Dynamic Graph Collaborative Filtering
1 概述
这是一篇发表在ICDM 2020的文章,代码已开源。论文主要研究如何使用动态的图结构表示的协同信息生成用户和物品的向量,然后用于后续的推荐。
文章指出,在真实的推荐场景,用户的兴趣是随时间不断变化的。然而,基于序列的模型无法直接使用用户和物品的系统信息。比如,这些模型主要是在建模物品之间的转移关系,却忽略了用户之间的相似性。基于图的推荐能够很好地建模这类协同信息,但目前的图模型只考虑了静态场景,时间和序列信息没有很好地利用,而且也没有考虑物品的演化关系。
因此,这篇提出在动态图的基础上进行协同推荐。为了在动态图中不断更新用户和物品的向量,文章提出了三种更新策略,获得用户或物品的三类向量:
- zero-order inheritance:合并最新的向量和当前时间步的特征。相当于GCN里面的自循环。
- first-order propagation:使用当前交互对\((u,v)\)计算。为了更新\(u\)的向量,可以对\(v\)求解zero-order信息,然后当做\(u\)的特征。反过来更新\(v\)时也一样。
- second-order aggregation:还是以交互对\((u, v)\)为例,在更新\(u\)的向量时,可以考虑之前与\(v\)交互的用户,这其实就是考虑了用户之间的相似性。反过来更新\(v\)时也一样。
下图是这三种方式的简单图解,其中红色节点表示用户,绿色节点表示物品,中间虚线表示当前正在发生交互。最终用户和物品的向量是这三类向量的聚合:
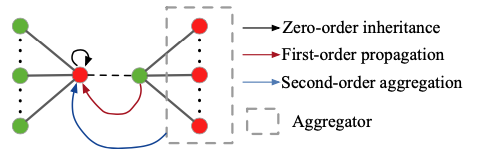
这里还需要解释下什么叫Dynamic Graph。论文提到,一开始Graph的节点都是孤立的,通过读取更多的用户和物品交互对,Graph越来越多边。论文考虑的也是序列推荐问题。
2 方法
文章的方法可以通过下图表示:
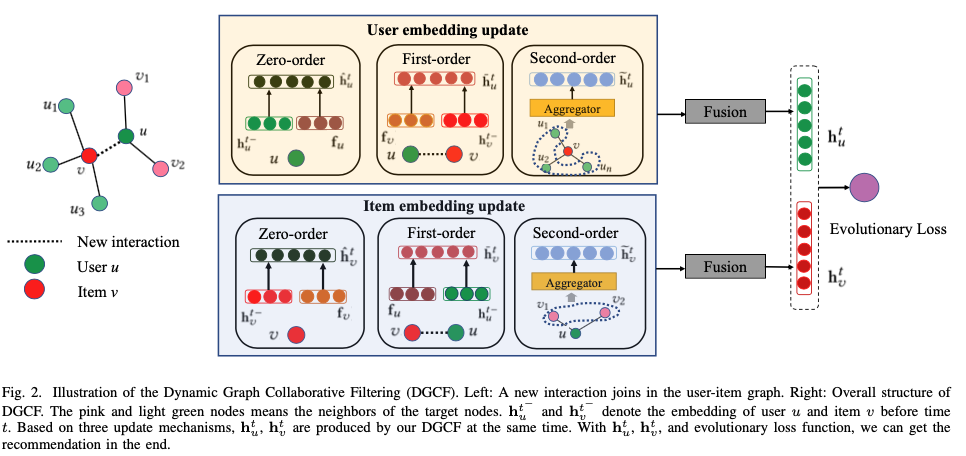
可以看到,整个模型其实分为上下两个部分,分别利用上面提到的三种策略计算用户或者物品在当前时间步的新向量,这三类向量将会被聚合成新的用户或者物品向量。最后,文章使用Evolutionary Loss进行训练。
2.1 向量更新过程
前面提到了文章的三种向量更新策略,下面我们来具体看看。
Zero-order 'inheritance'
这种策略思想其实比较简单,下一个时间步的向量当然要考虑当前时间步的向量。但不同的是,文章还考虑了时间间隔因素,公式如下:
其中\(t^-\)表示上一个时间步,\(\triangle t_u\)表示当前时间步和上一个交互的时间间隔,\(\mathbf{f}\)是特征向量。其它都是参数矩阵或者向量(\(\mathbf{w}_0\))。
First-order 'propagatin'
这类策略也比较直接,我们直接上公式:
Second-order 'aggregation'
这种方式最复杂,通过二阶关系来捕获用户和物品之间的协同关系。它的一般形式可以表示为:
其中,下标带数字的部分就是相应用户和物品节点的二阶特征。\(\zeta_u\)和\(\zeta_v\)是两个不同的聚合函数,这是为了区分两类节点。
为了聚合二阶信息,文章提出了三种方法,分别是
- Mean aggregator:将二阶邻居节点的向量取平均,再与当前向量相加。
- LSTM aggregator:将二阶邻居节点按照时间顺序排列,用LSTM抽取特征,再与当前向量相加。
- Graph Attention aggregator:参照GAT的方式计算二阶邻居节点的attention系数,然后再加权求和。
Fusion Information
用户向量和物品向量的聚合方式是一致的,只是参数不同,方式如下:
其中,\(F_u\)是激活函数,文章里用的是sigmoid。
2.2 损失函数
为了评估模型学出的向量好不好,文章的思路比较奇特。文章假设用户向量在特征空间中是随着时间平稳变化的,因此可以线性地推导出下一时间步的向量,文章称之为估计的未来向量。得到用户向量后,再进一步得到物品向量:
最终,模型的损失函数可以通过均方误差表示:
其中,\(\{S_i\}_{i=0}^I\)是按照时间排序的交互对,\(\lambda_u\)和\(\alpha_v\)是平滑,用于防止用户和物品向量变化太快。
在得到物品特征后,模型将与当前物品\(L_2\)距离最近的\(k\)个物品召回,用于下次推荐。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号