qwen与向量数据库搭建个人微知识库
@
概要
提示:记录下个人使用qwen+本地资料搭建个小型ai知识库过程
整体架构
因为这个实现坑踩了好几天,首先先贴下项目架构
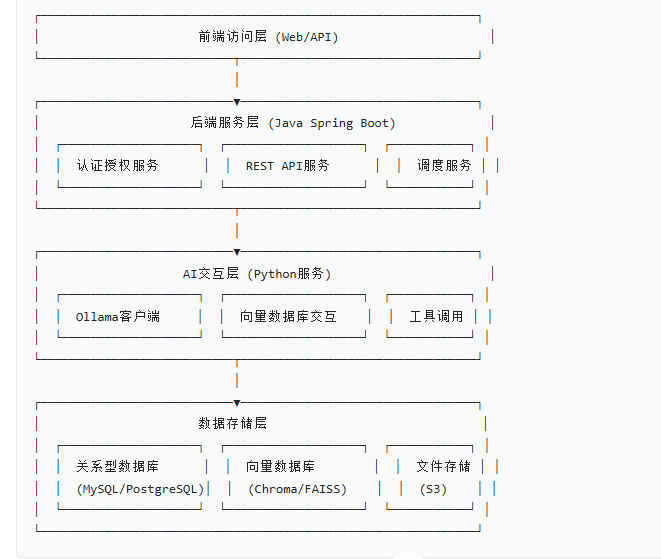
工作流程
- 准备环境python3.8
- 准备你的信息数据如.txt一堆文件到文件夹data中
- 使用
TextLoader加载读出txt文件里面的数据 - 将数据切割存储到向量数据库chroma中
- 使用
ollama拉下来的qwen检索本地向量库进行查询 - 使用接口返回
详细代码及运行
前面pip安装依赖命令
pip install -U langchain-community -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install chromadb
pip install fastapi==0.95.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install uvicorn -i https://pypi.tuna.tsinghua.edu.cn/simple
python代码
from fastapi import FastAPI, HTTPException
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain.chains import RetrievalQA
from langchain_community.llms import Ollama
from typing import List, Dict
import os
import traceback
app = FastAPI(title="企业知识库AI服务")
# 初始化Ollama模型和嵌入
llm = Ollama(model="qwen:7b-chat") # 替换为你的模型名称
embeddings = OllamaEmbeddings(model="qwen:7b-chat")
# 初始化向量数据库
def init_vector_db(docs_folder: str):
if not os.path.exists(docs_folder):
raise FileNotFoundError(f"指定的文件夹不存在: {docs_folder}")
# 检查chroma_db文件夹是否存在,如果不存在则创建
chroma_db_path = "./chroma_db"
if not os.path.exists(chroma_db_path):
os.makedirs(chroma_db_path)
loader = DirectoryLoader(
docs_folder,
glob="**/*.txt",
loader_cls=lambda path: TextLoader(path, encoding="utf-8") # 或 "gbk",“utf-8”
)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.split_documents(documents)
vectordb = Chroma.from_documents(
documents=texts,
embedding=embeddings,
persist_directory=chroma_db_path
)
vectordb.persist()
return vectordb
# 初始化知识库(首次运行或更新文档时调用)
@app.post("/api/knowledge/init")
async def initialize_knowledge_base(docs_folder: str):
try:
vectordb = init_vector_db(docs_folder)
return {"status": "success", "message": "知识库初始化完成"}
except Exception as e:
traceback.print_exc()
raise HTTPException(status_code=500, detail=str(e))
# 问答接口
@app.post("/api/knowledge/query")
async def query_knowledge_base(question: str):
try:
vectordb = Chroma(embedding_function=embeddings, persist_directory="./chroma_db")
retriever = vectordb.as_retriever()
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True
)
result = qa_chain({"query": question})
return {
"answer": result["result"],
"sources": [doc.metadata for doc in result["source_documents"]]
}
except Exception as e:
traceback.print_exc()
raise HTTPException(status_code=500, detail=str(e))
运行命令行
uvicorn app:app --host 0.0.0.0 --port 8000
请求curl
// 初始化数据
curl --location --request POST 'http://127.0.0.1:8000/api/knowledge/init?docs_folder=data'
// 请求接口(本地配置简陋回复有点慢)
curl --location --request POST '127.0.0.1:8000/api/knowledge/query?question=%E8%B1%86%E7%93%A3%E8%AF%8D%E4%BA%91%E5%9C%B0%E5%9D%80%E6%98%AF%E4%BB%80%E4%B9%88'
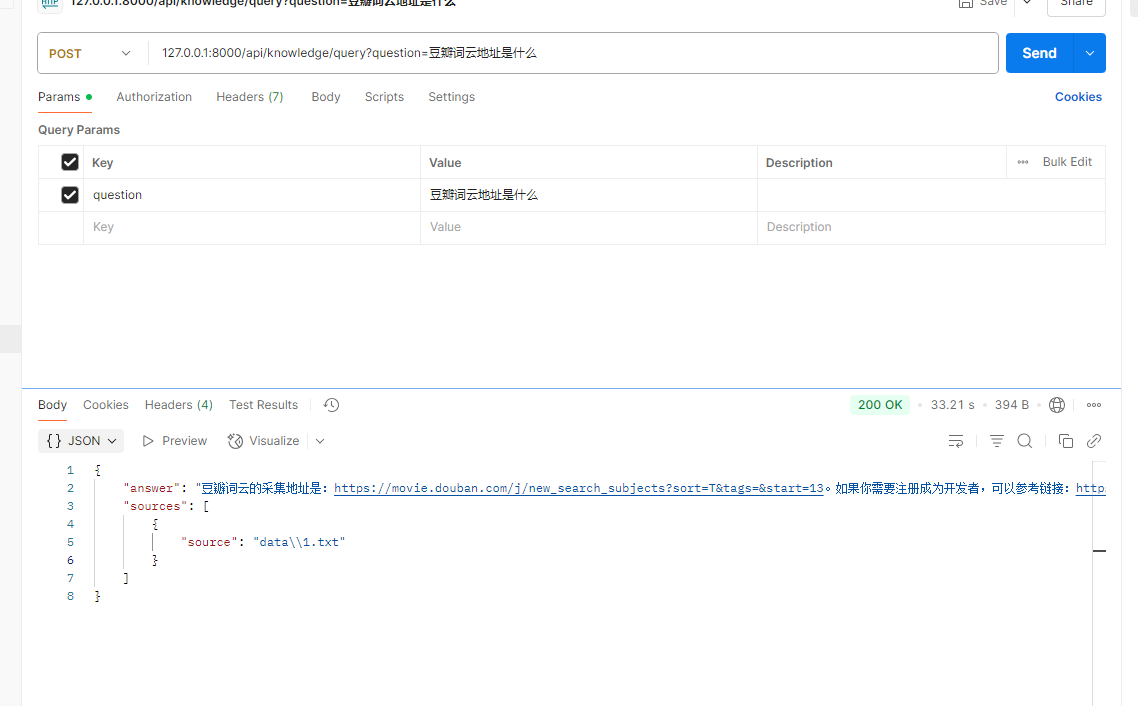
演示截图

小结
这个算是实现比较初步的个人大模型知识库,后面待继续优化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号