XtraBackup 原理与安装
1. XtraBackup 简介
XtraBackup(PXB) 工具是 Percona 公司用 perl 语言开发的一个用于 MySQL 数据库物理热备的备份工具,支持 MySQl(Oracle)、Percona Server 和 MariaDB,并且全部开源,真可谓是业界良心。阿里的 RDS MySQL 物理备份就是基于这个工具做的。由于是采取物理拷贝的方式来做的备份,所以速度非常快,几十G数据几分钟就搞定了,而它巧妙的利用了mysql 特性做到了在线热备份,不用像以前做物理备份那样必须关闭数据库才行,直接在线就能完成整库或者是部分库的全量备份和增量备份。新版本的xtrabackup改成了cmake安装,和以前有点不一样。
版本说明:这里安装的版本是2.4.6,而2.3.3之后死锁不再堵塞备份了,如果数据库是mysql 5.7之后的必须要装2.4.4才可以用,当然了, 会向下兼容的。
工具集:软件包安装后,有以下可执行文件(版本2.4.6)
bin/ ├── innobackupex -> xtrabackup ├── xbcloud ├── xbcloud_osenv ├── xbcrypt ├── xbstream └── xtrabackup
其中最主要的是 innobackupex 和 xtrabackup,前者是一个 perl 脚本,后者是 C/C++ 编译的二进制。Percona 在2.3 版本用C重写了 innobackupex ,innobackupex 功能全部集成到 xtrabackup 里面,只有一个 binary,另外为了使用上的兼容考虑,innobackupex 作为 xtrabackup 的一个软链接。对于二次开发来说,2.3 摆脱了之前2个进程协作的负担,架构上明显要好于之前版本。(Percona XtraBackup 2.3 发布之后,推荐的备份方法是使用 xtrabackup 脚本。 )
xtrabackup 是用来备份 InnoDB 表的,不能备份非 InnoDB 表,和 mysqld server 没有交互;innobackupex 脚本用来备份非 InnoDB 表,同时会调用 xtrabackup 命令来备份 InnoDB 表,还会和 mysqld server 发送命令进行交互,如加读锁(FTWRL)、获取位点(SHOW SLAVE STATUS)等。简单来说,innobackupex 在 xtrabackup 之上做了一层封装。
一般情况下,我们是希望能备份 MyISAM 表的,虽然我们可能自己不用 MyISAM 表,但是 mysql 库下的系统表是 MyISAM 的,因此备份基本都通过 innobackupex 命令进行;另外一个原因是我们可能需要保存位点信息。
另外几个工具相对小众些,xbcrypt 是加解密备份文件用的;xbstream 类似于tar,是 Percona 自己实现的一种支持并发写的流文件格式;两者在备份和解压时都会用到(如果备份用了加密和并发)。xbcloud 工具的作用是:把全部或部分 xbstream 档案从云上下载或上传到云。
2. XtraBackup 原理
2.3版本之前 innobackupex 和 xtrabackup 这2个工具之间的交互和协调是通过控制文件的创建和删除来实现的,2.3版本将 innobackupex 功能全部集成到 xtrabackup 里面,也就不需要他们之间的通信。这里介绍基于老的架构(2.2版本),但是原理和2.3是一样的,只是实现上的差别。
整个备份过程如下图:
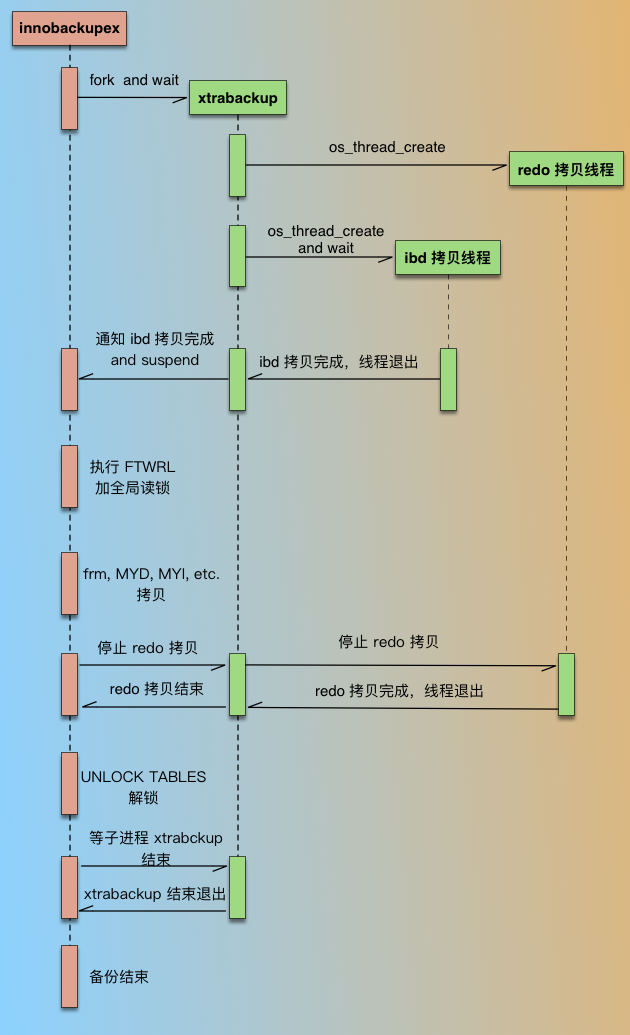
PXB 备份过程
- innobackupex 在启动后,会先 fork 一个进程,启动 xtrabackup进程,然后就等待 xtrabackup 备份完 ibd 数据文件;
- xtrabackup 在备份 InnoDB 相关数据时,是有2种线程的,1种是 redo 拷贝线程,负责拷贝 redo 文件,1种是 ibd 拷贝线程,负责拷贝 ibd 文件;redo 拷贝线程只有一个,在 ibd 拷贝线程之前启动,在 ibd 线程结束后结束。xtrabackup 进程开始执行后,先启动 redo 拷贝线程,从最新的 checkpoint 点开始顺序拷贝 redo 日志;然后再启动 ibd 数据拷贝线程,在 xtrabackup 拷贝 ibd 过程中,innobackupex 进程一直处于等待状态(等待文件被创建)。
