
Spring AI 代码分析(七)--文档的处理
文档处理能力分析
请关注微信公众号:阿呆-bot
1. 工程结构概览
Spring AI 提供了完整的文档处理能力,包括文档读取、文本分块和预处理。这些能力是 RAG 应用的基础。
document-readers/ # 文档读取器
├── pdf-reader/ # PDF 读取器
│ ├── PagePdfDocumentReader.java # 按页读取
│ └── ParagraphPdfDocumentReader.java # 按段落读取
├── markdown-reader/ # Markdown 读取器
│ └── MarkdownDocumentReader.java
├── tika-reader/ # 通用文档读取器(Tika)
│ └── TikaDocumentReader.java
└── jsoup-reader/ # HTML 读取器
└── JsoupDocumentReader.java
spring-ai-commons/ # 核心处理能力
├── document/
│ └── Document.java # 文档对象
└── transformer/
└── splitter/ # 文本分块
├── TextSplitter.java
├── TokenTextSplitter.java
└── CharacterTextSplitter.java
2. 技术体系与模块关系
文档处理流程:读取 → 分块 → 嵌入 → 存储

3. 关键场景示例代码
3.1 PDF 文档读取
PDF 读取支持按页和按段落两种方式:
// 按页读取
Resource pdfResource = new ClassPathResource("document.pdf");
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(pdfResource);
List<Document> documents = pdfReader.get();
// 按段落读取(更智能)
ParagraphPdfDocumentReader paragraphReader =
new ParagraphPdfDocumentReader(pdfResource, config);
List<Document> documents = paragraphReader.get();
3.2 Markdown 文档读取
Markdown 读取器可以按标题、段落或水平线分组:
MarkdownDocumentReader markdownReader =
new MarkdownDocumentReader("classpath:docs/*.md", config);
List<Document> documents = markdownReader.get();
3.3 Tika 通用读取
Tika 可以读取多种格式(PDF、Word、PPT 等):
TikaDocumentReader tikaReader =
new TikaDocumentReader("classpath:document.docx");
List<Document> documents = tikaReader.get();
3.4 文档分块
将长文档分割成适合嵌入的小块:
// Token 分块(推荐)
TokenTextSplitter splitter = TokenTextSplitter.builder()
.chunkSize(800) // 目标 token 数
.minChunkSizeChars(350) // 最小字符数
.build();
List<Document> chunks = splitter.split(documents);
// 字符分块
CharacterTextSplitter charSplitter = new CharacterTextSplitter(1000, 200);
List<Document> chunks = charSplitter.split(documents);
3.5 完整流程
文档处理的完整流程:
// 1. 读取文档
TikaDocumentReader reader = new TikaDocumentReader("document.pdf");
List<Document> documents = reader.get();
// 2. 分块
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> chunks = splitter.split(documents);
// 3. 嵌入并存储
vectorStore.add(chunks);
4. 核心实现图
4.1 文档处理流程

5. 入口类与关键类关系
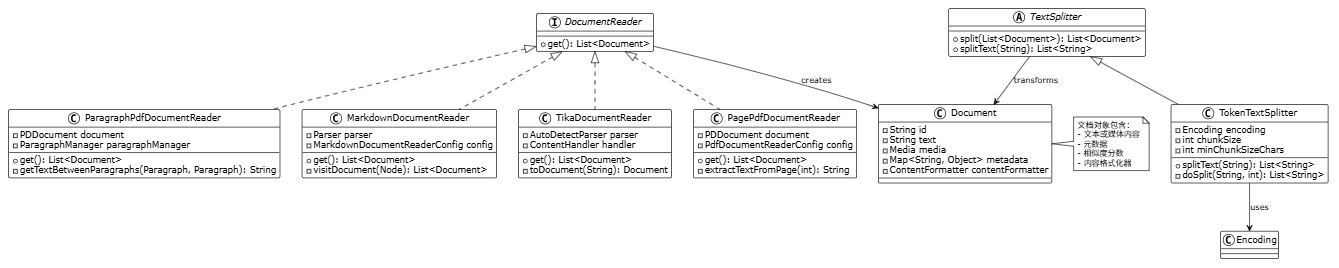
6. 关键实现逻辑分析
6.1 PDF 读取实现
PDF 读取有两种方式:
方式一:按页读取
public class PagePdfDocumentReader implements DocumentReader {
@Override
public List<Document> get() {
List<Document> documents = new ArrayList<>();
int pageCount = document.getNumberOfPages();
for (int i = 0; i < pageCount; i++) {
String pageText = extractTextFromPage(i);
Document doc = new Document(pageText);
doc.getMetadata().put("page", i);
