

计网(2)
计网(2)
基础篇
二、从键入网址到网页显示
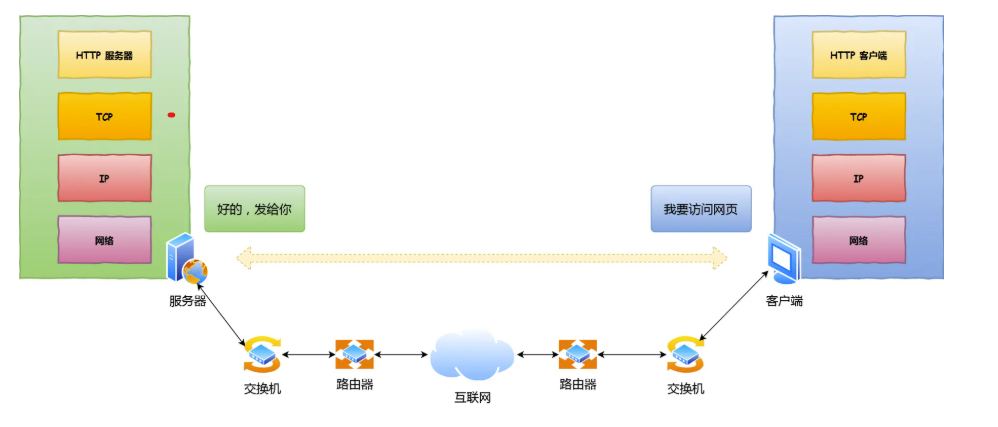
-
HTTP
键入网址后,浏览器首先解析URL,获取发送给web服务器的请求信息。
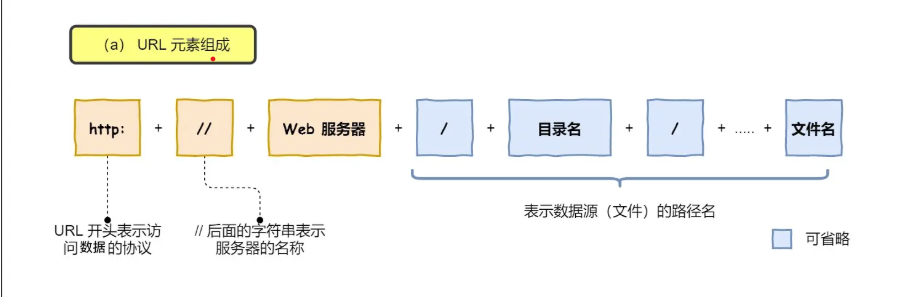
URL的组成:
![URL的组成]()
例子:https://www.baidu.com:其中www.baidu.com表示百度的服务器。
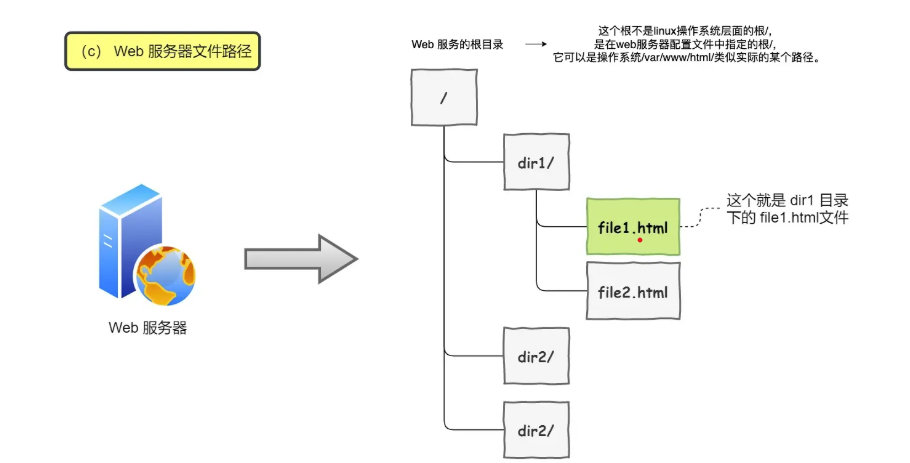
web服务器文件路径:
![web服务器文件路径]()
所以URL的本质就是请求服务器里的文件资源。当没有路径名时,就表示访问根目录下事先设置的默认文件:/index.html 或者/default.html。
