Spark系列 - (3) Spark SQL

3. Spark SQL
3.1 Hive、Shark和Sparksql
Hive:Hadoop刚开始出来的时候,使用的是hadoop自带的分布式计算系统 MapReduce,但是MapReduce的使用难度较大,所以就开发了Hive。Hive的出现解决了MapReduce的使用难度较大的问题,Hive的运行原理是将HQL语句经过语法解析、逻辑计划、物理计划转化成MapReduce程序执行。
Shark:2011年Shark诞生,即Hive on Spark。为了实现与Hive兼容,Shark在HiveQL方面重用了Hive中HiveQL的解析、逻辑执行计划、执行计划优化等逻辑;可以近似认为仅将物理执行计划从MapReduce作业替换成了Spark作业,通过Hive 的HiveQL解析,把HiveQL翻译成Spark上的RDD操作;Shark的出现,使得SQL-on-Hadoop的性能比Hive有了10-100倍的提高。
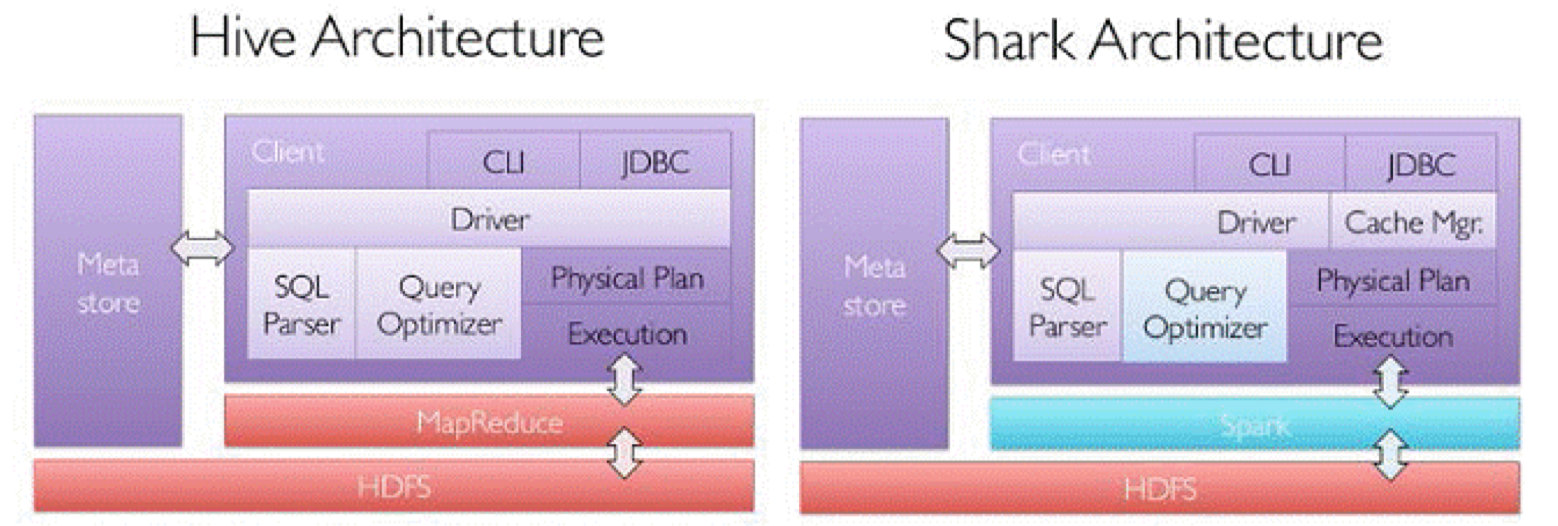
Shark的缺陷:
-
执行计划优化完全依赖于Hive,不方便添加新的优化策略
-
因为Spark是线程级并行,而MapReduce是进程级并行,因此,Spark在兼容 Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的打了补丁的Hive源码分支。
2014年7月,spark团队将Shark转给Hive进行管理,Hive on Spark是一个Hive的也就是说,Hive将不再受限于一个引擎,可以采用Map-Reduce、Tez、Spark等引擎;
Spark SQL作为Spark生态的一员诞生,不再受限于Hive,只是兼容Hive。
3.2 RDD和DataFrame、DataSet
RDD:弹性(Resilient)、分布式(Distributed)、数据集(Datasets),具有只读、Lazy、类型安全等特点,具有比较好用的API。RDD的劣势体现在性能限制上,它是一个JVM驻内存对象,这也就决定了存在GC的限制和数据增加时Java序列化成本的升高。
