




数据采集与融合技术第三次作业
作业①
1)单线程/多线程爬取天气气象网实验
1、实验要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。
2、编程思路
graph TB
id1[根据指定网址爬取网页获取网页数据]
id2[从爬取的网页数据中解析出图片的地址]
id3[根据图片的地址作为url爬取图片数据]
id4[将图片保存到本地]
id1-->id2
id2-->id3
id3-->id4
3、完整代码
- 单线程
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
def imageSpider(start_url):
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images = soup.select("img")
for image in images:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
print(url)
download(url)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url):
global count
try:
count = count + 1
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("images\\" + str(count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(count) + ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count=0
imageSpider(start_url)
- 多线程
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
def imageSpider(start_url):
global threads
global count
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images = soup.select("img")
for image in images:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
print(url)
count = count + 1
T = threading.Thread(target=download, args=(url, count))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url,count):
try:
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
fobj=open("images\\"+str(count)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded "+str(count)+ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"}
count=0
threads=[]
imageSpider(start_url)
for t in threads:
t.join()
print("The End")
4、实验结果截图
- 单线程
![]()

- 多线程
![]()
2)心得体会
- 遇到的问题
在复现的过程中没有遇到什么大问题,有碰到的一个问题如下:
![]()
查找资料后,得知是在python中的格式空格和tab键是不同的,有部分代码段复制的过程中用空格代替了制表符,出现了错误。 - 收获
通过复现代码,深入的理解了python多线程的应用,理解了线程之间并发执行的过程(输出结果来看特别明显),也通过下载图片的总时间比较感受到了多线程的效率。

作业②
1)scrapy框架爬取网页图片实验
1、实验要求:使用scrapy框架复现作业①
2、编程思路
graph TB
id1[配置items并定义所需数据结构]
id2[Spider发送第一轮爬取请求]
id3[Spider的parse方法处理网页数据并提取图片地址]
id4[Spider的parse方法发送第二轮爬取爬取请求]
id5[Spider的parse1方法处理爬下来的图片数据并封装在items]
id6[pipelines处理接受到的数据并将图片保存到本地]
id7[编写并运行run程序]
id1-->id2
id2-->id3
id3--将解析的图片地址作为url-->id4
id4-->id5
id5--发送数据-->id6
id6-->id7
3、完整代码
- items
items定义了数据结构,供Spider、pipelines调用,本题需要三个变量,分别存储图片数据、图片编号(便于命名)、图片后缀(使图片可用)
import scrapy
#PictureItem类定义了3个变量,data用于存储图片二进制数据,count用于存储图片编号用于命名,suffix用于存储图片后缀名,使图片按格式存储
class PictureItem(scrapy.Item):
data=scrapy.Field()
count=scrapy.Field()
suffix=scrapy.Field()
- Spider
Spider用于发送请求并处理请求,本次实验中item需要发送两轮请求,第一轮请求爬取网页信息,通过xpath解析出图片的地址,第二轮请求根据第一轮解析出的地址发送第二轮请求,下载图片数据,并将数据封装在items中,传送给pipelines
import scrapy
from picture.items import PictureItem
