

20242402 2024-2025-2 《Python程序设计》实验四报告
20242402 2024-2025-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级:2424
姓名:张宇涵
学号:20242402
实验教师:王志强
实验日期:2025年5月1日
必修/选修: 公选课
一.选题
- 在大一加入团学的时候,第一件事便是“学习公文格式”。公文格式说简单也简单,不就是对字体字号改改就行嘛,但是深究起来还是大有乾坤的——对于各级标题,正文,表格,落款,页脚页眉每一项都有明确的要求。慢慢改的多了,也就摸透了它的一些规律。既然有规律,可重复,为何不用python直接解放双手呢?于是就有了下面这整个实验。
二.实验目的
1.进一步学习python的操作,如对第三方库的使用(如jieba,python-docx,openai,tkinter),对于文件的编辑,对图形化界面的构建。
2.我希望这个程序能发挥它的作用,在实际的团学工作中减轻大家的工作负担,把更多的精力放到富有创造性的内容上。
2. 实验分析与过程
1.我将我的计划分成以下几个部分:
-
将word文件读入程序,对于它的各级标题,正文,表格,落款,页脚页眉,页边距等方面按照公文格式要求进行逐项修改。最后输出为完整的文件。
-
接入deepseek的api,将文章内容喂给deepseek,让其对内容,语病等方面进行分析,最后输出润色修改建议,建议可保存为md文件。
-
程序可查看处理文件的历史纪录,对于设置的deepseek api和模型能保存下来。
2.我的实验过程如下:
- 首先,我对于这个想法具体如何实现询问了deepseek:
现在我要做一个python的大实验,就是完整的做一个项目,我现在想到一个好点子,就是一个公文格式一键修改器,就传入一个word文档,把他的页边距,行距,字体,字号,进行修改,增加页码,首行缩进,识别大标题,小标题,换成不同的字体字号等对word文档的修改工作,如果可以的话,我还想实现接入ai来实现错别字的查找,请问我这个方案可以实现吗,源代码的编写,封装和图形化界面设计流程是啥样子的?谢谢。
它给了我一个框架:
| 功能模块 | 推荐工具/库 | 说明 |
|---|---|---|
| Word文档处理 | python-docx |
读写Word文档的核心库,支持格式修改、段落操作等 |
| AI错别字检查 | 百度AI开放平台(文本纠错API) | 免费且准确率较高,需申请API Key |
| 图形界面(GUI) | PyQt5 或 Tkinter |
PyQt5功能强大但稍复杂,Tkinter更简单(根据你的需求选择) |
| 程序封装 | PyInstaller |
将Python代码打包为exe文件,方便无环境用户使用 |
-
然后我向他询问了python-docx的基本操作,同时也翻阅了他的官方文档。
-
接着我安装好了所有的第三方库:jieba(用于分词,对标题过长时截断点的选择有帮助)python-docx(操作docx文件的库),openai(用于接入deepseek),tkinter(进行图形化处理)
-
接着开始漫长的写代码,调试,改bug的无限循环……
-
最后打包封装为可执行文件
3.对于我的代码分析
(1)图形化设计涉及setup_ui``add_history_record``create_main_frame等一系列函数,最后程序有了背景图,左侧有“主程序”“历史记录”“设置”三个状态栏。
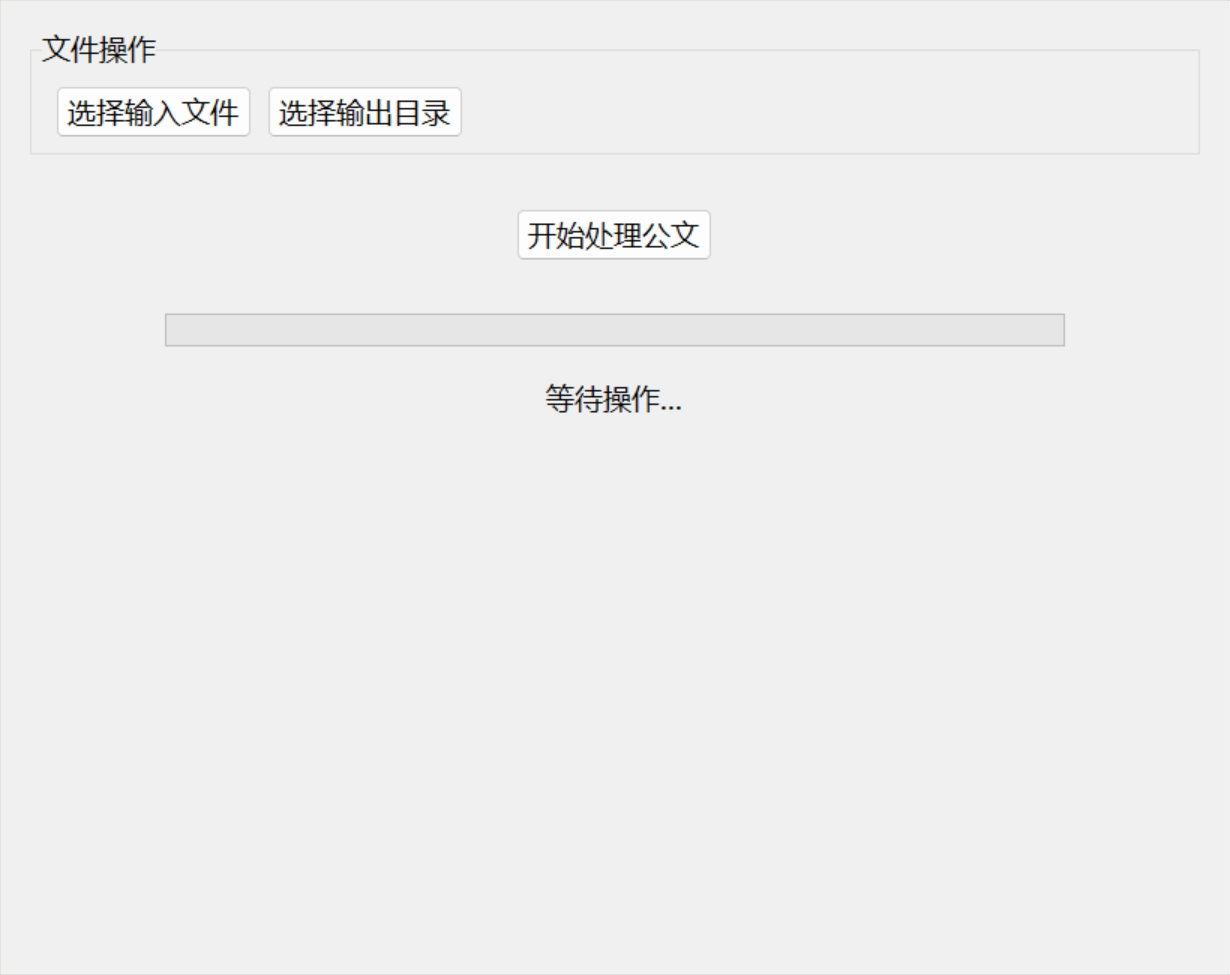
1.主程序界面中,有选择输入文件``选择输出目录``开始处理公文的按钮,下方还有进度条,显示文件修改的进度。
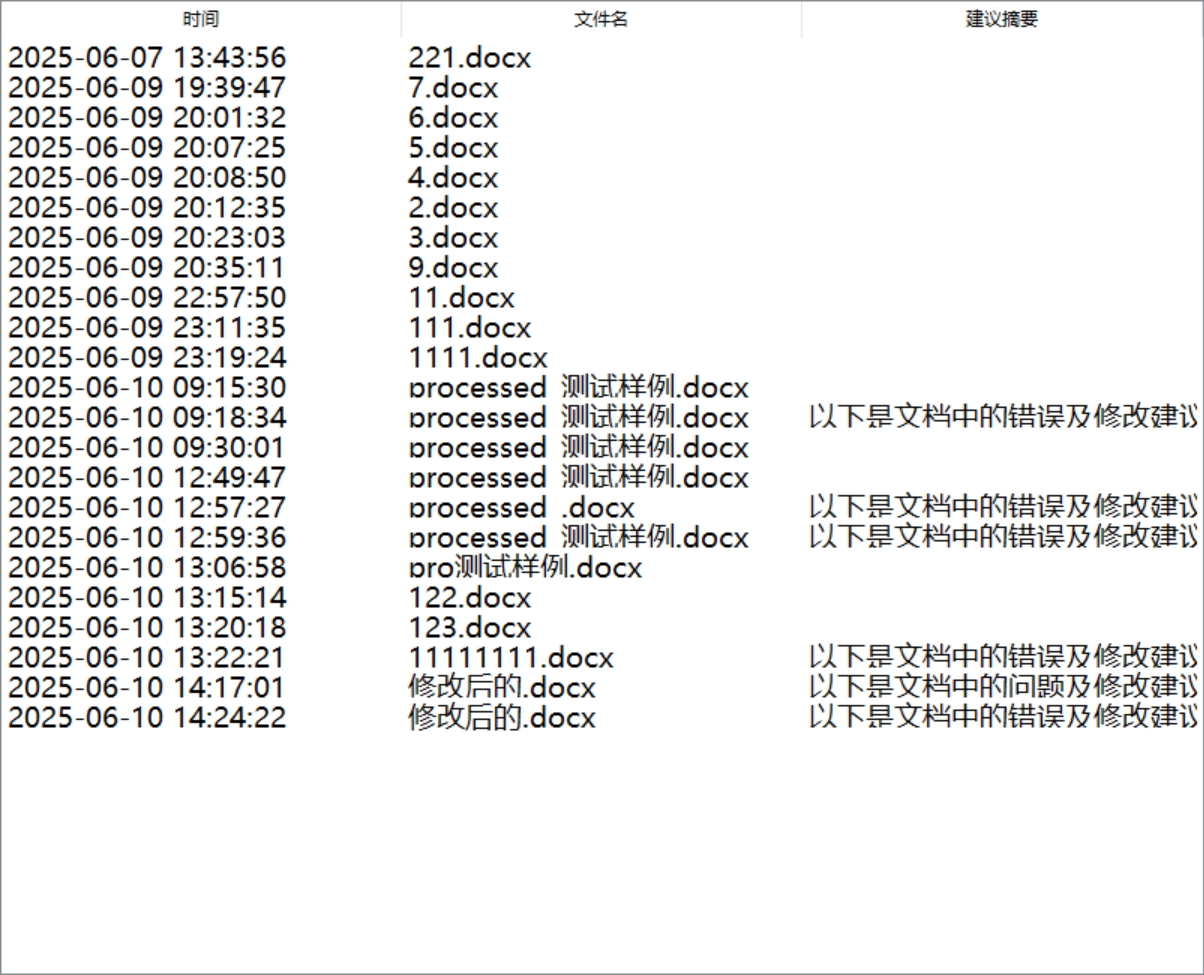
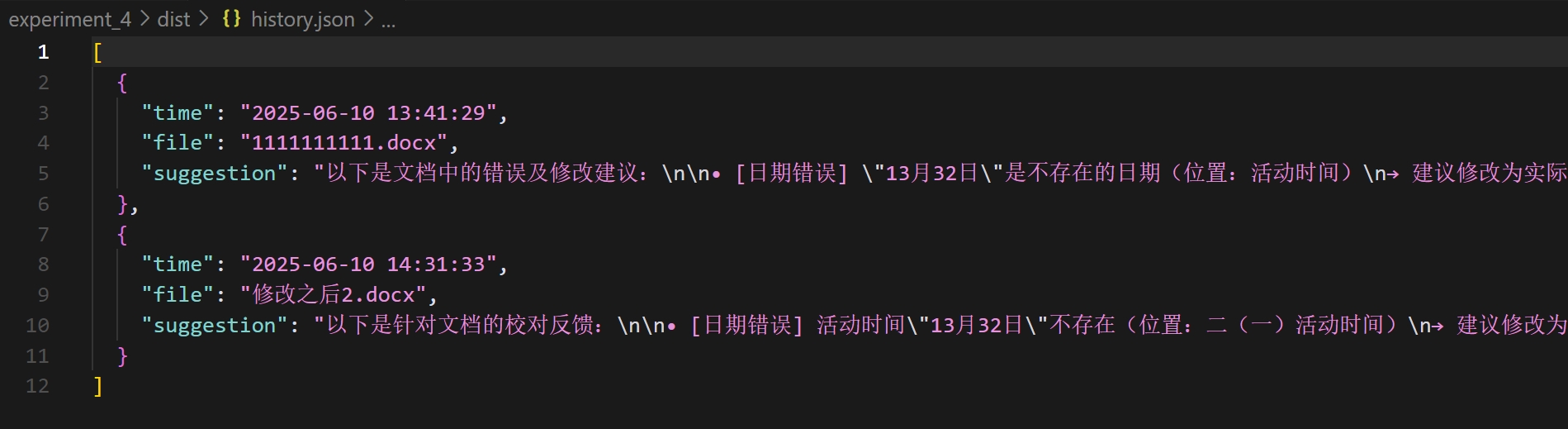
2.历史记录界面中,有时间,文件名,建议摘要三栏,每一项都保存在history.json文件中
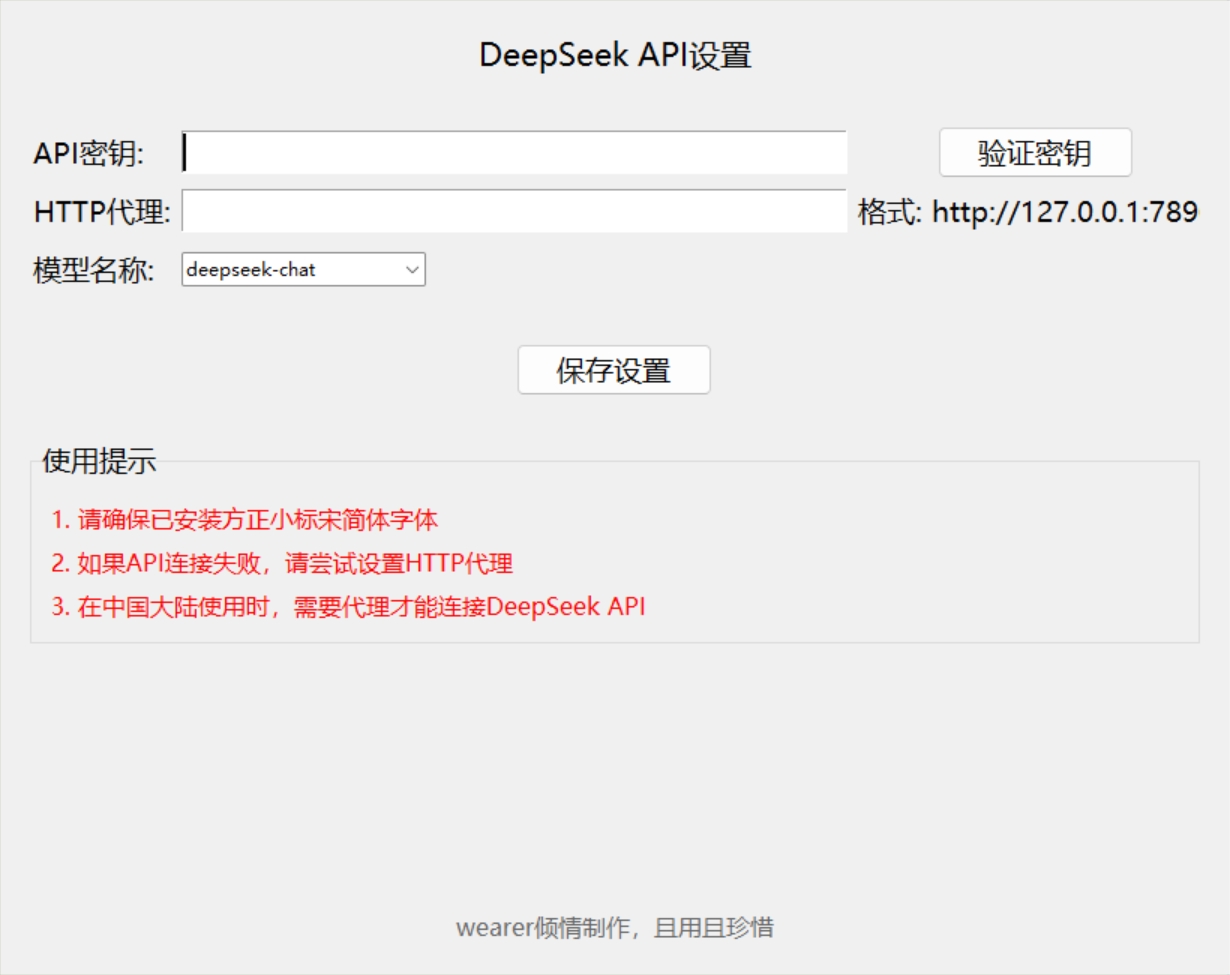
3.设置界面中,有deepseekapi设置``使用注意,设置将保存在config.json文件中
(2)页面设置涉及process_page_setup函数,对公文页面的标准化设置。
-
设置标准页边距:上边距3.6厘米,下边距3.0厘米,左右边距各2.7厘米
-
自动识别文档中第一个非空段落作为公文标题
-
智能处理长标题:当标题长度超过18个字符时,使用分词算法自动换行
