Adversarial Multi-Binary Neural Network for Multi-class Classification
论文信息:论文
概述
多类别分类要为每个样本分配一个标签,其中标签类别多于两个。比如对于一条微博,如果要对其主题分类,类别标签可能有娱乐、体育、军事、教育等。
现有的文本分类方法主要使用神经网络。一般在最后一层使用Softmax计算文本属于每个类别的概率。但是这种方法独立地考虑每个类别,忽略了类别之间的关联,认为原始输入特征对每个类别的贡献是相等的。
有些方法使用one-vs-rest(OVR)方式进行多标签分类。也就是说,对于每个类,都有一个二元分类器用于判断样本属于该类还是不属于该类。这种方式受启发于多任务学习,企图通过联合学习多个分类器以捕获多个任务之间的关联。多任务学习从不同方面学习特征,同时对模型进行潜在的正则化,使得模型效果更好。
本论文也是用OVR的方式进行多类别分类,但将每个OVR二元分类器当作一个单独的任务,所有的OVR二元分类器和原始的多类别分类组成多任务学习。作者认为输入特征既包含了共享的类别无关(class-agnostic)信息和类别特定(class-specific)的信息。前者对于分类用处不大,后者包含了用于分类的有用信息,他们希望把这两部分特征分开,也就是剔除掉类别无关的那部分信息。
为了让模型对特征进行划分,该论文还提出了对抗训练策略。具体地,每个OVR二元分类器都有一个类别特定的特征编码器,另外还有一个共享的特征编码器用于生成输入判别器的类别无关特征。判别器的目标是判断特征来自哪个类别,而生成器的目标是生成类别无关特征并欺骗判别器。这种方式对于其他多分类任务也是适用的。
方法
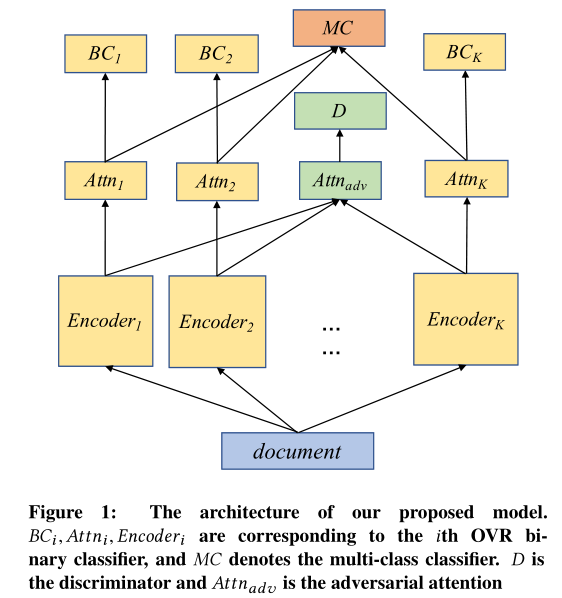
下面这个图是模型的主要结构
问题定义
每篇文档\(d_i \in D\)由一系列句子\(<s_1,s_2,\dots>\)组成,每个句子由一系列单词组成。给定一个文档集\(D\),文档\(K\)分类任务就是学习文档到标签的映射\(f:D\rightarrow \{l_1,\dots,l_K\}\)。论文将该多分类任务基于OVR方式拆分为\(K\)个二分类任务,每个二元分类器表示为\(f_k:D \rightarrow \{l_k,-l_k\}\),其中\(-l_k\)表示文档不属于第\(k\)类。
模型
二元分类
如上图所示,论文为每个OVR二分类任务都设置了一个编码器Encoder,编码器之上是注意力层。这两部分是直接通过层次注意力网络HAN(Yang, Zichao, et al., 2016)实现的。每个Attn注意力层的输出再输入到全连接层进行二分类。具体来说,对于文档\(d\)和类别\(k\),论文使用HAN计算类别特定特征\(a_k\)以用于二元分类:
其中,\(\text{Encoder}_k\)和\(\text{Attn}_k\)是第\(k\)个编码器和注意力层,参数分别是\(\theta_{e_k}\)和\(\theta_{a_k}\),它们将文档\(d\)转换为向量\(a_k\)。\(w_k^T\)和\({w^{'}}_k^T\)是全连接层的权重向量。二元分类的损失函数可以表示为负对数似然:
标准多类别分类
另外,\(K\)组特征\(a_1,a_2,\cdots,a_K\)还被用于标准多类别分类:
也就是直接使用Softmax进行多分类,此时多分类的损失函数为:
对抗训练
为了区分类别特定特征和类别无关特征,论文还使用了对抗训练策略。模型图中\(Attn_{adv}\)是生成器,\(D\)是判别器。\(Attn_{adv}\)将\(K\)个Encoder的输出作为输入,然后生成对应的\(K\)个对抗实例。判别器的目标就是判断生成器生成的对抗实例来自哪个Encoder。论文认为为了欺骗判别器,生成器\(Attn_{adv}\)能够学会提取类别无关特征。对抗训练的过程可以表示如下:
其中\(a_{adv}(k)\)就是生成器为第\(k\)个类别生成的对抗实例,\(z_k^j \in \{0,1\}\)指示该示例是否属于第\(k\)类,\(v_i\)是判别器的参数,\(\lambda\)是超参。\(P_D(j|k)\)是判别器分类过程,\(L_{adv}\)是对抗学习损失。
此时模型能够学会分开抽取类别无关特征和类别特定特征,也就是\(\text{Attn}_k\)能够输出特定于第\(k\)类的信息,\(\text{Attn}_{adv}\)则输出类别无关特征,此时就把类别无关的那部分特征给剔除了。同时,为了避免类别特定特征包含类别无关特征,论文还对这两个特征进行了正交约束。在预测阶段,只有类别特定特征会被用于分类。
损失函数
类别特定特征和类别无关特征的正交约束损失可以表示为:
模型最终的损失函数就是四种损失的线性组合:
其中,\(\alpha,\beta,\gamma,\delta\)都是超参数。
实验
该论文使用了两个大规模文本分类数据集,数据集的情况如下:

实验结果如下图所示:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号