class MySpider(scrapy.Spider):
name="mySpider"
#count用于标记传送给pipelines的数据编号,用于图片文件的命名。由于发送请求与响应是流水线型的,因此需要类变量,各方法通过self调用
count=1
#start_requests方法指定入口地址,发出第一次请求
def start_requests(self):
yield scrapy.Request(url='http://www.weather.com.cn', callback=self.parse)
#parse方法作为第一次访问的回调函数,获取带爬取网页的数据,并解析出图片的地址,发送二次请求
def parse(self, response):
try:
data = response.body.decode()
selector=scrapy.Selector(text=data)
#使用xpath语法,定位到标签为img的属性src的值,解析出待爬取图片的地址
addresses=selector.xpath("//img/@src")
#依次读取地址,并发送请求,parse1作为回调函数
for address in addresses:
yield scrapy.Request(url=address.extract(),callback=self.parse1)
except Exception as err:
print(err)
#parse1方法作为爬取图片请求的回调函数,获取爬取下来的图片的二进制信息,分别将图片的后缀“suffix”、图像二进制数据“data”和
#图片的编号(用于命名)封装在item中,传给pipeline进一步处理和存储
def parse1(self, response):
item=PictureItem()
#response.url的最后四位为图片的类型(.jpg、.png、.gif)
item["suffix"]=response.url[-4:]
#response.body为图片的二进制形式数据
item["data"]=response.body
#通过self调用count变量对图片数据进行编号
item["count"]=self.count
self.count+=1
yield item
- pipelines
pipelines调用items中的信息,将封装好的信息解析出来,存储到本地
from itemadapter import ItemAdapter
import urllib.request
class PicturePipeline:
def process_item(self, item, spider):
#使用try-except 查看写入过程的异常
try:
#使用路径+编号+后缀打开文件,wb+表示若文件不存在则创建,且以byte字符方式写入
fobj = open("C:\\Users\\57084\\example\\images\\" + str(item["count"]) + item["suffix"], "wb+")
except Exception as err:
print(err)
try:
#写入封装在item中的二进制数据
fobj.write(item["data"])
except Exception as err:
print(err)
fobj.close()
print("write " + str(item["count"]) + item["suffix"])
return item
- run
run用于使得整个框架能够运行起来
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())
4、实验结果截图
2)心得体会
- self的使用
本次实验中是按类进行编写,刚开始写的时候摸不着头脑,不知道怎么使用全局变量(如需要count来统计发出的请求个数),也不知道怎么调用类的变量。经过学习加上回想起之前java课程中面向对象的编程,慢慢熟练了self方法的使用(真好用)。使用self方法可以很好地调用和修改类变量,让整个编程过程都顺滑起来。 - scrapy框架的理解
1、items:我认为items在scrapy框架中是一种偏后台的存在,主要就是定义了需要的数据结构,比较容易理解
2、Spider:这次实验花了比较久的时间理解Spider的工作原理。其中一个很重要的方面就是response和回调函数的理解,刚开始一直不理解这两个地方,慢慢一步一步把中间结果print出来才大概理解。Spider的流程大概是发送爬取请求(Request)->等网页响应后,将爬下来的数据封装在response中,执行自己定义的回调函数->回调函数处理response的内容,将处理好的数据发给pipelines。
3、pipelines:pipelines把传输过来的数据存储在本地,而不应该在pipelines中再执行爬取请求。因此在一开始就应该想好pipelines需要获取哪几项数据,然后在items中定义相应的数据结构。 - 对scrapy框架的评价
1、各框架分工明确,各模块之间相互联系又互不干扰,适合做比较大的工程。
2、流水线方式工作,资源的利用率比较高,等待的时间比较短。
3、对新手感觉不太友好,第一次用的时候完全不知道怎么下手,及时看着书上的例子打也很难理解工作流程,比如response机制等等,花了比较长的时间才大概搞懂。
4、难以调试,前两次实验中认识到了pycharm强大的调试功能,而在scrapy框架中却无从下手,这次实验只有通过print进行调试,编程过程异常艰难。
作业③
1)scrapy框架爬取股票数据实验
1、实验要求:使用scrapy框架爬取股票相关信息
2、编程思路
graph TB
id1[配置items数据结构]
id2[抓包分析股票网页url]
id3[Spider根据不同的url发送请求]