DataFrame:与RDD类似,DataFRame也是一个不可变的弹性分布式数据集。除了数据以外,还记录着数据的结构信息,即Schema。另外DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好。DataFrame的查询计划可以通过Spark catalyst optimiser进行优化,即使 Spark经验并不丰富,用dataframe写得程序也可以尽量被转化为高效的形式予以执行。
DataFrame只是知道字段,但是不知道字段的类型,所以在执行这些操作的时候是 没办法在编译的时候检查是否类型失败的。
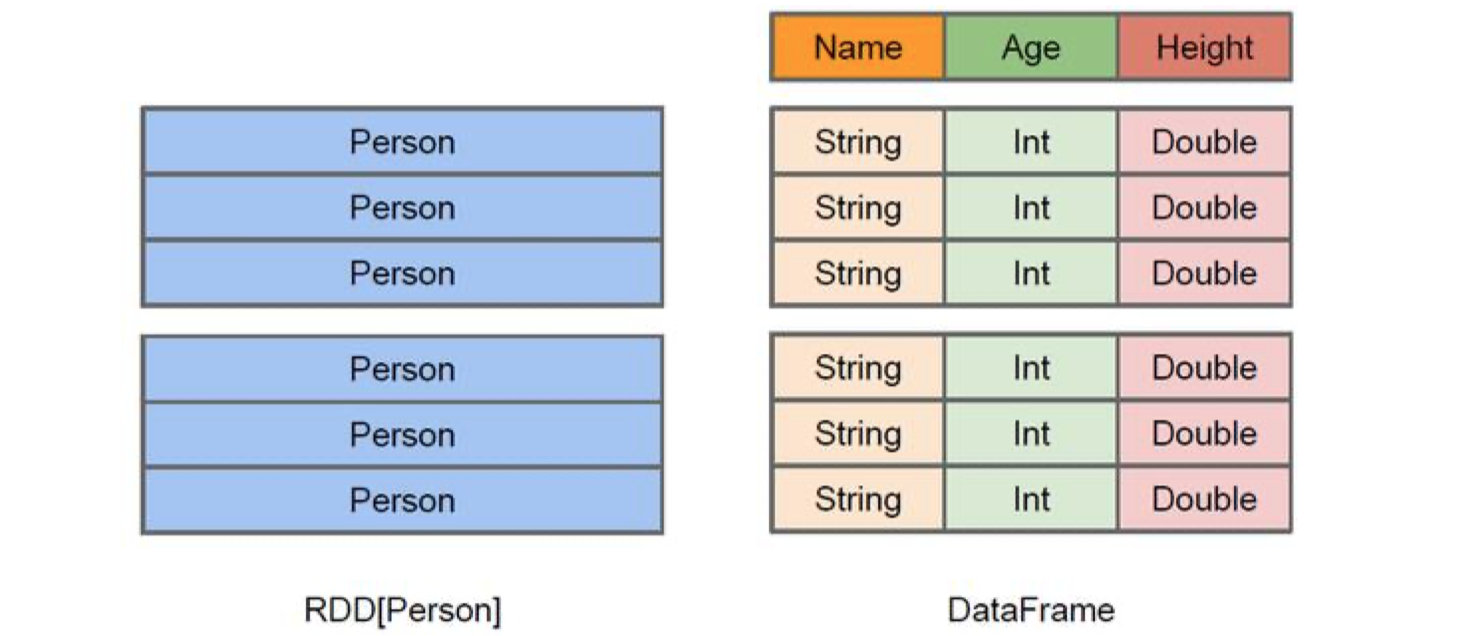
上图直观地体现了 DataFrame 和 RDD 的区别。左侧的 RDD[Person]虽然以Person为类型参 数,但 Spark 框架本身不了解Person 类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL 可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。 DataFrame是为数据提供了Schema的视图。可以把它当做数据库中的一张表来对待,DataFrame也是懒执行的。性能上比 RDD 要高,主要原因:优化的执行计划:查询计划通过 Spark catalyst optimiser 进行优化。
DataSet:DataSet是DataFrame的扩展,是Spark最新的数据抽象。Dataframe 是 Dataset 的特列,DataFrame=Dataset[Row] ,所以可以通过 as 方法将 Dataframe 转换为 Dataset。Row 是一个类型,跟Car、Person 这些的类型一样,所有的表结构信息我都用 Row 来表示。DataSet 是强类型的。比如可以有 Dataset[Car],Dataset[Person]。DataFrame只是知道字段,但是不知道字段的类型,所以在执行这些操作的时候是没办法在编译的时候检查是否类型失败的,比如你可以对一个String进行减法操作,在执行的时候才报错,而DataSet不仅仅知道字段,而且知道字段类型,所以有更严格的错误检查。就跟JSON对象和类对象之间的类比。
