
Making a Faster Cryptanalytic Time-Memory Trade-Off(未完待续)
摘要
1980年Martin Hellman描述一种通过使用预计算数据的时间空间的折中算法。这种技术被Rivest在1982年提升了,
极大的减少了密码分析过程中的查找次数。这个技术被广泛的研究,但是这之后就没有更多的提升了。
下面我们介绍一种新的预计算技术,可以将计算的数量减少一半。
由于这种模式不使用distinguished points,
它减少了可变chain带来的开销,这能有效的减少计算的数量。
例如:我们已经使用这种方式来攻击MS-Windows的password的hash,
使用1.4GB的数据能实现在13.6秒内99.9%的攻破所有字母数字的hash(2^37)
如果使用当前主流的distinguished points.将需要101秒。
We show that the gain could be even much higher depending on the parameters used.
关键字
time-memory trade-off, cryptanalysis, precomputation, fixed plaintext
1.介绍
基于全面搜索的Cryptanalytic攻击完成需要许多计算或时间,
当类似的攻击需要进行很多次时,那么就可能可以通过预计算和在内存中存储进行优化
一旦预计算完成,攻击将瞬间可以得到结果。
但是这种方式是不可行的,因为需要巨大的存储。
Hellman介绍了一种内存和攻击时间交换的方法。
对于一个有N个key的加密系统,这种方式能够恢复一个key,使用N^2/3次运算和N^2/3字的内存
这种模式被用在明文和密文已知的情况下。
一种典型的情况是攻击者能够猜出开始的几个字节的数据(例如:#include <stdio.h>)
其他的领域例如密码hash。
很多的系统都是将明文密码作为key,然后存储该key加密的数据生产的hash。
如果hash设计不够好,所有的结果的明文和加密方式都是相同的。
这样就可以对密码进行预计算,使用Time-Memory Trade-Off。
1.1 原始方法
给定一个固定的明文P0和相应的密文C0,
这种模式将找出k属于N,k被用于加密明文使用加密函数S,公式如下:
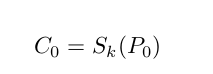
我们尝试去计算所有可能的密文。这些密文存储在一条链上,这条链只有第一个和最后一个节点的数据。
这种方式叫做 Trade-Off,这条链通过R函数构造(从密文创建一个key)。
密文比key长,所以需要裁剪。这样就可以形成一条链。例如:
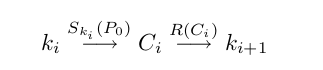
m条长度为t的链被存储在表里。
给定一个密文C,我们就能尝试去找出它是否在表中。
我们一直计算C,直到t次。
如果C计算的结果能匹配表中的数据,我们就能找到key了。
不幸的是,这些链可能会冲突和合并。
这是因为函数R是将密文空间任意缩减为密钥空间的结果
越大的表合并的可能性越大。
每一次合并都减少
Each merge reduces the number of distinct keys which are actually covered by a table.
The chance of finding a key by using a table of m rows of t keys is given in the
original paper [4] and is the following
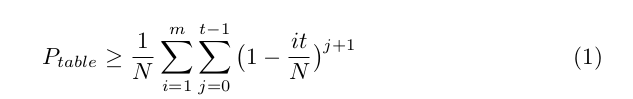
上面是单表的情况,为了更高的成功率,一般会使用不同的reduction函数。可能的成功率如下:
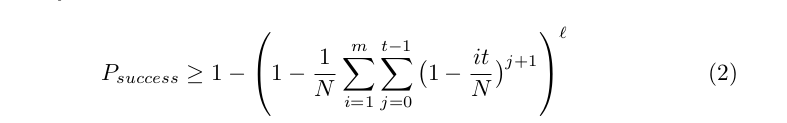
不同的链表也会冲突,但是不会合并。
失败警告
当在一个表里面找key的时候,匹配到最后一个节点不能说明key一定在这个表里。
通常,这个key只是可能在表里。
这种情况下这个key就是被合并到其他链条去了。
只能继续往下找,直到找到正确的key。
1.2 现有的工作
在文献2中,Rivest建议使用distinguished points作为链条的终止节点。
distinguished points有一些简单的判断标准(例如key的前面10个字节是0)
所有的distinguished points都存储在内存里。
当给一个ciphertext,我们能一直计算直到找到distinguished points生成一个链条。
这能大量的减少需要存储的数据量。
文献6描述了如何去优化参数t,m和l去实现最优的结果。
文献5描述了如何调整参数能够在不增加存储和计算时间的前提下增加成功的概率。
这些方法确实实现了预计算时间和成功率的折中。然而,这个成功率并不能无限的增加。
在文献1中,Borst提出,distinguished points有以下两条规则:
- 实现循环检测。如果超过一定的阀值还没有发现distinguished points(超过平均时间几倍),这个链条能够停止然后移除。这保证所有的链条都是没有循环的。
- 如果两条链条有相同的结束节点应该很容易被检测到。(the next distinguished point after the merge)由于端点必须进行排序,因此合并是在没有额外成本的情况下发现的。文献1指出,很容易生成无冲突表,而不会产生很大的开销。生成无合并表是另一个权衡,即以额外的预计算为代价减少内存。
最后,文献7指出,前面提到的所有计算都基于Hellman的最初模式,distinguished points的不同导致节点长度的不同和结果的不同。他们提供了一个详细的分析,并在专门构建的FPGA中进行了仿真。
文献3描述了一种Fiat和Noar创造的Hellman Trade-Off的变体。虽然这个Trade-Off是低效率的,但是它提供了这个反转函数的证明。
2 原始方法的结果
2.1 边界和参数
论文下载
http://www.enseignement.polytechnique.fr/profs/informatique/Francois.Morain/Master1/Crypto/projects/Oechslin03.pdf
reduction


 浙公网安备 33010602011771号
浙公网安备 33010602011771号