ORM框架-SQLAchemy使用
| 一、ORM简介 |
orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却都是关系型的,为了保证一致的使用习惯,通过orm将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用sql语言。
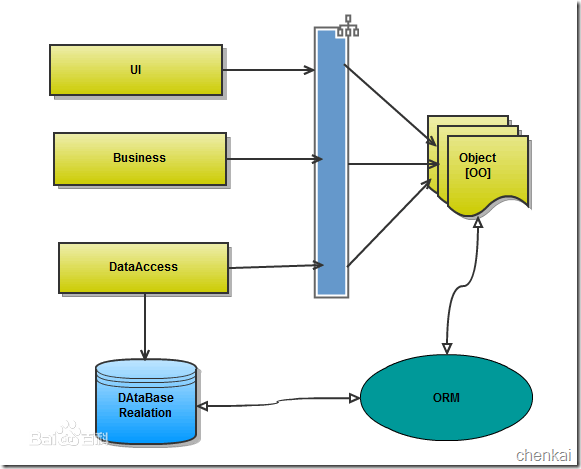
orm的优点:
- 隐藏了数据访问细节,“封闭”的通用数据库交互,ORM的核心。他使得我们的通用数据库交互变得简单易行,并且完全不用考虑该死的SQL语句。快速开发,由此而来。
- ORM使我们构造固化数据结构变得简单易行。
缺点:
- 无可避免的,自动化意味着映射和关联管理,代价是牺牲性能(早期,这是所有不喜欢ORM人的共同点)。现在的各种ORM框架都在尝试使用各种方法来减轻这块(LazyLoad,Cache),效果还是很显著的。
| 二、python中的orm框架(SQLAlchemy) |
ORM分为DB first和code first
DB first:手动创建数据库以及表-->ORM框架-->自动生成类
code first:手动创建类手动创建数据库-->ORM框架-->自动生成表,SQLAchemy属于code first
SQLAchemy
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
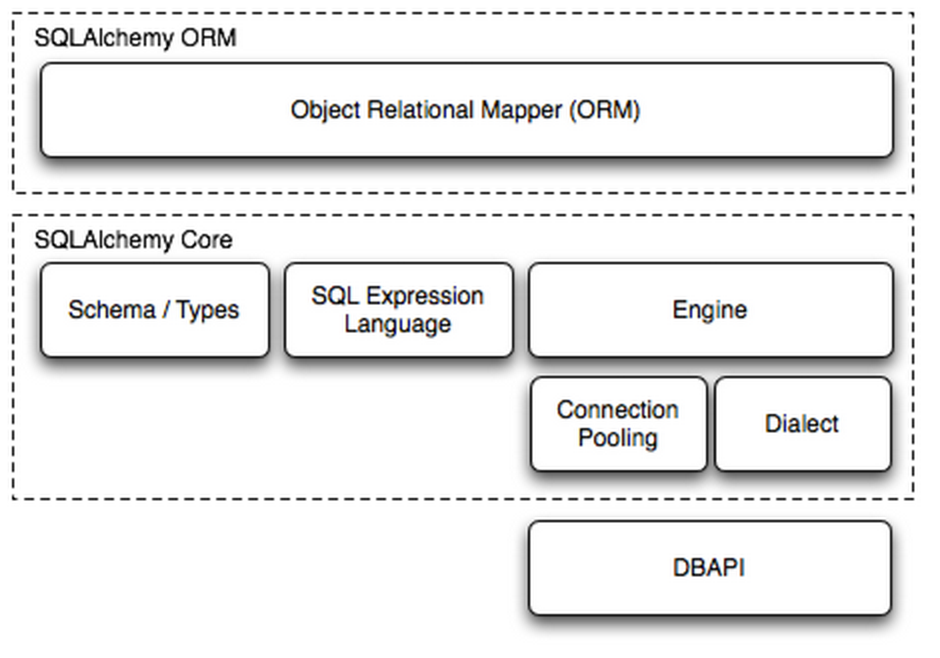
Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Python:
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>pymysql: mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]MySQL-Connector:
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>cx_Oracle: oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html| 三、sqlalchemy基本使用 |
安装
pip3 install sqlalchemy
注:SQLAlchemy无法修改表结构,如果需要可以使用SQLAlchemy开发者开源的另外一个软件Alembic来完成.
