Adversarial Learning with Contextual Embeddings for Zero-resource Cross-lingual Classification and NER
论文信息:论文,EMNLP2019
概述
上下文感知词嵌入已经被成功应用于命名实体识别、文档分类等NLP任务。其中多语言版BERT也基于XNLI数据集(Conneau et al., 2018)在“zero-shot”或者“zero-resource”的跨语言分类任务中展示了强大能力。这里所说的“zero-resource”意味着模型训练时只能使用英文语料的标注数据,训练完的模型要应用于其它语言,因此训练时完全未使用目标语言资源。
本论文目的是探索BERT的“zero-resource”迁移学习能力能否应用于其它多语言数据,该论文的主要贡献如下:
- 提出了在微调多语言版BERT时加入“语言对抗”任务,该任务能够提高“zero-resource”跨语言的迁移学习能力
- 表明了对于MLDoc文档分类和CoNLL实体识别任务,即使没有对抗训练,多语言版BERT都比之前的方法好
- 证明了对抗技术使得BERT将英文文档和其翻译对齐,就是这种对齐改进了“zero-resource”性能
方法
该论文模型架构如下图所示:
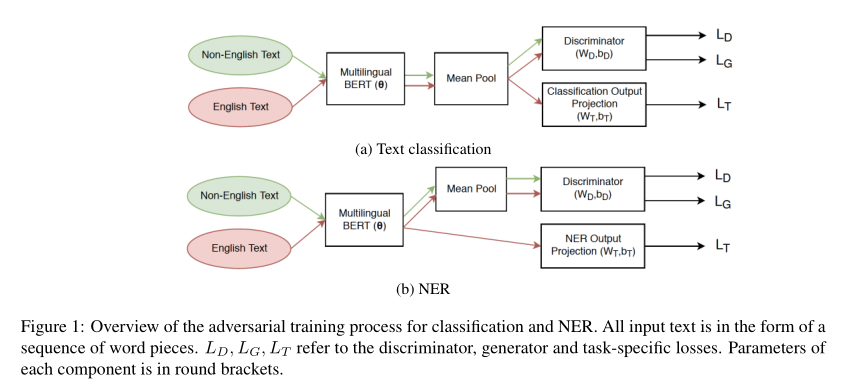
该方法将对抗任务看作是二元分类任务,即判断样本是英语还是非英语。为了实现这一点,论文额外添加了判别器和生成器,判别器基于BERT隐向量进行二元分类,而生成器让BERT趋向于生成难以判别的隐向量,以达到让BERT生成不包含特定语言信息的隐向量。算法的伪代码如下。

对于文档分类任务,模型的损失有三项:任务相关损失\(L_T\),生成器损失\(L_G\)和判别器损失\(L_D\)。任务相关损失使用交叉熵表示:
其中\(\bar{h}_{\theta}(x)\)是BERT输出的隐向量,\(p(Y|x)\)是\(x\)标签为\(Y\)的概率,\(y_i \in \mathbb{R}^{K \times 1}\)是标签one-hot向量,\(K\)是标签总数。
生成器和判别器损失函数为:
其中\(y^A \in \{0,1\}\)表示样本是否为英文,\(p(E=1|x)\)表示样本是英文的概率。
对于实体识别任务,任务相关损失函数是序列标注形式:
其中\(t\)表示当前处理的是文本中的第\(t\)个单词。
模型总的参数由三部分:判别器参数\(\theta_D=\{W_D,b_D\}\),任务参数\(\theta_T=\{\theta,W_T,b_T\}\),生成器参数\(\theta_G=\{\theta\}\)。在实验中论文依次更新这些参数,更新比例为1:1:1。
实验
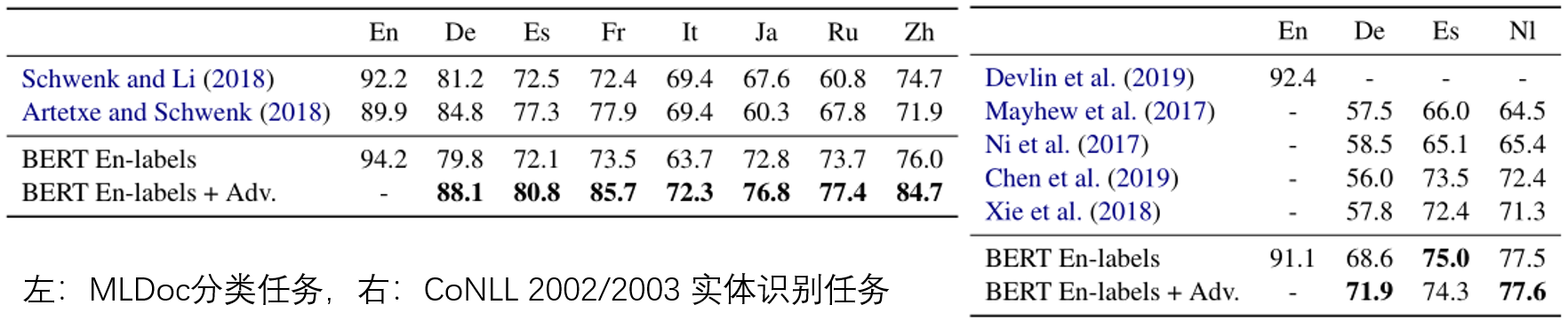
该论文在MLDoc分类任务和CoNLL 2002/2003实体识别任务上进行了实验,下面是实验结果。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号