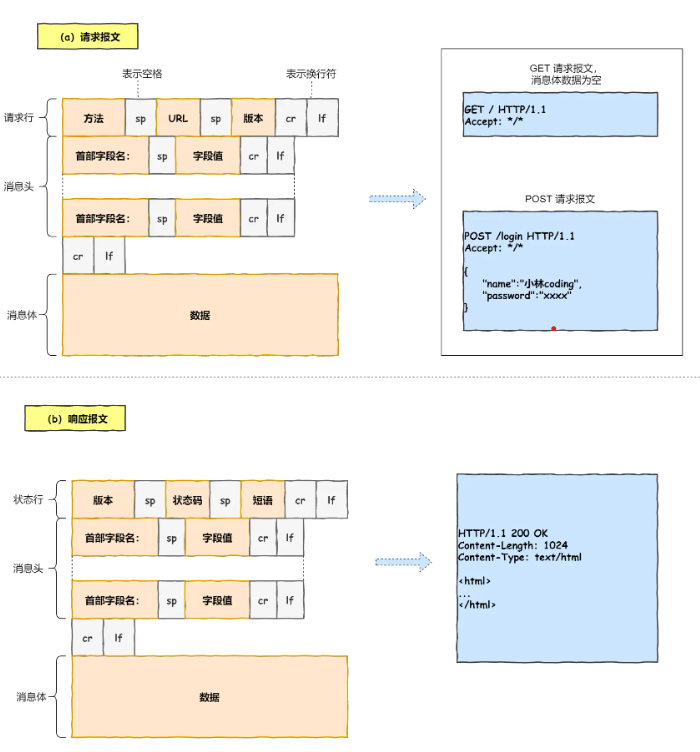
对URL解析获取Web服务器和文件名后,根据这些信息生成http请求报文:![http报文]()
-
DNS(ip地址查询)
浏览器解析URL生成HTTP消息后,通过操作系统将消息发送到web服务器。在发送之前。需要查询服务器域名对应的IP地址,如果每次访问需要填写具体的ip地址,难以记忆很不方便(类比手机号),所以我们通常可以将ip地址以及对应服务器保存再“通讯录中”。
所以,引入了一个专门保存web服务器与IP的对应关系的服务器,即DNS服务器。www.baidu.com 称其为域名,.代表了不同层次之间的界限。在域名中,越靠右的位置表示层级越高。实际上域名最后还有一个. ,比如 www.baidu.com. , 最后这个点代表根域名。所以域名的层级关系类似一个树状结构:跟DNS服务器(.)