- xtrabackup 拷贝完成idb后,通知 innobackupex(通过创建文件),同时自己进入等待(redo 线程仍然继续拷贝);
- innobackupex 收到 xtrabackup 通知后,执行FLUSH TABLES WITH READ LOCK (FTWRL),取得一致性位点,然后开始备份非 InnoDB 文件(包括 frm、MYD、MYI、CSV、opt、par等)。拷贝非 InnoDB 文件过程中,因为数据库处于全局只读状态,如果在业务的主库备份的话,要特别小心,非 InnoDB 表(主要是MyISAM)比较多的话整库只读时间就会比较长,这个影响一定要评估到。
- 当 innobackupex 拷贝完所有非 InnoDB 表文件后,通知 xtrabackup(通过删文件) ,同时自己进入等待(等待另一个文件被创建);
- xtrabackup 收到 innobackupex 备份完非 InnoDB 通知后,就停止 redo 拷贝线程,然后通知 innobackupex redo log 拷贝完成(通过创建文件);
- innobackupex 收到 redo 备份完成通知后,就开始解锁,执行 UNLOCK TABLES;
- 最后 innobackupex 和 xtrabackup 进程各自完成收尾工作,如资源的释放、写备份元数据信息等,innobackupex 等待 xtrabackup 子进程结束后退出。
在上面描述的文件拷贝,都是备份进程直接通过操作系统读取数据文件的,只在执行 SQL 命令时和数据库有交互,基本不影响数据库的运行,在备份非 InnoDB 时会有一段时间只读(如果没有MyISAM表的话,只读时间在几秒左右),在备份 InnoDB 数据文件时,对数据库完全没有影响,是真正的热备。
InnoDB 和非 InnoDB 文件的备份都是通过拷贝文件来做的,但是实现的方式不同,前者是以page为粒度做的(xtrabackup),后者是 cp 或者 tar 命令(innobackupex),xtrabackup 在读取每个page时会校验 checksum 值,保证数据块是一致的,而 innobackupex 在 cp MyISAM 文件时已经做了flush(FTWRL),磁盘上的文件也是完整的,所以最终备份集里的数据文件都是写入完整的。
增量备份
PXB 是支持增量备份的,但是只能对 InnoDB 做增量,InnoDB 每个 page 有个 LSN 号,LSN 是全局递增的,page 被更改时会记录当前的 LSN 号,page中的 LSN 越大,说明当前page越新(最近被更新)。每次备份会记录当前备份到的LSN(xtrabackup_checkpoints 文件中),增量备份就是只拷贝LSN大于上次备份的page,比上次备份小的跳过,每个ibd文件最终备份出来的是增量 delta 文件。
MyISAM 是没有增量的机制的,每次增量备份都是全部拷贝的。
增量备份过程和全量备份一样,只是在 ibd 文件拷贝上有不同。
恢复过程
如果看恢复备份集的日志,会发现和 mysqld 启动时非常相似,其实备份集的恢复就是类似 mysqld crash后,做一次 crash recover。
恢复的目的是把备份集中的数据恢复到一个一致性位点,所谓一致就是指原数据库某一时间点各引擎数据的状态,比如 MyISAM 中的数据对应的是 15:00 时间点的,InnoDB 中的数据对应的是 15:20 的,这种状态的数据就是不一致的。PXB 备份集对应的一致点,就是备份时FTWRL的时间点,恢复出来的数据,就对应原数据库FTWRL时的状态。
因为备份时 FTWRL 后,数据库是处于只读的,非 InnoDB 数据是在持有全局读锁情况下拷贝的,所以非 InnoDB 数据本身就对应 FTWRL 时间点;InnoDB 的 ibd 文件拷贝是在 FTWRL 前做的,拷贝出来的不同 ibd 文件最后更新时间点是不一样的,这种状态的 ibd 文件是不能直接用的,但是 redo log 是从备份开始一直持续拷贝的,最后的 redo 日志点是在持有 FTWRL 后取得的,所以最终通过 redo 应用后的 ibd 数据时间点也是和 FTWRL 一致的。
