




数据采集与融合技术第六次作业
作业①
1)BeautifulSoup方法爬取豆瓣电影实验
1、实验要求:用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据;每部电影的图片,采用多线程的方法爬取,图片名字为电影名;了解正则的使用方法
2、编程思路:
3、完整代码:
from bs4 import BeautifulSoup
import urllib.request
from bs4 import UnicodeDammit
import re
import threading
import pymysql
def mySpider(start_url):
global threads
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
#用于多线程爬取图片
urls = []
#定位到图片,多用一个标签a排序二维码的干扰
images = soup.select("a img")
#多线程爬取图片
for image in images:
try:
src = image["src"]
name = image['alt']
url = urllib.request.urljoin(start_url, src)
if url not in urls:
print(url)
T = threading.Thread(target=download, args=(url, name))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
#爬取除图片之外的其他数据,每个电影的数据都包在一个li标签对中
lists = soup.select("ol[class='grid_view'] li")
for li in lists:
rank=li.select("div em")[0].contents[0]
name=li.select("div span[class='title']")[0].text
score=li.select("div span[class='rating_num']")[0].text
#[:-3]去掉‘人评价’
number=li.select("div[class='star'] span")[3].text[:-3]
#导演、主演、类型等都杂糅在同一个标签对中,需要手动分割
data=li.select("div p")[0].text.strip().split("\n")
pat = "导演: .*? "
director = re.compile(pat, re.S).findall(data[0])[0][4:]
pat = "主演: .*? "
#有些电影没有主演信息,因此提取时会报错,因此做特判,避免干扰整个程序
try:
Actor = re.compile(pat, re.S).findall(data[0])[0][4:]
except:
Actor=""
date=data[1].strip().split("/")[0]
country=data[1].strip().split("/")[1]
type=data[1].strip().split("/")[2]
#有些引用格式不正确,避免干扰整个程序运行,进行特判
try:
quote=li.select("p span")[0].text
except:
quote=""
print(rank,name,number,score,director,Actor,date,country,type,quote)
#将数据插入数据库表中
try:
cursor.execute("insert into movies values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(rank,name,director,Actor,date,country,type,score,number,quote,name+".jpg"))