顶级域DNS服务器(.com)
权威DNS服务器(server.com)
根域的DNS服务器信息保存在互联网中所有的DNS服务器中,所以任何DNS服务器都可以找到并访问根域DNS服务器。
因此,客户端只要能找到任意一台DNS服务器,就可以通过它找到根域服务器,然后在一路顺藤摸瓜根服务器下的目标DNS服务器。
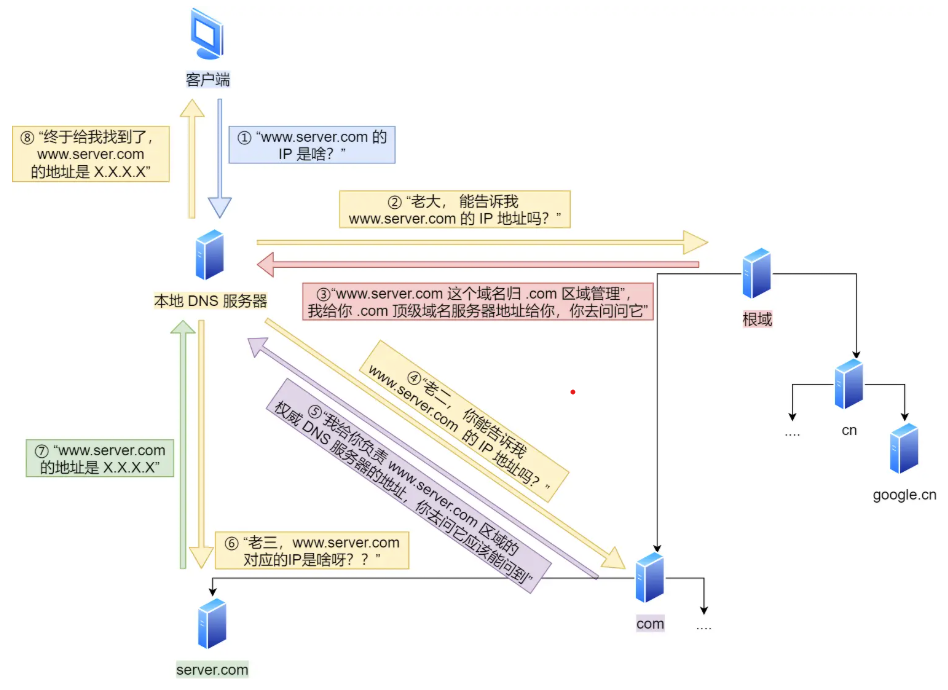
域名解析的工作流程:
![DNS解析流程]()
- 客户端首先发出一个DNS请求,询问本地域名服务器(在TCP/IP配置中指定) www.baidu.com 的IP是什么。
- 本地服务器拿到 www.baidu.com 首先查询服务器中的缓存表是否有对应的IP地址,如果有直接返回。如果没有,本地服务器会去问根域名服务器:“老大,www.baidu.com 的ip地址是多少?”
- 根服务器不会直接解析www.baidu.com 并存储其IP地址,这样的话根服务器的存储是很大的问题,他会找到顶级域DNS服务器 .com,并将他的ip地址告诉本地服务器:“我给你 .com顶级域名服务器的地址,你去问问他。”
- 同样地,顶级域名服务器同样也不会直接存储IP地址,它会将权威DNS服务器的地址(www.server.com) 告诉本地服务器,让他去问他。