3.2.1 三者的共性
- 都是分布式弹性数据集,为处理超大型数据提供便利;
- 都是Lasy的,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始遍历运算,极端情况下,如果代码里面有创建、 转换,但是后面没有在Action中使用对应的结果,在执行时会被直接跳过;
- 都有partition的概念;
- 三者有许多共同的函数,如filter,排序等;
- DataFrame和Dataset均可使用模式匹配获取各个字段的值和类型;
- 三者可以相互转化
3.2.2 区别
RDD与DataFrame/DataSet的区别
RDD:
- 用于Spark1.X各模块的API(SparkContext、MLLib,Dstream等)
- 不支持sparksql操作
- 不支持代码自动优化
DataFrame与DataSet:
- 用于Spark2.X各模块的API(SparkSession、ML、StructuredStreaming等等)
- 支持SparkSql操作,比如select,groupby之类,还能注册临时表/视窗,进行 sql语句操作
- 支持一些方便的保存方式,比如保存成csv、json等格式
- 基于sparksql引擎构建,支持代码自动优化
DataFrame与DataSet的区别
DataFrame:
- DataFrame每一行的类型固定为Row,只有通过解析才能获取各个字段的值, 每一列的值没法直接访问。
- DataFrame编译器缺少类型安全检查。
testDF.foreach{
line => val col1=line.getAs[String]("col1")
println(col1)
val col2=line.getAs[String]("col2")
println(col2)
}
DataSet:
- DataFrame和DataSet之间,可以看成JSON对象和类对象之间的类比。
- DataSet是类型安全的。
3.2.3 Sql、dataframe、DataSet的类型安全
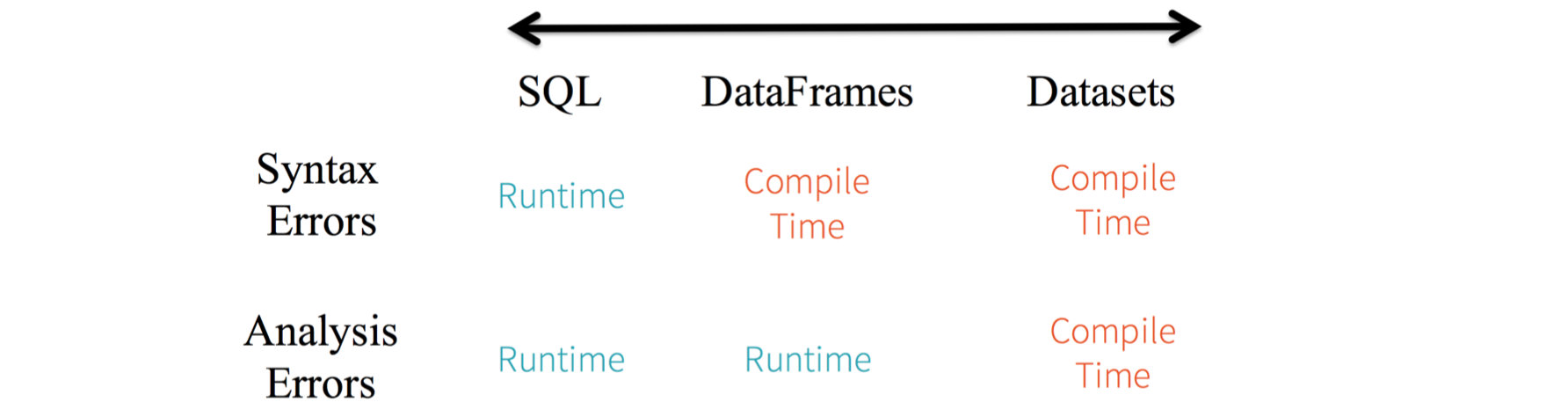
- 如果使用Spark SQL的查询语句,要直到运行时你才会发现有语法错误(这样做代价很大)。