connect.commit()
except Exception as err:
print(err)
#下载图片并将图片保存到本地
def download(url,name):
try:
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
fobj=open("images\\"+str(name)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded "+str(name)+ext)
except Exception as err:
print(err)
#初始化操作,定义头、与数据建立连接并建表
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"}
threads=[]
connect = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="a570846984", charset="utf8",
db="mydb")
# 获取游标
cursor = connect.cursor()
# 建表sql语句
sql = """create table movies(排名 varchar(8),电影名称 varchar(64),导演 varchar(64),主演 varchar(64),上映时间 varchar(64),
国家 varchar(64),电影类型 varchar(64),评分 varchar(64),评价人数 varchar(64),引用 varchar(64),
文件路径 varchar(64))ENGINE=InnoDB DEFAULT CHARSET=utf8"""
cursor.execute(sql)
connect.commit()
#通过分析url变化,得到翻页的规律:每页25个电影,url以这页第一个电影排名来命名,通过url来进行翻页
for i in range(0,250,25):
url="https://movie.douban.com/top250?start="+str(i)+"&filter="
mySpider(url)
4、实验结果截图:
控制台截图:多线程爬取

数据库截图:
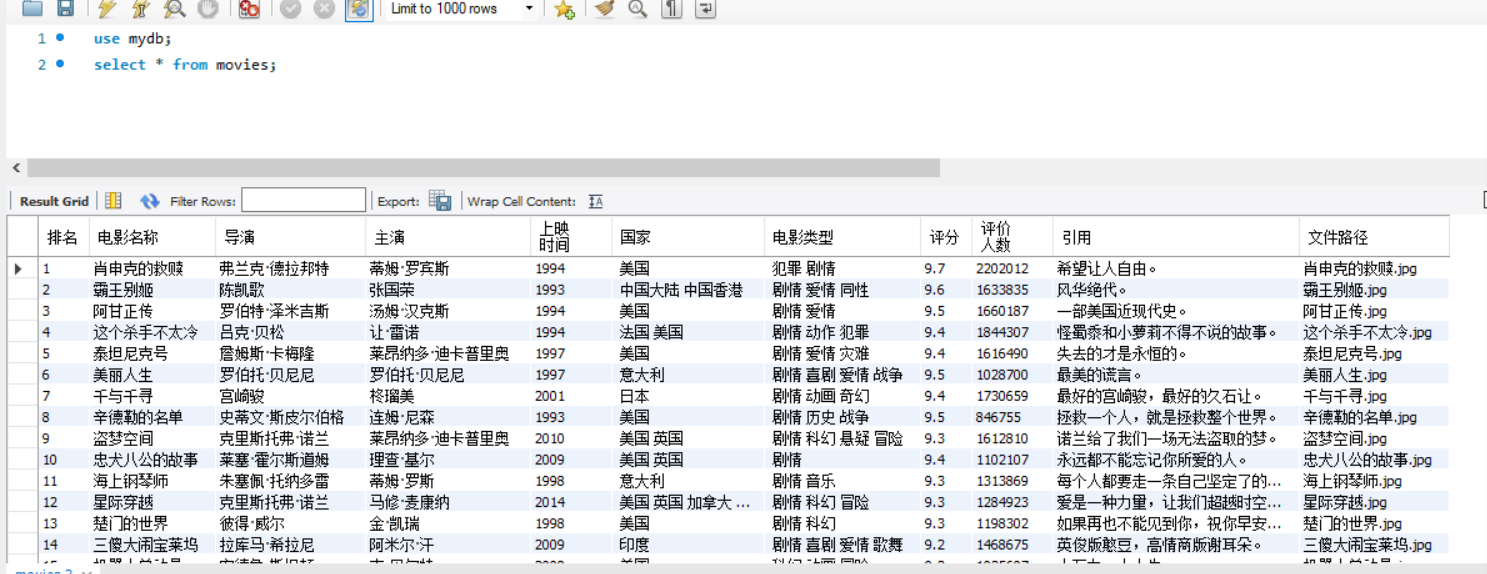
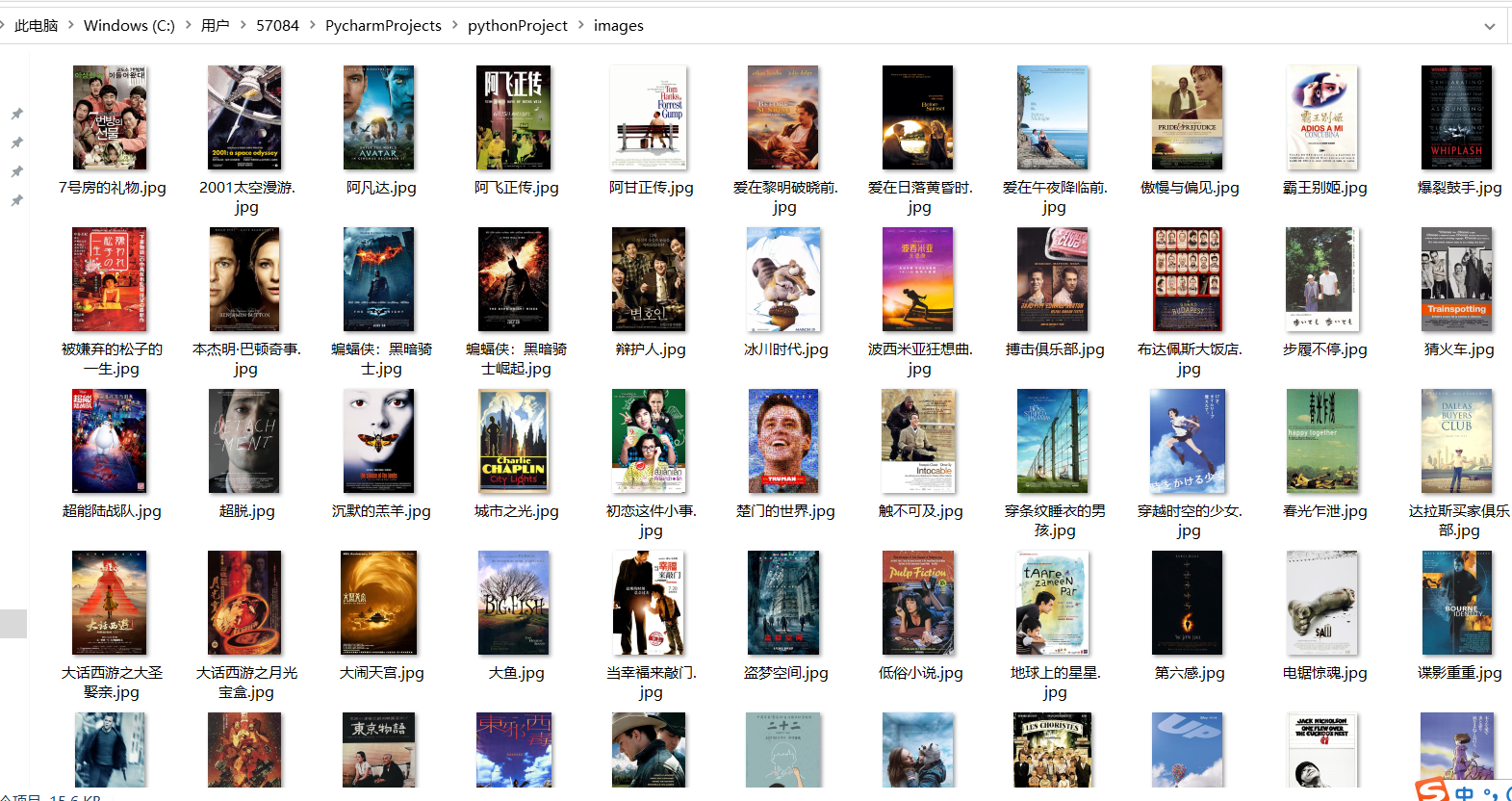
电影图片截图:
2)心得体会
本次实验是对之前很早的知识的复习。之所以说很早,因为我已经完全忘记了。在习惯了selenium之后,再倒回来使用最原始的BeautifulSoup,就感觉非常不习惯,也感觉非常的不方便,甚至一时间无从下手,只能一边翻看之前写的代码,一边看书复习定位元素的CSS语法。在慢慢摸索过程中也还算顺利地爬出来了,这很大在于调试器的功劳。编程方法也逐渐转化为面向调试器编程。在有些元素不知道要怎么去定位时,就打开调试器,一步一步地试,然后按照调试器的提示,能够清晰地看到各个方法的返回值,进而定位到最终想要的值。包括在对主演和导演的提取时,由于全部数据都杂糅在同一个标签对下,因此需要使用正则表达式来提取,这是调试器也可以非常方便地对正则表达式进行测试,而不用改一下就要执行一遍程序来print出来,这大大提高了编程的效率。所以大部分问题都在调试过程中就规避掉了,只有以下两个问题:
1、在下载图片时,出现了一个不速之客:

乱入了一张绿绿的二维码,这显然不是我想要爬取的。倒回去网页中检查时发现,这张二维码,也是img标签,和我一开始提取的方法(images = soup.select("img"))是符合的:

因此自然会被爬取下来。把它和我想要的图片进行对比:

发现想要的图片的上一级标签是a,而二维码上一级是div,因此更改提取条件为images = soup.select("a img"),成功规避了那张扎眼的图片。
2、在爬取过程中报数组越界

根据报错提示,回去网页中检查,发现有些电影居然没有主演(难以理解),给爬取造成困难。解决方法是加入try-except方法特判,对出问题的主演把这条数据置为空值,不影响整个程序运行。
作业②
1)Scrapy+Xpath+MySQL爬取大学排名实验
1、实验要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息;爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
2、编程思路:
3、完整代码:
- items:items定义所需的数据结构,本次实验中需要的数据项为学校的排名sNo、学校的名称schoolName、学校所在的城市city、学校的官网网址officialUrl、学校的简介info和图片存储的相对路径(以图片名命名)
import scrapy
class SchoolItem(scrapy.Item):
#按照爬取的需求定义所需要的数据结构
sNo=scrapy.Field()
schoolName=scrapy.Field()
city=scrapy.Field()
officialUrl=scrapy.Field()
info=scrapy.Field()
myFile=scrapy.Field()
- spider:spider用于发送爬取请求,并提取爬取到的数据,将数据封装在items中,传送给pipelines。在本次实验中,其他数据项都正常的采用items封装好传给pipeline处理,而图片的数据没有以二进制封装在items中传给pipeline处理,而是直接在spider的download的方法中同时下载同时存放到本地处理,原因是爬取图片需要发送新一轮的请求,而scrapy是以流水线的形式进行,因此爬下来的图片没有办法和其他数据在同一批次得到,也就没有办法封装在同一组item中传给pipeline,这样传过去的就是乱的,所以直接在spider中下载后直接处理比较方便
import scrapy
from school.items import SchoolItem
import urllib
class MySpider(scrapy.Spider):
name="mySpider"
#发送初始爬取请求,获取起始页面信息,回调函数为parse
def start_requests(self):
yield scrapy.Request(url='https://www.shanghairanking.cn/rankings/bcur/2020', callback=self.parse)
#在起始页面信息中定位到各个学校的跳转链接,分别进行跳转,发送新的爬取请求,回调函数为parse1
def parse(self, response, **kwargs):
data = response.body.decode()
selector = scrapy.Selector(text=data)
addresses=selector.xpath("//table[@class='rk-table']/tbody/tr")
for address in addresses:
yield scrapy.Request(url="https://www.shanghairanking.cn"+address.xpath("./td/a/@href")[0].root,callback=self.parse1)
#在各个学校的页面爬取想要的数据项,同时获取到校徽的网址
def parse1(self, response, **kwargs):