-
在标题上方插入两个空行,标题下方插入一个空行
-
将标题设置为方正小标宋简体、二号字(22磅)、居中对齐


(3)正文处理是process_body_format函数,对公文正文内容进行规范化处理。
-
设置正文字体:中文使用仿宋三号(16磅),英文数字使用Times New Roman
-
统一段落格式:两端对齐、首行缩进2字符(24磅)
-
固定行间距为29磅,
-
智能识别并跳过标题段落,避免对标题内容进行错误修改
-
处理特殊符号:将数字后的半角句点替换为全角句点


(4) 标题层级为process_headings函数,对多级标题进行规范化处理。
-
识别一级标题(如"一、")并设置为黑体三号(16磅)、加粗
-
识别二级标题(如"(一)")并设置为楷体三号(16磅)
-
设置标题段落格式:段前12磅、段后6磅间距
-
保持标题首行缩进2字符(24磅),与正文格式一致
-
确保标题行间距固定为29磅


(5) 表格格式设置在process_tables函数,对公文表格进行标准化处理。
-
设置表格整体居中对齐,无文字环绕
-
规范表格边框:外边框1.5磅,内边框0.5磅
-
设置表头为黑体小四(12磅),表格内容为仿宋小四(12磅)
-
统一单元格垂直居中,行高最小值0.75厘米
-
表格内数字字母使用Times New Roman,保持与正文一致
(6) 附件格式在process_attachments函数,对公文附件部分进行标准化处理。
-
自动识别包含"附件"关键词的段落
-
将附件标题设置为黑体三号(16磅)
-
附件标题下确保空出一行正文间距
-
附件标题段落两端对齐,无首行缩进
-
智能处理附件位置,确保与正文有适当间距


(7) 落款格式(process_signature函数),对公文落款部分进行规范化处理。
-
自动识别包含"学生会"的落款单位
-
设置落款日期和单位右对齐
-
在落款前确保空出两行正文间距
-
处理日期格式:日期后添加两个全角空格
-
确保落款单位首字超出日期两个全角空格


(8)页码信息在add_page_numbers函数,对公文页码进行标准化设置:
-
在页脚居中位置添加页码
-
页码格式为"— 页码 —"的规范形式
-
页码字体为宋体四号(14磅)
-
使用域代码实现动态页码,支持文档更新
-
确保每节页脚不链接到前一节

(9)DeepSeek接入在generate_ai_suggestions函数,与DeepSeek API的深度集成功能。
-
提供API密钥管理界面,支持密钥验证和保存
-
支持HTTP代理设置,解决网络访问问题
-
定制专业公文校对提示词,优化AI建议质量
-
提供模型选择功能(deepseek-chat/deepseek-reasoner)
-
自动提取文档内容(跳过标题)生成改进建议
## 四、实验过程中遇到的问题和解决过程
(1)卡在页面设置这一步,提示是:处理失败:页面设置失败:'_Body'ohiect has no attribute'insert。
错误信息 '_Body' object has no attribute 'insert' 表明 self.doc._body 对象没有 insert 方法。在 python-docx 库中,我们需要使用不同的方法来操作文档结构。让我们修改 process_page_setup 方法,使用更可靠的文档操作方法:
-
使用
addprevious方法:-
替换了有问题的
body.insert()方法 -
使用
first_paragraph.addprevious()将标题插入到文档开头 -
使用
title_element.addnext()在标题后插入空段落
-
-
更可靠的 DOM 操作:
将新标题移动到文档开头
first_paragraph = self.doc.paragraphs[0]._element first_paragraph.addprevious(title_element)在标题后插入空段落
title_element.addnext(empty_para_after._element) -
简化段落删除:
直接删除原标题段落
title_para._element.getparent().remove(title_para._element)
(2)后面我又卡在页面设置这一步,这次的提示是:处理失败:页面设置失败:'_Body'ohiect has no attribute'insertBuilding prefix dict from the default dictionary ...