- 权威域名服务器(域名解析结果的原出处,权威即它旗下的域名它做主)查询后将对应的IP地址告诉本地DNS
- 本地DNS再将IP地址返回客户端,客户端与目标建立连接。
域名解析就像我们生活中问路,这个过程通常只指路不带路。
不是每次解析域名都要经过这么多步骤!浏览器、操作系统、本地host文件、本地DNS服务器中都有存储IP地址的缓存,如果在缓存中找到了对应的IP地址,都会直接返回。
在通过DNS找到对应的ip地址后,上文提到操作系统会帮助我们发送请求到web服务器。
-
协议栈(操作系统发送HTTP的帮手)
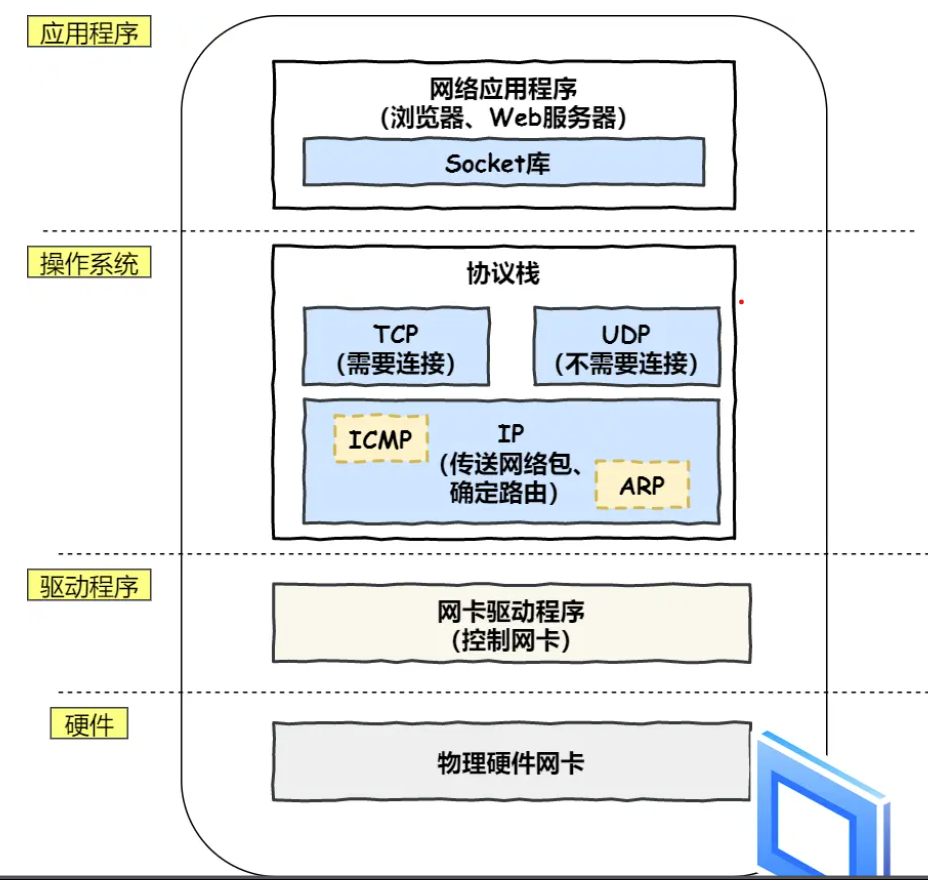
协议栈的内部分为几个部分,分别承担不同的工作。上下关系有一定的规则,上面的部分会向下面的部分委托工作。
![协议栈]()
应用程序通过Socket库来调用协议栈来工作。在操作系统层面,协议栈的工作主要有两方面:一是负责数据收发的TCP与UDP协议,这俩协议会接受应用层的收发委托操作。二是IP协议控制网络包的收发操作,其中IP协议中包含了ICMP协议和ARP协议。
ICMP协议:用于告知网络包传输过程中产生的错误以及各种控制信息 ARP协议:根据IP地址查询对应的以太网MAC地址实际的收发操作是网线中的信号执行的。
可以看到协议栈的工作流程严格遵守TCP/IP网络模型的四层结构。 -
TCP——可靠的传输