data = response.body.decode()
selector = scrapy.Selector(text=data)
item=SchoolItem()
item["schoolName"]=selector.xpath("//div[@class='info-container']/table/tbody/tr/td/div/text()")[0].root
item["officialUrl"]=selector.xpath("//div[@class='info-container']/table/tbody/tr[2]/td/div/a/@href")[0].root
item["sNo"]=selector.xpath("//div[@class='info-container']/table/tbody/tr[4]//div/a/text()")[0].root
#提取“某某市排名”前两位作为城市名
item["city"]=selector.xpath("//div[@class='science-ranks']/div[2]/div[2]/text()")[0].root[:2]
item["info"]=selector.xpath("//div[@class='univ-introduce']/p/text()")[0].root
item["myFile"]=selector.xpath("//div[@class='info-container']/table/tbody/tr/td/img/@src")[0].root
#由于使用回调函数的方法无法将学校名传给download,进而无法用学校名命名,因此直接调用download方法
self.downdoad(pictureurl=item["myFile"],schoolname=item["schoolName"])
yield item
#根据传过来的url和图片名称,下载图片
def downdoad(self,pictureurl,schoolname):
req = urllib.request.Request(pictureurl)
data = urllib.request.urlopen(req)
data = data.read()
try:
#使用路径+编号+后缀打开文件,wb+表示若文件不存在则创建,且以byte字符方式写入,[-4:]提取形如".jpg"的后缀
fobj = open("C:\\Users\\57084\\example\\images\\"+schoolname+pictureurl[-4:], "wb+")
except Exception as err:
print(err)
try:
fobj.write(data)
except Exception as err:
print(err)
print("download"+schoolname+pictureurl[-4:])
- pipelines:pipelines处理传送过来的items数据,建立与数据库的连接,使用sql语言创建表,并将items数据插入到MySQL数据库中。
import pymysql
class SchoolPipeline:
#与数据库建立连接
connect = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="a570846984", charset="utf8",
db="mydb")
# 获取游标
cursor = connect.cursor()
# 建表sql语句
sql = """create table school(sNo varchar(8),schoolName varchar(64),city varchar(64),officialUrl varchar(64),info varchar(512),
