hive安装
2022-05-12 23:30 wang03 阅读(219) 评论(0) 收藏 举报本次操作是在安装完hadoop的基础上进行的,安装
hadoop请参看上篇博客hadoop集群搭建。
hive会使用到mysql,所以需要提前安装好mysql服务。可以参看这篇博客mysql解压版安装_wbo112的博客-CSDN博客。本次所有操作也都是基于
hadoop用户执行。
jdk8以上会报类加载器的报错,需要用jdk8。请自行将jdk版本换成jdk8。本次
hive安装到hadoop1节点上。
1、修改jdk版本为jdk8
由于我们
hive只装到hadoop1节点上,所以只修改hadoop1节点上的jdk就可以了。我使用的是
jdk-8u211-linux-x64.tar.gz,已上传到/home/hadoop/software目录中。
- 解压
jdk8
tar -zxvf jdk-8u211-linux-x64.tar.gz
-
修改环境变量
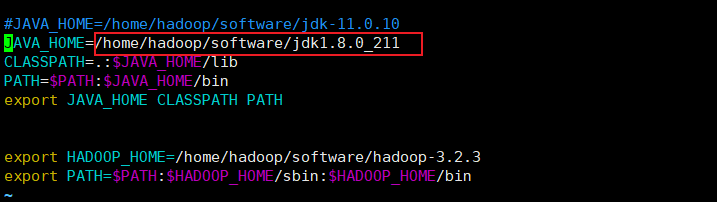
修改
~/.bashrc,将JAVA_HOME修改为jdk8的安装目录。![]()
执行
source ~/.bashrc使环境变量生效。 -
执行
java -version验证修改![]()

2、修改hadoop配置
修改
hadoop配置在hadoop1上执行,后分发到其他节点。
- 节点
/home/hadoop/software/hadoop-3.2.3/etc/hadoop/core-site.xml文件中加入如下配置。
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>

- 将刚才修改的
