
使用requests简单的页面爬取
首先安装requests库和准备User Agent
安装requests直接使用pip安装即可
pip install requests
准备User Agent,直接在百度搜索"UA查询",随便找一个即可.
1.进行信息爬取
以爬取政府网站信息为例
############################# 简单的页面爬取 #######################################
# Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0
#导入requests库
import requests
#指定我们的UserAgent
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'
headers = {'User-Agent':user_agent}
#requests库用来发送请求的语句是requests.get
r = requests.get("http://www.gov.cn/zhengce/2019-05/09/content_5390046.htm",headers = headers)
#打印结果
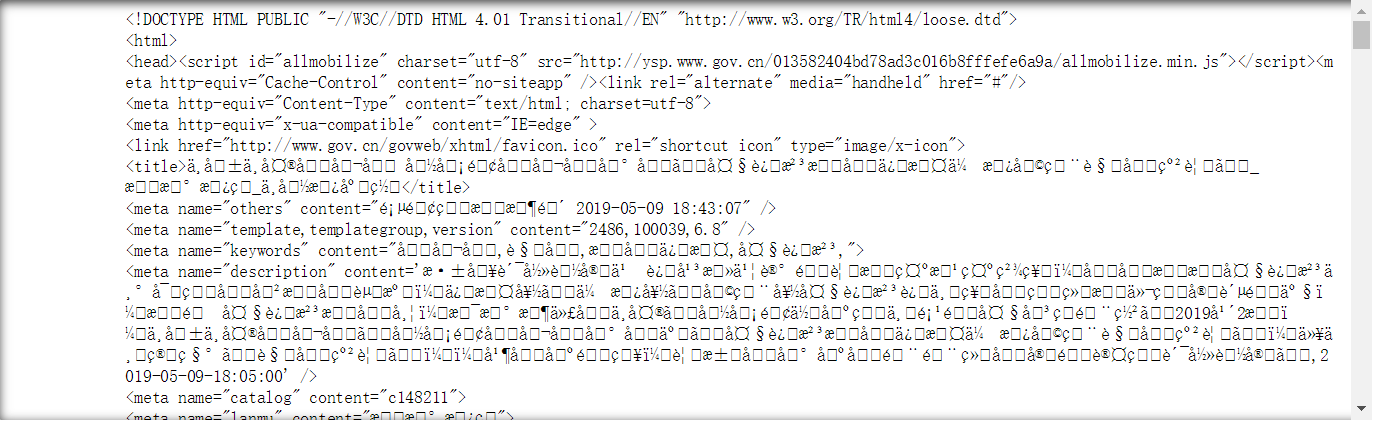
print(r.text)
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#使用.encoding查询编码方式
print('编码方式:',r.encoding)
print('\n====================================')
print('\n\n\n')
代码运行结果: ==================================== 编码方式: ISO-8859-1 ====================================
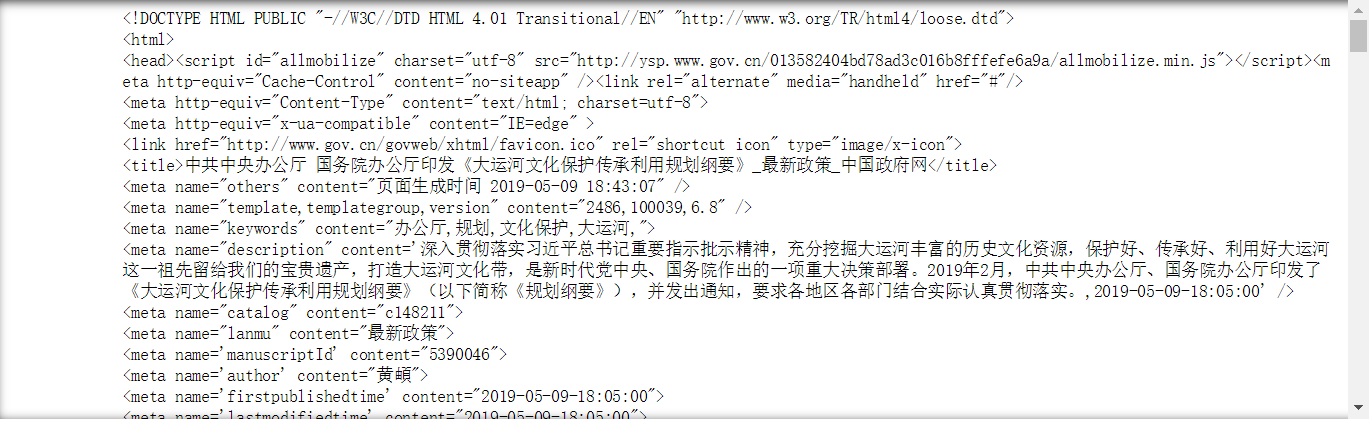
#修改encoding为utf-8 r.encoding = 'utf-8' #重新打印结果 print(r.text)
#保存指定html文件的路径,文件名和编码方式
with open ('d:/jupyternotebook/requests.html','w',encoding = 'utf8') as f :
#将文本写入
f.write(r.text)
'''
'\d+'前面的"r"意思是不要对"\"进行转义-------在pyton中,"\"表示转义符,如我们常用的"\n"就表示换行.
