支预测结果,如果相同,说明使用更长的分支历史没有必要,因此不增加有用计数器;如果不相同,且当前的预测结果正确,说明使用更长的分支历史是有必要的,因此增加有用计数器的值。一般而言,处理器应该周期性地重置有用计数器的值。
查看饱和计数器
TAGE 预测器中的饱和计数器有 3 位, 111b 状态为预测强跳转、000b 预测为强不跳转,这里不再赘述。
比较不同表项的结果
对于一条分支指令,TAGE 预测器会索引所有表,比较各个表项:
- 并行索引 T0 到 Tn 表,根据命中结果选择预测结果:
- 如果命中到 tag 匹配的 Tn 表,则选择历史最长的 Tn 表,根据其饱和计数器给出预测结果;
- 如果没有命中 Tn 表,则由 T0 表给出预测结果。
- 如果匹配到的 Tn 表为弱预测(
100b与011b),而且 T0 表中的饱和计数器为强预测,则选择 T0 表的预测结果;反之选择 Tn 表的预测结果。
TAGE 预测器的更新过程
这里我们不讨论预测器在流水线的哪个阶段进行更新,因为这与处理器微架构的具体设计相关。现在我们只讨论 TAGE 预测器需要更新的内容与对应的规则。
更新 T0 表项
当 T0 作为最终的预测结果时,按照以下规则更新:如果发生跳转,饱和计数器的值加 1;否则减 1。
当只有 T0 命中时,不更新。
更新 Tn 表项
饱和计数器:如果任何一个 Ti 表命中,其饱和计数器都会更新,规则为:如果发生跳转,饱和计数器的值加 1;否则减 1。
有用计数器:将 Ti 表与上一级表预测结果进行比较,如果都预测正确,则有用计数器不更新;如果 Ti 表预测结果正确、上一级表预测结果错误,则有用计数器加 1。处理器会定时重置有用计数器的值。
分配表项
为了减少单个分支所占用的空间,在错误预测的情况下,最多分配一个带标记的条目。要被分配的条目是通过有用计数器进行管理的,具体规则如下:
- 只在更长历史的 Tn 表中分配表项;
- 最近有用的表项不会被分配;
- 选择有用计数器值最小的表项进行分配。
有以下几种情况需要分配表项:
- 只有 T0 命中,且 T0 预测错误;
- T0 与 Tn 同时命中,T0 与 Tn 的预测结果相同,且预测错误。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号