core-site.xml拷贝至其他节点
scp /home/hadoop/software/hadoop-3.2.3/etc/hadoop/core-site.xml hadoop2:/home/hadoop/software/hadoop-3.2.3/etc/hadoop/
scp /home/hadoop/software/hadoop-3.2.3/etc/hadoop/core-site.xml hadoop3:/home/hadoop/software/hadoop-3.2.3/etc/hadoop/
-
在
hadoop1节点上重启服务stop-dfs.sh start-dfs.sh
3、安装hive
我本次使用的是
apache-hive-3.1.2-bin.tar.gz,已经上传到了/home/hadoop/software/目录。
cd /home/hadoop/software/
tar -zxvf apache-hive-3.1.2-bin.tar.gz
2.1 、hadoop与hive的guava有冲突,需要删除hive中的guava,将hadoop中的guava拷贝过来。
rm /home/hadoop/software/apache-hive-3.1.2-bin/lib/guava-19.0.jar
cp /home/hadoop/software/hadoop-3.2.3/share/hadoop/common/lib/guava-27.0-jre.jar /home/hadoop/software/apache-hive-3.1.2-bin/lib/
2.2、接下来就要进入/home/hadoop/software/apache-hive-3.1.2-bin/conf/ 目录,修改配置:
-
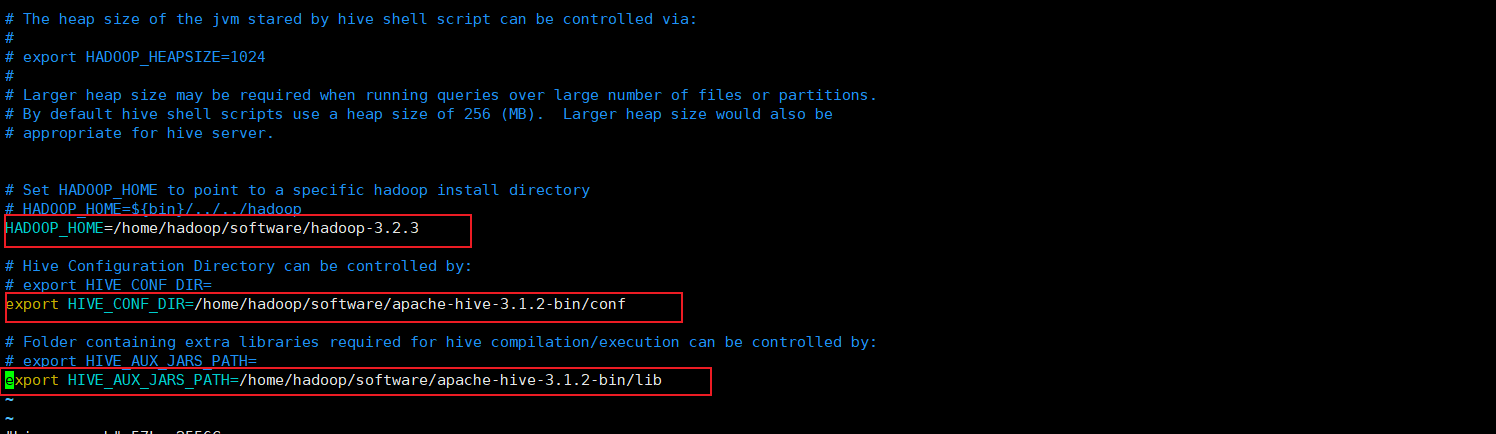
创建一个
hive-env.shcp hive-env.sh.template hive-env.sh #添加如下配置:
HADOOP_HOME=/home/hadoop/software/hadoop-3.2.3 export HIVE_CONF_DIR=/home/hadoop/software/apache-hive-3.1.2-bin/conf xport HIVE_AUX_JARS_PATH=/home/hadoop/software/apache-hive-3.1.2-bin/lib
-
创建
hive-site.xml<?xml version="1.0" encoding="UTF-8" standalone="no"?> <configuration> <!-- 存储元数据mysql相关配置 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop1:3306/hive3?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=UTC</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <!-- H2S运行绑定host --> <property> <name>hive.server2.thrift.bind.host</name> <value>hadoop1</value> </property> <!