Loading model from cache C:\Users\weare\AppData\Local\Temp\jieba.cache
Loading model cost 0.381 seconds.
Prefix dict has been built successfully.
根据错误信息 '_Body' object has no attribute 'insert',问题出现在 process_page_setup 方法中对 body 对象使用 insert 方法时。在 python-docx 库中,_Body 对象没有 insert 方法,我们需要使用正确的 XML 操作方法。
所以我使用 empty_para._element 获取段落的XML元素,并且对 body 对象使用 insert 方法时,传入的是段落元素(_element),而不是段落对象,之后再使用 addnext 方法在标题后插入空段落
(3)程序在生成的过程中提示“处理失败:页面设置失败:'Paragraph'object has no attribute 'insert_paragraph after'
确”,然后就停止继续处理了。
错误发生在process_page_setup方法中的以下代码段:
title_para.insert_paragraph_after("", style="Normal")
Paragraph对象确实没有insert_paragraph_after方法,这是python-docx库的API使用错误。
五、代码设计
以下是我在deepseek,通义千问,cursor的辅助下完成的代码
点击查看代码
# -*- coding: utf-8 -*-
# @Time : 2025/5/10 11:34
# @Author : weare
# @Email : 1021149940@qq.com
# @File : third-2.py
# @Project : fourth.py
# -*- what can I say -*-
# -*- coding: utf-8 -*-
# ...(保留原有文件头信息)...
import tkinter as tk
from tkinter import ttk, filedialog, messagebox, scrolledtext
from PIL import ImageTk, Image
import json
import os
import threading
import time
from docx import Document
from openai import OpenAI
from docx.shared import Pt, Cm
from docx.oxml.ns import qn
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.enum.text import WD_LINE_SPACING
import re
import jieba
from docx.oxml.shared import OxmlElement
from docx.oxml.ns import nsdecls
from docx.enum.text import WD_ALIGN_PARAGRAPH
# ======================
# 常量定义
# ======================
BACKGROUND_IMAGE_PATH = r"D:\pycharm\python-experiment\experiment_4\2019-7-16 124810 4.jpg" # 替换为你的背景图片路径
HISTORY_FILE = "history.json"
CONFIG_FILE = "config.json"
MAX_HISTORY = 100
FONT_NAME = "微软雅黑"
FONT_SIZE = 14 # 增大后的字号
# ======================
# 改进后的DocFormatter类
# ======================
class DocFormatter:
# 修改__init__方法中的属性初始化顺序
def __init__(self):
self.root = tk.Tk()
self.root.title("智能公文处理系统 v3.0")
self.root.geometry("1000x700")
# 声明实例属性(放在最前面)
self.current_frame = None # 确保此行存在
self.bg_photo = None
self.canvas = None
self.main_frame = None
self.history_frame = None
self.settings_frame = None
self.api_entry = None
self.history_tree = None
self.ai_suggestion = ""
self.input_path = ""
self.output_dir = ""
self.doc = None
self.progress = None
self.lbl_status = None
# 加载配置和历史记录
self.config = self.load_config()
self.history = self.load_history()
# 设置可能需要的代理(如果在中国大陆访问)
# 在配置文件中添加http_proxy和https_proxy支持
proxy = self.config.get("http_proxy", "")
if proxy:
print(f"使用代理: {proxy}")
os.environ["http_proxy"] = proxy
os.environ["https_proxy"] = proxy
# 初始化界面
self.setup_ui()
# 初始化AI客户端(需要在加载配置之后)
try:
self.ai_client = OpenAI(
api_key=self.config.get("api_key", ""),
base_url="https://api.deepseek.com" # 修改为不带v1的基础URL
)
print("AI客户端初始化成功")
except Exception as e:
print(f"AI客户端初始化失败: {str(e)}")
self.ai_client = None
# 最后检查API密钥
self.check_api_key()
# 确保API输入框可以正常输入
self.root.after(100, self.enable_api_entry)
# ======================
# 新增:界面美化模块
# ======================
# ======================
# 新增:配置加载方法
# ======================
def load_config(self):
"""加载配置文件"""
return self.load_json_file(CONFIG_FILE, {"api_key": ""})
def load_history(self):
"""加载历史记录"""
return self.load_json_file(HISTORY_FILE, [])[-MAX_HISTORY:]
def load_json_file(self, file_path, default):
"""通用JSON加载方法"""
try:
if os.path.exists(file_path):
with open(file_path, "r", encoding="utf-8") as f:
return json.load(f)
return default
except Exception as e:
messagebox.showerror("错误", f"加载文件失败: {str(e)}")
return default
def setup_ui(self):
"""初始化美化后的用户界面"""
# 加载背景图片
try:
bg_image = Image.open(BACKGROUND_IMAGE_PATH).resize((1000, 700))
self.bg_photo = ImageTk.PhotoImage(bg_image)
self.canvas = tk.Canvas(self.root, width=1000, height=700)
self.canvas.create_image(0, 0, image=self.bg_photo, anchor=tk.NW)
self.canvas.pack(fill=tk.BOTH, expand=True)
except Exception as e:
messagebox.showerror("错误", f"加载背景失败: {str(e)}")
self.root.destroy()
return
# 配置全局样式
style = ttk.Style()
style.configure(".", font=(FONT_NAME, FONT_SIZE))
style.configure("Nav.TButton",
width=15,
anchor="w",
font=(FONT_NAME, FONT_SIZE),
background="#f0f0f0", # 修改背景色
foreground="black") # 文字颜色设为黑色
style.map("Nav.TButton",
background=[('active', '#e0e0e0')]) # 仅修改悬停背景色
# 创建导航栏
nav_frame = ttk.Frame(self.canvas, width=180)
nav_frame.place(x=0, y=0, relheight=1)
ttk.Button(nav_frame, text="主程序",
command=self.show_main,
style="Nav.TButton").pack(pady=10, fill=tk.X)
ttk.Button(nav_frame, text="历史记录",
command=self.show_history,
style="Nav.TButton").pack(pady=10, fill=tk.X)
ttk.Button(nav_frame, text="设置",
command=self.show_settings,
style="Nav.TButton").pack(pady=10, fill=tk.X)
# 初始化各功能面板
self.main_frame = self.create_main_frame()
self.history_frame = self.create_history_frame()
self.settings_frame = self.create_settings_frame()
# ======================
# 恢复文件操作方法
# ======================
def create_main_frame(self):
"""创建主操作面板"""
frame = ttk.Frame(self.canvas)
# 文件操作区域
file_frame = ttk.LabelFrame(frame, text="文件操作", padding=10)
file_frame.pack(pady=20, padx=20, fill=tk.X)
ttk.Button(file_frame, text="选择输入文件",
command=self.select_input_file).pack(side=tk.LEFT, padx=5)
ttk.Button(file_frame, text="选择输出目录",
command=self.select_output_dir).pack(side=tk.LEFT, padx=5)
# 新增开始处理按钮
ttk.Button(frame,
text="开始处理公文",
command=self.start_processing).pack(pady=15)
# 进度条
self.progress = ttk.Progressbar(frame, orient=tk.HORIZONTAL, length=600)
self.progress.pack(pady=20)
self.lbl_status = ttk.Label(frame, text="等待操作...")
self.lbl_status.pack()
return frame
def select_input_file(self):
"""选择输入文件"""
self.input_path = filedialog.askopenfilename(
filetypes=[("Word文档", "*.docx")],
title="选择要处理的文档"
)
if self.input_path:
self.update_status(f"已选择文件:{os.path.basename(self.input_path)}")
def select_output_dir(self):
"""选择输出目录"""
self.output_dir = filedialog.askdirectory(title="选择输出目录")
if self.output_dir:
self.update_status(f"输出目录:{self.output_dir}")
# 新增处理方法(在适当位置添加)
def start_processing(self):
"""启动文档处理流程"""
if not self.input_path:
messagebox.showwarning("提示", "请先选择输入文件")
return
if not self.output_dir:
messagebox.showwarning("提示", "请先选择输出目录")
return
try:
# 加载文档
self.doc = Document(self.input_path)
print(f"成功加载文档: {self.input_path}")
# 执行处理步骤
processing_steps = [
(10, "正在设置页面布局...", self.process_page_setup),
(30, "正在处理标题格式...", self.process_headings),
(20, "正在调整正文样式...", self.process_body_format),
(40, "正在处理表格格式...", self.process_tables),
(50, "正在处理附件格式...", self.process_attachments),
(60, "正在处理落款格式...", self.process_signature),
(70, "正在添加页码...", self.add_page_numbers),
(80, "正在生成AI建议...", self.generate_ai_suggestions),
(90, "正在确保标题格式...", self.ensure_title_format),
(100, "正在保存文件...", self.save_document)
]
for progress, msg, func in processing_steps:
self.update_status(msg, progress)
print(f"开始: {msg}")
func()
print(f"完成: {msg}")
time.sleep(0.5) # 模拟处理过程
messagebox.showinfo("完成", "公文处理成功!")