- 如果使用DataFrame,你在也就是说,当你在 DataFrame 中调用了 API 之外的函数时,编译器就可以发现这个错。但如果此时,使用了一个不存在字段的名字,则只能到运行时才能发现错误;
- 如果用的是DataSet[Person],所有不匹配的类型参数都可以在编译时发现;
3.2.4 什么时候使用DataFrame或DataSet
下面的情况可以考虑使用DataFrame或Dataset,
- 如果你需要丰富的语义、高级抽象和特定领域专用的 API,那就使用 DataFrame 或 Dataset;
- 如果你的处理需要对半结构化数据进行高级处理,如 filter、map、aggregation、 average、sum、SQL 查询、列式访问或使用 lambda 函数,那就使用 DataFrame 或 Dataset;
- 如果你想在编译时就有高度的类型安全,想要有类型的 JVM 对象,用上 Catalyst 优化,并得益于 Tungsten 生成的高效代码,那就使用 Dataset;
- 如果你想在不同的 Spark 库之间使用一致和简化的 API,那就使用 DataFrame 或 Dataset;
- 如果你是R或者Python使用者,就用DataFrame;
除此之外,在需要更细致的控制时就退回去使用RDD;
3.2.5 RDD、DataFrame、DataSet之间的转换
1. RDD转DataFrame、Dataset
- RDD转DataFrame:一般用元组把一行的数据写在一起,然后在toDF中指定字段名。

- RDD转Dataset:需要提前定义字段名和类型。

2. DataFrame转RDD、Dataset
- DataFrame转RDD:直接转
val rdd = testDF.rdd - DataFrame转Dataset:需要提前定义case class,然后使用as方法。

3. Dataset转RDD、DataFrame
- DataSet转RDD:直接转
val rdd = testDS.rdd - DataSet转DataFrame:直接转即可,spark会把case class封装成Row。

3.3 Spark SQL优化