官网doc:http://docs.sqlalchemy.org/en/latest/core/expression_api.html
1.SQL使用
使用 Engine/ConnectionPooling/Dialect 进行数据库操作,Engine使用ConnectionPooling连接数据库,然后再通过Dialect执行SQL语句
demo:
#!/usr/bin/env python3 #_*_ coding:utf-8 _*_ #Author:wd from sqlalchemy import create_engine engine=create_engine("mysql+pymysql://stu:1234qwer@10.0.0.241:3307/student", max_overflow=5)#创建连接,允许溢出5个连接 result = engine.execute('select * from student')#使用excute执行原生sql print(result.fetchall())#获取所有结果,与pymyql类似
事务:
#!/usr/bin/env python3 #_*_ coding:utf-8 _*_ #Author:wd from sqlalchemy import create_engine engine=create_engine("mysql+pymysql://stu:1234qwer@10.0.0.241:3307/student", max_overflow=5)#创建连接,允许溢出5个连接 result = engine.execute('select * from student')#使用excute执行原生sql with engine.begin() as conn: #事务操作 conn.execute("insert into student (name, age, res_date) values ('weikang', 33, '1992-11-11')") print(result.fetchall())#获取所有结果,与pymyql类似
2.创建表
定义数据表,才能进行sql表达式的操作,毕竟sql表达式的表的确定,是sqlalchemy制定的,如果数据库已经存在了数据表还需要定义么?当然,这里其实是一个映射关系,如果不指定,查询表达式就不知道是附加在那个表的操作,当然定义的时候,注意表名和字段名,代码和数据的必须保持一致。定义好之后,就能创建数据表,一旦创建了,再次运行创建的代码,数据库是不会创建的。
sqlalchemy内部组件调用顺序为:使用 Schema Type/SQL Expression Language/Engine/ConnectionPooling/Dialect 进行数据库操作。Engine使用Schema Type创建一个特定的结构对象,之后通过SQL Expression Language将该对象转换成SQL语句,然后通过 ConnectionPooling 连接数据库,再然后通过 Dialect 执行SQL,并获取结果。
TIPS:使用类的方式和使用metadata方式创建表时候区别在于metadata可以不指定主键,而是用class方式必须要求有主键。
demo1:
from sqlalchemy import create_engine,Table,Column,Integer,String,ForeignKey,MetaData engine=create_engine("mysql+pymysql://stu:1234qwer@10.0.0.241:3307/student?charset=gbk", encoding="utf-8", echo=True, max_overflow=5 ) #?charset是字符集编码,echo=True打印输出信息和执行的sql语句默认Flase,max_overflow=5允许溢出连接池连接数量 meta=MetaData()#生成源类 #定义表结构 user=Table('user',meta, Column('id',Integer,nullable=Table,autoincrement=True,primary_key=True), Column('name',String(20),nullable=True), Column('age',Integer,nullable=True) ) host=Table('host',meta, Column('ip',String(20),nullable=True), Column('hostname',String(20),nullable=True), ) meta.create_all(engine)#创建表,如果存在则忽视
demo2:
使用orm基类创建
#!/usr/bin/env python3 #_*_ coding:utf-8 _*_ #Author:wd from sqlalchemy import create_engine,Table,Column,Integer,String,ForeignKey,MetaData,Date from sqlalchemy.ext.declarative import declarative_base engine=create_engine("mysql+pymysql://stu:1234qwer@10.0.0.241:3307/student?charset=gbk", encoding="utf-8", echo=True, max_overflow=5 ) #?charset是字符集编码,echo=True打印输出信息和执行的sql语句默认Flase,max_overflow=5允许溢出连接池连接数量 base=declarative_base()#生成ORM基类 #定义表结构 class User(base): __tablename__='book' #表明 id = Column(Integer, primary_key=True) name=Column(String(32)) date=Column(Date) base.metadata.create_all(engine)#创建表,如果存在则忽视
demo3:使用orm中的mapper创建,其实上面表的创建方式是封装了mapper
#!/usr/bin/env python3 #_*_ coding:utf-8 _*_ #Author:wd from sqlalchemy import create_engine,Table,Column,Integer,String,ForeignKey,MetaData,Date from sqlalchemy.orm import mapper engine=create_engine("mysql+pymysql://stu:1234qwer@10.0.0.241:3307/student?charset=gbk", encoding="utf-8", echo=True, max_overflow=5 ) #?charset是字符集编码,echo=True打印输出信息和执行的sql语句默认Flase,max_overflow=5允许溢出连接池连接数量 meta=MetaData() #定义表结构 person=Table('person',meta, Column('id',primary_key=True), Column('name',String(20)), Column('age',String(20)), ) class people(object): def __init__(self,id,name,age): self.id=id self.name=name self.age=age mapper(people,person)#将类和表映射起来,把类和表关键