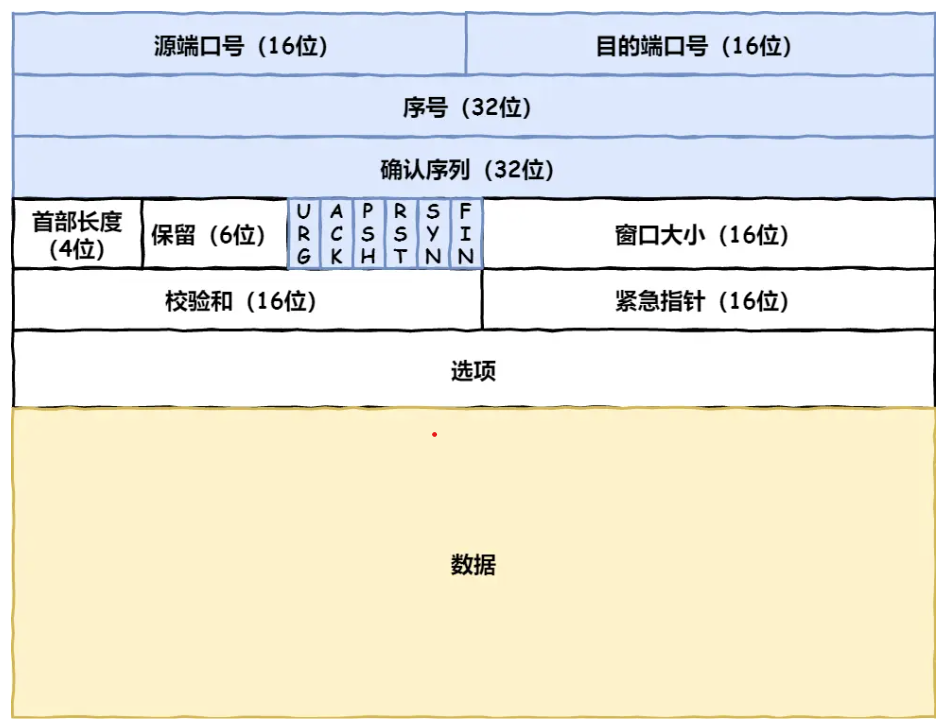
HTTP是基于TCP协议传输的。TCP报文头部的格式:
![TCP报文头部]()
源端口号与目的端口号:指明数据来自谁与数据发给谁
序号:包的序号,防止包乱序
确认序列:确认发出去后对方是否收到,如果没有收到就重新发送,直到送达,解决了丢包的问题。
状态位:例如:SYN是发起一个连接,ACK是回复,RST是重新连接,FIN是结束连接等。TCP是面向连接的,因而双方要维护连接的状态,带状态位的包的发送,会引起双方状态的变更。
窗口大小:用来实现流量控制,通信双发各声明一个窗口(缓存大小),标识自己的处理能能力。“发送的太快,会撑死,发送的太慢,会饿死。”
TCP还提供拥塞控制,在报文头部没有体现。它是通过发送端和接收端的协议栈维护的状态变量与算法实现。但是要利用报文中的ACK,丢包等信息来实现。
例子:TCP 序号与确认序列解决乱序与丢包的例子
🔗 背景
序号 (SEQ):表示当前 segment 第一个字节在数据流中的位置
确认序列 (ACK):接收方期望收到的下一个字节序号
正常场景
客户端发送 3 个 segment,每个 100 字节,初始 SEQ=1000- 发送 Segment1
SEQ=1000,长度=100
服务器收到后回复:ACK=1100 - 发送 Segment2
SEQ=1100,长度=100