except Exception as e:
print(f"处理失败: {str(e)}")
import traceback
print(traceback.format_exc()) # 打印完整堆栈跟踪
messagebox.showerror("错误", f"处理失败:{str(e)}")
# 修改save_document方法
def save_document(self):
"""保存处理后的文档"""
default_name = f"processed_{os.path.basename(self.input_path)}"
output_path = filedialog.asksaveasfilename(
defaultextension=".docx",
initialfile=default_name,
filetypes=[("Word文档", "*.docx")],
initialdir=self.output_dir
)
if output_path:
try:
self.doc.save(output_path)
self.add_history_record(output_path, self.ai_suggestion)
messagebox.showinfo("保存成功", f"文件已保存至:\n{output_path}")
except Exception as e:
messagebox.showerror("错误", f"保存失败: {str(e)}")
# 在save_document方法后添加(约260行)
def add_history_record(self, filename, suggestion):
"""添加历史记录"""
record = {
"time": time.strftime("%Y-%m-%d %H:%M:%S"),
"file": os.path.basename(filename),
"suggestion": suggestion[:100] + "..." if len(suggestion) > 100 else suggestion
}
self.history.append(record)
# 保持最多MAX_HISTORY条记录
self.history = self.history[-MAX_HISTORY:]
try:
with open(HISTORY_FILE, "w", encoding="utf-8") as f:
json.dump(self.history, f, indent=2, ensure_ascii=False)
except Exception as e:
messagebox.showerror("错误", f"保存历史失败: {str(e)}")
# 新增刷新历史记录显示
self.history_tree.insert("", 0, values=(
record["time"],
record["file"],
record["suggestion"]
))
# 保持最多显示MAX_HISTORY条
if len(self.history_tree.get_children()) > MAX_HISTORY:
self.history_tree.delete(self.history_tree.get_children()[-1])
def update_status(self, message, progress=0):
"""更新状态信息"""
self.lbl_status.config(text=message)
self.progress["value"] = progress
self.root.update_idletasks()
def _set_title_style(self, paragraph):
"""设置标题样式"""
run = paragraph.runs[0] if paragraph.runs else paragraph.add_run()
run.font.name = "方正小标宋简体"
run._element.rPr.rFonts.set(qn("w:eastAsia"), "方正小标宋简体")
run.font.size = Pt(22) # 二号字体为22磅
run.font.color.rgb = RGBColor(0, 0, 0)
# 段落格式调整
paragraph.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中对齐
paragraph.paragraph_format.line_spacing = Pt(29)
paragraph.paragraph_format.space_before = Pt(0) # 段前0磅
paragraph.paragraph_format.space_after = Pt(0) # 段后0磅
paragraph.paragraph_format.first_line_indent = Cm(0) # 取消缩进
# ...(前面的代码保持不变)...
def process_page_setup(self):
"""重构后的页面设置函数"""
try:
# 设置页边距
for section in self.doc.sections:
section.top_margin = Cm(3.6)
section.bottom_margin = Cm(3.0)
section.left_margin = Cm(2.7)
section.right_margin = Cm(2.7)
# 查找第一个非空段落作为标题
title_para = next((p for p in self.doc.paragraphs if p.text.strip()), None)
if title_para:
# 保存标题文本和删除原标题
title_text = title_para.text
title_para._element.getparent().remove(title_para._element)
# 创建一个全新的文档
new_doc = Document()
# 复制原文档的节属性(页面设置)
for new_section, old_section in zip(new_doc.sections, self.doc.sections):
new_section.top_margin = old_section.top_margin
new_section.bottom_margin = old_section.bottom_margin
new_section.left_margin = old_section.left_margin
new_section.right_margin = old_section.right_margin
# 在新文档中添加一个空行
new_doc.add_paragraph("")
# 添加标题并处理换行
print(f"标题文本: '{title_text}', 长度: {len(title_text)}")
# 检查标题长度,如果超过18个字符,进行换行处理
if len(title_text) > 18:
# 分割标题文本
lines = self._split_title_text(title_text)
print(f"标题分割为 {len(lines)} 行: {lines}")
# 添加每一行作为单独的标题段落
for line in lines:
title = new_doc.add_paragraph(line, style="Title")
self._set_title_style(title)
# 确保标题格式正确
title.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中对齐
title.paragraph_format.first_line_indent = Cm(0) # 取消首行缩进
else:
# 标题不需要换行
title = new_doc.add_paragraph(title_text, style="Title")
self._set_title_style(title)
# 确保标题格式正确
title.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中对齐
title.paragraph_format.first_line_indent = Cm(0) # 取消首行缩进
# 添加两个空行
new_doc.add_paragraph("")
new_doc.add_paragraph("")
# 复制原文档中的所有内容到新文档
for para in self.doc.paragraphs:
if para.text.strip() or len(para.runs) > 0: # 确保不是空段落
p = new_doc.add_paragraph()
# 复制段落格式
if hasattr(para.paragraph_format, 'alignment') and para.paragraph_format.alignment:
p.paragraph_format.alignment = para.paragraph_format.alignment
if hasattr(para.paragraph_format, 'first_line_indent') and para.paragraph_format.first_line_indent:
p.paragraph_format.first_line_indent = para.paragraph_format.first_line_indent
if hasattr(para.paragraph_format, 'line_spacing') and para.paragraph_format.line_spacing:
p.paragraph_format.line_spacing = para.paragraph_format.line_spacing
# 复制段落内容和格式
for run in para.runs:
new_run = p.add_run(run.text)
# 复制字体格式
if run.bold:
new_run.bold = run.bold
if run.italic:
new_run.italic = run.italic
if run.underline:
new_run.underline = run.underline
if run.font.name:
new_run.font.name = run.font.name
# 设置东亚字体
if hasattr(run._element, 'rPr') and hasattr(run._element.rPr, 'rFonts'):
east_asia_font = run._element.rPr.rFonts.get(qn('w:eastAsia'))
if east_asia_font:
new_run._element.rPr.rFonts.set(qn('w:eastAsia'), east_asia_font)
if run.font.size:
new_run.font.size = run.font.size
if hasattr(run.font, 'color') and run.font.color.rgb:
new_run.font.color.rgb = run.font.color.rgb
# 复制表格
for table in self.doc.tables:
# 创建新表格
new_table = new_doc.add_table(rows=len(table.rows), cols=len(table.columns))
# 复制表格样式
if table.style:
new_table.style = table.style
# 复制表格内容
for i, row in enumerate(table.rows):
for j, cell in enumerate(row.cells):
# 复制单元格内容
new_cell = new_table.cell(i, j)
for para in cell.paragraphs:
if para.text.strip(): # 非空段落
p = new_cell.add_paragraph(para.text)
# 复制段落格式
if para.paragraph_format.alignment:
p.paragraph_format.alignment = para.paragraph_format.alignment
# 用新文档替换原文档
self.doc = new_doc
except Exception as e:
print(f"页面设置失败: {str(e)}") # 打印错误信息以便调试
raise Exception(f"页面设置失败: {str(e)}")
def _split_title_text(self, text):
"""分割标题文本为多行"""
print(f"开始分割标题文本: '{text}'")
# 如果标题长度不超过18个字符,不需要分割
if len(text) <= 18:
return [text]
# 使用jieba进行分词
words = list(jieba.cut(text))
print(f"分词结果: {words}")
lines = []
current_line = []
current_len = 0
# 根据标点和词性换行
for word in words:
# 如果当前词包含标点符号,添加到当前行并开始新行
if any(c in word for c in ",。;!?"):
current_line.append(word)
lines.append("".join(current_line))
print(f"遇到标点,添加行: {''.join(current_line)}")
current_line = []
current_len = 0
# 如果添加当前词会导致行长度超过18,先保存当前行,然后开始新行
elif current_len + len(word) > 18:
lines.append("".join(current_line))
print(f"行长度超过18,添加行: {''.join(current_line)}")
current_line = [word]
current_len = len(word)
# 否则,将当前词添加到当前行
else:
current_line.append(word)
current_len += len(word)
# 添加最后一行(如果有)
if current_line:
lines.append("".join(current_line))
print(f"添加最后一行: {''.join(current_line)}")
# 检查行数平衡(如果只有两行且长度差异大)
if len(lines) == 2 and abs(len(lines[0]) - len(lines[1])) > 5:
print("行长度不平衡,重新平衡")
mid = len(text) // 2
lines = [text[:mid], text[mid:]]
print(f"平衡后的行: {lines}")
print(f"最终分割结果: {lines}")
return lines
# ...(后面的代码保持不变)...
def _auto_wrap_title(self, paragraph):
"""智能标题换行(硬回车)"""
text = paragraph.text.strip()
if len(text) <= 18:
return
# 使用jieba进行分词
words = list(jieba.cut(text))
lines = []
current_line = []
current_len = 0
# 根据标点和词性换行
for word in words:
if any(c in word for c in ",。;!?"):
current_line.append(word)
lines.append("".join(current_line))
current_line = []
current_len = 0
elif current_len + len(word) > 18:
lines.append("".join(current_line))
current_line = [word]
current_len = len(word)
else:
current_line.append(word)
current_len += len(word)
if current_line:
lines.append("".join(current_line))
# 检查行数平衡
if len(lines) == 2 and abs(len(lines[0]) - len(lines[1])) > 5:
mid = len(text) // 2
lines = [text[:mid], text[mid:]]
# 清空原段落内容
paragraph.clear()
# 添加硬换行(通过多个段落实现)
for line in lines:
new_para = self.doc.add_paragraph(line, style="Title")
# 应用标题样式
run = new_para.runs[0] if new_para.runs else new_para.add_run(line)
run.font.name = "方正小标宋简体"
run._element.rPr.rFonts.set(qn("w:eastAsia"), "方正小标宋简体")
run.font.size = Pt(22) # 二号字体为22磅
run.font.color.rgb = RGBColor(0, 0, 0)
# 段落格式调整
new_para.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中对齐
new_para.paragraph_format.line_spacing = Pt(29)
new_para.paragraph_format.space_before = Pt(0) # 段前0磅
new_para.paragraph_format.space_after = Pt(0) # 段后0磅
new_para.paragraph_format.first_line_indent = Cm(0) # 取消缩进
def process_body_format(self):
"""优化后的正文处理函数"""
try:
fullwidth_dot = re.compile(r'(\d+)\.')