2.通过orm对数据进行增删改查。
使用sqlalchemy进行增删改茶之前需要映射表,然后才可以进行相应的操作。
增:
#!/usr/bin/env python3 #_*_ coding:utf-8 _*_ #Author:wd from sqlalchemy import create_engine,Table,Column,Integer,String,ForeignKey from sqlalchemy.orm import sessionmaker from sqlalchemy.ext.declarative import declarative_base engine=create_engine("mysql+pymysql://stu:1234qwer@10.0.0.241:3307/student?charset=gbk", max_overflow=5, echo=True) #数据库连接信息为,连接类型://用户名:密码@数据库地址:端口/数据库名字?编码 #max_overflow创建连接,允许溢出5个连接,echo=True,输出相应的sql信息到控制台,方便调试。 base=declarative_base()#生成orm基类 class user(base): #映射表 __tablename__='user' id=Column(Integer,autoincrement=True,primary_key=True) name=Column(String(20)) age=Column(Integer) sessoion_class=sessionmaker(bind=engine)#创建与数据库的会话类,这里的sessoion_class是类 Session=sessoion_class()#生成会话实例 user1=user(name='wd',age=22)#生成user对象 Session.add(user1) #添加user1,可以使用add_all,参数为列表或者tuple Session.commit() #提交 #Session.rollback() #回滚 Session.close() #关闭会话
查:
常用查询语法:


Common Filter Operators Here’s a rundown of some of the most common operators used in filter(): equals: query.filter(User.name == 'ed') not equals: query.filter(User.name != 'ed') LIKE: query.filter(User.name.like('%ed%')) IN: NOT IN: query.filter(~User.name.in_(['ed', 'wendy', 'jack'])) IS NULL: IS NOT NULL: AND: 2.1. ObjectRelationalTutorial 17 query.filter(User.name.in_(['ed', 'wendy', 'jack'])) # works with query objects too: query.filter(User.name.in_( session.query(User.name).filter(User.name.like('%ed%')) )) query.filter(User.name == None) # alternatively, if pep8/linters are a concern query.filter(User.name.is_(None)) query.filter(User.name != None) # alternatively, if pep8/linters are a concern query.filter(User.name.isnot(None)) SQLAlchemy Documentation, Release 1.1.0b1 # use and_() from sqlalchemy import and_ query.filter(and_(User.name == 'ed', User.fullname == 'Ed Jones')) # or send multiple expressions to .filter() query.filter(User.name == 'ed', User.fullname == 'Ed Jones') # or chain multiple filter()/filter_by() calls query.filter(User.name == 'ed').filter(User.fullname == 'Ed Jones') Note: Makesureyouuseand_()andnotthePythonandoperator! • OR: Note: Makesureyouuseor_()andnotthePythonoroperator! • MATCH: query.filter(User.name.match('wendy')) Note: match() uses a database-specific MATCH or CONTAINS f
#!/usr/bin/env python3 #_*_ coding:utf-8 _*_ #Author:wd from sqlalchemy import create_engine,Table,Column,Integer,String,ForeignKey from sqlalchemy.orm import sessionmaker from sqlalchemy.ext.declarative import declarative_base engine=create_engine("mysql+pymysql://stu:1234qwer@10.0.0.241:3307/student?charset=gbk", max_overflow=5, echo=True) #数据库连接信息为,连接类型://用户名:密码@数据库地址:端口/数据库名字?编码 #max_overflow创建连接,允许溢出5个连接,echo=True,输出相应的sql信息到控制台,方便调试。 base=declarative_base()#生成orm基类 class user(base): #映射表 __tablename__='user' id=Column(Integer,autoincrement=True,primary_key=True) name=Column(String(20)) age=Column(Integer) def __repr__(self): #定义 return "(%s,%s,%s)" % (self.id,self.name,self.age) sessoion_class=sessionmaker(bind=engine)#创建与数据库的会话类,这里的sessoion_class是类 Session=sessoion_class()#生成会话实例 #data=Session.query(user).get(2) #get语法获取primrykey中的关键字,在这里主键为id,获取id为2的数据 #data=Session.query(user).filter(user.age>22,user.name=='mack').first() #filter语法两个等于号,filter_by语法一个等于号,可以有多个filter,如果多个数据返回列表,first代表获取第一个,为all()获取所有 data=Session.query(user).filter(user.age>20,user.name.in_(['mack','wd'])).all()#in语法 print(data[0]) #打印第一个结果 Session.commit() #提交,如果回滚的话,数据将不存在了 Session.close() #关闭会话