-- 远程模式部署metastore metastore地址 --> <property> <name>hive.metastore.uris</name> <value>thrift://hadoop1:9083</value> </property> <!-- 关闭元数据存储授权 --> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> </configuration> -
将
mysql的jdbc包拷贝到hive的lib目录中(最好是mysql-connector-java-8.x.xx.jar)。
4、初始化元数据
cd /home/hadoop/software/apache-hive-3.1.2-bin
./bin/schematool -initSchema -dbType mysql -verbos #如果是其他数据库,修改这里的mysql就可以了
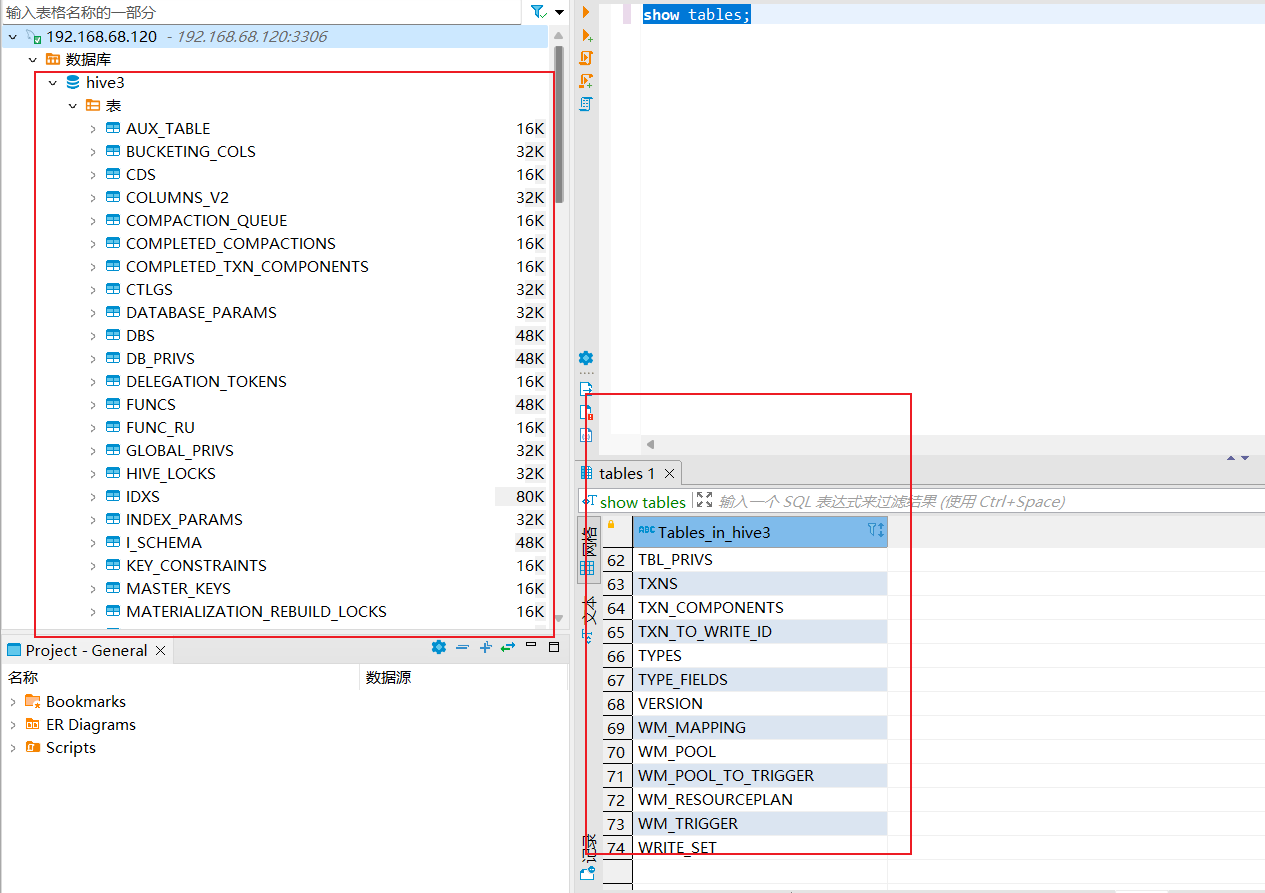
执行完之后,mysql中就会有个hive3的数据库,里面有74个表
5、创建hive的存储目录
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
6、启动hive
cd /home/hadoop/software/apache-hive-3.1.2-bin
nohup ./bin/hive --service metastore &
nohup ./bin/hive --service hiveserver2 &
# 前台启动
# ./bin/hive --service metastore
# 前台启动开启debug日志
#./bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console