dash_pattern = re.compile(r'(\d{1,2}:\d{2})-(\d{1,2}:\d{2})')
for para in self.doc.paragraphs:
# ==== 修复点1:安全判断标题段落 ====
# 获取字体名称(兼容None值)
font_name = ""
try:
if para.style and para.style.font:
font_name = para.style.font.name or ""
except AttributeError:
pass
# 检查是否为标题段落
is_title = False
# 通过字体名称判断
if "方正小标宋" in font_name:
is_title = True
# 通过段落格式判断(居中对齐且无首行缩进可能是标题)
if (hasattr(para.paragraph_format, 'alignment') and
para.paragraph_format.alignment == WD_PARAGRAPH_ALIGNMENT.CENTER and
hasattr(para.paragraph_format, 'first_line_indent') and
para.paragraph_format.first_line_indent == 0):
is_title = True
# 通过文本内容判断(如果是第一个非空段落)
if para == next((p for p in self.doc.paragraphs if p.text.strip()), None):
is_title = True
# 跳过标题段落
if is_title:
print(f"跳过标题段落: '{para.text}'")
continue
# ==== 修复点2:增强空段落处理 ====
if not para.text.strip():
continue
# 检查是否为一级或二级标题
text = para.text.strip()
level1_pattern = re.compile(r'^[一二三四五六七八九十]+、')
level2_pattern = re.compile(r'^([一二三四五六七八九十]+)')
if level1_pattern.match(text) or level2_pattern.match(text):
continue # 跳过标题段落
# ==== 设置正文格式 ====
# 设置段落格式
para.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.JUSTIFY
para.paragraph_format.first_line_indent = Pt(24) # 2字符
para.paragraph_format.line_spacing_rule = WD_LINE_SPACING.EXACTLY
para.paragraph_format.line_spacing = Pt(29)
# 清空段落内容并重新添加,以应用正确的字体
text = para.text
if not text.strip():
continue
para.clear()
# 分离文本中的数字、字母和汉字
segments = []
current_seg = ""
current_type = None # 0: 汉字, 1: 数字字母
for char in text:
if re.match(r'[A-Za-z0-9]', char):
char_type = 1 # 数字字母
else:
char_type = 0 # 汉字
if current_type is None:
current_type = char_type
current_seg = char
elif current_type == char_type:
current_seg += char
else:
segments.append((current_seg, current_type))
current_type = char_type
current_seg = char
if current_seg:
segments.append((current_seg, current_type))
# 应用样式
for segment, seg_type in segments:
run = para.add_run(segment)
if seg_type == 0: # 汉字
run.font.name = '仿宋'
run._element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋')
run.font.size = Pt(16) # 三号字体为16磅
else: # 数字、字母
run.font.name = 'Times New Roman'
run.font.size = Pt(16) # 三号字体为16磅
except Exception as e:
raise Exception(f"正文格式处理失败: {str(e)}")
def process_headings(self):
"""处理标题层级格式"""
try:
# 一级标题正则表达式(一、二、三、等)
level1_pattern = re.compile(r'^[一二三四五六七八九十]+、')
# 二级标题正则表达式((一)(二)等)
level2_pattern = re.compile(r'^([一二三四五六七八九十]+)')
for para in self.doc.paragraphs:
text = para.text.strip()
# 跳过空段落
if not text:
continue
# 处理一级标题(一、二、三、等)
if level1_pattern.match(text):
# 清空段落内容
para.clear()
# 添加内容并设置为黑体
run = para.add_run(text)
run.font.name = '黑体'
run._element.rPr.rFonts.set(qn('w:eastAsia'), '黑体')
run.font.bold = True
run.font.size = Pt(16)
# 设置段落格式
para.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.JUSTIFY
para.paragraph_format.space_before = Pt(12)
para.paragraph_format.space_after = Pt(6)
para.paragraph_format.first_line_indent = Pt(24) # 首行缩进2字符(24磅)
para.paragraph_format.line_spacing_rule = WD_LINE_SPACING.EXACTLY
para.paragraph_format.line_spacing = Pt(29) # 固定行间距29磅
# 处理二级标题((一)(二)等)
elif level2_pattern.match(text):
# 清空段落内容
para.clear()
# 添加内容并设置为楷体三号
run = para.add_run(text)
run.font.name = '楷体'
run._element.rPr.rFonts.set(qn('w:eastAsia'), '楷体')
run.font.size = Pt(16) # 三号字体为16磅
# 设置段落格式
para.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.JUSTIFY
para.paragraph_format.space_before = Pt(10)
para.paragraph_format.space_after = Pt(6)
para.paragraph_format.first_line_indent = Pt(24) # 首行缩进2字符(24磅)
para.paragraph_format.line_spacing_rule = WD_LINE_SPACING.EXACTLY
para.paragraph_format.line_spacing = Pt(29) # 固定行间距29磅
except Exception as e:
raise Exception(f"标题格式处理失败: {str(e)}")
def process_tables(self):
"""处理表格格式"""
try:
print("开始处理表格格式...")
# 检查文档中是否有表格
if not self.doc.tables:
print("文档中没有表格")
return
from docx.shared import Pt, Cm
from docx.enum.table import WD_TABLE_ALIGNMENT, WD_CELL_VERTICAL_ALIGNMENT
from docx.oxml.shared import OxmlElement, qn
# 处理文档中的所有表格
for table_index, table in enumerate(self.doc.tables):
print(f"处理第 {table_index+1} 个表格")
# 1. 设置表格属性:水平居中对齐,无文字环绕
table.alignment = WD_TABLE_ALIGNMENT.CENTER
# 2. 设置表格外边框(1.5磅)和内边框(0.5磅)
self._set_table_borders(table, outer_width=1.5, inner_width=0.5)
# 处理表格中的所有行
for i, row in enumerate(table.rows):
# 3. 设置行高:最小值0.7-0.8厘米
row.height = Cm(0.75) # 取中间值0.75厘米
# 处理每个单元格
for j, cell in enumerate(row.cells):
# 4. 设置单元格垂直对齐方式:居中
cell.vertical_alignment = WD_CELL_VERTICAL_ALIGNMENT.CENTER
# 处理单元格中的段落
for para in cell.paragraphs:
# 5. 设置段落行距:单倍行距1倍
para.paragraph_format.line_spacing = 1.0
# 清空段落
text = para.text
if not text.strip():
continue
para.clear()
# 分离文本中的数字、字母和汉字
import re
segments = []
current_seg = ""
current_type = None # 0: 汉字, 1: 数字字母
for char in text:
if re.match(r'[A-Za-z0-9]', char):
char_type = 1 # 数字字母
else:
char_type = 0 # 汉字
if current_type is None:
current_type = char_type
current_seg = char
elif current_type == char_type:
current_seg += char
else:
segments.append((current_seg, current_type))
current_type = char_type
current_seg = char
if current_seg:
segments.append((current_seg, current_type))
# 应用样式
for segment, seg_type in segments:
run = para.add_run(segment)
if i == 0: # 表头
# 6. 表头:黑体小四
if seg_type == 0: # 汉字
run.font.name = '黑体'
run._element.rPr.rFonts.set(qn('w:eastAsia'), '黑体')
run.font.size = Pt(12) # 小四号字体为12磅
else: # 数字、字母
# 7. 数字、字母:Times New Roman(包括标题及表头)
run.font.name = 'Times New Roman'
run.font.size = Pt(12) # 小四号字体为12磅
else: # 表格内容
# 8. 表格里的内容:仿宋小四
if seg_type == 0: # 汉字
run.font.name = '仿宋'
run._element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋')
run.font.size = Pt(12) # 小四号字体为12磅
else: # 数字、字母
# 9. 数字、字母:Times New Roman
run.font.name = 'Times New Roman'
run.font.size = Pt(12) # 小四号字体为12磅
print("表格格式处理完成")
except Exception as e:
print(f"表格格式处理失败: {str(e)}")
import traceback
print(traceback.format_exc()) # 打印完整堆栈跟踪
raise Exception(f"表格格式处理失败: {str(e)}")
def _set_table_borders(self, table, outer_width=1.5, inner_width=0.5):
"""设置表格边框宽度"""
try:
print(f"设置表格边框: 外边框={outer_width}磅, 内边框={inner_width}磅")
# 设置所有单元格边框为内边框宽度
for cell in table._cells:
# 获取单元格属性
tcPr = cell._tc.get_or_add_tcPr()
# 创建单元格边框元素
tcBorders = OxmlElement('w:tcBorders')
# 设置四个边(上、左、下、右)的边框属性
for border_position in ['top', 'left', 'bottom', 'right']:
border = OxmlElement(f'w:{border_position}')
border.set(qn('w:val'), 'single') # 实线
border.set(qn('w:sz'), str(int(inner_width * 8))) # 内边框宽度(磅的8倍)
border.set(qn('w:space'), '0') # 边框间距
border.set(qn('w:color'), '000000') # 边框颜色(黑色)
tcBorders.append(border)
# 先删除现有的边框设置(如果有)
existing_borders = None
for child in tcPr.getchildren():
if child.tag.endswith('tcBorders'):
existing_borders = child
break
if existing_borders is not None:
tcPr.remove(existing_borders)
# 将新的边框元素添加到单元格属性中
tcPr.append(tcBorders)
# 设置表格外边框(1.5磅)
# 1. 获取第一行和最后一行的所有单元格
if table.rows:
first_row = table.rows[0]
last_row = table.rows[-1]
# 2. 设置第一行的上边框
for cell in first_row.cells:
tcPr = cell._tc.get_or_add_tcPr()
# 找到现有的边框元素或创建新的
tcBorders = None
for child in tcPr.getchildren():
if child.tag.endswith('tcBorders'):
tcBorders = child
break
if tcBorders is None:
tcBorders = OxmlElement('w:tcBorders')
tcPr.append(tcBorders)
# 删除现有的上边框(如果有)
for child in tcBorders.getchildren():
if child.tag.endswith('top'):
