



数据采集与融合技术第五次作业
作业①
1)selenium爬取京东网实验
1、实验要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架爬取京东商城某类商品信息及图片。
2、编程思路:
3、完整代码:(因为图片太多了,总共几千张,因此做了特判,爬取了10页图片,每页30张;另外将数据库部分修改成与mysql数据库进行连接)
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import urllib.request
import threading
import sqlite3
import os
import datetime
from selenium.webdriver.common.keys import Keys
import time
import pymysql
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
imagePath = "download"
def startUp(self, url, key):
# # Initializing Chrome browser
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
# Initializing variables
self.threads = []
self.No = 0
self.imgNo = 0
self.page=0
# Initializing database
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", charset="utf8",db="mydb")
self.cursor = self.con.cursor()
try:
# 如果有表就删除
self.cursor.execute("drop table phones")
except:
pass
try:
# 建立新的表
sql = "create table phones (mNo varchar(32) primary key, mMark varchar(256),mPrice varchar(32),mNote varchar(1024),mFile varchar(256))ENGINE=InnoDB DEFAULT CHARSET=utf8"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
# Initializing images folder
try:
if not os.path.exists(MySpider.imagePath):
os.mkdir(MySpider.imagePath)
images = os.listdir(MySpider.imagePath)
for img in images:
s = os.path.join(MySpider.imagePath, img)
os.remove(s)
except Exception as err:
print(err)
self.driver.get(url)
keyInput = self.driver.find_element_by_id("key")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err);
def insertDB(self, mNo, mMark, mPrice, mNote, mFile):
try:
sql = "insert into phones values (%s,%s,%s,%s,%s)"
self.cursor.execute(sql, (mNo, mMark, mPrice, mNote, mFile))
self.con.commit()
except Exception as err:
print(err)
print(1)
def showDB(self):
try:
con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="a570846984", charset="utf8",db="mydb")
cursor = con.cursor()
print("%-8s%-16s%-8s%-16s%s" % ("No", "Mark", "Price", "Image", "Note"))
cursor.execute("select mNo,mMark,mPrice,mFile,mNote from phones order by mNo")
rows = cursor.fetchall()
for row in rows:
print("%-8s %-16s %-8s %-16s %s" % (row[0], row[1], row[2], row[3], row[4]))
con.close()
except Exception as err:
print(err)
def download(self, src1, src2, mFile):
data = None
if src1:
try:
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if data:
print("download begin", mFile)
fobj = open(MySpider.imagePath + "\\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)
def processSpider(self):
try:
if(self.page>=10):
return ;
time.sleep(1)
print(self.driver.current_url)
lis = self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
for li in lis:
# We find that the image is either in src or in data-lazy-img attribute
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("爱心东东\n", "")
mark = mark.replace(",", "")
note = note.replace("爱心东东\n", "")
note = note.replace(",", "")
except:
note = ""
mark = ""
self.No = self.No + 1
no = str(self.No)
while len(no) < 6:
no = "0" + no
print(no, mark, price)
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
if src1 or src2:
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
self.insertDB(no, mark, price, note, mFile)
try:
self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next disabled']")
except:
self.page+=1
nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
#time.sleep(10)
nextPage.click()
self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, url, key):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url, key)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
for t in self.threads:
t.join()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "http://www.jd.com"
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
spider.executeSpider(url, "手机")
continue
elif s == "2":
spider.showDB()
continue
elif s == "3":
break
4、实验结果截图:
控制台输出:

数据库截图:

下载的图片截图:
2)心得体会
本次实验是复现实验,由于一开始不理解代码,而且老师的代码各方面都封装得比较完美(包括用户交互、数据库表的存在删除、图片存在删除等等),导致代码量很大,理解起来有点困难,因此复现过程中出现了很多问题,且大多是由缩进造成的。主要出现的问题如下:
1、
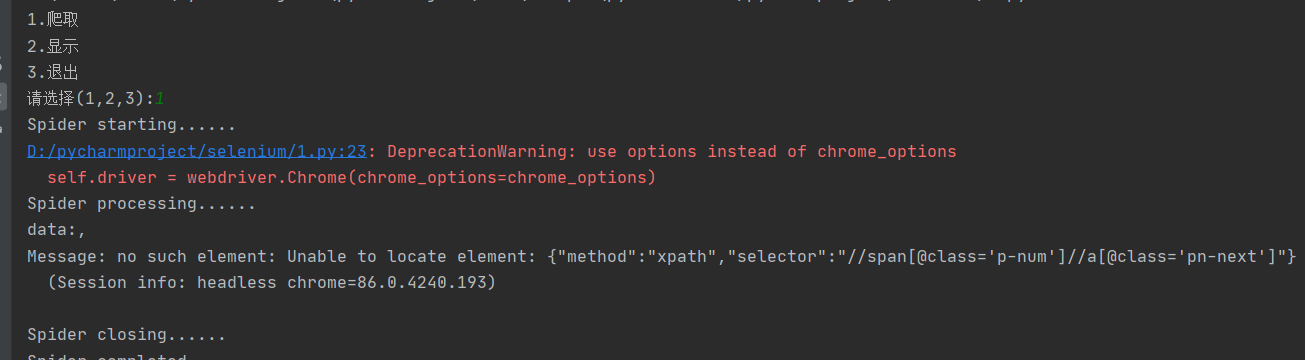
打开调试器打断点后发现问题所在:list值为空。一开始以为是之前老师上课讲的那种由于网速等原因数据还没提取到的问题,因此在几个地方sleep,但都没有效果。一直找不到解决的方法,一直在debug,而在一次调试偶然之间居然错误消失了,并报异常无法删除debug.log文件。重新检查代码后发现:
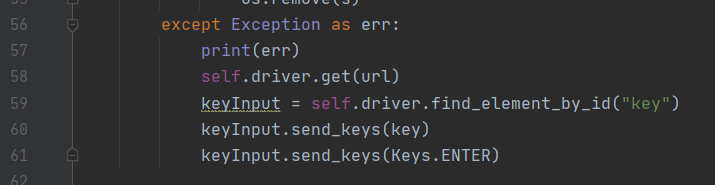
是缩进的问题,缩进错误导致代码只有在出异常的时候才把key输入到输入框,正常的时候反而无法执行,把缩进改了后问题解决(瞎猫碰到死耗子调bug)
2、爬取过程爬到80个数据以后就爬不到数据

认真理解代码,理清了逻辑之后,发现依旧是缩进的问题。正确的思路应该是打开一页,程序对应执行一次processSpider>>提取该页的list>>遍历list(一页30张),依次爬取下30张图片,程序对应执行一次循环>>翻页,继续爬取下一页,直到没有下一页。
而因为一开始不理解代码导致了循环体缩进错误,程序的逻辑变为打开一页,程序执行processSpider>>提取该页的list,但遍历了第一个元素后,开始判断是否有下一页,然后进行了翻页
这就等于每次processSpider只爬取下了一页的第一张图片后就翻页,总共51页,爬取了前50页的各一张,最后一页的时候没有下一页了,所以执行了完整的循环,爬取了30张,之后函数的开始递归地回调,此时的url已经全乱了,因此只爬取到了缺省值0.
3、总结:复现实验也要在理解的基础上复现,直接Ctrl C Ctrl V会出现很多问题。
作业②
1)selenium爬取股票数据实验
1、实验要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
2、编程思路:
3、完整代码:
代码解释:整个爬虫过程封装成MySpider类,需要传入类的数据只有待爬取网页的url,而需要选择的股票类型则在类里实现,通过在终端输入获取。类中包括4个方法:
- init:init方法初始化整个爬虫程序,对driver进行定义和初始化、与mysql数据库进行连接并创建数据表、以及定义一些类变量如页数、序号等
- choose:choose方法通过把传进来的key封装成xpath相关路径,点击对应按钮来选择要爬取的股票类型
- download:download方法为爬取数据的主要过程,实现爬取数据、数据分割并存入数据库中、进行翻页操作直到最后一样
- process:process方法将另外三个方法整合起来,按需要顺序逐步调用,并接收终端输入的数据。其中比较关键的一步是要定义一个字典keydict = {1: "hs_a_board", 2: "sh_a_board", 3: "sz_a_board"}来让股票类型和xpath中的关键词对应
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import pymysql
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
def init(self):
print("初始化爬虫中......")
chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.page=1
try:
#与数据库建立连接
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", charset="utf8",db="mydb")
self.cursor = self.con.cursor()
try:
# 如果有表就删除
self.cursor.execute("drop table shares")
except:
pass
try:
# 建立股票数据表
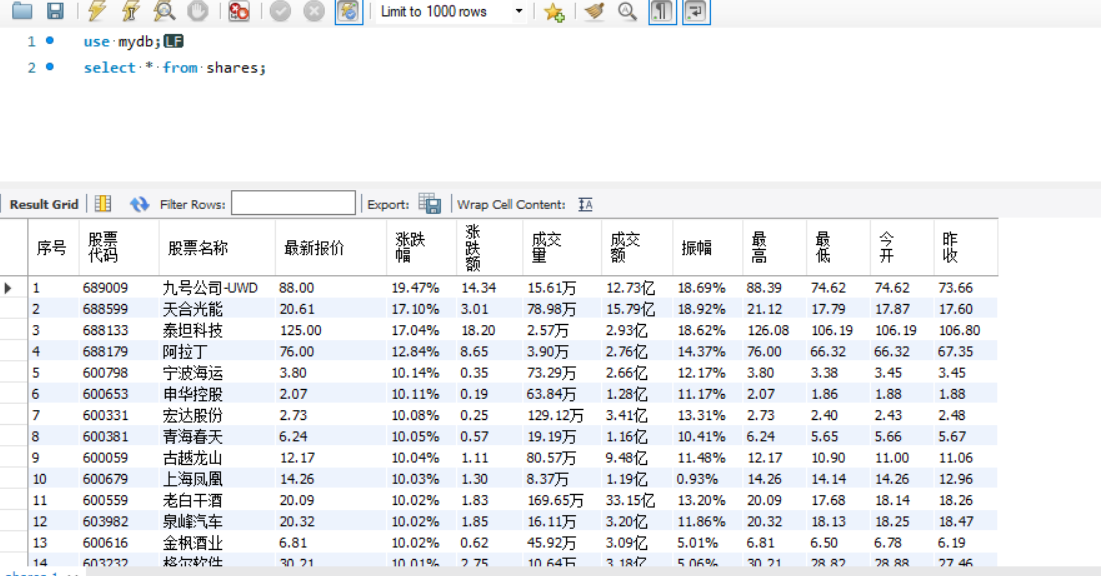
sql="""create table shares(序号 varchar(8),股票代码 varchar(8),股票名称 varchar(10),最新报价 varchar(8),
涨跌幅 varchar(8), 涨跌额 varchar(8),成交量 varchar(64),成交额 varchar(64),振幅 varchar(8),最高 varchar(8),
最低 varchar(8),今开 varchar(8),昨收 varchar(8))ENGINE=InnoDB DEFAULT CHARSET=utf8"""
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
print("初始化完成,准备选择股票类型")
def choose(self,url,key):
#选择爬取的股票类型沪深A股、上证A股、深圳A股
print("正在选择爬取股票类型......")
self.driver.get(url)
try:
#选择股票类型,对输入的key进行拼接成xpath,以定位到不同key对应的按钮位置
path="""//li[@id="nav_"""+key+""""]/a[@href="#"""+key+""""]"""
click=self.driver.find_element_by_xpath(path)
click.click()
time.sleep(3)
except Exception as err:
print(err)
print("选择完成,准备爬取")
def downdownload(self):
#数据实在太多了,200多页每页20条有40000多条,爬不过来,共爬取十页
if(self.page>10):
print("爬取结束")
return
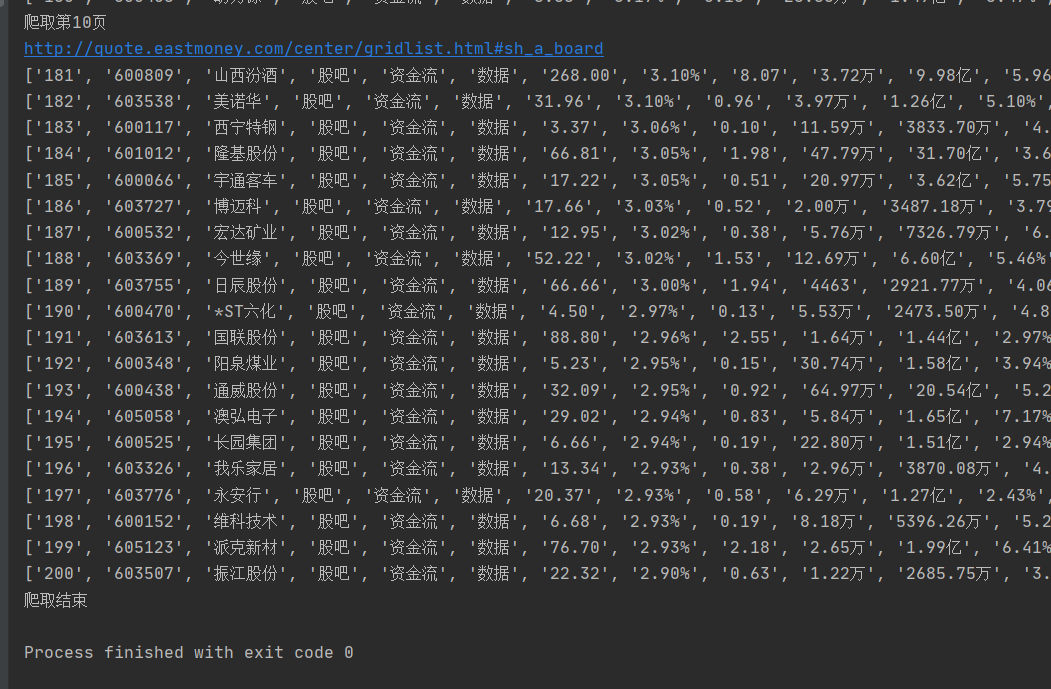
print("爬取第{}页".format(self.page))
print(self.driver.current_url)