myFile varchar(64))ENGINE=InnoDB DEFAULT CHARSET=utf8"""
# 执行sql语句
try:
cursor.execute(sql)
except:
pass
def process_item(self, item, spider):
try:
# 插入数据
self.cursor.execute("insert into school values(%s,%s,%s,%s,%s,%s)",
(item["sNo"],item["schoolName"],item["city"],item["officialUrl"],item["info"],item["schoolName"]+item["myFile"][-4:]))
#将sql语句提交到数据库执行,否则无法执行
self.connect.commit()
except Exception as err:
print(err)
return item
4、实验结果截图:
控制台截图:爬取的过程是随机的,并非按学校排名顺序

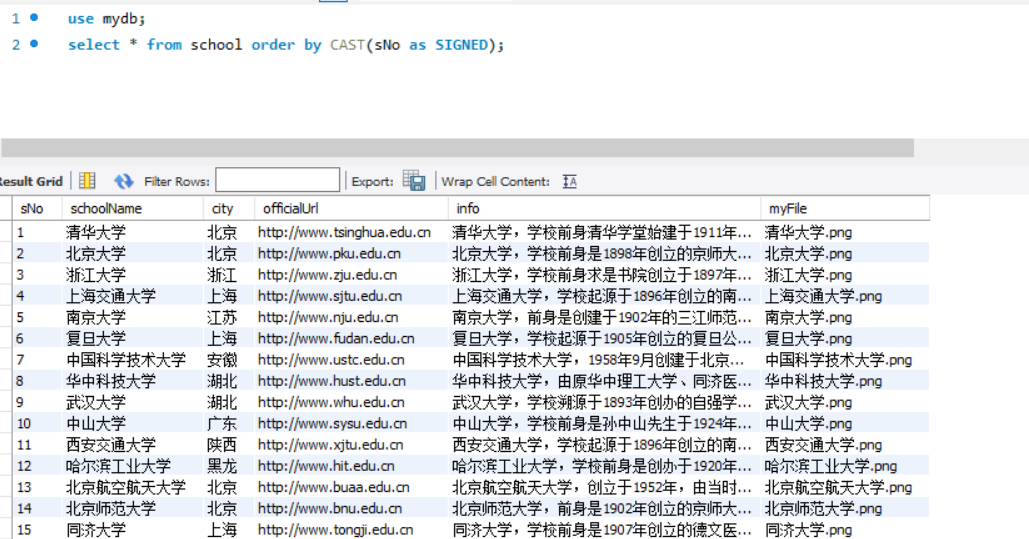
数据库截图:使用sql语言让数据按学校排名排序
logo图片截图:

2)心得体会
本次实验是复习之前学习的scrapy框架,和第一题一样,在用惯了selenium这个神器之后,用其他的爬虫方法都感觉非常的不习惯,尤其是页面跳转时,还在想着怎么点击去跳转,没反应过来应该去看url来跳转。熟悉了之后问题就不大了,就是越来越习惯于面向调试器编程,在定位元素时参考调试器能有意想不到的效果,如下图:
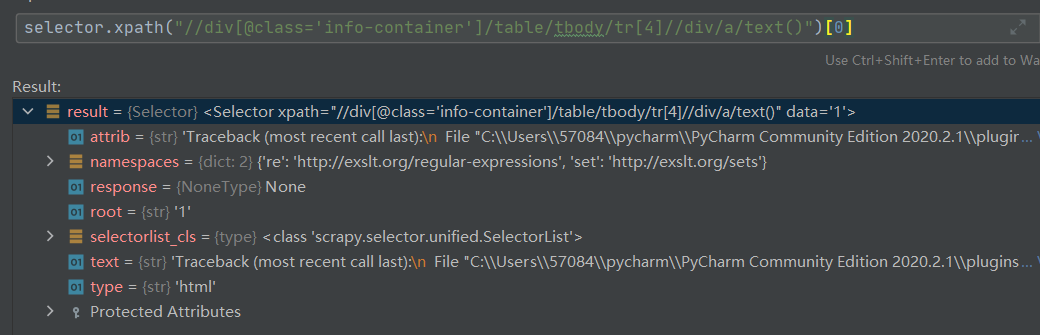
之前从来没有用过root这个方法,也不知道什么意思,但是调试器告诉我这个方法能得到我想要的数据“排名”,在使用了之后:
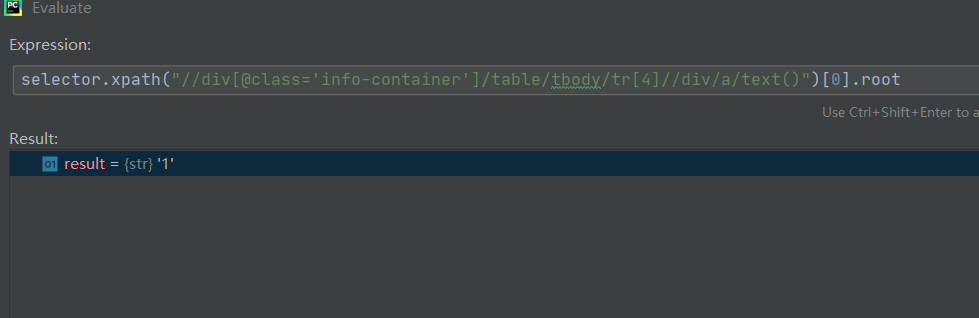
这样就能很清晰的定位到自己想要的元素,也不会担心会错。这种方法非常适合在语法不太熟练的时候使用
作业③
1)Selenium爬取mooc网站实验
1、实验要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容;使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。;其中模拟登录账号环节需要录制gif图。
2、编程思路:
3、完整代码:
代码解释:爬虫过程封装成一个类MySider,需要传入类的参数为待爬取页面的url和登录页面的url,同时在类中通过控制台输入获取待爬取的关键字、账号和密码。类中包括5个方法:
- init:init方法初始化整个爬虫程序,对driver进行定义和初始化、与mysql数据库进行连接并创建数据表、以及定义一些类变量如页数、序号等
- login:login方法实现了用户登录的过程,通过用户在命令行输入的账号和密码去点击对应的按钮并填入账号密码进行登录
- prepare:prepare方法主要是对登录后的弹窗进行处理,并点击我的课程按钮进入待爬虫的页面准备爬虫
- download:download方法为主要的爬虫过程,实现了爬取当页数据并存到数据库中、翻页然后递归调用自身直到爬取到最后一页
- process:process方法整合其他方法,并接收用户输入的账号、密码和关键词,使程序按init、login、choose、download的顺序执行
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
import time
import pymysql
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
def init(self):
print("初始化爬虫中......")
chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.page = 0
self.no=0
try:
#与数据库建立连接
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="a570846984", charset="utf8",
db="mydb")
self.cursor = self.con.cursor()
try:
# 如果有表就删除
self.cursor.execute("drop table mooc")
except:
pass
try:
#建立数据表
sql = """create table mooc2(Id varchar(16),cCource varchar(128),cCollege varchar(128),learnedclass varchar(128),
overtime varchar(128))ENGINE=InnoDB DEFAULT CHARSET=utf8"""
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
print("初始化完成,准备进行登录")
def login(self,account,password,url):
print("登录中")
#获取登录页面
self.driver.get(url)
self.driver.find_element_by_xpath("/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[2]/div/div/div/a").click()
#点击“以其他登录方式登录”按钮(否则要扫码登录)
self.driver.find_element_by_xpath("/html/body/div[13]/div[2]/div/div/div/div/div[2]/span").click()
#点击手机号登录按钮切换至手机号登录
self.driver.find_element_by_xpath("/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[1]/ul/li[2]").click()
#由于登录框是一个弹出窗口,需要切换frame,否则会找不到元素
self.driver.switch_to.frame(self.driver.find_element_by_xpath("/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div/iframe"))
#定位到输入账号的位置,输入账号
self.driver.find_element_by_xpath("//*[@id='phoneipt']").send_keys(account)
#定位到输入密码的位置,输入密码
self.driver.find_element_by_xpath("/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]").send_keys(password)
#点击登录按钮
