思路
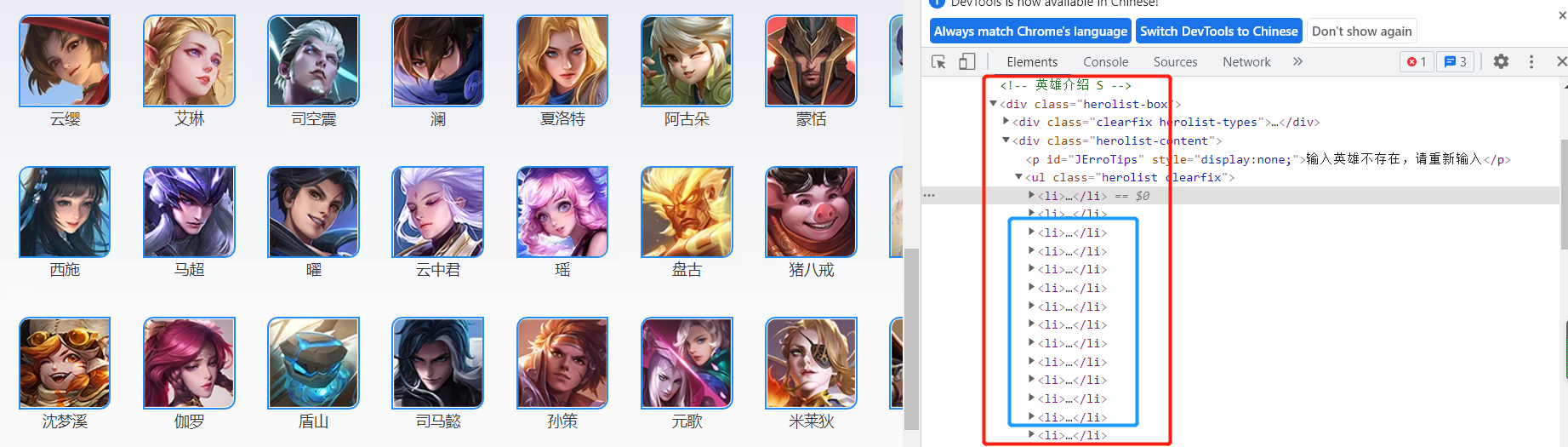
登录英雄页,每个英雄就是一个li标签,使用xpath获取
![]()
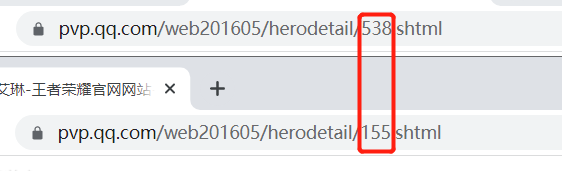
进入详情页,观察链接,发现只有英雄编号不同
![]()
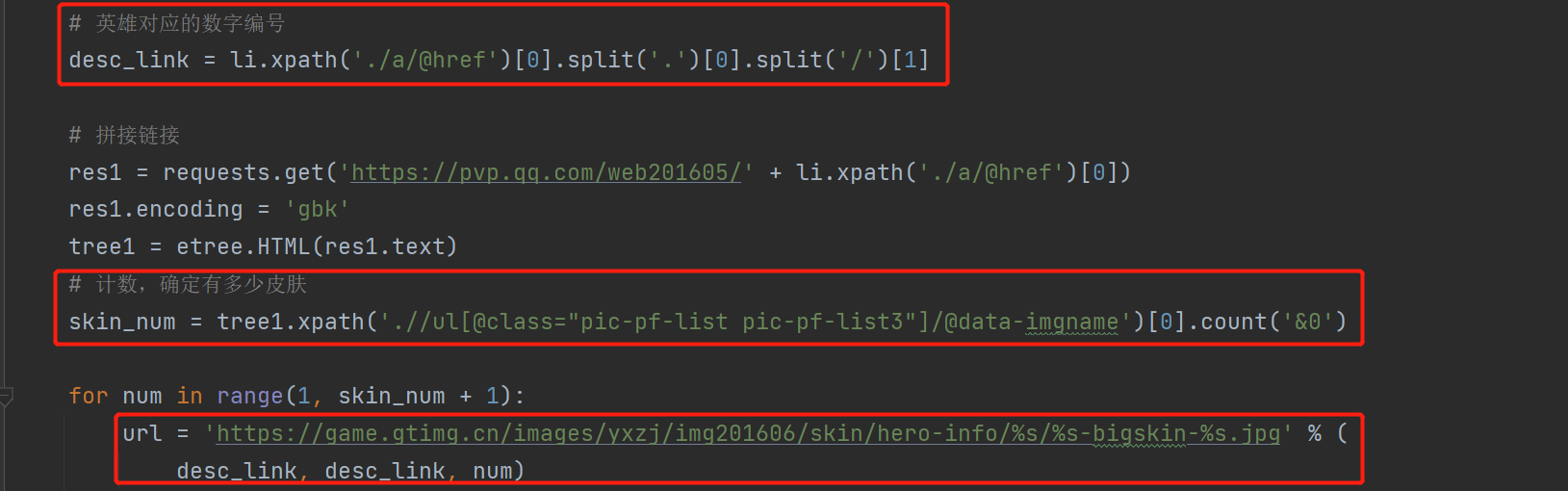
可以从之前获取的li标签中获取到英雄编号
![]()
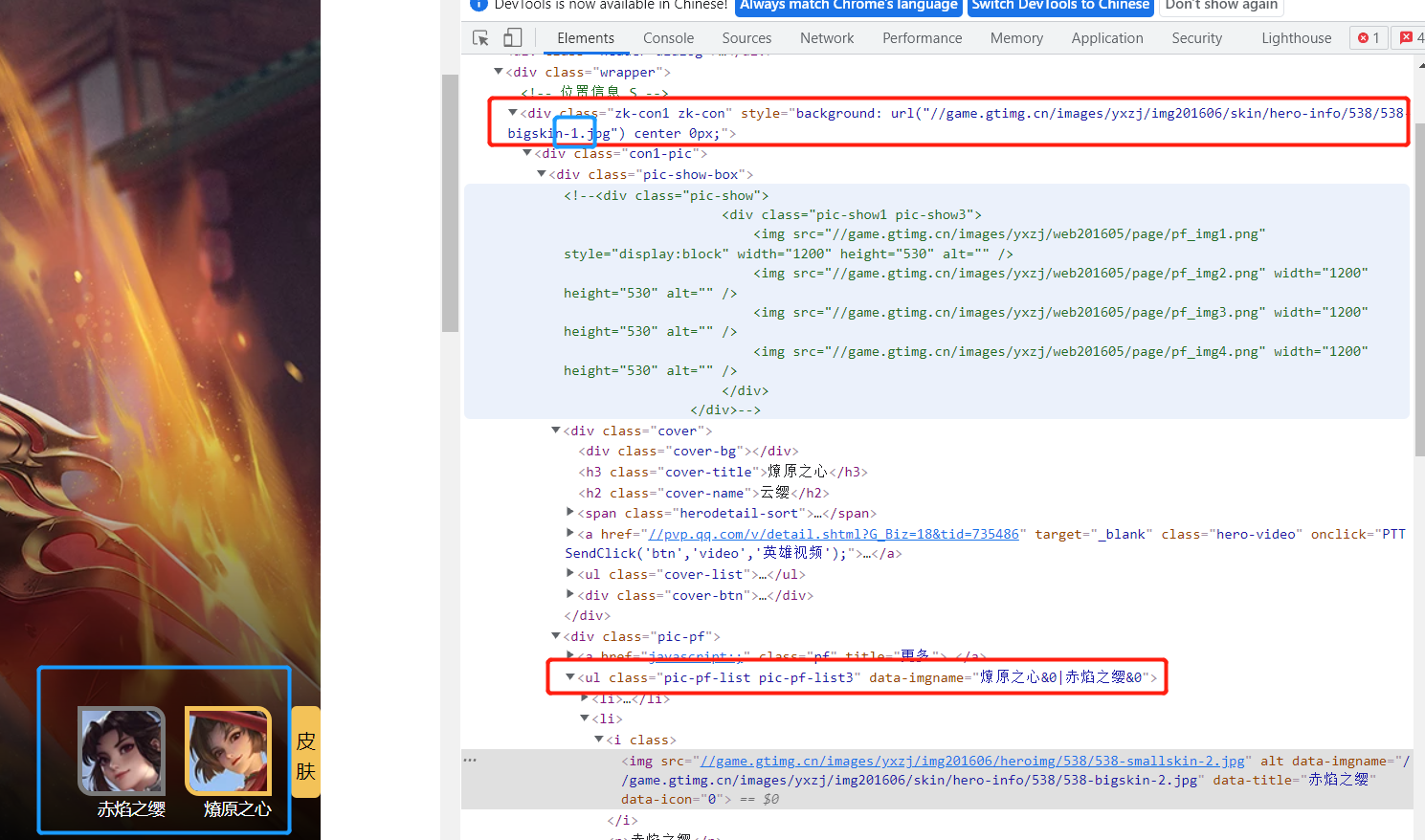
进入详情页,点击下方切换,发现图片链接所在位置以及链接的变化:数字从1开始变化,具体的数量可以使用count(&0)的方法获取
![]()
本次代码运行前需要配置字符编码格式
![]()
拼接出完整的链接
![]()
代码
import requests
import os
from lxml import etree
import time
# 判断文件夹存在
if not os.path.exists(r'wzry_skin'):
os.mkdir(r'wzry_skin')
res = requests.get('https://pvp.qq.com/web201605/herolist.shtml')
# 字符编码
res.encoding = 'gbk'
# print(res.text)
tree = etree.HTML(res.text)
# 找有英雄的li标签
li_list = tree.xpath('//*[@class="herolist-box"]/div[2]/ul[1]/li')
for li in li_list:
# 英雄对应的数字编号
desc_link = li.xpath('./a/@href')[0].split('.')[0].split('/')[1]
# 拼接链接
res1 = requests.get('https://pvp.qq.com/web201605/' + li.xpath('./a/@href')[0])
res1.encoding = 'gbk'
tree1 = etree.HTML(res1.text)
# 计数,确定有多少皮肤
skin_num = tree1.xpath('.//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[0].count('&0')
for num in range(1, skin_num + 1):
url = 'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/%s/%s-bigskin-%s.jpg' % (
desc_link, desc_link, num)
name = tree1.xpath('.//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[0].split('|')[num - 1].strip(
'&0')
print(name)
res2 = requests.get(url)
img = res2.content
file_path = os.path.join(r'wzry_skin', '%s.jpg' % name)
with open(file_path, 'wb')as f:
f.write(img)
time.sleep(0.5)
![]()





 浙公网安备 33010602011771号
浙公网安备 33010602011771号