try:
#获取数据列表
list=self.driver.find_elements_by_xpath("//table[@id='table_wrapper-table']//tbody//tr")
for li in list:
#对字符串使用split()方法分割成列表,便于存储
li=li.text.split()
#简单记录爬取过程
print(li)
#将数据插入mysql数据库
self.cursor.execute("insert into shares values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",(li[0],
li[1],li[2],li[6],li[7],li[8],li[9],li[10],li[11],li[12],li[13],li[14],li[15]))
self.con.commit()
try:
#查看是否可翻页,不可翻页则结束,若可以翻页则执行except,递归调用download
self.driver.find_element_by_xpath("//a[@class='next paginate_button disable']")
print("爬取结束")
except:
#递归调用download方法进行爬取
self.page+=1
nextpage=self.driver.find_element_by_xpath("//a[@class='next paginate_button']")
nextpage.click()
time.sleep(2)
self.downdownload()
except Exception as err:
print(err)
def process(self,url):
self.init()
#定义钥匙库,即对应key对应的用于检索xpath
keydict = {1: "hs_a_board", 2: "sh_a_board", 3: "sz_a_board"}
print("请输入要爬取的股票类型对应的数字编号:")
print("1:沪深A股 2:上证A股 3:深圳A股")
keyno = eval(input())
key = keydict[keyno]
self.choose(url,key)
self.downdownload()
url="http://quote.eastmoney.com/center/gridlist.html"
Spider=MySpider()
Spider.process(url)
4、实验结果截图:
控制台截图:(用户交互过程)
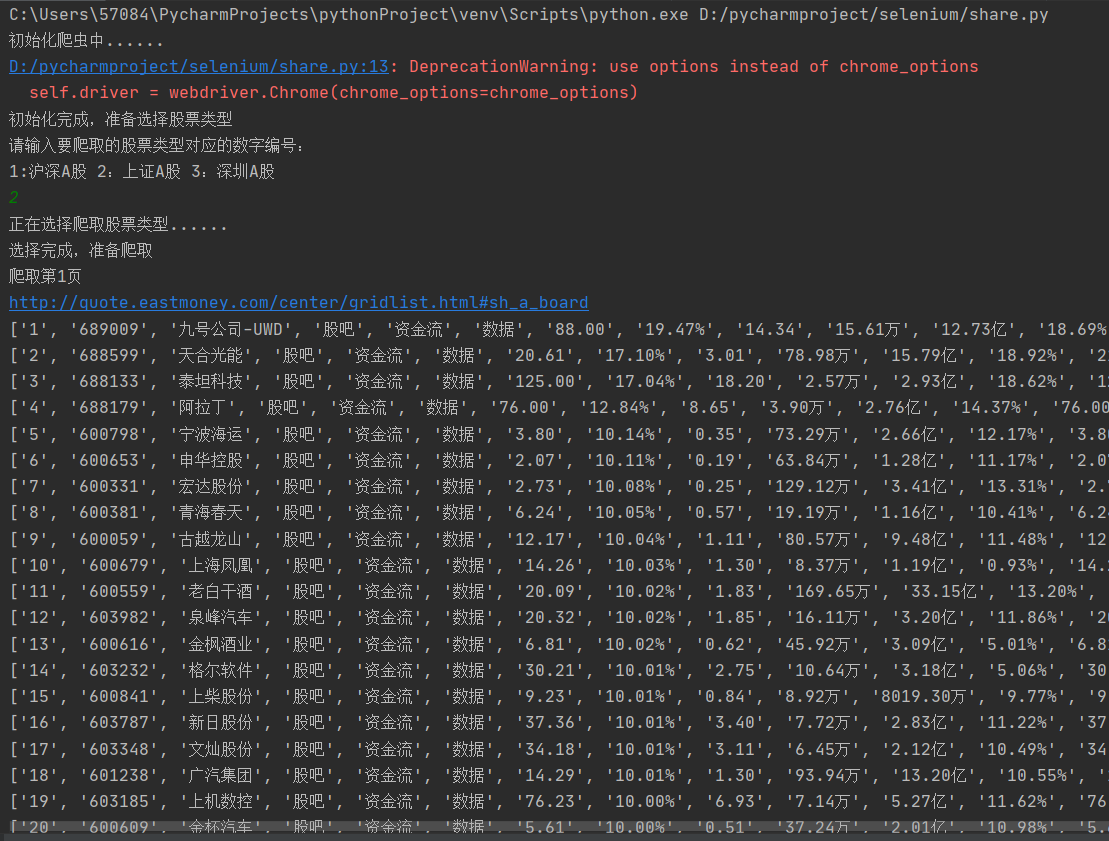