self.driver.find_element_by_xpath("/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a").click()
print("登录成功")
def prepare(self,url):
time.sleep(3)
#由于登录之后会有弹窗,需要点击确定,否则无法点击到我的课程,但有时又没有弹出,因此使用try-except,有弹出时点击,没有时跳过
try:
self.driver.find_element_by_xpath("//*[@id='privacy-ok']").click()
except Exception as err:
pass
#点击我的课程
self.driver.find_element_by_xpath("/html/body/div[4]/div[2]/div[1]/div/div/div[1]/div[3]/div[4]/div").click()
def download(self):
try:
#统计爬取的当前页
self.page+=1
print("爬取第{}页".format(self.page))
datalist = self.driver.find_elements_by_xpath("//div[@class='course-card-wrapper']")
time.sleep(2)
#爬取的各个课程数据列表
try:
for data in datalist:
#我的课程页面中能爬取到的数据有课程名、开课学校、已学习课时和结束时间
cCource=data.find_element_by_xpath(".//span[@class='text']").text
cCollege=data.find_element_by_xpath(".//div[@class='school']/a").text
learnedclass=data.find_element_by_xpath(".//span[@class='course-progress-text-span']").text
overtime=data.find_element_by_xpath(".//div[@class='course-status']").text
self.no+=1
self.cursor.execute("insert into mooc2 values(%s,%s,%s,%s,%s)", (self.no,
cCource, cCollege, learnedclass,overtime))
self.con.commit()
print(cCource)
except Exception as err:
print(err)
time.sleep(2)
try:
#查找是否可以翻页,如果找到不可翻页标记则说明到了最后一页,程序结束,否则进入except
self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']/a[@class='th-bk-disable-gh']")
print("爬取结束")
except:
#点击翻页,然后递归调用download
nextpage=self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']/a[@class='th-bk-main-gh']")
