seq2seq
用序列学习方法创建语言翻译模型
大家好。自从我上一篇博客文章发布以来已经有很长一段时间了。这听起来像是一个借口,但我一直在努力寻找新的地方。我不得不说,对于外国人来说,在日本寻找一个合理的公寓真是个问题。幸运的是,我设法找到一个,我刚搬进来将近两个星期。无论如何,最艰难的时刻已经过去了,现在我可以让自己重新开始工作,带给你们一些关于深度学习的新的有趣的(也许是无聊的)博客文章。
因此,在我之前的博客文章中,我告诉过您如何通过训练递归神经网络模型来创建简单的文本生成器。RNN与正常神经网络的不同之处在于,RNN不是独立计算每个输入的输出预测,而是计算时间步长t的输出不仅使用时间步t的输入,还涉及先前时间步的输入(比如,时间步t - 1,t - 2,...)。
正如您在上一篇文章中看到的那样,输入实际上是字符序列,每个输出只是相应的输入向右移动了一个字符。显然,您可以看到每对输入序列和输出序列具有相同的长度。然后,使用着名的哈利波特作为训练数据集训练网络,结果,训练好的模型可以产生一些伟大的JK罗琳式段落。如果您尚未阅读我以前的帖子,请通过以下链接查看(请确保您在继续之前):
用递归神经网络创建文本生成器
但是这里有一个很大的问题:如果输入序列和输出序列有不同的长度怎么办?
您知道,存在许多类型的机器学习问题,其中输入和输出序列不一定具有完全相同的长度。就自然语言处理(或简称NLP)而言,您更有可能遇到长度完全不同的问题,不仅在每对输入和输出序列之间,而且在输入序列本身之间!例如,在构建语言翻译模型时,每对输入和输出序列都使用不同的语言,因此很可能它们的长度不同。而且,我可以打赌我的生活中没有已知的语言,我们可以创建具有完全相同长度的所有句子!显然,这是一个非常大的问题,因为我在上一篇文章中向您展示的模型要求所有输入和输出序列具有相同的长度。
答案是不。大问题只会吸引聪明人,因此不仅解决了一个问题,而且解决了许多问题。让我们回到我们的问题。进行了许多尝试,与其他人相比,他们每个人都有自己的优点和缺点。在今天的帖子中,我将向您介绍一种受到NLP社区极大关注的方法:序列到序列网络(或简称seq2seq),来自谷歌的Ilya Sutskever,Oriol Vinyals,Quoc V. Le的出色工作。
我将在下面简要介绍一下seq2seq背后的想法。对于想要深入了解最先进模型的人,请参阅本文末尾的论文链接。
在这一点上,我们已经知道我们必须处理的问题,即我们有不同长度的输入和输出序列。为了使问题变得更具体,让我们看一下下图:
数字
(从神经网络的序列到序列学习的原始论文剪切的图像)
如上图所示,我们将“ABC”作为输入序列,将“WXYZ”作为输出序列。显然,两个序列的长度是不同的。那么,seq2seq如何解决这个问题呢?答案是:他们创建了一个模型,它由两个独立的递归神经网络组成,分别称为编码器和解码器。为了方便您,我在下面绘制了一个简单的图表:

encode_decode
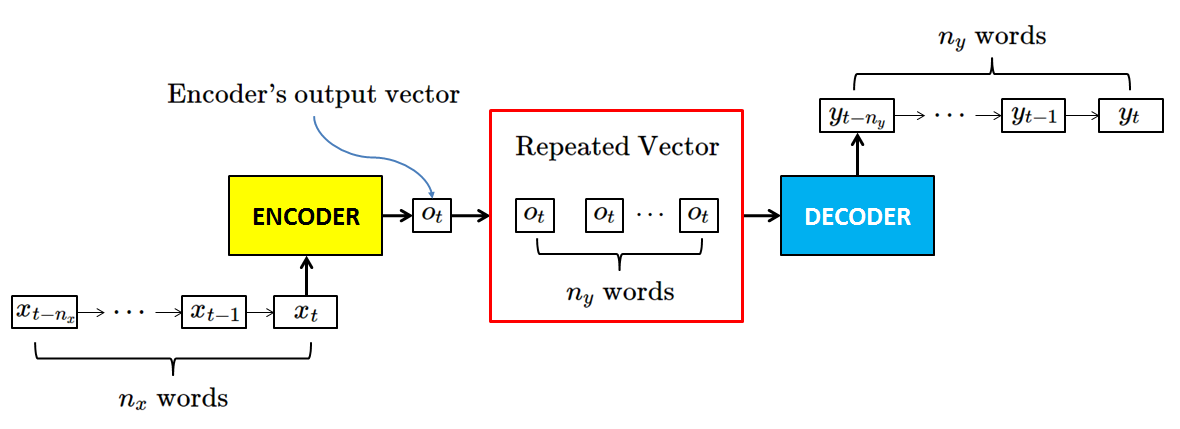
由于两个网络的名称在某种程度上是自我解释的,首先,很明显我们不能通过仅使用一个网络直接计算输出序列,因此我们需要使用第一个网络将输入序列编码为某种类型的“中间序列”,然后另一个网络将该序列解码为我们的期望输出序列。那么,“中间序列”是什么样的?我们来看看下面的下图:
repeated_vec
这个谜就揭晓了!具体来说,编码器实际上做的是从输入序列创建临时输出向量(您可以将该临时输出向量视为仅具有一个时间步长的序列)。然后,重复该向量n时间,与n是我们的欲望输出序列的长度。到目前为止,你可以得到所有其余的。是的,解码器网络的行为与我在上一篇文章中谈到的网络完全相同。重复编码器n的输出向量后我们可以获得一个与相关输出序列具有完全相同长度的序列,我们可以为解码器网络留下计算!这就是seq2seq背后的想法。它并不像看起来那么难,对吧?
所以我们现在知道如何从不同长度的输入输出序列。但是输入序列的长度呢?正如我上面提到的,输入序列本身也不一定具有完全相同的长度!听起来像是另一个头痛,不是吗?幸运的是,它比上面的问题更加放松。事实上,我们需要做的就是所谓的:零填充。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号