MZNT: Memory Augmented Zero-Shot Fine-grained Named Entity Typing
论文:《MZNT: Memory Augmented Zero-Shot Fine-grained Named Entity Typing》

一、概述
命名实体分类(Named entity typing, NET)旨在推断文本中实体指称的语义类型。比如给定句子"John plays piano on the state"和指称"John",NET需要将"John"识别为pianist、musician或者person类别。随着实体类型越来越多,收集足够的标注数据变得越发困难,由此引发了对Zero-Shot NET的研究热潮。本文所处理的任务就是Zero-Shot细粒度实体分类(ZFNET)。
毫无疑问,对实体指称和实体类型学习更好的表示,对NET任务很重要。之前的方法一般将实体指称和对应的实体类型投影到相同的语义空间,通过最小化它们之间的距离对模型进行学习。在测试时,直接通过距离度量实体指称和实体类型的关联性。但实体指称的类型有部分是可观测到的,有部分是不可见的(即训练数据中不存在这样的指称-类型对),这些方法没有显式建立已观测类型和未观测类型之间的联系。
本文论提出了一个记忆增强的ZFNET框架(MZET)用于解决上述问题,主要的创新点如下:
- MZET能够在不借助额外数据的情况下同时利用实体指称的语义表示和实体类型的结构感知表示。
- MZET将已观测类型看作记忆组件,显式建模已观测类型和未观测类型的关系,以更有效地进行知识迁移。
- MZET在三个基准数据集上的表现超过了现有模型。
二、方法
假设已观测标签集为\(\mathcal{Y}_{seen}=\{y_1^s,y_2^s,\dots,y_{D_s}^s\}\),对于这些标签,存在训练数据\(\mathcal{D}_{tr}=\{(x_i,y_i),i=1,2,\dots,|\mathcal{D}_{tr}|\}\)。其中\(x_i\)是实体指称,\(y_i \in \mathcal{Y}_{seen}\)。同时未观测标签集合为\(\mathcal{Y}_{unseen}=\{y_1^u,y_2^u,\dots,y_{D_u}^u\}\),且\(\mathcal{Y}_{seen} \cap \mathcal{Y}_{unseen}=\emptyset\)。ZFNET的目标就是对属于未观测类型的实体指称进行分类。
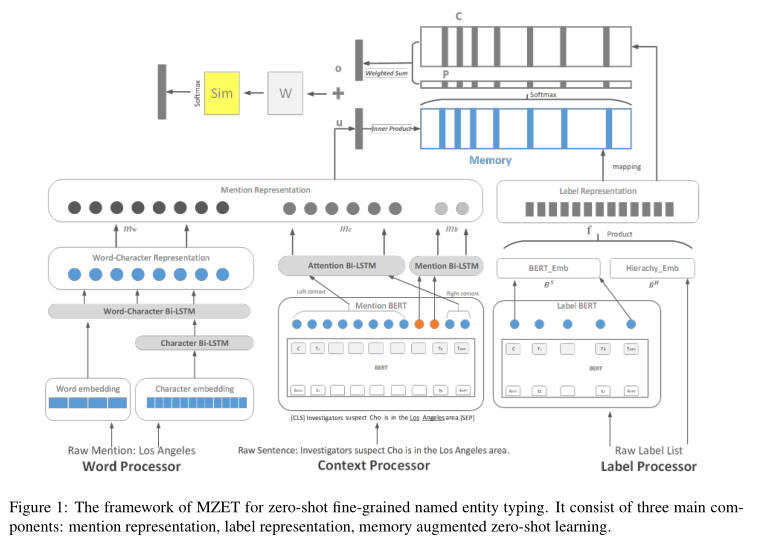
上图表示本论文的模型架构,模型主要分为三个部分:1)Mention Processor;2)Label Processor;3)Zero-Shot Memory Network。
1 Mention Processor
为了更好地理解实体指称,论文同时考虑了指称中的单词还有指称的上下文。
Word Processor
Word Processer的作用就是学习实体指称的表示,首先,它将每个单词表示为词向量和字符向量的连接:
字符向量\(c_k\)是通过字符级别Bi-LSTM获得的。得到\(K\)个词的向量后,论文又增加了一层Bi-LSTM学习实体指称的的向量:
Context Processor
