



数据采集与融合技术第四次作业
作业①
1)Scrapy+Xpath+MySQL爬取当当网数据实验
1、实验要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
2、编程思路:
3、完整代码:
- items:items定义了实验所需的数据类型,输出的结果需要title、author、date、publisher、detail、price六项,因此items需要定义包含该6项的数据结构
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
price = scrapy.Field()
- spider:spider是scrapy框架爬取过程的核心部分,本次实验中,spider需要指定关键词(我选择的关键词是“哈利波特”),然后递归地发送爬取请求,使用scrapy框架中特定的xpath语法提取想要的数据项,将爬取下来的各维度的图书信息封装在items中,通过items传递给pipelines,由pipelines做进一步的处理。
import scrapy
from book.items import BookItem #如果你的目录结构和我不一样注意一下
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider"
key = '哈利波特'
source_url = 'http://search.dangdang.com/'
def start_requests(self): #程序开始时会调用
url = MySpider.source_url+"?key="+MySpider.key+"&act=input"
yield scrapy.Request(url=url, callback=self.parse) # 调用parse函数
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]") # 取到当前页面中所有带有属性ddt-pit的<li>,即每一条书籍
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date = li.xpath("./p[@class='search_book_author']/span[position()=last()-1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
# detail 有时没有,结果为None
item = BookItem()
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else "" # 注意到日期前有一个符号/,所以从1开始取值
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item # 将爬取到的一条记录推送到pipelines.py由process_item函数处理
#最后一页是link为None
link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
print(link)
if link:
url = response.urljoin(link)
print(url)
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
- pipelines:pipelines将收到的items数据进行处理。本次实验要求使用MySQL数据库存储数据,因此pipelines需要使用pymysql与数据库建立连接,然后使用sql语言,完成创建表、插入数据的操作。
from itemadapter import ItemAdapter
import pymysql
class BookPipeline(object):
# 爬虫开始是执行的函数
def open_spider(self, spider):
print("opened")
try:
# 连接数据库,密码写自己的密码
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
#使用try-except创建数据库,若已经存在数据库,则报出异常,跳过
self.cursor.execute("create database mydb")
except:
pass
self.con.select_db("mydb")
try:
#如果表已经存在,则先将其删除,避免之后创建表时报错
self.cursor.execute("drop table books")
except:
pass
try:
#按照所需要的数据库表格式,使用sql语言创建表
sql = """
create table books(
bID varchar(8) primary key,
bTitle varchar(512),
bAuthor varchar(256),
bPublisher varchar(256),
bDate varchar(32),
bPrice varchar(16),
bDetail text
)ENGINE=InnoDB DEFAULT CHARSET=utf8; # 保证建立的表与打开的数据库编码一致
"""
self.cursor.execute(sql)
except:
self.cursor.execute("delete from books")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "本书籍")
def process_item(self, item, spider):
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
if self.opened:
self.count += 1 # 用来构造bID
ID = str(self.count)
while len(ID) < 8:
ID = "0" + ID
# 插入数据到表中
self.cursor.execute(
"insert into books(bID,bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values(%s,%s,%s,%s,%s,%s,%s)",
(ID, item["title"], item["author"], item["publisher"], item["date"], item["price"], item["detail"]))
except Exception as err:
print("wrong error:" + str(err))
return item
4、实验结果截图:
控制台截图(共爬取6000本图书):
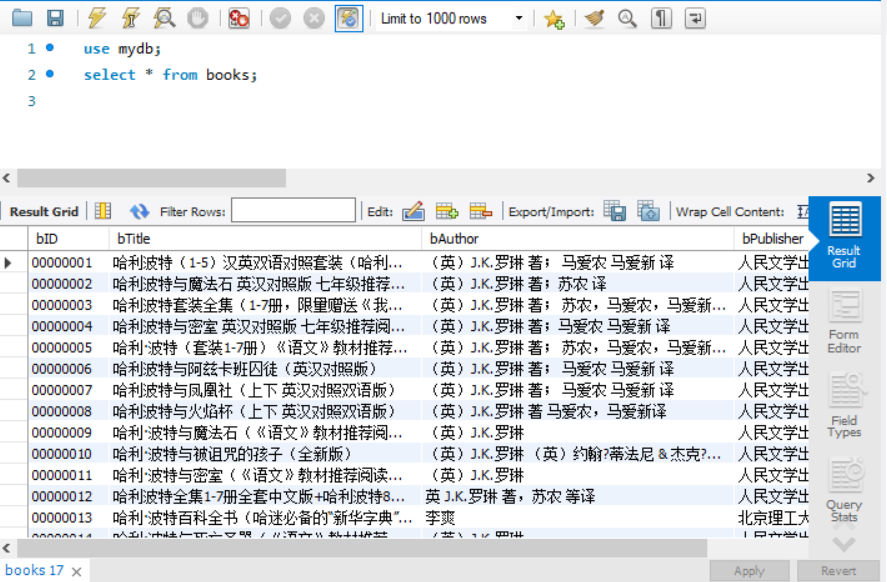
MySQL数据库截图:使用select语句,查询books表中所有数据
2)心得体会
- python操作MySQL数据库方面
本次实验的重点就是使用python操作MySQL数据库。由于开始编程的时候数据库课程的实践也还没有开始,因此对于MySQL数据库本身的操作也还很陌生,使用python去操作MySQL更是难上加难,连复现代码都看不太懂,不知道该怎么改,只能去网络上查找相关资料。认真学习了之后就豁然开朗,感觉非常的简单和方便。相关的一些操作和一些坑,这里做一个小结:
1、面向MySQL编程首先要pymysql.connect()方法建立连接,指定窗口、密码、数据库等(一开始很难理解连接和数据库的关系,现在大概理解:mysql软件可以创建多个连接,一个连接可以创建多个数据库)
2、操作需要调用cursor()方法建立游标,之后的操作大多都在游标上
3、用游标调用execute()方法可以执行sql语句
4、创建表的sql语句可以直接执行,而插入数据的sql语句需要调用connect.commit()方法,将其提交到数据库进行执行,否则无法执行(之前找了好久都没找出问题,不知道为什么数据插入不进去)
5、用select语句查询需要使用fetchall方法才能将查询的数据显示在命令行中(也是看了好久不知道为什么查不到数据,还以为自己sql语言没学好)
作业②
1)Scrapy+Xpath+MySQL爬取股票数据实验
1、实验要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
2、编程思路:
3、完整代码:
- items:items定义所需的数据结构,由于本次实验股票信息数据项比较多,每项数据封装一个items项过于繁杂,而且爬取下来的数据是按行存储的,因此定义一个data数据项包含所有数据,另一个数据项count用于统计爬取数量,作为序号。
import scrapy
class SharemysqlItem(scrapy.Item):
# data用于存储各项股票数据
data = scrapy.Field()
# count用于存储股票个数
count = scrapy.Field()
- spider:spider用于发送爬取请求,并提取爬取到的数据,将数据封装在items中,传送给pipelines。本次实验爬取股票数据,我没有采用xpath的爬取方法,而是使用re方法比较方便。思路和前几次实验差不多,主要的差别在于pipelines中数据库的使用上。
import scrapy
import re