documents.add(doc);
}
return documents;
}
}
方式二:按段落读取(更智能)
public class ParagraphPdfDocumentReader implements DocumentReader {
@Override
public List<Document> get() {
// 1. 提取段落
List<Paragraph> paragraphs = paragraphManager.flatten();
// 2. 将相邻段落合并为文档
List<Document> documents = new ArrayList<>();
for (int i = 0; i < paragraphs.size(); i++) {
Paragraph from = paragraphs.get(i);
Paragraph to = (i + 1 < paragraphs.size())
? paragraphs.get(i + 1)
: from;
String text = getTextBetweenParagraphs(from, to);
Document doc = new Document(text);
addMetadata(from, to, doc);
documents.add(doc);
}
return documents;
}
}
按段落读取的优势:
- 保持语义完整性:段落是自然的语义单元
- 更好的检索效果:段落级别的文档更适合向量搜索
- 保留布局信息:可以保留 PDF 的布局结构
6.2 Markdown 读取实现
Markdown 读取器使用 CommonMark 解析器:
public class MarkdownDocumentReader implements DocumentReader {
@Override
public List<Document> get() {
List<Document> documents = new ArrayList<>();
for (Resource resource : markdownResources) {
// 1. 解析 Markdown
Node document = parser.parse(loadContent(resource));
// 2. 访问文档节点
DocumentVisitor visitor = new DocumentVisitor(config);
document.accept(visitor);
// 3. 收集文档
documents.addAll(visitor.getDocuments());
}
return documents;
}
}
Markdown 读取器可以按以下方式分组:
- 按标题分组:每个标题及其内容成为一个文档
- 按段落分组:每个段落成为一个文档
- 按水平线分组:水平线分隔的内容成为独立文档
6.3 Tika 通用读取实现
Tika 使用自动检测解析器:
public class TikaDocumentReader implements DocumentReader {
@Override
public List<Document> get() {
try (InputStream stream = resource.getInputStream()) {
// 1. 自动检测文档类型并解析
parser.parse(stream, handler, metadata, context);
// 2. 提取文本
String text = handler.toString();
// 3. 格式化文本
text = textFormatter.format(text);
// 4. 创建文档
Document doc = new Document(text);
doc.getMetadata().put(METADATA_SOURCE, resourceName());
return List.of(doc);
}
}
}
Tika 的优势:
- 支持多种格式:PDF、Word、PPT、Excel、HTML 等
- 自动检测:无需指定文档类型
- 提取元数据:自动提取文档的元数据
6.4 文本分块实现
文本分块是 RAG 应用的关键步骤:
public abstract class TextSplitter implements DocumentTransformer {
@Override
public List<Document> apply(List<Document> documents) {
List<Document> chunks = new ArrayList<>();
for (Document doc : documents) {
// 1. 分割文本
List<String> textChunks = splitText(doc.getText());
// 2. 为每个分块创建文档
for (int i = 0; i < textChunks.size(); i++) {
Map<String, Object> metadata = new HashMap<>(doc.getMetadata());
// 3. 添加分块元数据
metadata.put("parent_document_id", doc.getId());
metadata.put("chunk_index", i);
metadata.put("total_chunks", textChunks.size());
Document chunk = Document.builder()
.text(textChunks.get(i))
.metadata(metadata)
.score(doc.getScore())
.build();