服务器收到后回复:ACK=1200 - 发送 Segment3
SEQ=1200,长度=100
服务器收到后回复:ACK=1300
乱序场景
Segment2 先到,Segment1 后到 - 发送 Segment2
SEQ=1100
服务器期望的是 SEQ=1000,因此缓存 Segment2,回复:ACK=1000 - 发送 Segment1
SEQ=1000
服务器收到 Segment1 后,可拼接已缓存的 Segment2,回复:ACK=1200 - 继续接收后续 Segment3
丢包场景
Segment2 丢失 - 发送 Segment1
SEQ=1000,长度=100
服务器回复:ACK=1100 - 发送 Segment2(丢失)
- 发送 Segment3
SEQ=1200
服务器仍期望 SEQ=1100,回复:ACK=1100 - 客户端收到多次重复 ACK=1100,会触发 快速重传,重发 Segment2
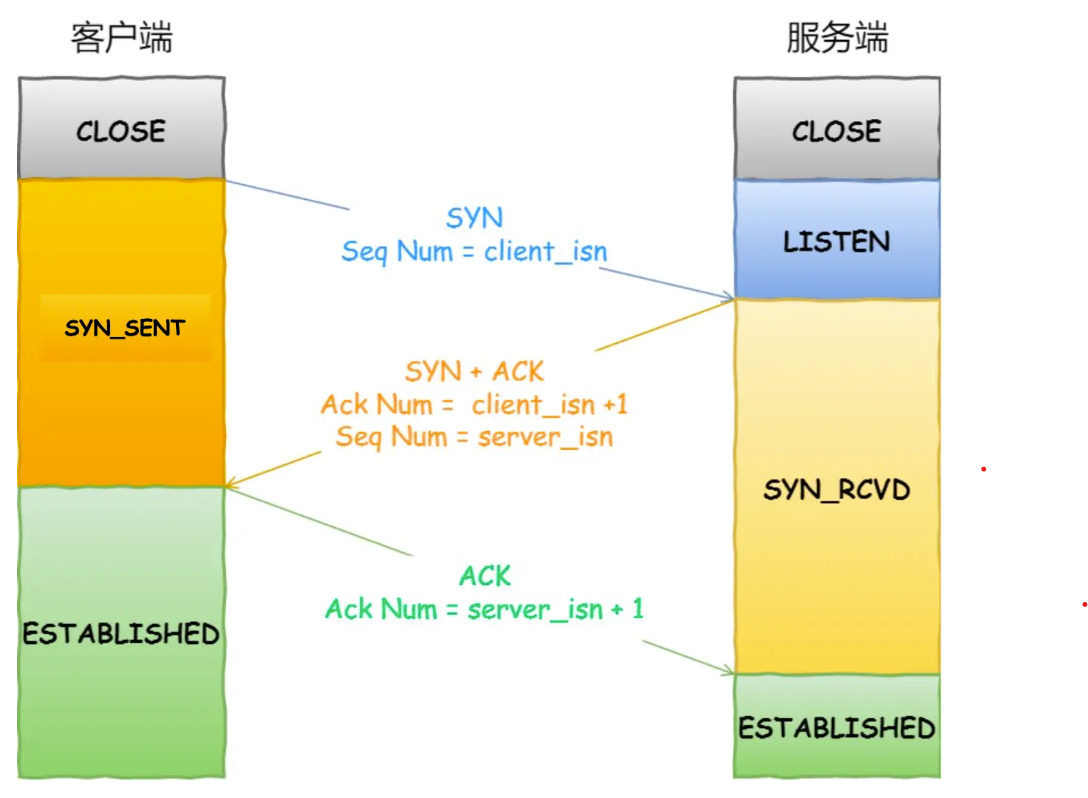
TCP传输数据之前,通过三次握手建立连接(这里的连接通过双方计算机里维护一个状态机实现)。
![三次握手]()
双发都进行一发一收后就处于 ESTABLISHED(已确立) 状态,所以三次握手的本质就是确保双方都有发送和接受的能能力。
TCP 分割数据:
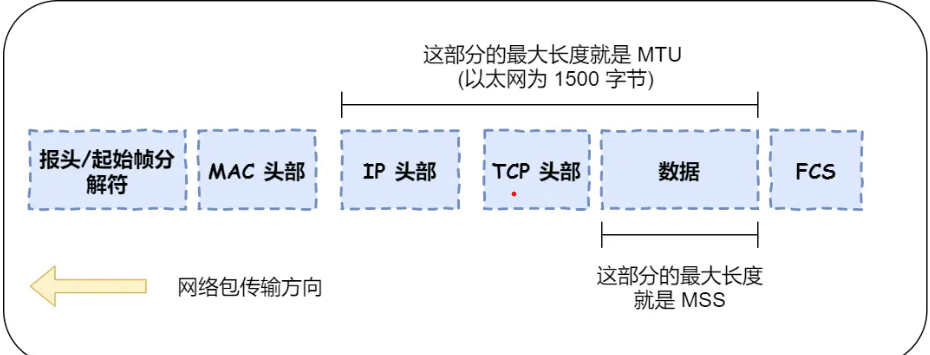
如果HTTP请求消息比较长,超过了MSS长度,这时TCP就需要把HTTP的数据拆解成一块块的数据发送,而不是一次性发送所有数据。
![网络数据包]()
MTU:网络包的最大长度,以太网中一般为1500字节
MSS:除去IP和TCP头部之后,网络包能容纳的TCP数据的最大长度。
数据会被以 MSS 的长度为单位进行拆分,拆分出来的每一块数据都会被放进单独的网络包中,也就是每个被拆分的数据加上TCP头信息,然后交给IP模块来发送数据。
TCP报文的数据部分就是存放HTTP的头部+数据,组装好TCP保温之后,就交给下面的网络层处理。 - 发送 Segment1
-
远程定位——IP
TCP模块在执行连接、收发、断开等各阶段操作时,都需要委托IP模块将数据封装成网络包发送给通信对象。
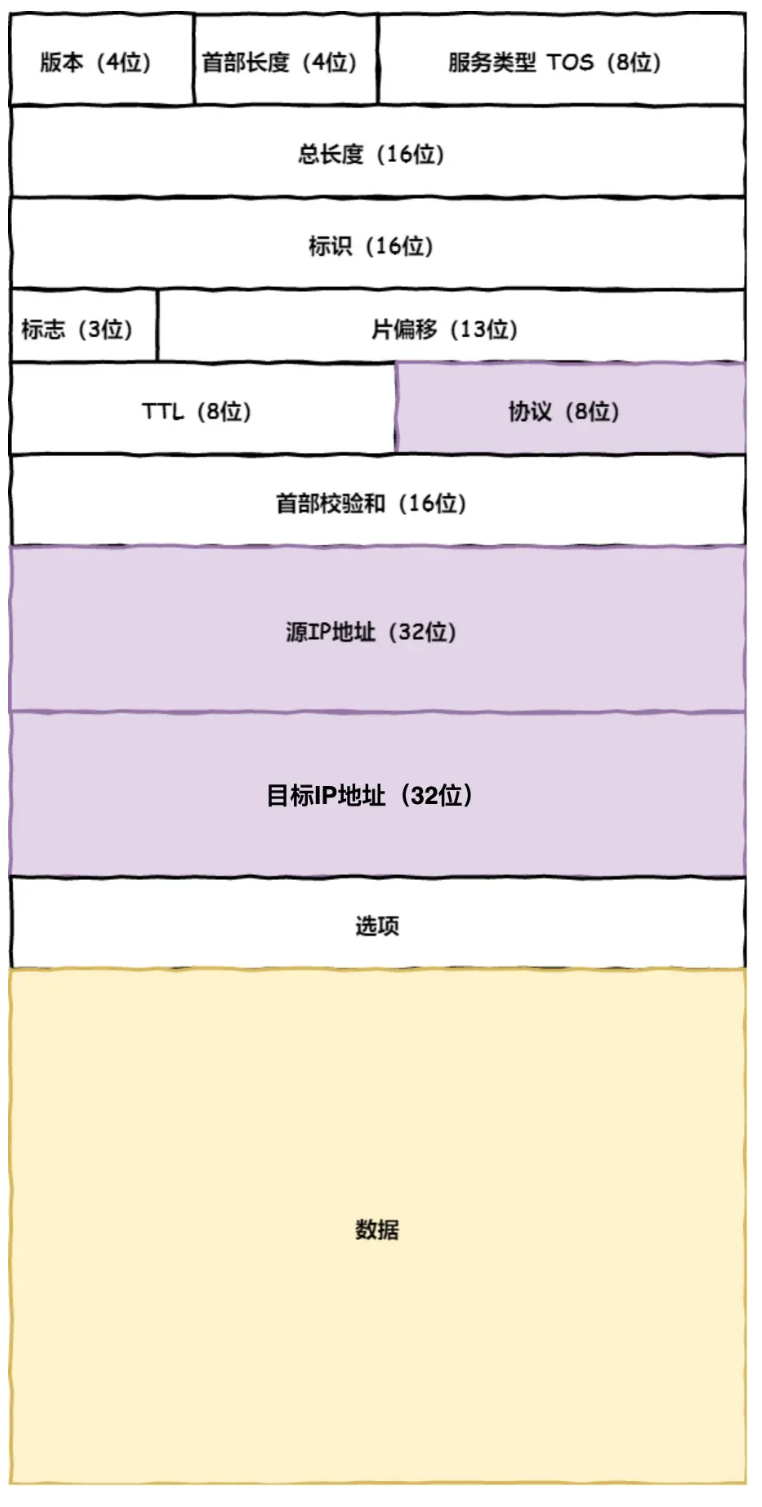
IP 包头格式:
源地址IP:客户端输出的IP地址
目标地址:通过DNS域名解析得到的Web服务器IP
协议号:因为HTTP是经过TCP传输的,所以在IP包头的协议号,要填写为06(十六进制),表示协议为TCP。
数据:就是TCP报文。
![IP包头]()
如果客户端有多个网卡,就会有多个IP地址,那IP头部的源地址应该选择哪个IP呢?