from shareMysql.items import SharemysqlItem
class mySpider(scrapy.Spider):
name = "mySpider"
count=1
def start_requests(self):
#爬取十页股票数据,每页对应不同的url,每页发送一个爬取请求,parse作为回调函数
for page in range(1,10):
url="http://nufm.dfcfw.com/EM_Finance2014NumericApplication/JS.aspx?cb=jQuery112406115645482397511_1542356447436&type=CT&token=4f1862fc3b5e77c150a2b985b12db0fd&sty=FCOIATC&js=(%7Bdata%3A%5B(x)%5D%2CrecordsFiltered%3A(tot)%7D)&cmd=C.1&st=(ChangePercent)&sr=-1&p="+str(page)+"&ps=20"
yield scrapy.Request(url=url, callback=self.parse)
#parse方法处理response,将所需要的数据项封装在item中,传输给pipelines
def parse(self, response):
item=SharemysqlItem()
data = response.body.decode()
#使用正则表达式匹配出初始信息,再使用split方法进一步提取
pat = "data:\[(.*?)\]"
data1 = re.compile(pat, re.S).findall(data)
data2=data1[0].split('","')
for i in range(len(data2)):
#分离出后[1:13]的数据是需要的,封装起来传给pipelis
stock = data2[i].replace('"', "").split(",")[1:13]
item["data"]=stock
item["count"]=self.count
self.count+=1
yield item
- pipelines:pipelines处理传送过来的items数据,建立与数据库的连接,使用sql语言创建表,并将items数据插入到MySQL数据库中。
import pymysql
class SharemysqlPipeline:
#与数据库建立连接
connect=pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", charset="utf8",db="mydb")
#建立游标
cursor=connect.cursor()
#建表sql语句
sql="""create table share(序号 varchar(8),股票代码 varchar(8),股票名称 varchar(10),最新报价 varchar(8),
涨跌额 varchar(8), 涨跌幅 varchar(8),成交量 varchar(64),成交额 varchar(64),振幅 varchar(8),最高 varchar(8),
最低 varchar(8),今开 varchar(8),昨收 varchar(8))ENGINE=InnoDB DEFAULT CHARSET=utf8"""
#执行建表语句
cursor.execute(sql)
def process_item(self, item, spider):
print(item["count"],item["data"])
try:
#使用sql的insert语句插入数据
self.cursor.execute("insert into share values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",(item["count"],item["data"][0],item["data"][1],item["data"][2],
item["data"][3],item["data"][4],item["data"][5],item["data"][6],item["data"][7],
item["data"][8],item["data"][9],item["data"][10],item["data"][11]))
#将插入sql语句提交到数据库执行,否则无法插入
self.connect.commit()
except Exception as err:
print(err)
return item
4、实验结果截图:
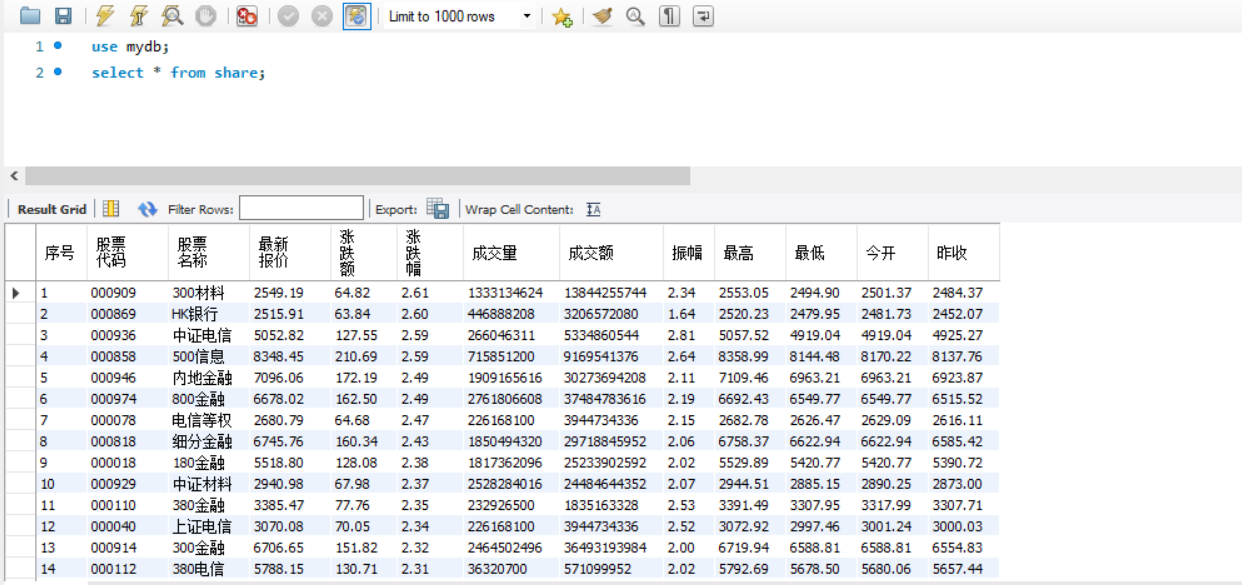