数据库截图:
2)心得体会
本次实验是三个作业中最简单的一个,没有涉及到作业1的下载图片部分,也没有涉及到作业3的用户登录部分,而且数据都在同一个标签对下,获取起来非常方便,在理解了第一题的基础上,做起来比较顺畅,只碰到了一个异常:Message: stale element reference: element is not attached to the page document。调试了一会儿之后明白了是页面还没有加载完成就开始爬取,导致爬取不到数据。只要在click之后加上sleep,让它睡2s就可以了
总结:
1、更加理解了selenium是完全模仿人在上网,页面在跳转的时候该等待就得等待,不然可能会爬取不到数据。一般click之后都可以停个一两秒
2、在爬取时把driver设置为可见可以更好的观察爬虫过程,容易发现bug出在哪,而且看着鼠标自己点感觉特别爽
3、再次熟练了面向对象编程的思路,通过定义一个类实现多个方法,使用self进行方法直接的互通,相比于长长的一整串代码,既容易修改错误,又使整个逻辑清晰,让整个编程变得很流畅很美观(强迫症患者及其舒适)
作业③
1)selenium爬取mooc网实验
1、实验要求:熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
2、编程思路:
3、完整代码:
代码解释:爬虫过程封装成一个类MySider,需要传入类的参数为待爬取页面的url和登录页面的url,同时在类中通过控制台输入获取待爬取的关键字、账号和密码。类中包括5个方法:
- init:init方法初始化整个爬虫程序,对driver进行定义和初始化、与mysql数据库进行连接并创建数据表、以及定义一些类变量如页数、序号等
- login:login方法实现了用户登录的过程,通过用户在命令行输入的账号和密码去点击对应的按钮并填入账号密码进行登录
- choose:choose方法通过用户输入的关键词找到搜索框对需要爬取的课程类型进行搜索
- download:download方法为主要的爬虫过程,实现了爬取当页数据并存到数据库中、翻页然后递归调用自身直到爬取到最后一页
- process:process方法整合其他方法,并接收用户输入的账号、密码和关键词,使程序按init、login、choose、download的顺序执行
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
import time
import pymysql
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
def init(self):
print("初始化爬虫中......")
chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.page = 0
self.no=0
try:
#与数据库建立连接
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="a570846984", charset="utf8",
db="mydb")
self.cursor = self.con.cursor()
try:
# 如果有表就删除
self.cursor.execute("drop table mooc")
except:
pass
try:
#建立数据表
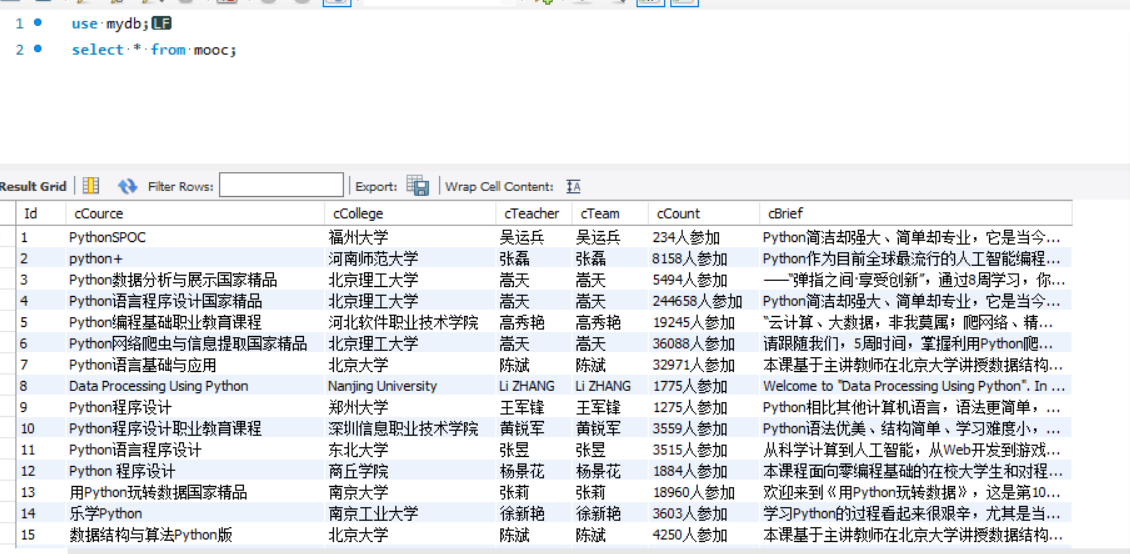
sql = """create table mooc(Id varchar(8),cCource varchar(64),cCollege varchar(64),cTeacher varchar(64),
cTeam varchar(64),cCount varchar(64),cBrief varchar(256))ENGINE=InnoDB DEFAULT CHARSET=utf8"""
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
print("初始化完成,准备进行登录")
def login(self,account,password,loginurl):
print("登录中")
#获取登录页面
self.driver.get(loginurl)
#点击“以其他登录方式登录”按钮(否则要扫码登录)
self.driver.find_element_by_xpath("/html/body/div[4]/div[2]/div/div/div/div/div/div/div/div/div[2]/span").click()
#点击手机号登录按钮切换至手机号登录
self.driver.find_element_by_xpath("/html/body/div[4]/div[2]/div/div/div/div/div/div/div/div/div/div[1]/div/div[1]/div[1]/ul/li[2]").click()
#由于登录框是一个弹出窗口,需要切换frame,否则会找不到元素
self.driver.switch_to.frame(self.driver.find_element_by_xpath("/html/body/div[4]/div[2]/div/div/div/div/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div/iframe"))
#定位到输入账号的位置,输入账号
self.driver.find_element_by_xpath("/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input").send_keys(account)
#定位到输入密码的位置,输入密码
self.driver.find_element_by_xpath("/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]").send_keys(password)
#点击登录按钮