所以恢复过程只涉及 InnoDB 文件的恢复,非 InnoDB 数据是不动的。备份恢复完成后,就可以把数据文件拷贝到对应的目录,然后通过mysqld来启动了。
注:以上原理摘自阿里云数据库内核月报。
实现细节 ( Percona官方说明 )
1. 文件权限
因为XtraBackup要从文件系统中复制大量的数据,所以它尽可能地使用 posix_fadvise(),来告诉OS不要缓存读取到的数据,因为这些数据不会重用到了,从而提升性能。如果一次备份要缓存几个G的数据,会对OS的虚拟内存造成很大的压力,其它进程,比如mysqld很有可能被swap出去,这样系统就会受到很大影响了。xtrabackup 就是通过 posix_fadvise() 来避免这种情况:
posix_fadvise(file,0,0,POSIX_FADV_DONTNEED)
而且, xtrabackup 要求操作系统对源文件进行更多的预读优化:
posix_fadvise(file,0,0,POSIX_FADV_SEQUENTIAL)
3. 复制数据文件
在备份innodb page的过程中,XtraBackup 每次读写1MB的数据,1MB/16KB=64个page。这个不可配置。读取1MB数据之后,XtraBackup一页一页地遍历这1MB数据,并使用innodb的buf_page_is_corrupted()函数检查此页的数据是否正常,如果数据不正常,就重新读取这一页,最多重新读取10次(注意:doublewrite buffer 中的 page 会跳过此检查)。
在复制 transactions log(redo log) 的时候,每次读写512KB的数据。同样不可以配置。
3. XtraBackup 安装
系统:CentOS 6.6(Percona 官方建议安装在 RHEL/CentOS 6.5 及以上的系统)
版本:percona-xtrabackup-24-2.4.6-2.el6.x86_64
- rpm 安装(下载:https://pan.baidu.com/s/1sl4jByP)
- 二进制安装/解压缩安装(下载:http://pan.baidu.com/s/1c1Vyt3q)
- 编译安装
1. rpm 安装
这种安装方法比较简单,只需下载相应的rpm安装包安装即可(注意根据提示安装相应的依赖包)。其中需要的 libev.so.4() 安装包:https://pan.baidu.com/s/1i4EZfwT
[root@centos6 xtrabackup]# rpm -ivh percona-xtrabackup-24-2.4.6-2.el6.x86_64.rpm warning: percona-xtrabackup-24-2.4.6-2.el6.x86_64.rpm: Header V4 DSA/SHA1 Signature, key ID cd2efd2a: NOKEY Preparing... ########################################### [100%] 1:percona-xtrabackup-24 ########################################### [100%]
2. 二进制安装/解压缩安装
这种安装方法也很简单,不需要安装依赖,只需解压安装文件,为了方便可创建软连接。
# tar zxvf percona-xtrabackup-2.4.6-Linux-x86_64.tar.gz #解压目录下有3个目录: bin man percona-xtrabackup-2.4-test # mv percona-xtrabackup-2.4.6-Linux-x86_64 /usr/local/xtrabackup # ln -sf /usr/local/xtrabackup/bin/* /usr/bin/ #给命令建个软连接 [root@centos6 ~]# xtrabackup --version xtrabackup version 2.4.6 based on MySQL server 5.7.13 Linux (x86_64) (revision id: 8ec05b7)
3. 编译安装
这种安装方法比较麻烦,需要安装很多依赖,也很耗时间,这里就不做介绍了。
4. XtraBackup 备份恢复
待续……

 浙公网安备 33010602011771号
浙公网安备 33010602011771号