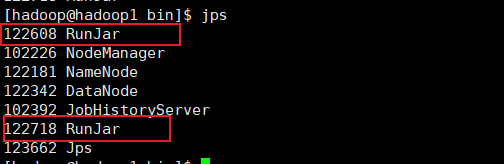
查看进程,会发现有两个RunJar进程
启动后,web界面也可以打开,默认端口是10002。

7、客户端连接
之前的客户端工具是
./bin/hive,目前已经被弃用,现在推荐使用./bin/beeline.关于
hive客户端的操作,具体可以看官方文档.LanguageManual Cli - Apache Hive - Apache Software Foundation
使用bin/beeline进行访问(可以在所有节点上操作。只需要把hive安装包拷贝过去,不需要再做任何其他操作)
关于
beeline的更多内容,还是建议看官方文档HiveServer2 Clients - Apache Hive - Apache Software Foundation
! connect jdbc:hive2://hadoop1:10000
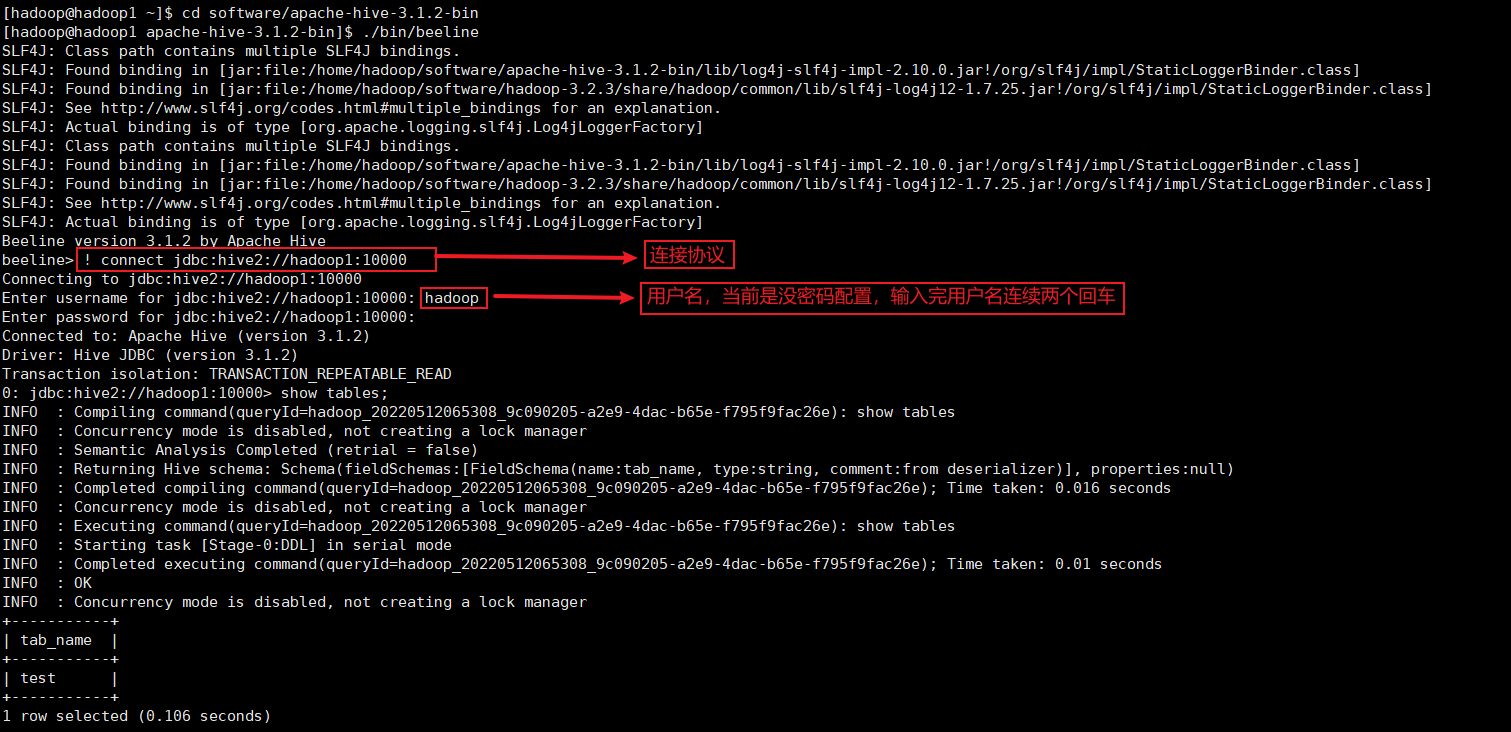
这里有个细节需要注意下:
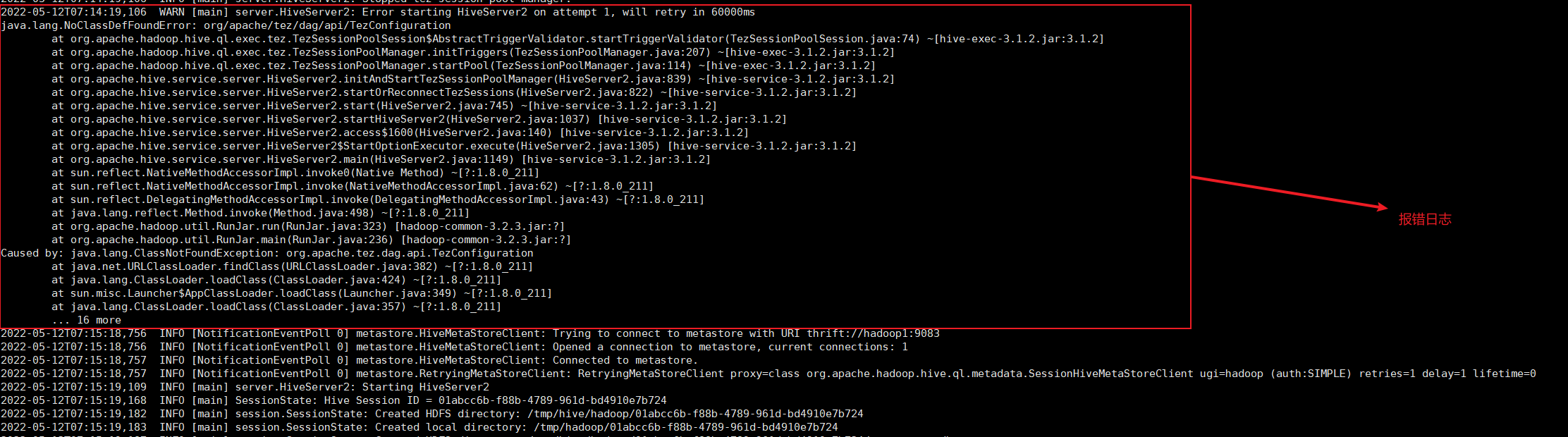
如果是刚启动
hive后,使用beeline连接会报错,看日志是当前没有org/apache/tez/dag/api/TezConfiguration,会60s后重启,用其他去连接,所以需要hive启动60s后才能连接成功。
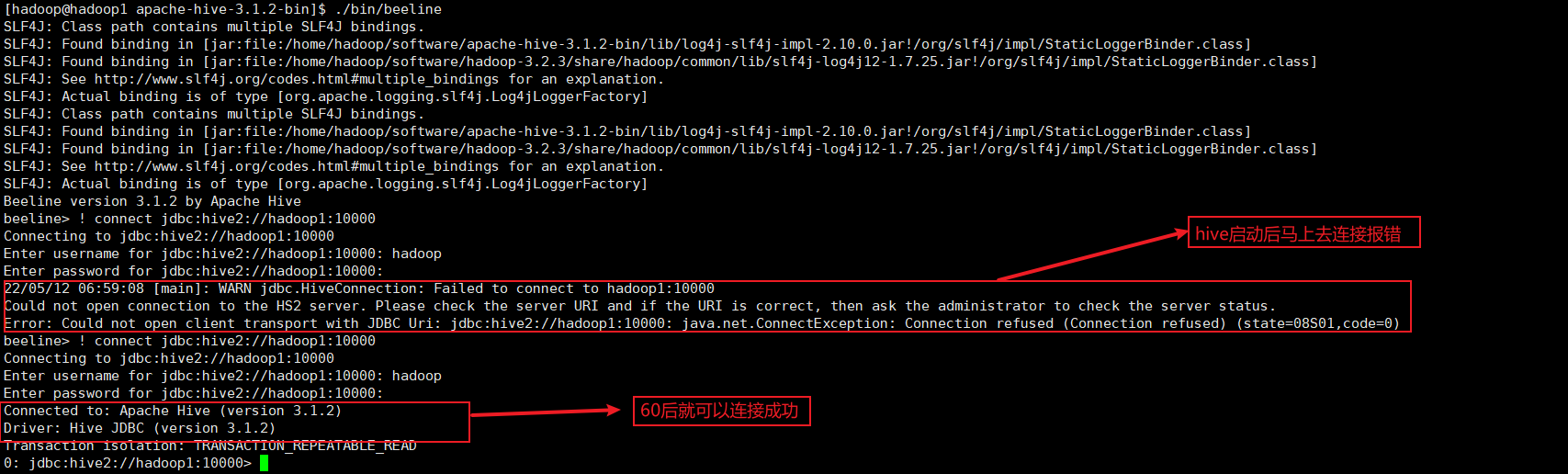
日志默认在
tmp/hadoop/hive.log文件中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号