chunks.add(chunk);
}
}
return chunks;
}
protected abstract List<String> splitText(String text);
}
6.5 Token 分块实现
Token 分块使用编码器计算 token 数:
public class TokenTextSplitter extends TextSplitter {
@Override
protected List<String> splitText(String text) {
// 1. 编码为 tokens
List<Integer> tokens = encoding.encode(text).boxed();
List<String> chunks = new ArrayList<>();
while (!tokens.isEmpty() && chunks.size() < maxNumChunks) {
// 2. 取目标大小的 tokens
List<Integer> chunk = tokens.subList(0,
Math.min(chunkSize, tokens.size()));
String chunkText = decodeTokens(chunk);
// 3. 在标点符号处截断(保持语义)
int lastPunctuation = findLastPunctuation(chunkText);
if (lastPunctuation > minChunkSizeChars) {
chunkText = chunkText.substring(0, lastPunctuation + 1);
}
// 4. 过滤太短的分块
if (chunkText.length() > minChunkLengthToEmbed) {
chunks.add(chunkText.trim());
}
// 5. 移除已处理的 tokens
tokens = tokens.subList(getEncodedTokens(chunkText).size(),
tokens.size());
}
return chunks;
}
}
Token 分块的优势:
- 精确控制大小:按 token 数分割,而不是字符数
- 保持语义:在标点符号处截断
- 适合嵌入模型:token 数是嵌入模型的输入单位
7. 文档分块策略
7.1 Token 分块(推荐)
适合大多数场景,特别是使用 OpenAI 等基于 token 的模型:
TokenTextSplitter splitter = TokenTextSplitter.builder()
.chunkSize(800) // 目标 token 数
.minChunkSizeChars(350) // 最小字符数(避免过小)
.minChunkLengthToEmbed(5) // 最小嵌入长度
.maxNumChunks(10000) // 最大分块数
.keepSeparator(true) // 保留分隔符
.build();
7.2 字符分块
适合固定大小的分块需求:
CharacterTextSplitter splitter = new CharacterTextSplitter(
1000, // chunkSize
200 // chunkOverlap(重叠部分,保持上下文)
);
7.3 自定义分块
可以实现自己的分块策略:
public class CustomTextSplitter extends TextSplitter {
@Override
protected List<String> splitText(String text) {
// 自定义分块逻辑
// 例如:按句子、按段落、按章节等
return customSplit(text);
}
}
8. 外部依赖
不同读取器的依赖:
8.1 PDF Reader
- PDFBox:Apache PDFBox,PDF 解析库
- 无其他依赖
8.2 Markdown Reader
- CommonMark:Markdown 解析库
- 无其他依赖
8.3 Tika Reader
- Apache Tika:通用文档解析库
- 支持 100+ 种格式
8.4 Text Splitter
- tiktoken:Token 编码库(用于 TokenTextSplitter)
- 无其他依赖(CharacterTextSplitter)
9. 工程总结
Spring AI 的文档处理能力设计有几个亮点:
统一的 Document 抽象。所有读取器都返回 Document 对象,这让后续处理(分块、嵌入、存储)变得统一。不管是从 PDF 还是 Word 读取,出来的都是 Document,处理起来很方便。
灵活的读取策略。不同格式有不同的读取策略(按页、按段落、按标题),可以根据需求选择最合适的方式。PDF 可以按页读,也可以按段落读,看你的需求。
智能的分块机制。Token 分块不仅考虑大小,还考虑语义完整性(在标点符号处截断),这提高了检索效果。不会在句子中间截断,保持语义完整。
元数据保留。分块时会保留原始文档的元数据,并添加分块相关的元数据(parent_document_id、chunk_index 等),这有助于追踪和调试。想知道某个分块来自哪个文档?看元数据就行。
可扩展性。所有组件都通过接口定义,可以轻松实现自定义的读取器和分块器。想支持新的文档格式?实现 DocumentReader 接口就行。
总的来说,Spring AI 的文档处理能力既全面又灵活。它支持多种文档格式,提供了智能的分块策略,同时保持了高度的可扩展性。这种设计让开发者可以轻松构建基于文档的 RAG 应用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号