self.driver.find_element_by_xpath("/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a").click()
print("登录成功")
def choose(self,key,url):
#获取网页
print("正在搜索关键词{}......".format(key))
self.driver.get(url)
time.sleep(1)
#定位到搜索框,将关键词输入到搜索框
keyInput = self.driver.find_element_by_xpath("//div[@class='u-baseinputui']/input[@type='text']")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
time.sleep(2)
print("搜索完成,准备开始爬取")
def download(self):
try:
#统计爬取的当前页
self.page+=1
print("爬取第{}页".format(self.page))
#爬取的各个课程数据列表
datalist=self.driver.find_elements_by_xpath("//div[@class='cnt f-pr']")
time.sleep(2)
for data in datalist:
# 有些课程格式不符合规范,如没有开课学校的,使用except略过,否则会因为格式问题报错,影响爬取
try:
#待爬取的各项数据
cCource=data.find_element_by_xpath("./div[@class='t1 f-f0 f-cb first-row']").text
cCollege=data.find_element_by_xpath(".//a[@class='t21 f-fc9']").text
cTeacher=data.find_element_by_xpath(".//a[@class='f-fc9']").text
cTeam=data.find_element_by_xpath(".//a[@class='f-fc9']").text
cCount=data.find_element_by_xpath(".//span[@class='hot']").text
cBrief=data.find_element_by_xpath(".//span[@class='p5 brief f-ib f-f0 f-cb']").text
#统计爬取的课程个数,用做序号数据项
self.no += 1
#将爬取的数据插入到mysql数据库中
self.cursor.execute("insert into mooc values(%s,%s,%s,%s,%s,%s,%s)",(self.no,
cCource,cCollege,cTeacher,cTeam,cCount,cBrief))
#提交到命令行执行
self.con.commit()
#简单记录爬取过程
print(cCource)
except:
pass
try:
#查找是否可以翻页,如果找到不可翻页标记则说明到了最后一页,程序结束,否则进入except
self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']/a[@class='th-bk-disable-gh']")
print("爬取结束")
except:
#点击翻页,然后递归调用download