id4[Spider的parse方法使用正则表达式和split方法一步一步解析出需要的数据并封装在items中]
id5[pipelines将收到的数据逐行存入本地csv文件]
id6[编写并运行run程序]
id1-->id2
id2-->id3
id3--response-->id4
id4--发送给pipelines-->id5
id5-->id6
3、完整代码
- items
items定义数据结构,本次实验需要的数据有股票信息data和股票序号(即爬取的个数,用于命名)count
import scrapy
class SharesItem(scrapy.Item):
#data用于存储各项股票数据
data=scrapy.Field()
#count用于存储股票个数
count=scrapy.Field()
- Spider
本次实验的Spider比较复杂,我爬取了十页的股票数据,因此需要根据不同的url发送10次请求,10次请求可以采用相同的回调函数进行处理。爬取的数据不太方遍使用xpath语法,而是采用正则表达式。爬取数据之后需要对数据进行处理,剔除不要的数据项,把有用的数据项和统计爬取个数的count变量封装在items中,发送给pipelines处理。
import scrapy
import re
from shares.items import SharesItem
class MySpider(scrapy.Spider):
name = "mySpider"
count=1
def start_requests(self):
#爬取十页股票数据,每页对应不同的url,每页发送一个爬取请求,parse作为回调函数
for page in range(1,10):
url="http://nufm.dfcfw.com/EM_Finance2014NumericApplication/JS.aspx?cb=jQuery112406115645482397511_1542356447436&type=CT&token=4f1862fc3b5e77c150a2b985b12db0fd&sty=FCOIATC&js=(%7Bdata%3A%5B(x)%5D%2CrecordsFiltered%3A(tot)%7D)&cmd=C.1&st=(ChangePercent)&sr=-1&p="+str(page)+"&ps=20"
yield scrapy.Request(url=url, callback=self.parse)
#parse方法处理response,将所需要的数据项封装在item中,传输给pipelines
def parse(self, response):
item=SharesItem()
data = response.body.decode()
#使用正则表达式匹配出初始信息,再使用split方法进一步提取
pat = "data:\[(.*?)\]"
data1 = re.compile(pat, re.S).findall(data)
data2=data1[0].split('","')
for i in range(len(data2)):
#分离出后[1:13]的数据是需要的,封装起来传给pipelines
stock = data2[i].replace('"', "").split(",")[1:13]
item["data"]=stock
item["count"]=self.count
self.count+=1
yield item
- pipelines
pipelines将收到的一行一行的股票编号和股票数据存在同一个列表中,进而逐行存入到csv表格中
from itemadapter import ItemAdapter
import csv
import codecs
class SharesPipeline:
#若直接使用python内置open方法,写入会中文乱码,使用codecs.open设置写入为utf-8格式
f = codecs.open('C:\\Users\\57084\\example\\1.csv', 'a', 'utf-8')
writer = csv.writer(f)
#写入标题
writer.writerow(["序号","代码","名称","最新价","涨跌额","涨跌幅","成交量","成交额","涨幅","最高","最低","今开","昨收"])
def process_item(self, item, spider):
#以流水线形式写入
empty=[]
#append()方法在列表后添加单个元素,extend()方法将整个列表的值依次添加到列表中
empty.append(item["count"])
empty.extend(item["data"])
self.writer.writerow(empty)
return item
4、实验结果截图
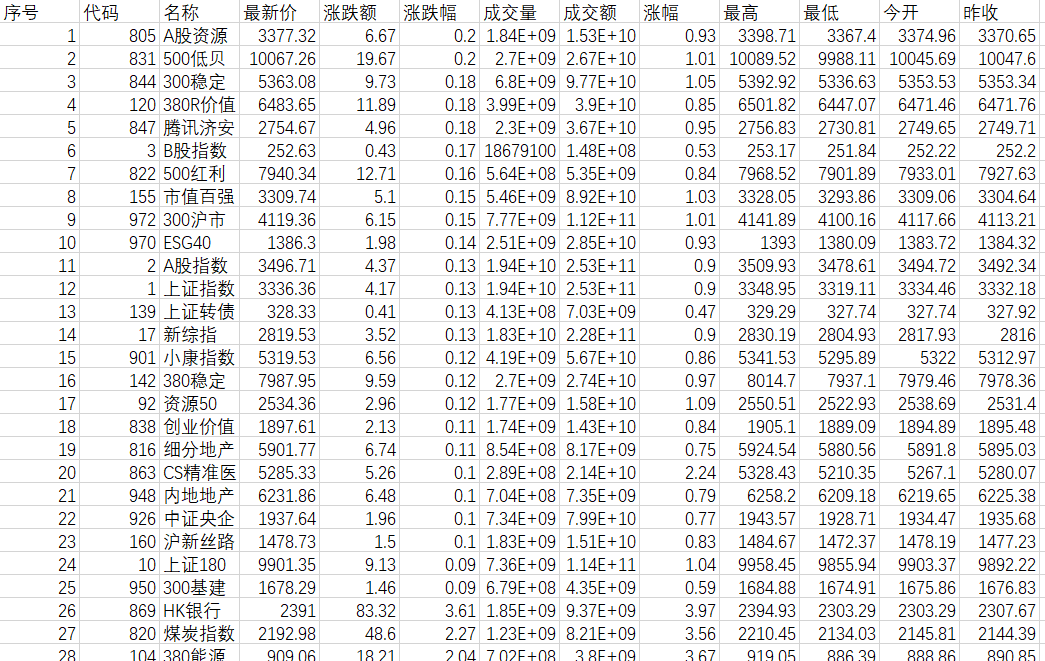
2)心得体会
- 信息泄露
不知道为什么,在这几天爬取完股票信息后,每天都会有小姐姐打电话给我问我要不要进股票交流群,也不知道是哪个环节出了问题,看来爬别人的数据也要注意自己的信息的泄露。 - 舍弃prettytable使用csv原因
本次实验本来打算使用prettytable输出,但是由于scrapy框架是流水线形式运行的,数据是逐行传输到pipelines的,因此出现一个问题:如果我在pipelines的process_item方法内部输出结果,则会是每进来一行就输出一次,不符合要求;如果在process_item方法外部输出,则发现只输出了一个标题,无法输出数据。因此直接将数据逐行存入到csv中,比较符合流水线的思想。
参考链接
- markdown排版中流程图的画法:https://www.cnblogs.com/qomumu/articles/12894813.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号