

梨视频多页视频数据爬取
思路
登录网页,观察到向下拉动网页时,会出现不同的内部请求文件,
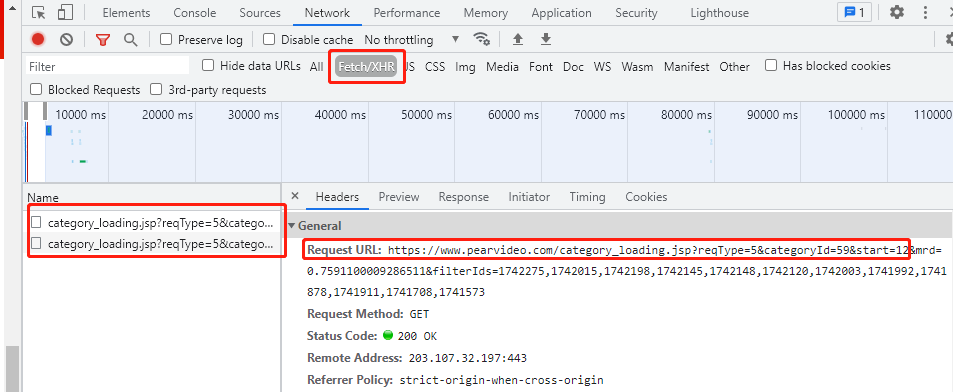
向如上图框选的地址发送请求,获取到只有html的界面
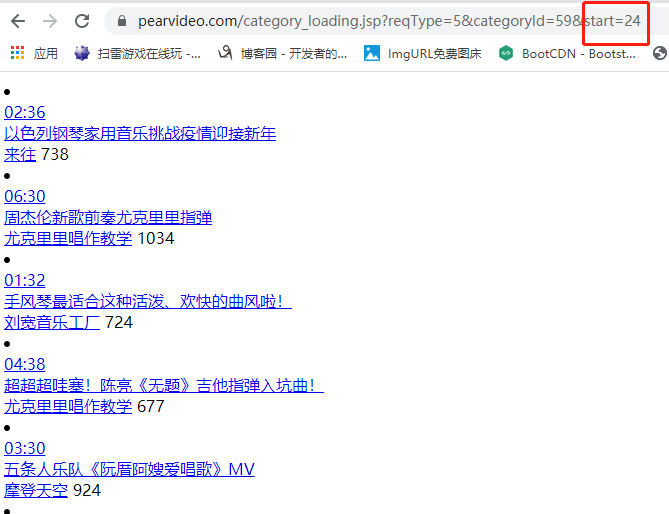
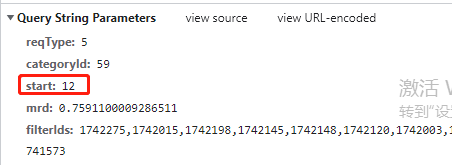
根据params数据可以看出start对应的数据决定了出现的视频。
回到视频详情页,根据Preview获取到视频对应的srcUrl,和中间需要替换的数据:systemTime
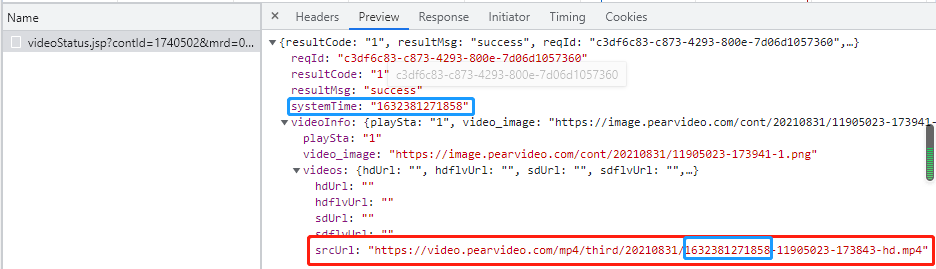
把systemTime替换成condid

向替换完之后的网址发送请求,访问到视频数据,但是访问失败,因为有防盗链。
看到referer键,可知是有防盗链的。

在requests请求中设置params和headers就可以访问了。
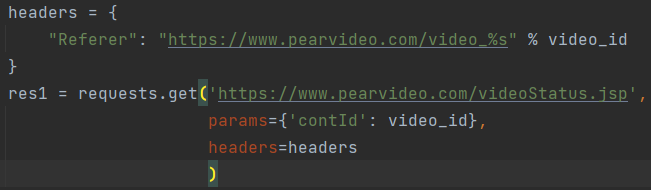
代码
import requests
from bs4 import BeautifulSoup
import os
import time
if not os.path.exists(r'梨视频数据'):
os.mkdir(r'梨视频数据')
def get_video(n):
# 1.先朝一个固定的url发送请求 获取到只有html标签的页面 重点描述分析过程
res = requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=31&start=%s' % n)
# 2.解析页面数据获取到详情页的链接地址
soup = BeautifulSoup(res.text, 'lxml')
# 3.研究视频详情链接
li_list = soup.select('li.categoryem')
# 4.循环获取每个li里面的a标签
for li in li_list:
a_tag = li.find(name='a')
a_href_link = a_tag.get('href') # video_1742158
# 通过研究发现详情页数据是动态加载的 所以通过network获取到地址
video_id = a_href_link.split('_')[-1]
# 防盗链
headers = {
"Referer": "https://www.pearvideo.com/video_%s" % video_id
}
res1 = requests.get('https://www.pearvideo.com/videoStatus.jsp',
params={'contId': video_id},
headers=headers
)
data_dict = res1.json()
src_url = data_dict['videoInfo']['videos']['srcUrl']
systemTime = data_dict['systemTime']
# https://video.pearvideo.com/mp4/adshort/20210920/1632285084621-15771122_adpkg-ad_hd.mp4
'''如何替换核心数据 通过研究发现systemTime是关键'''
real_url = src_url.replace(systemTime, 'cont-%s' % video_id)
res2 = requests.get(real_url)
file_path = os.path.join(r'梨视频数据', '%s.mp4' % video_id)
with open(file_path, 'wb') as f:
f.write(res2.content)
time.sleep(0.5)
print('%s 已下载' % video_id)
for n in range(0, 12, 48, 12):
get_video(n)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号