nextpage=self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']/a[@class='th-bk-main-gh']")
nextpage.click()
time.sleep(3)
self.download()
except Exception as err:
print(err)
def prccess(self,url,loginurl):
self.init()
print("请输入账号:")
account = input()
print("请输入密码:")
passward = input()
self.login(account,passward,loginurl)
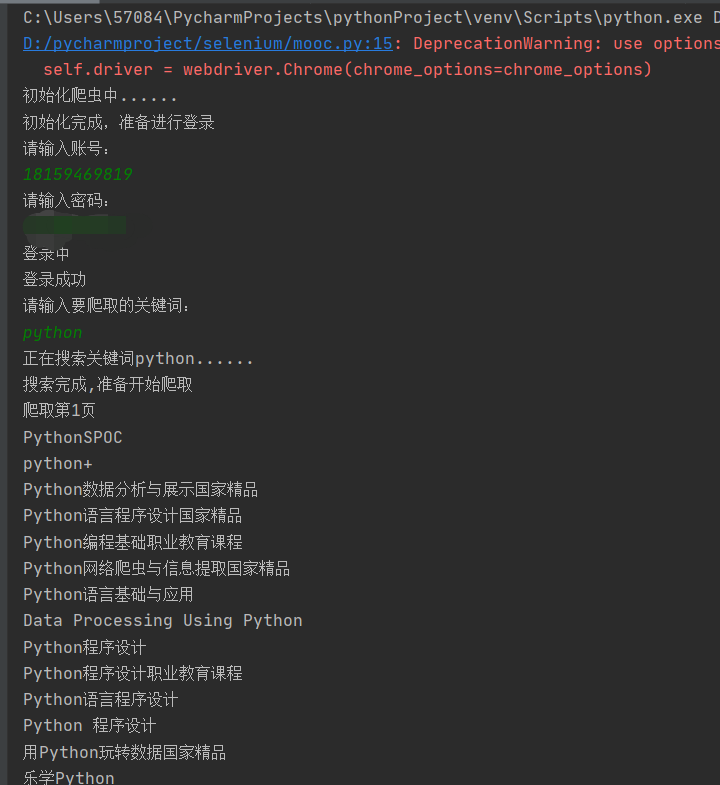
print("请输入要爬取的关键词:")
key=input()
self.choose(key,url)
self.download()
url="https://www.icourse163.org"
loginurl="https://www.icourse163.org/member/login.htm#/webLoginIndex"
spider=MySpider()
spider.prccess(url,loginurl)
4、实验结果截图:
控制台截图:(用户的输入、执行的过程,其中密码部分打了马赛克)

数据库截图:
2)心得体会
本次实验相比于作业2难度有所提升,一方面是mooc需要的各个数据项比较分散,需要一个一个定位来提取,同时用户登录方面花了很多时间才弄好,碰到了比较多的问题,有比较多的体会
1、更深入的理解了xpath的//、/、text的含义,尤其是多标签下有比较分散的文本的情况下,如果定位得标签对比较大,则下面的所有非标签内容都会作为text且没有分割,如果把标签定小一点可以定位到区分好的text列表
2、关于frame的理解。这次作业其他部分花的时间不多,用户登录这一小部分花了我好久的时间。由于一开始不知道有frame这个概念,在用户登录时一直点一直定位都报错找不到元素,使用sleep方法也不管用,卡了很久都没有进展。后面百度了之后才慢慢了解了frame这个概念。由于点击用户登录时有个小弹窗,网页把它定位到了一个新的frame,因此如果没有切换到对应的frame,继续使用原来的frame爬取是爬取不到想要的东西的,所以必须使用driver.switch_to.frame方法切换frame。
3、关于检查元素的使用。之前爬取的时候我都是找到想要爬取的元素,然后老老实实地看他的结构,然后思考怎么写xpath,在看了同学写代码之后才知道,原来可以直接直接复制元素的完整路径(如下图)
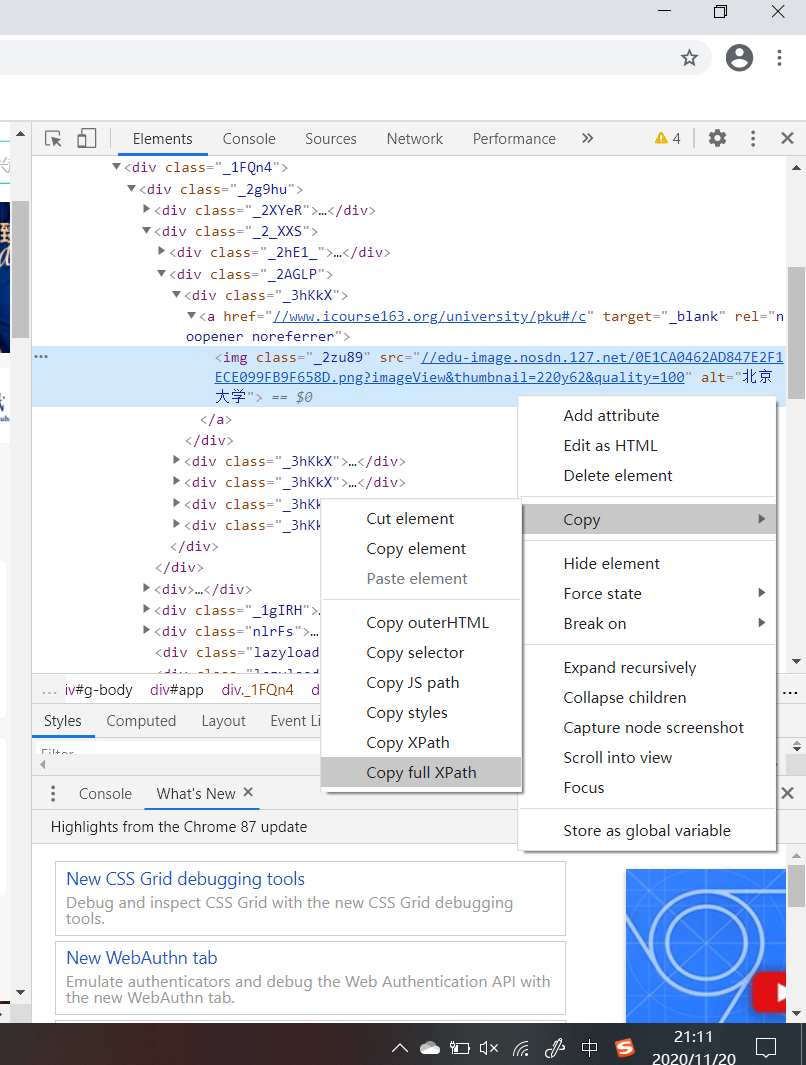
然后把路径当成xpath路径即可。这种方法大大降低了爬虫花费的时间和难度,也提高了定位的准确性,尤其是要提取的元素比较多的时候,一个一个自己写xpath很容易出错。
4、关于selenium的感受:太好用了。再打开了driver可视化之后我才感受到selenium的神奇,他完全就是跟一个人在操作一样,这种自动化的感觉特别舒服,而且也让我对刷课软件有了一定的认识,用selenium框架可以很轻松地完成一个刷课软件的编写,这应该也拓宽了selenium的应用。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号