数据库截图:使用select语句查询share表中数据
2)心得体会
爬取股票网址的实验做了三遍(多次接到小姐姐打来邀请加入股票交流群的电话),但每次都有一些新的收获,也会遇到一些新的问题。在这次作业的作业1时对python操作MySQL数据库的基本操作有所了解,因此在编写这题时还算比较顺畅,其中也多次修改。由于python编程大多是调用封装得比较好的函数,因此很多时候有问题却不知道在哪里,而控制台却没有任何输出。这种时候就是要采用try-except方法,将可能出错的地方包含起来。其中有一个错误如下:

通过网络上查找,得知是因为数据库的编码问题,解决方法是在创建表时加上"ENGINE=InnoDB DEFAULT CHARSET=utf8"就可以了
作业③
1)scrapy+Xpath+MySQL爬取外汇数据实验
1、实验要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据
2、编程思路:
3、完整代码:
- items:items定义所需的数据结构。本次实验需要的数据有七个维度,分别为id、Currency、TSP、CSP、TBP、CBP、Time。按照所需要的数据结构编写items。
import scrapy
class ExchangeItem(scrapy.Item):
count=scrapy.Field()
Currency=scrapy.Field()
TSP=scrapy.Field()
CSP=scrapy.Field()
TBP=scrapy.Field()
CBP=scrapy.Field()
Time=scrapy.Field()
- spider:spider发送爬取请求并对爬取下来的数据进行处理和提取,使用xpath定位到了所需各项数据,再分别进行提取,以流水线形式发给items。
import scrapy
from exchange.items import ExchangeItem
class mySpider(scrapy.Spider):
name = "mySpider"
#count用来统计爬取数目,作为序号这一项
count=0
def start_requests(self):
url="http://fx.cmbchina.com/hq/"
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response, **kwargs):
item=ExchangeItem()
data=response.body.decode()
selector=scrapy.Selector(text=data)
#使用xpath先定位到tr,然后再对tr下的目录进行处理
start_text=selector.xpath("//div[@id='realRateInfo']/table[@align='center']/tr")
#1:排除掉第一个tr:标题
for text in start_text[1:]:
self.count+=1
item["count"]=self.count
#获取货币种类
item["Currency"]=text.xpath("./td[1]/text()").extract_first().strip()
#td[2]和td[3]分别是100(即用100人民币来兑换)和“人民币”,故跳过
item["TSP"]=text.xpath("./td[4]/text()").extract_first().strip()
item["CSP"] = text.xpath("./td[5]/text()").extract_first().strip()
item["TBP"] = text.xpath("./td[6]/text()").extract_first().strip()
item["CBP"] = text.xpath("./td[7]/text()").extract_first().strip()
item["Time"] = text.xpath("./td[8]/text()").extract_first().strip()
yield item
其中爬取下来的html内容如下(截取部分需要的部分)
<tr>
<td class="fontbold">
港币
</td>
<td align="center">
100
</td>
<td align="center" class="fontbold">
人民币
</td>
<td class="numberright">
86.35
</td>
<td class="numberright">
86.35
</td>
<td class="numberright">