如果不希望python对'\'进行转义,有两种方法,一是在转义符前面再增加一个斜杠'\',如:'\\n',那么python就不会对字符进行转义,
另一种方法就是在前面添加'r',如本例中的"r'\d+"
'''
#导入re模块
import re
#指定匹配模式为从开始位置匹配数字
pattern = re.compile(r'\d+')
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#第一句话前面是文本,后面是数字
result1 = re.match(pattern,'你说什么都是对的456')
#如果匹配成功,打印匹配的内容
if result1:
print(result1.group())
#否则打印"匹配失败"
else:
print('匹配失败')
#第二句话前面是数字,后面是文本
result2 = re.match(pattern,"465你说什么都是对的---")
#如果匹配成功,打印匹配的内容
if result2:
print(result2.group())
#否则打印"匹配失败"
else:
print('匹配失败')
print('\n====================================')
print('\n\n\n')
代码运行结果: ==================================== 匹配失败 465 ====================================
#用.search()来进行搜索
result3 = re.search(pattern,'你说什么456都是对的')
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#如果匹配成功,打印结果,否则打印'匹配失败'
if result3:
print(result3.group())
#否则打印"匹配失败"
else:
print('匹配失败')
print('\n====================================')
print('\n\n\n')
代码运行结果: ==================================== 456 ====================================
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#使用.split()把数字之间的文本拆分出来
print(re.split(pattern,'你说什么56565都是对的79879879啊哈'))
print('\n====================================')
print('\n\n\n')
代码运行结果: ==================================== ['你说什么', '都是对的', '啊哈'] ====================================
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#使用.findall()把数字之间的文本拆分出来
print(re.findall(pattern,'你说什么56565都是对的79879879啊哈'))
print('\n====================================')
print('\n\n\n')
代码运行结果: ==================================== ['56565', '79879879'] ====================================
#导入BeautifulSoup from bs4 import BeautifulSoup #创建一个名为soup的对象 soup = BeautifulSoup(r.text,'lxml',from_encoding='utf8') print(soup)

print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#使用.'标签名'即可提取这部分内容
print(soup.title)
print('\n====================================')
print('\n\n\n')
代码运行结果: ==================================== <title>中共中央办公厅 国务院办公厅印发《大运河文化保护传承利用规划纲要》_最新政策_中国政府网</title> ====================================
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#使用.string即可提取这部分内容中的文本数据
print(soup.title.string)
print('\n====================================')
print('\n\n\n')
代码运行结果: ==================================== 中共中央办公厅 国务院办公厅印发《大运河文化保护传承利用规划纲要》_最新政策_中国政府网 ====================================