tcBorders.remove(child)
break
# 添加新的上边框
top = OxmlElement('w:top')
top.set(qn('w:val'), 'single')
top.set(qn('w:sz'), str(int(outer_width * 8)))
top.set(qn('w:space'), '0')
top.set(qn('w:color'), '000000')
tcBorders.append(top)
# 3. 设置最后一行的下边框
for cell in last_row.cells:
tcPr = cell._tc.get_or_add_tcPr()
# 找到现有的边框元素或创建新的
tcBorders = None
for child in tcPr.getchildren():
if child.tag.endswith('tcBorders'):
tcBorders = child
break
if tcBorders is None:
tcBorders = OxmlElement('w:tcBorders')
tcPr.append(tcBorders)
# 删除现有的下边框(如果有)
for child in tcBorders.getchildren():
if child.tag.endswith('bottom'):
tcBorders.remove(child)
break
# 添加新的下边框
bottom = OxmlElement('w:bottom')
bottom.set(qn('w:val'), 'single')
bottom.set(qn('w:sz'), str(int(outer_width * 8)))
bottom.set(qn('w:space'), '0')
bottom.set(qn('w:color'), '000000')
tcBorders.append(bottom)
# 4. 设置第一列和最后一列的单元格的左右边框
for row in table.rows:
# 第一列左边框
if row.cells:
left_cell = row.cells[0]
tcPr = left_cell._tc.get_or_add_tcPr()
# 找到现有的边框元素或创建新的
tcBorders = None
for child in tcPr.getchildren():
if child.tag.endswith('tcBorders'):
tcBorders = child
break
if tcBorders is None:
tcBorders = OxmlElement('w:tcBorders')
tcPr.append(tcBorders)
# 删除现有的左边框(如果有)
for child in tcBorders.getchildren():
if child.tag.endswith('left'):
tcBorders.remove(child)
break
# 添加新的左边框
left = OxmlElement('w:left')
left.set(qn('w:val'), 'single')
left.set(qn('w:sz'), str(int(outer_width * 8)))
left.set(qn('w:space'), '0')
left.set(qn('w:color'), '000000')
tcBorders.append(left)
# 最后一列右边框
right_cell = row.cells[-1]
tcPr = right_cell._tc.get_or_add_tcPr()
# 找到现有的边框元素或创建新的
tcBorders = None
for child in tcPr.getchildren():
if child.tag.endswith('tcBorders'):
tcBorders = child
break
if tcBorders is None:
tcBorders = OxmlElement('w:tcBorders')
tcPr.append(tcBorders)
# 删除现有的右边框(如果有)
for child in tcBorders.getchildren():
if child.tag.endswith('right'):
tcBorders.remove(child)
break
# 添加新的右边框
right = OxmlElement('w:right')
right.set(qn('w:val'), 'single')
right.set(qn('w:sz'), str(int(outer_width * 8)))
right.set(qn('w:space'), '0')
right.set(qn('w:color'), '000000')
tcBorders.append(right)
print("表格边框设置完成")
except Exception as e:
print(f"设置表格边框失败: {str(e)}")
import traceback
print(traceback.format_exc()) # 打印完整堆栈跟踪
raise
def process_attachments(self):
"""处理附件格式"""
try:
# 使用更宽松的模式匹配"附件"关键词
attachment_found = False
for para in self.doc.paragraphs:
text = para.text.strip()
# 跳过空段落
if not text:
continue
# 查找包含"附件"的段落(更宽松的匹配)
if "附件" in text:
attachment_found = True
print(f"找到附件段落: '{text}'") # 调试输出
# 清空段落内容并重新添加
para.clear()
run = para.add_run(text)
# 设置为黑体3号
run.font.name = '黑体'
run._element.rPr.rFonts.set(qn('w:eastAsia'), '黑体')
run.font.size = Pt(16) # 3号字体为16磅
# 设置段落格式:两端对齐,无首行缩进
para.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.JUSTIFY
para.paragraph_format.first_line_indent = Cm(0) # 无首行缩进
# 确保附件标题下与正文空出一行
# 查找当前段落的索引
index = 0
for i, p in enumerate(self.doc.paragraphs):
if p == para:
index = i
break
# 如果不是最后一个段落,检查下一个段落是否为空
if index < len(self.doc.paragraphs) - 1:
next_para = self.doc.paragraphs[index + 1]
# 如果下一个段落不是空段落,则插入一个空段落
if next_para.text.strip():
# 在附件标题后插入一个空段落
empty_para = self.doc.add_paragraph()
# 获取XML元素
empty_element = empty_para._element
# 将空段落插入到附件标题后面
para._element.addnext(empty_element)
if not attachment_found:
print("未找到附件段落") # 调试输出
except Exception as e:
print(f"附件格式处理失败: {str(e)}") # 调试输出
raise Exception(f"附件格式处理失败: {str(e)}")
def process_signature(self):
"""处理落款格式"""
try:
# 使用更宽松的模式匹配"院学生会"关键词
signature_found = False
# 打印所有段落内容以便调试
print("文档段落内容:")
for i, para in enumerate(self.doc.paragraphs):
if para.text.strip():
print(f"段落 {i}: '{para.text}'")
if "学生会" in para.text:
print(f" --> 可能的学生会段落")
# 查找包含"学生会"的段落
for i, para in enumerate(self.doc.paragraphs):
text = para.text.strip()
# 跳过空段落
if not text:
continue
# 查找包含"学生会"的段落
if "学生会" in text:
signature_found = True
print(f"找到学生会段落: '{text}'")
# 确保有足够的后续段落
if i + 1 < len(self.doc.paragraphs):
# 下一段是日期段落
date_para = self.doc.paragraphs[i + 1]
date_text = date_para.text.strip()
if date_text:
print(f"日期段落: '{date_text}'")
# 设置日期段落右对齐
date_para.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT
# 确保日期段落与正文空出两行
# 查找日期段落前的段落
prev_para_index = i - 1
while prev_para_index >= 0 and not self.doc.paragraphs[prev_para_index].text.strip():
prev_para_index -= 1
# 如果找到了前一个非空段落(正文末尾)
if prev_para_index >= 0:
# 计算需要插入的空行数
empty_lines_needed = 2
current_empty_lines = 0
# 计算已有的空行数
for j in range(prev_para_index + 1, i):
if not self.doc.paragraphs[j].text.strip():
current_empty_lines += 1
print(f"当前空行数: {current_empty_lines}, 需要: {empty_lines_needed}")
# 插入缺少的空行
for _ in range(empty_lines_needed - current_empty_lines):
empty_para = self.doc.add_paragraph()
# 获取XML元素并插入到合适位置
empty_element = empty_para._element
self.doc.paragraphs[prev_para_index]._element.addnext(empty_element)
# 处理日期格式:在日期后添加两个全角空格
date_para.clear()
# 使用正则表达式分离数字和汉字
parts = re.split(r'(\d+)', date_text)
for part in parts:
if part.strip():
run = date_para.add_run(part)
if re.match(r'\d+', part): # 数字部分
run.font.name = 'Times New Roman'
run.font.size = Pt(16) # 三号字体为16磅
else: # 汉字部分
run.font.name = '仿宋'
run._element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋')
run.font.size = Pt(16) # 三号字体为16磅
# 添加两个全角空格
date_para.add_run(" ")
# 处理署名:确保第一个字超出日期两个全角空格
if i + 2 < len(self.doc.paragraphs):
signature_para = self.doc.paragraphs[i + 2]
signature_text = signature_para.text.strip()
if signature_text:
print(f"署名段落: '{signature_text}'")
# 设置署名段落右对齐
signature_para.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT
# 清空原段落内容
signature_para.clear()
# 添加两个全角空格
signature_para.add_run(" ")
# 使用正则表达式分离数字和汉字
parts = re.split(r'(\d+)', signature_text)
for part in parts:
if part.strip():
run = signature_para.add_run(part)
if re.match(r'\d+', part): # 数字部分
run.font.name = 'Times New Roman'
run.font.size = Pt(16) # 三号字体为16磅
else: # 汉字部分
run.font.name = '仿宋'
run._element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋')
run.font.size = Pt(16) # 三号字体为16磅
# 找到一个落款就退出,避免重复处理
break
if not signature_found:
print("未找到学生会段落")
except Exception as e:
print(f"落款格式处理失败: {str(e)}") # 调试输出
raise Exception(f"落款格式处理失败: {str(e)}")
def add_page_numbers(self):
"""添加页码信息"""
try:
print("开始添加页码...")
# 确保文档至少有一个节
if not self.doc.sections:
print("文档没有节,无法添加页码")
return
# 遍历文档中的所有节
for i, section in enumerate(self.doc.sections):
print(f"处理第 {i+1} 个节的页码")
# 获取页脚
footer = section.footer
# 确保页脚不是链接到前一节
footer.is_linked_to_previous = False
print(f"页脚链接状态: {footer.is_linked_to_previous}")
# 获取或创建页脚段落
if len(footer.paragraphs) == 0:
print("创建新的页脚段落")
p = footer.add_paragraph()
else:
print("使用现有页脚段落")
p = footer.paragraphs[0]
p.clear()
# 设置页脚段落居中对齐
p.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 添加页码文本:"— "
run1 = p.add_run("— ")
run1.font.name = '宋体'
run1._element.rPr.rFonts.set(qn('w:eastAsia'), '宋体')
run1.font.size = Pt(14) # 四号字体为14磅
# 添加页码域代码
self._add_page_number_field(p)
# 添加页码文本:" —"
run2 = p.add_run(" —")
run2.font.name = '宋体'
run2._element.rPr.rFonts.set(qn('w:eastAsia'), '宋体')
run2.font.size = Pt(14) # 四号字体为14磅
print(f"第 {i+1} 个节的页码添加完成")
print("页码添加完成")
except Exception as e:
print(f"添加页码失败: {str(e)}")
import traceback
print(traceback.format_exc()) # 打印完整堆栈跟踪
raise Exception(f"添加页码失败: {str(e)}")