为了捕获实体指称的上下文,这部分又生成了两个指称表示:\(m_b\)和\(m_c\)。
论文首先通过BERT对句子编码,获得每个单词的向量。然后取出实体指称对应的向量序列\(b_1,b_2,\dots,b_K\),用Bi-LSTM将其编码为\(m_b\)。然后论文将实体指称左右各10个单词看作指称的上下文,并利用带注意力机制的Bi-LSTM对其进行编码,获得表示\(m_c\)。
Mention Representation
最终,实体指称的表示是上述多个表示的拼接:
2 Label Processor
论文首先基于BERT模型对所有的已观测和未观测类型标签进行编码,将每个标签编码为维度为\(D_b\)的向量,得到嵌入矩阵\(B_S \in \mathbb{R}^{(D_s+D_u) \times D_b}\)。
为了捕获类型之间的层次结构,论文使用了一个稀疏矩阵\(B^H \in \mathbb{R}^{(D_s+D_u) \times (D_s+D_u)}\)对标签之间的关系进行编码。其中,\(B^H_{ij}\)表示类型\(i\)与类型\(j\)的关系,取值如下:
最终,类型标签\(y_i\)的向量可以表示为:
3 Zero-Shot Memory Network
论文将Memory Network看作特殊的注意力机制,进而建模实体指称和已观测实体类型之间的关系。具体来说,论文首先将已观测标签的向量表示\(F=(f_1^s,\dots,f_{D_s}^s) \in \mathbb{R}^{D_s \times D_b}\)进行投影操作得到输入记忆表示\(G \in \mathbb{R}^{D_s \times D_m}\)。也就是将每个已观测标签投影成维度为\(D_m\)的向量,用作记忆。然后,实体指称\(m\)和记忆\(g_i\)的注意力被定义为:
\(F\)还将进行另一个投影操作运算得到输出记忆表示\(O \in \mathbb{R}^{D_s \times D_m}\)。那么实体指称\(m\)的加权标签表示为:
为了进行Zero-Shot学习,论文引入标签表示之间的相似度用于知识迁移,未观测标签\(f_i\)和已观测标签\(f_j\)的相似度可以表示为:
其中\(d\)是欧几里得距离。最终得到相似度矩阵\(R \in \mathbb{R}^{D_u \times D_s}\)。
给定实体指称表示\(m\)时,它的实体类型分类结果可以定义如下:
其中\(W_p\)是参数。
4 损失函数
给定实体指称\(x\),\(Y\)是\(x\)对应的正确类型集合,\(y_{pos}\)是为\(x\)分配正确标签的概率。\(\bar{Y}\)是错误标签集合,\(y_{neg}\)是为\(x\)分配错误标签的概率。
三、实验
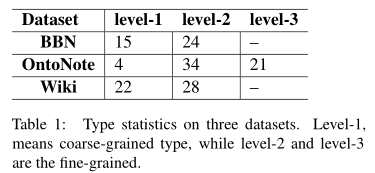
本文使用三个常用的细粒度实体分类数据集进行实验:BBN、OntoNote和Wiki。数据集的情况如下:
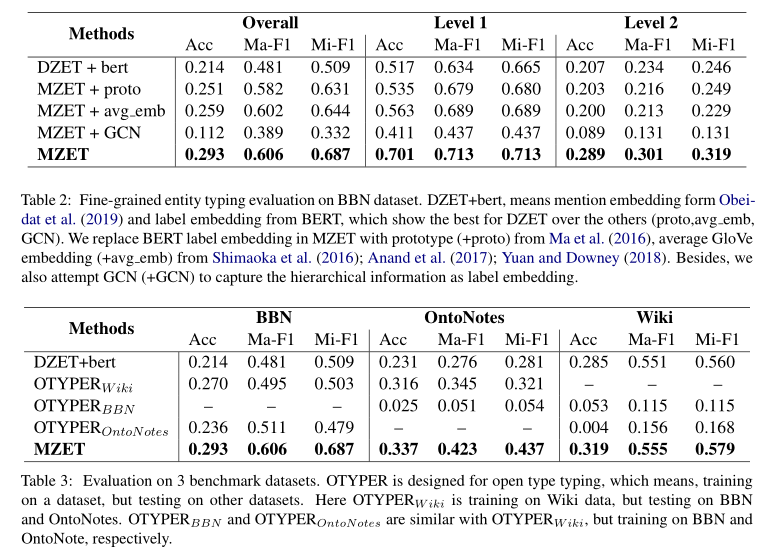
模型的评价指标包括strict accuracy(Acc.)、Marco-F1、Micro-F1。主要实验结果如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号