修改
#data=Session.query(user).filter(user.age>20).update({"name":'jarry'})#update语法 data=Session.query(user).filter(user.age==22).first()#面向对象语法 data.name='coco'#如果data中数据多条需要使用for循环设置 Session.commit() #提交 Session.close() #关闭会话
删除:
data=Session.query(user).filter(user.age==33).delete() Session.commit() #提交 Session.close() #关闭会话
获取所有数据:
data=Session.query(user).all()#获取user表所有数据 for i in data: print(i) Session.commit() #提交 Session.close() #关闭会话
统计:
#count=Session.query(user).count()#获取所有的条数 count=Session.query(user).filter(user.name.like("ja%")).count()#获取某些条数 print(count) Session.commit() #提交 Session.close() #关闭会话
分组:
from sqlalchemy import func#需要导入func函数 res=Session.query(func.count(user.name),user.name).group_by(user.name).all() print(res) Session.commit() #提交 Session.close() #关闭会话
3.外键关联
TIPS:设置外检的另一种方式 ForeignKeyConstraint(['other_id'], ['othertable.other_id'])
#!/usr/bin/env python3 #_*_ coding:utf-8 _*_ #Author:wd from sqlalchemy import create_engine,Table,Column,Integer,String,ForeignKey from sqlalchemy.orm import sessionmaker from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import relationship engine=create_engine("mysql+pymysql://stu:1234qwer@10.0.0.241:3307/student?charset=gbk", encoding="utf-8", echo=True, max_overflow=5 ) #?charset是连接数据库的字符集编码(和数据库的编码一样),echo=True打印输出信息和执行的sql语句默认Flase,max_overflow=5允许溢出连接池连接数量 Base=declarative_base() class user(Base): __tablename__='user' id=Column(Integer,primary_key=True,autoincrement=True) name=Column(String(20)) age=Column(Integer) def __repr__(self): return "<id:%s,name:%s,age:%s>"%(self.id,self.name,self.age) class host(Base): __tablename__='host' user_id=Column(Integer,ForeignKey('user.id'))#user_id关联user表中的id hostname=Column(String(20)) ip=Column(String(20),primary_key=True) host_user=relationship('user',backref='user_host') #通过host_user查询host表中关联的user信息,通过user_host,在user表查询关联的host,与生成的表结构无关,只是为了方便查询 def __repr__(self): return "<user_id:%s,hostname:%s,ip:%s>"%(self.user_id,self.hostname,self.ip) Base.metadata.create_all(engine) Session_class=sessionmaker(bind=engine) Session=Session_class() host1=Session.query(host).first() print(host1.host_user) print(host1) user1=Session.query(user).first() print(user1.user_host)
4.多外键关联一个表中的一个字段
应用场景:当我们购物时候,你会发现有一个收发票地址,和一个收货地址。关系如下:默认情况下,发票地址和收获地址是一致的,但是也有可能我想买东西送给别人,而发票要自己留着,那收货的地址和寄送发票的地址可以不同。即:同一个人的两个收获地址可以不同,多个收获地址关联同一个人。
demo:
#!/usr/bin/env python3 #_*_ coding:utf-8 _*_ #Author:wd from sqlalchemy import Integer, ForeignKey, String, Column from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import relationship Base = declarative_base() class Customer(Base): __tablename__ = 'customer' id = Column(Integer, primary_key=True) name = Column(String) billing_address_id = Column(Integer, ForeignKey("address.id")) shipping_address_id = Column(Integer, ForeignKey("address.id")) billing_address = relationship("Address", foreign_keys=[billing_address_id]) shipping_address = relationship("Address", foreign_keys=[shipping_address_id]) #同时关联同一个字段,使用relationship需要指定foreign_keys,为了让sqlalchemy清楚关联的外键 class Address(Base): __tablename__ = 'address' id = Column(Integer, primary_key=True) street = Column(String) city = Column(String) state = Column(String)