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#使用.get_text()也可以提取这部分内容中的文本数据
print(soup.title.get_text())
print('\n====================================')
print('\n\n\n')
代码运行结果: ==================================== 中共中央办公厅 国务院办公厅印发《大运河文化保护传承利用规划纲要》_最新政策_中国政府网 ====================================
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#打印标签<p>中的内容
print(soup.p.string)
print('\n====================================')
print('\n\n\n')

#使用find_all找到所有的<p>标签中的内容
texts = soup.find_all('p')
#使用for循环来打印所有的内容
for text in texts:
print(text.string)

#找到倒数第一个<a>标签
link = soup.find_all('a')[-1]
print('\n\n\n')
print('BeautifulSoup提取的连接:')
print('====================================\n')
print(link.get('href'))
print('\n====================================')
print('\n\n\n')
BeautifulSoup提取的连接: ==================================== None ====================================
2.对目标页面进行爬取并保存到本地
############################# 简单的页面爬取,并保存为excel文件实例 #######################################
# Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0
#导入requests库
import requests
#导入CSV库便于我们把爬取的内容保存为CSV文件
import csv
#导入BeautifulSoup
from bs4 import BeautifulSoup
#导入正则表达式re库
import re
#定义爬虫的User Agent
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'
headers = {'User-Agent':user_agent}
#使用requests发送请求
policies = requests.get('http://www.gov.cn/zhengce/zuixin.htm',headers = headers)
#指定编码为"utf-8"
policies.encoding = 'utf-8'
#创建BeatifulSoup对象
p = BeautifulSoup(policies.text,'lxml')
#用正则表达式匹配所有包含"content"单词的链接
contents = p.find_all(href = re.compile('content'))
#定义一个空列表
rows = []
#设计一个for循环,将每个数据中的链接和文本进行提取
for content in contents:
href = content.get('href')
row = ('国务院',content.string,href)
#将提取的内容添加到前面定义的空列表中
rows.append(row)
#定义CSV的文件头
header = ['发文部门','标题','链接']
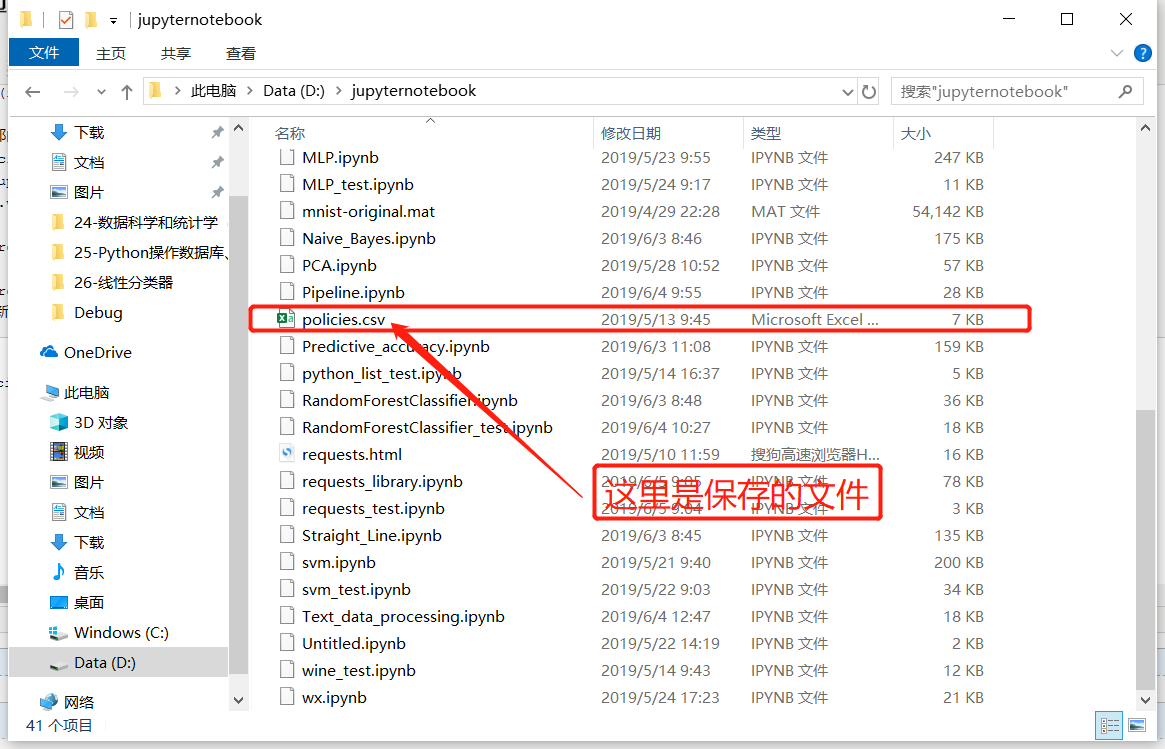
#建立一个名叫policies.csv的文件,以写入模式打开,记得设置编码为gb18030,否则会乱码
with open('d:/jupyternotebook/policies.csv','w',encoding='gb18030') as f:
f_csv = csv.writer(f)
#写入文件头
f_csv.writerow(header)
#写入列表
f_csv.writerows(rows)
print('\n\n\n最新信息获取完成\n结果保存在D盘policies.csv文件\n\n\n')
最新信息获取完成 结果保存在D盘policies.csv文件

总结 :
这里是简单的对网页进行爬取,如果想进行复杂的爬取,可以深入了解Scrapy,其目前是最常用的python开发爬虫的工具之一.
文章引自 : 《深入浅出python机器学习》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号