def _add_page_number_field(self, paragraph):
"""向段落添加页码域代码"""
try:
# 创建包含页码域的运行
run = paragraph.add_run()
run.font.name = '宋体'
run._element.rPr.rFonts.set(qn('w:eastAsia'), '宋体')
run.font.size = Pt(14) # 四号字体为14磅
# 创建复杂域开始标记
fldChar1 = OxmlElement('w:fldChar')
fldChar1.set(qn('w:fldCharType'), 'begin')
run._element.append(fldChar1)
# 创建域指令
instrText = OxmlElement('w:instrText')
instrText.set(qn('xml:space'), 'preserve')
instrText.text = " PAGE "
run._element.append(instrText)
# 创建域分隔符
fldChar2 = OxmlElement('w:fldChar')
fldChar2.set(qn('w:fldCharType'), 'separate')
run._element.append(fldChar2)
# 创建域结果(默认显示1)
t = OxmlElement('w:t')
t.text = "1"
run._element.append(t)
# 创建域结束标记
fldChar3 = OxmlElement('w:fldChar')
fldChar3.set(qn('w:fldCharType'), 'end')
run._element.append(fldChar3)
print("页码域代码添加成功")
except Exception as e:
print(f"添加页码域代码失败: {str(e)}")
raise
# ======================
# 新增:设置界面模块
# ======================
def create_settings_frame(self):
"""创建包含API设置的界面"""
frame = ttk.Frame(self.canvas)
# API设置区域
ttk.Label(frame, text="DeepSeek API设置", font=(FONT_NAME, 16)).pack(pady=20)
api_frame = ttk.Frame(frame)
api_frame.pack(pady=10, fill=tk.X, padx=20)
# API密钥设置
ttk.Label(api_frame, text="API密钥:").grid(row=0, column=0, sticky=tk.W, pady=5)
# 使用StringVar来管理API输入框的值
self.api_var = tk.StringVar()
if self.config.get("api_key"):
self.api_var.set(self.config["api_key"])
# 创建输入框并绑定到StringVar
self.api_entry = tk.Entry(api_frame, width=40, font=(FONT_NAME, FONT_SIZE), textvariable=self.api_var)
self.api_entry.grid(row=0, column=1, padx=5, sticky=tk.W+tk.E)
ttk.Button(api_frame, text="验证密钥",
command=self.validate_api).grid(row=0, column=2)
# 添加代理设置
ttk.Label(api_frame, text="HTTP代理:").grid(row=1, column=0, sticky=tk.W, pady=5)
# 使用StringVar来管理代理输入框的值
self.proxy_var = tk.StringVar()
if self.config.get("http_proxy"):
self.proxy_var.set(self.config["http_proxy"])
# 创建输入框并绑定到StringVar
proxy_entry = tk.Entry(api_frame, width=40, font=(FONT_NAME, FONT_SIZE), textvariable=self.proxy_var)
proxy_entry.grid(row=1, column=1, padx=5, sticky=tk.W+tk.E)
# 添加代理说明标签
ttk.Label(api_frame, text="格式: http://127.0.0.1:7890").grid(row=1, column=2, sticky=tk.W, pady=5)
# 添加模型设置
ttk.Label(api_frame, text="模型名称:").grid(row=2, column=0, sticky=tk.W, pady=5)
# 使用StringVar来管理模型输入框的值
self.model_var = tk.StringVar(value=self.config.get("model", "deepseek-chat"))
# 创建下拉选择框
model_combo = ttk.Combobox(api_frame, textvariable=self.model_var, width=20)
model_combo['values'] = ('deepseek-chat', 'deepseek-reasoner')
model_combo.grid(row=2, column=1, padx=5, sticky=tk.W)
# 保存按钮
ttk.Button(frame, text="保存设置",
command=self.save_settings).pack(pady=20)
# 新增提示文字(在此处添加)
tips_frame = ttk.LabelFrame(frame, text="使用提示", padding=10)
tips_frame.pack(pady=10, padx=20, fill=tk.X)
ttk.Label(tips_frame,
text="1. 请确保已安装方正小标宋简体字体",
font=(FONT_NAME, 12),
foreground="red").pack(anchor=tk.W, pady=2)
ttk.Label(tips_frame,
text="2. 如果API连接失败,请尝试设置HTTP代理",
font=(FONT_NAME, 12),
foreground="red").pack(anchor=tk.W, pady=2)
ttk.Label(tips_frame,
text="3. 在中国大陆使用时,需要代理才能连接DeepSeek API",
font=(FONT_NAME, 12),
foreground="red").pack(anchor=tk.W, pady=2)
# 版权信息
ttk.Label(frame,
text="wearer倾情制作,且用且珍惜",
font=(FONT_NAME, 12),
foreground="#666").pack(side=tk.BOTTOM, pady=20)
return frame
# ======================
# 新增:历史记录模块
# ======================
def create_history_frame(self):
"""创建历史记录界面"""
frame = ttk.Frame(self.canvas)
columns = ("时间", "文件名", "建议摘要")
self.history_tree = ttk.Treeview(frame, columns=columns, show="headings")
for col in columns:
self.history_tree.heading(col, text=col)
self.history_tree.column(col, width=200)
vsb = ttk.Scrollbar(frame, orient="vertical", command=self.history_tree.yview)
self.history_tree.configure(yscrollcommand=vsb.set)
self.history_tree.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
vsb.pack(side=tk.RIGHT, fill=tk.Y)
# 加载历史数据
for record in self.history:
self.history_tree.insert("", "end", values=(
record["time"],
record["file"],
record["suggestion"]
))
return frame
# ======================
# 改进:API验证与保存
# ======================
# 修改validate_api方法(约337行)
def validate_api(self):
"""验证API密钥有效性"""
api_key = self.api_var.get()
if not api_key:
messagebox.showerror("错误", "请输入API密钥")
return False
print(f"开始验证API密钥,长度: {len(api_key)}")
try:
print("创建OpenAI客户端...")
client = OpenAI(
api_key=api_key,
base_url="https://api.deepseek.com" # 修改为不带v1的基础URL
)
print("发送测试请求...")
# 使用更简单的测试请求
response = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": "1+1="}],
max_tokens=1
)
print(f"收到响应: {response}")
if response.choices:
print(f"响应内容: {response.choices[0].message.content}")
messagebox.showinfo("成功", "API密钥有效")
return True
except Exception as e:
error_msg = str(e)
print(f"API验证失败: {error_msg}")
import traceback
print(traceback.format_exc()) # 打印完整堆栈跟踪
if "402" in error_msg:
messagebox.showerror("失败", "账户余额不足,请充值")
elif "401" in error_msg:
messagebox.showerror("失败", "API密钥无效")
elif "connect" in error_msg.lower():
messagebox.showerror("失败", "网络连接错误,无法连接到API服务器")
else:
messagebox.showerror("失败", f"验证失败: {error_msg}")
return False
# 修改save_settings方法
def save_settings(self):
"""保存设置到配置文件"""
try:
# 从StringVar获取API密钥
self.config["api_key"] = self.api_var.get()
# 保存代理设置
self.config["http_proxy"] = self.proxy_var.get()
# 保存模型设置
self.config["model"] = self.model_var.get()
print(f"保存设置: API密钥长度={len(self.config['api_key'])}, 代理={self.config['http_proxy']}, 模型={self.config['model']}")
# 应用代理设置
if self.config["http_proxy"]:
os.environ["http_proxy"] = self.config["http_proxy"]
os.environ["https_proxy"] = self.config["http_proxy"]
print(f"已设置代理: {self.config['http_proxy']}")
else:
# 清除代理设置
if "http_proxy" in os.environ:
del os.environ["http_proxy"]
if "https_proxy" in os.environ:
del os.environ["https_proxy"]
print("已清除代理设置")
# 重新初始化AI客户端
try:
self.ai_client = OpenAI(
api_key=self.config["api_key"],
base_url="https://api.deepseek.com" # 使用不带v1的基础URL
)
print("已重新初始化AI客户端")
except Exception as e:
print(f"重新初始化AI客户端失败: {str(e)}")
# 确保使用正确的文件打开模式
with open(CONFIG_FILE, "w", encoding="utf-8") as f:
json.dump(self.config, f, ensure_ascii=False, indent=2)
messagebox.showinfo("成功", "设置已保存")
except Exception as e:
print(f"保存设置失败: {str(e)}")
import traceback
print(traceback.format_exc())
messagebox.showerror("错误", f"保存失败: {str(e)}")
def check_api_key(self):
"""启动时检查API密钥"""
if not self.config.get("api_key"):
messagebox.showwarning("提示", "请先在设置中配置API密钥")
self.show_settings()
# ======================
# 改进:提示词优化
# ======================
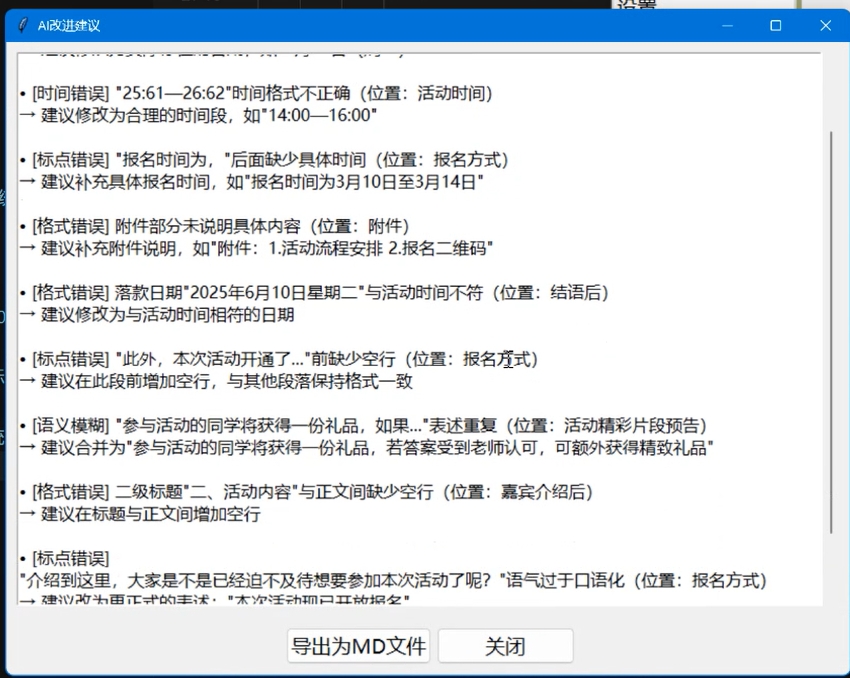
def generate_ai_suggestions(self):
"""生成并显示AI建议"""
try:
print("开始生成AI建议...")
api_key = self.config.get("api_key", "")
if not api_key:
print("缺少API密钥,无法生成建议")
messagebox.showerror("错误", "请先在设置中配置API密钥")
return
# 确保使用最新API配置
print(f"使用API密钥(长度: {len(api_key)})创建OpenAI客户端")
self.ai_client = OpenAI(
api_key=api_key,
base_url="https://api.deepseek.com" # 修改为不带v1的基础URL
)
# 提取文档内容(跳过标题段落)
content = "\n".join(p.text for p in self.doc.paragraphs[3:] if p.text.strip())[:1000]
print(f"提取文档内容,长度: {len(content)}")
# 构造系统提示词
system_prompt = (
"""你是一个专业的公文校对助手,请严格检查以下内容:
1. 错别字和标点错误
2. 语法不通顺的句子
3. 不符合公文格式的内容
4. 语义模糊需要明确的地方
请按以下格式反馈:
• [错误类型] 具体问题描述(位置:第X段)
→ 修改建议
示例:
• [标点错误] 句末缺少标点(位置:第3段第2行)
→ 建议在句尾添加句号"""
)
print("发送API请求...")