5.多对多外键关联
很多时候,我们会使用多对多外键关联,例如:书和作者,学生和课程,即:书可以有多个作者,而每个作者可以写多本书,orm提供了更简单方式操作多对多关系,在进行删除操作的时候,
orm会自动删除相关联的数据。
表结构创建:
#!/usr/bin/env python3 #_*_ coding:utf-8 _*_ #Author:wd from sqlalchemy import Column,Table,String,Integer,ForeignKey from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import create_engine from sqlalchemy.orm import relationship engine=create_engine("mysql+pymysql://stu:1234qwer@10.0.0.241:3307/student?charset=gbk", encoding="utf-8", echo=True, max_overflow=5 ) Base=declarative_base() stu_cour=Table('stu_cour',Base.metadata, Column('stu_id',Integer,ForeignKey('student.id')), Column('cour_id',Integer,ForeignKey('course.id')) ) class student(Base): __tablename__='student' id=Column(Integer,autoincrement=True,primary_key=True) stu_name=Column(String(32)) stu_age=Column(String(32)) courses=relationship('course',secondary=stu_cour,backref='students') #course是关联的第一张表,stu_cour是关联的第二张表,当然,也可以在第三张关联表中使用两个relationship关联student表和course表 def __repr__(self): return '<%s>'%self.stu_name class course(Base): __tablename__='course' id=Column(Integer,autoincrement=True,primary_key=True) cour_name=Column(String(32)) def __repr__(self): return '<%s>'%self.cour_name Base.metadata.create_all(engine)
插入数据:
#!/usr/bin/env python3 #_*_ coding:utf-8 _*_ #Author:wd from sqlalchemy import Column,Table,String,Integer,ForeignKey from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import create_engine from sqlalchemy.orm import relationship from sqlalchemy.orm import sessionmaker engine=create_engine("mysql+pymysql://stu:1234qwer@10.0.0.241:3307/student?charset=gbk", encoding="utf-8", echo=True, max_overflow=5 ) Base=declarative_base() stu_cour=Table('stu_cour',Base.metadata, Column('stu_id',Integer,ForeignKey('student.id')), Column('cour_id',Integer,ForeignKey('course.id')) ) class student(Base): __tablename__='student' id=Column(Integer,autoincrement=True,primary_key=True) stu_name=Column(String(32)) stu_age=Column(String(32)) courses=relationship('course',secondary=stu_cour,backref='students') #course是关联的第一张表,stu_cour是关联的第二张表,当然,也可以在第三张关联表中使用两个relationship关联student表和course表 def __repr__(self): return '<%s>'%self.stu_name class course(Base): __tablename__='course' id=Column(Integer,autoincrement=True,primary_key=True) cour_name=Column(String(32)) def __repr__(self): return '<%s>'%self.cour_name stu1=student(stu_name='wd',stu_age='22') stu2=student(stu_name='jack',stu_age=33) stu3=student(stu_name='rose',stu_age=18) c1=course(cour_name='linux') c2=course(cour_name='python') c3=course(cour_name='go') stu1.courses=[c1,c2] #添加学生课程关联 stu2.courses=[c1] stu3.courses=[c1,c2,c3] session_class=sessionmaker(bind=engine) session=session_class() session.add_all([stu1,stu2,stu3,c1,c2,c3]) session.commit()
使用查询:
session_class=sessionmaker(bind=engine) session=session_class() stu_obj=session.query(student).filter(student.stu_name=='wd').first() print(stu_obj.courses)#查询wd学生所报名的课程 cour_obj=session.query(course).filter(course.cour_name=='python').first() print(cour_obj.students)#查询报名python课程所对应的课程 session.commit()
删除多对多:
session_class=sessionmaker(bind=engine) session=session_class() cour_obj=session.query(course).filter(course.cour_name=='python').first() session.delete(cour_obj)#删除python课程 session.commit()
| 四、sqlalchemy拾遗 |
更新中...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号