nextpage.click()
time.sleep(3)
self.download()
except Exception as err:
print(err)
def prccess(self,url):
self.init()
#在控制台让用户输入账号和密码
print("请输入账号:")
account = input()
print("请输入密码:")
passward = input()
self.login(account,passward,url)
self.prepare(url)
self.download()
url="https://www.icourse163.org"
spider=MySpider()
spider.prccess(url)
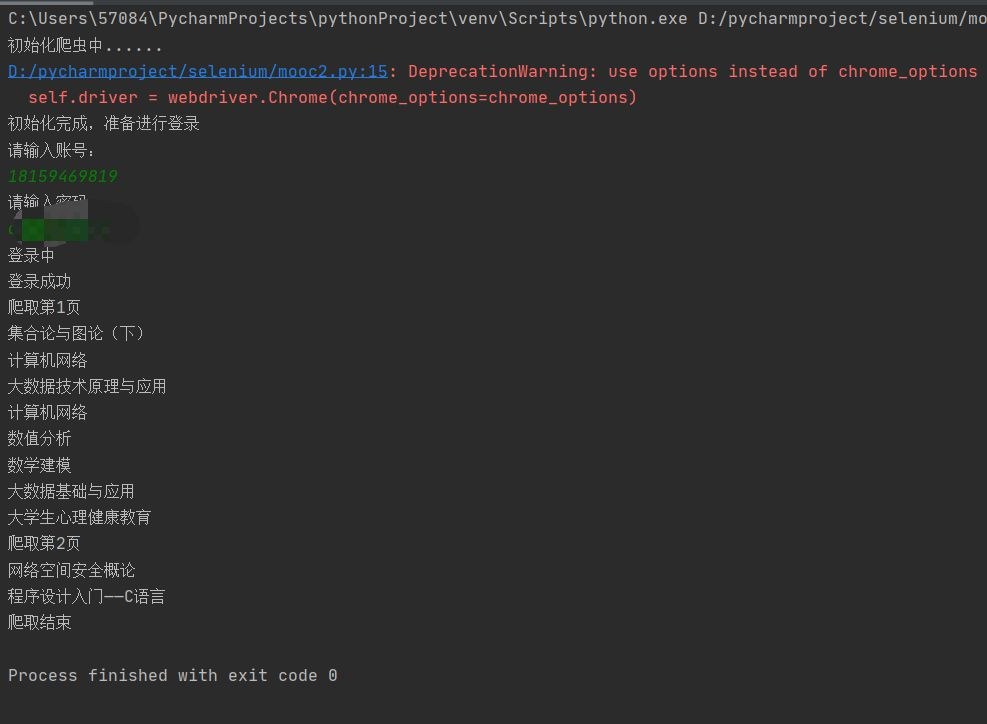
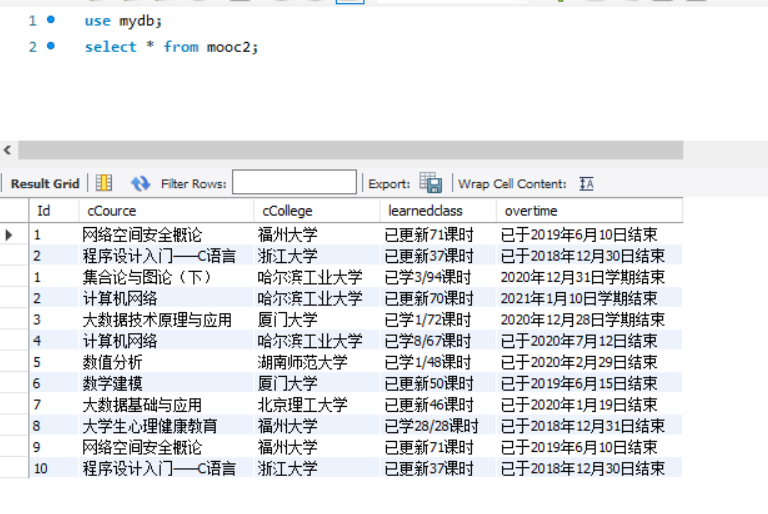
4、实验结果截图:
-
控制台截图:用户在终端输入,密码部分打码
![]()
-
数据库截图:使用select语句查询mooc2表中数据
![]()
-
模拟用户登录动图
![]()
2)心得体会
这次实验是对上一次实验的完善和改进,再上一次实验中由于直接在本页面登录切换框架等很麻烦,所以我小小的走江湖了一下,采用在mooc提供的单独的登录界面而非登录框中登录,但是要切换url。而这一次需要登录后爬取自己账户中的课程,因此只能老老实实地在本页面登录。在认真分析一个按钮一个按钮的路径之后,还是成功地登录进去爬取。爬取的部分就比较简单,由于学得课程不多,只有两页,所以爬取的时间也比上一次作业少很多。主要碰到了以下问题:
1、弹窗的干扰。
如下图:
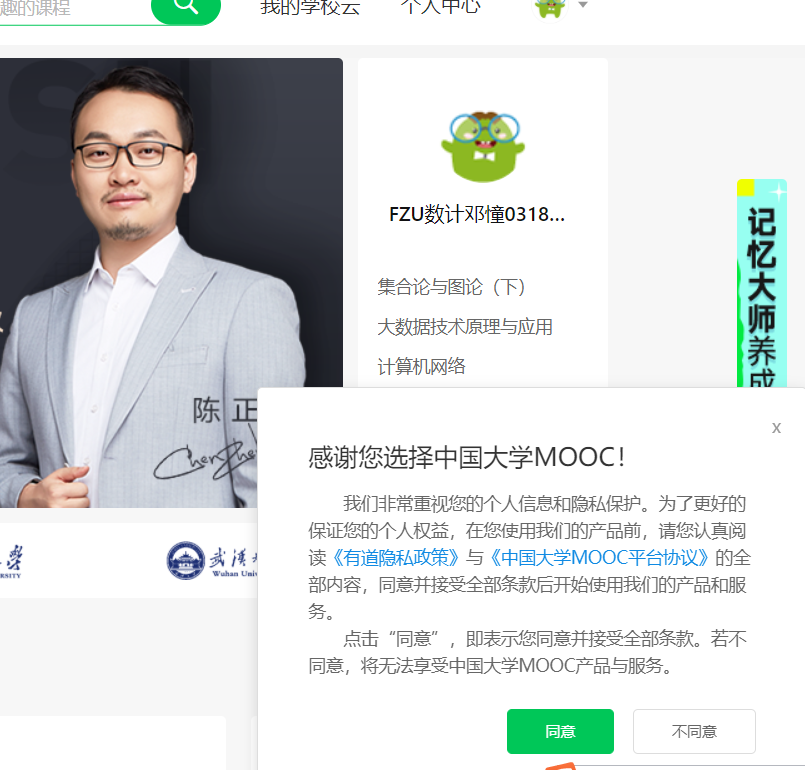
在登录成功之后,页面中会弹出这样的窗口,如果不点同意或者叉掉,直接定位我的课程按钮的话,是没有办法定位到的。因此还得写代码先处理这个页面的按钮。如果仅仅是点一个按钮倒也不难,讨厌的地方是这个框非常地随性(不讲武德),有的时候弹出来,有的时候又不弹出来,如果代码按弹出来处理,那在它没有弹出来的时候又会报错,因为定位不到这个框里的元素。最后想起了之前对数据库表的创建和删除操作的处理,使用了try-except方法,成功解决了这个问题。

这让我对于try-except的强大之处又有了进一步的认识,它不仅可以用于检查异常,更可以用来处理一些特殊的情况,对特殊情况特判或者过滤掉,包括在爬取过程中有一些干扰项也可以用它来过滤。
2、验证码的出现
如下图:
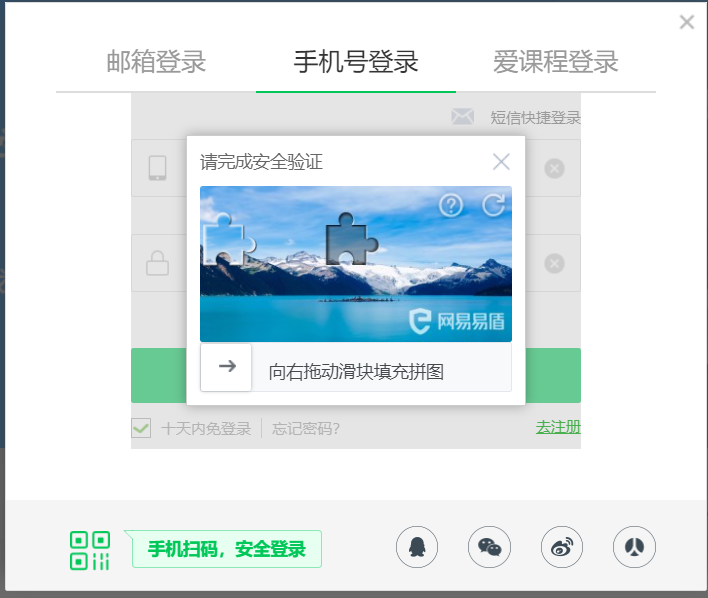
在频繁地登录了几次进行调试之后,登录时就弹出了验证码界面。由于还没有学习到相关的知识,我还没有能力绕过验证码,因此解决方法只能是先不做,等待一段时间之后再登录就不要验证码了。这也说明这门课虽然结束了,但是对于爬虫的学习还远远不够,在今后还要多花时间,去学习一些更高级的爬虫技巧,让爬虫真正成为一个实用而又为我所用的工具。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号