Catalyst是spark sql的核心,是一套针对spark sql 语句执行过程中的查询优化框架。因此要理解spark sql的执行流程,理解Catalyst的工作流程是理解spark sql的关键。而说到Catalyst,就必须提到下面这张图了,这张图描述了spark sql执行的全流程。其中,中间四步为catalyst的工作流程。
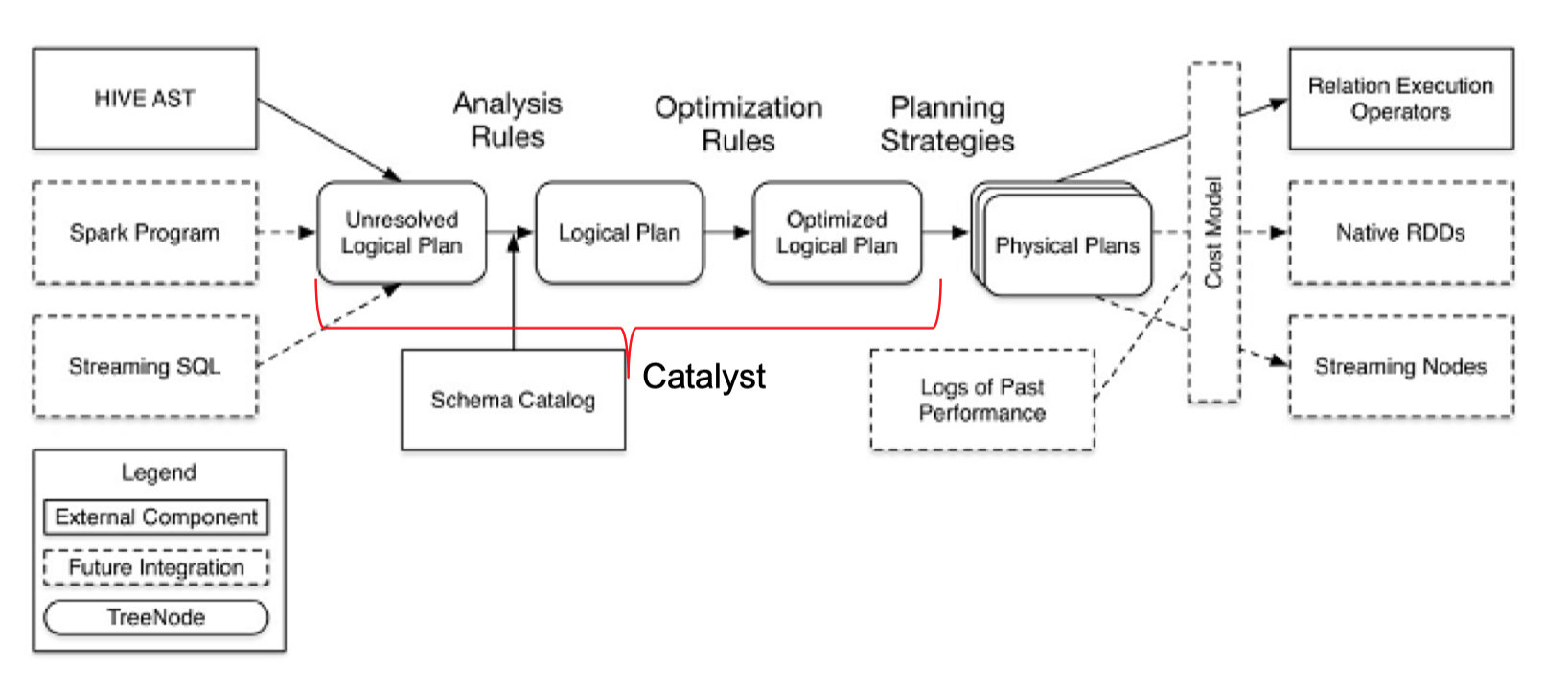
SQL语句首先通过Parser模块被解析为语法树,此棵树称为Unresolved Logical Plan;Unresolved Logical Plan通过Analyzer模块借助于Catalog中的表信息解析为Logical Plan;此时,Optimizer再通过各种基于规则的优化策略进行深入优化,得到Optimized Logical Plan;优化后的逻辑执行计划依然是逻辑的,并不能被Spark系统理解,此时需要将此逻辑执行计划转换为Physical Plan。
Spark常见的优化策略有下面几类:
- Combine Limits:合并Limit,就是将两个相邻的limit合为一个。
- Constant Folding:常量叠加
- NullPropagation:空格处理
- BooleanSimplification:布尔表达式简化
- ConstantFolding:常量叠加
- SimplifyFilters:Filter简化
- LikeSimplification:like表达式简化。
- SimplifyCasts:Cast简化
- SimplifyCaseConversionExpressions:CASE大小写转化表达式简化
- Filter Pushdown Filter下推
- CombineFilters Filter合并
- PushPredicateThroughProject:通过Project下推
- PushPredicateThroughJoin:通过Join下推
- ColumnPruning:列剪枝
搜索『后端精进之路』并关注,立刻获取文章合集和面试攻略,还有价值数千元的面试大礼包等你拿。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号