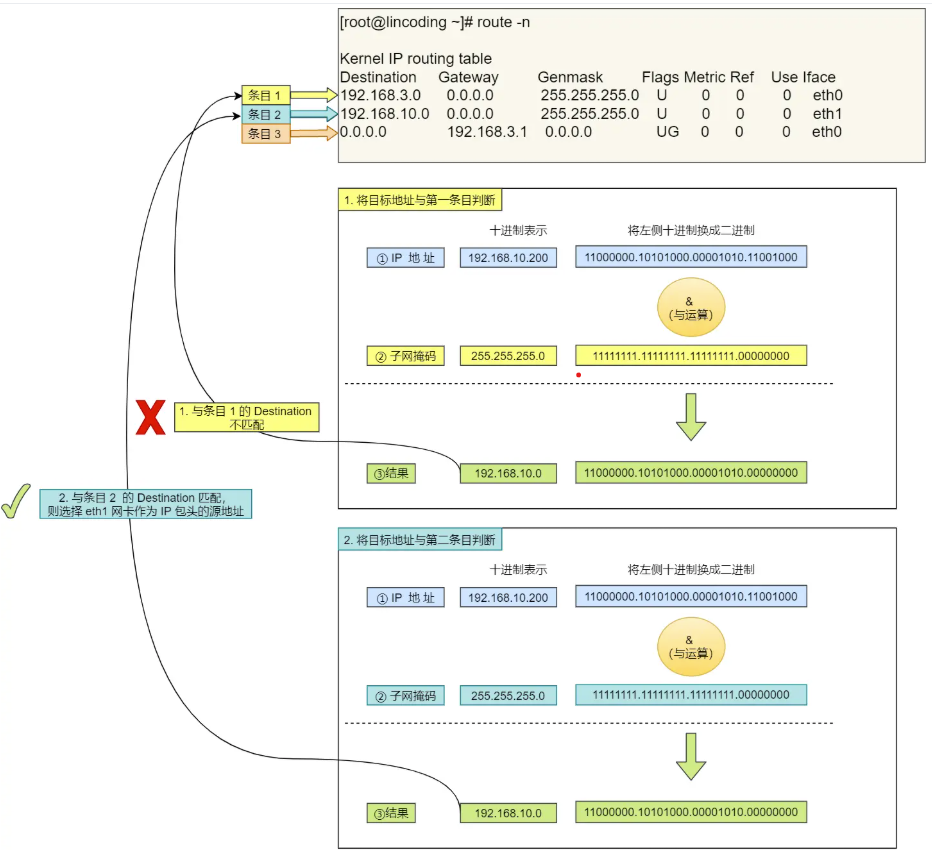
根据路由表规则,判断哪一个网卡作为源地址IP。在 Linux 操作系统中,通过route -n命令查看当前系统路由表。
例如:
![路由表]()
根据上面的路由表,我们假设 Web 服务器的目标地址是 192.168.10.200。
![路由表对应网卡]()
第三条目比较特殊,它目标地址和子网掩码都是 0.0.0.0 ,表示默认网关,如果其他所有条目都无法匹配,就会自动匹配这一行。并且后续就把包发给路由器,Getway即使路由器的IP地址。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号