InternVL3: Advancing Open-Source Multimodal Models with Native Multimodal Pretraining
InternVL3 是一款原生多模态预训练的大模型系列,在图文理解、工具使用、视频分析等方面实现全面升级,模型规模覆盖 1B–78B,全线在开源模型中表现优异。
概述
InternVL3 是 OpenGVLab 团队推出的第三代多模态大模型,继承并全面超越 InternVL2.5。
它采用 原生多模态预训练(Native Multimodal Pretraining) 方法,在语义理解、视觉感知、工具使用、GUI 操作、3D 场景等多模态任务上表现出色。
相较前代,InternVL3 带来 3 项关键突破:
- 训练范式升级:统一语言+多模态联合预训练
- 推理能力增强:引入 VisualPRM 作为 Test-Time Critic
- 模型体系完备:从轻量 1B 到旗舰 78B 全覆盖
动机与方法
多模态模型的核心挑战
- 多数模型采用“先训语言、后接图像”的拼接式训练范式,导致模态间适配效率低
- 缺少兼顾语言精度与多模态理解的模型训练策略
- 推理过程中缺少高质量反馈机制,影响复杂任务表现
InternVL3 的设计理念
- Native Multimodal Pretraining:预训练阶段同时学习语言与多模态对齐
- Variable Visual Position Encoding(V2PE):灵活视觉位置编码,提升长上下文建模能力
- Mixed Preference Optimization(MPO):加入偏好学习,增强推理稳定性与准确率
- Test-Time Scaling with VisualPRM:推理时引入 VisualPRM 选择最佳结果(Best-of-N 策略)
架构与训练细节
模型架构
- 结构:ViT + MLP + LLM 三段式设计(类似前代,但细节进化)
- 图像编码:动态分辨率策略(最多支持 128 tiles 的 448×448 图像)
- 支持多图、视频、多轮图文对话、3D 场景、GUI 操作等输入
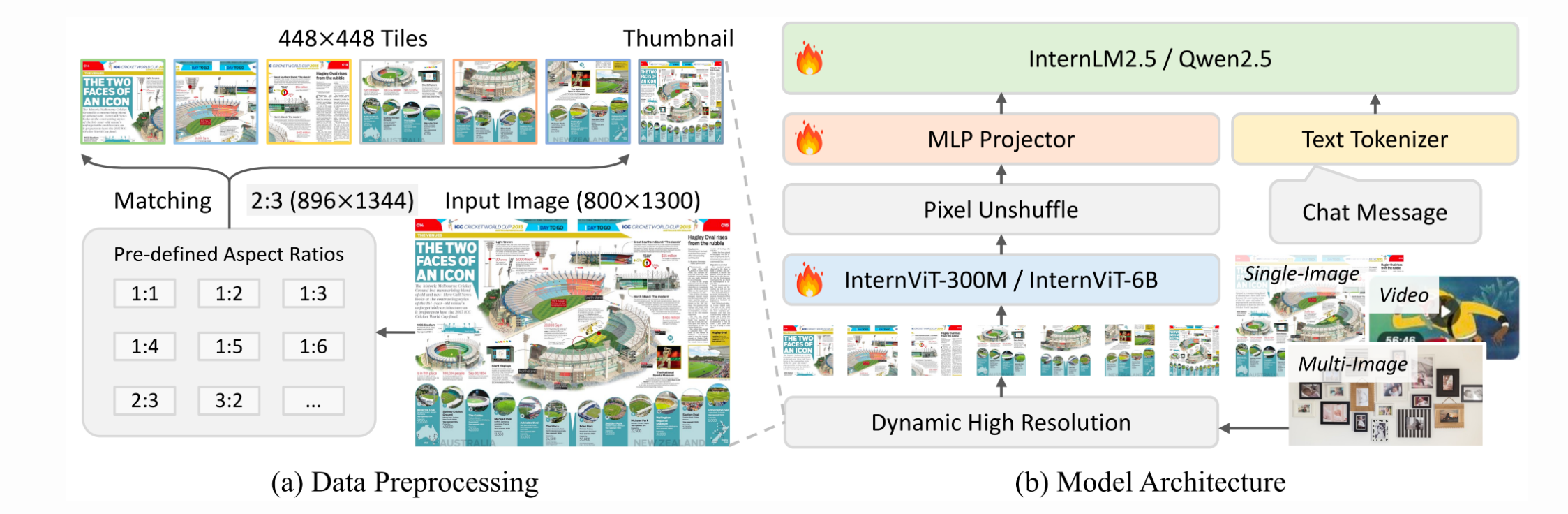
原生多模态预训练
与传统“语言优先”不同,InternVL3 将图文数据、视频文本、文本语料混合交替训练,统一优化。
- 训练数据包括 InternVL2.5 所有数据 + 新增真实任务数据(工具使用、3D、GUI、科学图表等)
- 同时更新 ViT、MLP、LLM 三大模块权重
微调策略(SFT & MPO)
- SFT 数据量:训练样本由 1.6 亿增至 2.17 亿,覆盖更多多模态任务场景
- MPO 阶段:采用 30 万个偏好对进行训练,对抗生成偏差,提升 Chain-of-Thought 推理表现
实验结果亮点
多模态推理与数学能力
结论:InternVL3 + VisualPRM 在多个benchmark上超越 GPT-4o
文档/OCR/图表理解能力
- 在 DocVQA、ChartQA、TextVQA、InfoVQA 等任务上全面领先开源模型
- InternVL3-78B 在 OCRBench 和 SEED-2+ 上达开源最佳表现
多图/视频理解与 GUI 操作
- 视频多模态理解(Video-MME、LongVideoBench)得分领先,超越 GPT-4V/Gemini
- GUI 基准 ScreenSpot-V2 上 InternVL3-38B 得分 88.3,逼近闭源水平
多语言/多模态能力
InternVL3 支持英语、中文、葡语、阿语、俄语等多语言输入,在多语言图文问答中表现突出
例如:
- InternVL3-8B 在 MTVQA 多语种测试中 Overall 达 64.7
- 超越 GPT-4V 与多个 Qwen 同规模模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号