86.01
</td>
<td class="numberright">
85.40
</td>
<td align="center">
10:37:28
</td>
<td align="center">
<a href="javascript:link2History('港币');">查看历史>></a>
</td>
</tr>
<tr>
<td class="fontbold">
新西兰元
</td>
<td align="center">
100
</td>
<td align="center" class="fontbold">
人民币
</td>
<td class="numberright">
443.44
</td>
<td class="numberright">
443.44
</td>
<td class="numberright">
439.90
</td>
<td class="numberright">
425.99
</td>
<td align="center">
10:37:28
</td>
<td align="center">
<a href="javascript:link2History('新西兰元');">查看历史>></a>
</td>
</tr>
由上可知,定位到tr标签对后,只要分别访问其中第1、4、5、6、7、8的td下的文本值即可得到想要的结果,使用xpath语法"./td[1]/text()"即可很容易的得到结果。并且每一次循环处理一个tr,正好里面的值可以构成一个item,每次循环yield一次item,刚好符合流水线的编程模式。
- pipelines
pipelines对收到的items数据进行处理,连接数据库,使用sql语言创建表并插入数据。
import pymysql
class ExchangePipeline:
#建立连接
connect=pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", charset="utf8",db="mydb")
#获取游标
cursor=connect.cursor()
#建表sql语句
sql="""create table exchange(Id int,Currency varchar(64),TSP varchar(64),CSP varchar(64),TBP varchar(64),
CBP varchar(64),Time varchar(64))ENGINE=InnoDB DEFAULT CHARSET=utf8"""
#执行sql语句
cursor.execute(sql)
def process_item(self, item, spider):
try:
#插入数据
self.cursor.execute("insert into exchange values(%s,%s,%s,%s,%s,%s,%s)",
(item["count"],item["Currency"],item["TSP"],item["CSP"],item["TBP"],
item["CBP"],item["Time"]))
#将sql语句提交到数据库执行,否则无法执行
self.connect.commit()
except Exception as err:
print(err)
return item
4、实验结果截图:
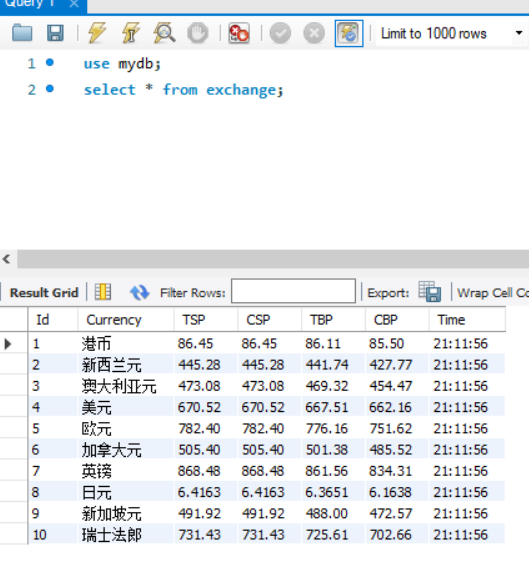
数据库截图:使用select语句查询exchange表中数据
2)心得体会
做完前两个作业后,做第三个作业就感觉到顺风顺水,从分析html到爬取数据再到连接和同步数据库都比较顺利。其中就是在xpath语法上有点卡了一下,之前的定式思维认为xpath语法就是一级一级的定位下来,直到定位到要的值,因此在一开始提取数据时完全按照标签加属性一级一级提取直到文本,而好几个值得标签和属性都是一模一样的,如下图:
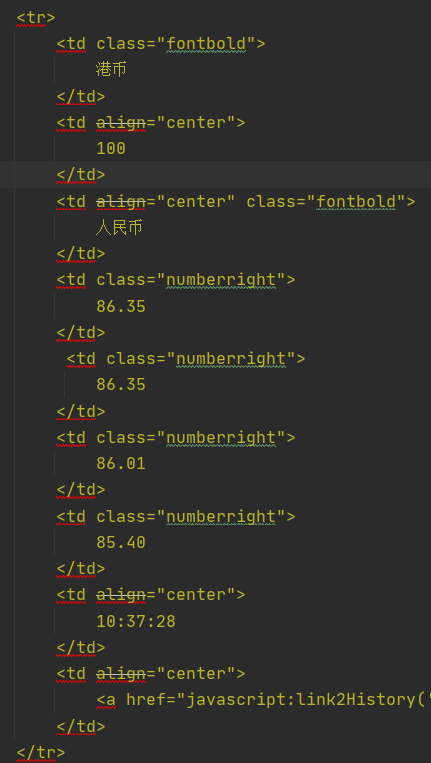
第二个和第八个标签属性值完全一样,第四、五、六、七标签的属性值完全一样,这就使得还得进一步筛选,很不方便。然后去认真查看老师的ppt后才发现,xpath语法出了按标签和属性定位外,还可以对标签目录下的各个数据进行索引,这就如同使用数组一样直接用数字索引,非常方便,还能契合流水线编程思路。之后的实验中还要多练习xpath语法的使用,挖掘出更深层次的知识。
参考链接
使用python连接mysql基本操作:https://www.runoob.com/python/python-mysql.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号