print(f"系统提示词长度: {len(system_prompt)}")
print(f"用户内容长度: {len(content)}")
# 在API调用中使用配置的模型名称
model_name = self.config.get("model", "deepseek-chat")
print(f"使用模型: {model_name}")
# 尝试使用完整URL路径
try:
# 调用API
response = self.ai_client.chat.completions.create(
model=model_name, # 使用配置中的模型名称
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"请分析以下文档:\n{content}"}
],
temperature=0.3,
max_tokens=500,
timeout=30 # 增加超时设置
)
print(f"收到API响应: {response}")
# 处理响应
if response.choices:
self.ai_suggestion = response.choices[0].message.content
print(f"建议内容长度: {len(self.ai_suggestion)}")
self.show_ai_suggestion()
else:
print("API响应中没有内容")
self.ai_suggestion = "API返回了空响应,请稍后再试。"
self.show_ai_suggestion()
except Exception as e:
error_msg = str(e)
print(f"第一次API请求失败: {error_msg}")
# 如果失败,尝试使用带/v1的URL
try:
print("尝试使用带/v1的URL重新连接...")
backup_client = OpenAI(
api_key=api_key,
base_url="https://api.deepseek.com/v1"
)
response = backup_client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "简短回复"},
{"role": "user", "content": "测试连接"}
],
max_tokens=10,
timeout=30
)
print(f"备用URL测试成功: {response}")
# 再次尝试完整请求
response = backup_client.chat.completions.create(
model=model_name, # 使用配置中的模型名称
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"请分析以下文档:\n{content}"}
],
temperature=0.3,
max_tokens=500,
timeout=30
)
if response.choices:
self.ai_suggestion = response.choices[0].message.content
self.show_ai_suggestion()
else:
self.ai_suggestion = "API返回了空响应,请稍后再试。"
self.show_ai_suggestion()
except Exception as e2:
print(f"备用URL尝试也失败: {str(e2)}")
raise Exception(f"两种URL都尝试失败: {str(e)} 和 {str(e2)}")
except Exception as e:
error_msg = str(e)
print(f"生成AI建议失败: {error_msg}")
import traceback
print(traceback.format_exc()) # 打印完整堆栈跟踪
# 精准错误分类
if "401" in error_msg:
msg = "API密钥无效"
elif "402" in error_msg:
msg = "账户余额不足,请充值"
elif "429" in error_msg:
msg = "请求过于频繁,请稍后再试"
elif "404" in error_msg:
msg = "API端点不存在,请检查URL"
elif "connect" in error_msg.lower():
msg = "网络连接错误,无法连接到API服务器"
else:
msg = f"错误详情:{error_msg}"
messagebox.showerror("AI错误",
f"生成建议失败:{msg}\n"
"请检查:\n"
"1. API密钥是否正确\n"
"2. 网络连接是否正常\n"
"3. 账户余额是否充足"
)
def show_ai_suggestion(self):
"""显示AI建议对话框"""
ai_window = tk.Toplevel(self.root)
ai_window.title("AI改进建议")
ai_window.geometry("800x600")
text_area = scrolledtext.ScrolledText(
ai_window,
wrap=tk.WORD,
font=(FONT_NAME, FONT_SIZE - 2))
text_area.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)
text_area.insert(tk.END, self.ai_suggestion)
text_area.config(state=tk.DISABLED)
btn_frame = ttk.Frame(ai_window)
btn_frame.pack(pady=10)
ttk.Button(btn_frame, text="导出为MD文件",
command=self.export_md).pack(side=tk.LEFT, padx=5)
ttk.Button(btn_frame, text="关闭",
command=ai_window.destroy).pack(side=tk.LEFT)
def export_md(self):
"""导出为Markdown文件"""
save_path = filedialog.asksaveasfilename(
defaultextension=".md",
filetypes=[("Markdown文件", "*.md")]
)
if save_path:
try:
with open(save_path, "w", encoding="utf-8") as f:
f.write(f"# AI改进建议\n\n{self.ai_suggestion}")
messagebox.showinfo("成功", "文件已保存")
except Exception as e:
messagebox.showerror("错误", f"导出失败: {str(e)}")
# ======================
# 界面切换功能
# ======================
def show_main(self):
self.switch_frame(self.main_frame)
def show_history(self):
self.switch_frame(self.history_frame)
def show_settings(self):
self.switch_frame(self.settings_frame)
# 确保API输入框可以正常输入
self.root.after(100, lambda: self.api_entry.config(state='normal'))
# 修改switch_frame方法
def switch_frame(self, frame):
"""切换功能面板"""
if self.current_frame is not None: # 更严格的空值判断
self.current_frame.place_forget()
frame.place(x=180, y=20, width=820, height=650)
self.current_frame = frame
# 在类的最后添加run方法
def run(self):
"""启动程序"""
self.root.mainloop()
def enable_api_entry(self):
"""确保API输入框可以正常输入"""
if self.api_entry:
self.api_entry.config(state='normal')
def ensure_title_format(self):
"""确保标题格式正确,不被其他处理步骤覆盖"""
try:
# 查找文档中的标题段落
for i, para in enumerate(self.doc.paragraphs):
# 如果是第一个非空段落,认为是标题
if i == 0 or (i == 1 and not self.doc.paragraphs[0].text.strip()):
if para.text.strip():
print(f"重新应用标题格式: '{para.text}'")
# 重新应用标题样式
para.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中对齐
para.paragraph_format.first_line_indent = Cm(0) # 取消首行缩进
para.paragraph_format.line_spacing = Pt(29) # 行间距29磅
# 应用字体样式
for run in para.runs:
run.font.name = "方正小标宋简体"
run._element.rPr.rFonts.set(qn("w:eastAsia"), "方正小标宋简体")
run.font.size = Pt(22) # 二号字体为22磅
run.font.color.rgb = RGBColor(0, 0, 0)
# 检查是否有多行标题(通过样式判断)
elif para.style and para.style.name == "Title":
print(f"重新应用多行标题格式: '{para.text}'")
# 重新应用标题样式
para.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中对齐
para.paragraph_format.first_line_indent = Cm(0) # 取消首行缩进
para.paragraph_format.line_spacing = Pt(29) # 行间距29磅
# 应用字体样式
for run in para.runs:
run.font.name = "方正小标宋简体"
run._element.rPr.rFonts.set(qn("w:eastAsia"), "方正小标宋简体")
run.font.size = Pt(22) # 二号字体为22磅
run.font.color.rgb = RGBColor(0, 0, 0)
# 通过字体名称判断是否为标题
else:
for run in para.runs:
if hasattr(run._element, 'rPr') and hasattr(run._element.rPr, 'rFonts'):
east_asia_font = run._element.rPr.rFonts.get(qn('w:eastAsia'))
if east_asia_font and "方正小标宋" in east_asia_font:
print(f"通过字体检测到标题段落: '{para.text}'")
# 重新应用标题样式
para.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中对齐
para.paragraph_format.first_line_indent = Cm(0) # 取消首行缩进
para.paragraph_format.line_spacing = Pt(29) # 行间距29磅
# 应用字体样式
run.font.name = "方正小标宋简体"
run._element.rPr.rFonts.set(qn("w:eastAsia"), "方正小标宋简体")
run.font.size = Pt(22) # 二号字体为22磅
run.font.color.rgb = RGBColor(0, 0, 0)
break
print("标题格式确认完成")
except Exception as e:
print(f"确保标题格式失败: {str(e)}")
import traceback
print(traceback.format_exc()) # 打印完整堆栈跟踪
if __name__ == "__main__":
app = DocFormatter()
app.run()
(共计1772行)
代码已经上传至gitee
六、实验结果
1.实验视频:
-
源代码的运行演示:
-
打包后的exe程序的运行演示:
基于python-docx库及接入deepseekapi实现docx文件格式自动修改和润色建议_2
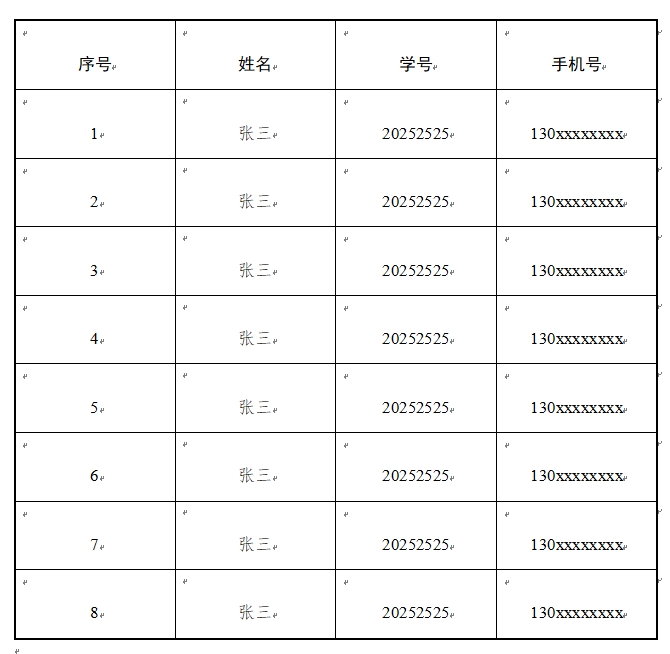
2.运行前后文件对比:
前:

后:

3.ai润色的md文件:

七、实验感悟与课程总结
从最开始的"hello world!"再到通过编程来实现各种“不可思议”的功能,凝结了无数人的智慧。生活处处充满了编程的影子,让我们不禁感慨于“编程改变了生活”。从现实生活的抽象逻辑中剥离出本质,再将它们交由机器代劳,这是我对编程的理解。
再说回我的此次试验吧,我的理想是丰满的,但现实是残酷的。对于本次实验的库和一些操作,我还属于“未开化”阶段,无从下手。只能求教于ai和同学,一点一点边学边写。中间把deepseek整崩溃过,也把自己整崩溃过。写写停停,愈挫愈勇,拉锯了一个月后,难产的孩子才终于见了人间。程序真的跑通那一刻,喜悦之情无以言表。
提及python这门课和王老师,我是充满感激和激动的。王老师事无巨细带着我们做实践写代码,事无巨细的回答同学们的问题,对实验设计提出宝贵的建议。最后一课的寄语让我印象深刻,“那些看似波澜不惊的日复一日,终将在某一天,让我们看到坚持的意义。”尽管python的课程告一段落,学习还是要继续的,希望自己能更加认真努力,创造更多的成果。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号