
软件工程第一次作业
软件工程第一次作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/202501SoftwareEngineering |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/202501SoftwareEngineering/homework/13546 |
| 这个作业的目标 | 创建并完善github账户及博客园账户,掌握markdown语法,掌握git基本命令的用法,熟练运用ai工具,明确自己具备的技能并做好职业规划 |
| 学号 | 102301510 |
markdown编辑截图
Github团队主页搭建
团队仓库: https://github.com/XunBo2023/cuddly-umbrella
团队logo

自我介绍: https://github.com/XunBo2023/cuddly-umbrella/blob/main/Dafang.md
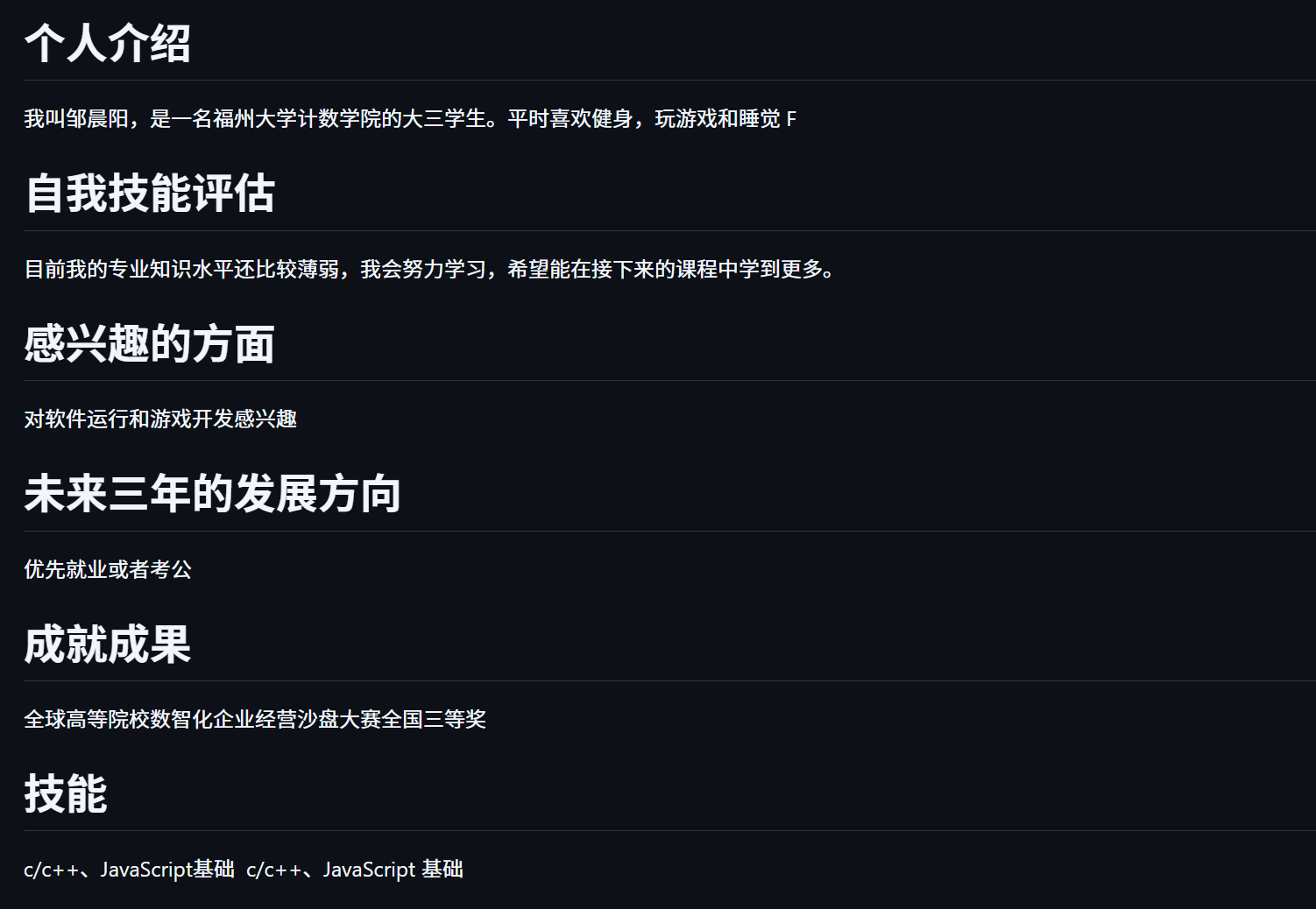
个人评估
目前具备技能
- c/c++、JavaScript基础,能写简单程序
感兴趣的方面
- 对软件工程,开发程序感兴趣
目前缺少的能力
- 缺少大型项目开发经验
代码量
- 1k+
本学期学习目标
- 希望代码量能达到2k+
- 能完成一个项目
AI生成的学习指南
一、学习核心目标
数据科学的核心是 “从数据中提取价值,用数据驱动决策”,核心目标聚焦 “从‘看懂数据’到‘用数据解决实际问题’的能力跨越”,具体拆解为 3 点:
1.理解数据从采集、清洗、分析到建模、可视化、落地应用的全流程逻辑;
2.掌握各环节的核心工具与算法,能独立完成中小型数据项目的完整落地;
3.建立 “数据思维 + 业务思维” 双驱动模式,具备将数据结论转化为可执行方案的能力。
二、分阶段学习路径(适合新手,周期 7-9 个月)
阶段1:基础能力搭建(2-3 个月)
重点解决 “数据科学是什么、需要哪些基础能力” 的认知问题,避免后续学习陷入 “工具堆砌” 或 “算法空转” 误区。
- 必学内容:
- 数学基础:概率论(古典概型、条件概率、正态分布)、线性代数(矩阵运算、向量相关性)、统计学(均值、方差、假设检验、置信区间),无需深入推导,重点掌握 “如何用数学思维理解数据规律”;
- 编程基础:Python 核心语法(变量、循环、函数、类)、数据结构(列表、字典、数组),重点训练 “用代码处理数据的基本能力”;
- 数据认知:数据类型(结构化数据如 Excel 表格、非结构化数据如文本 / 图片)、数据质量指标(完整性、准确性、一致性)、常见数据来源(公开数据集如 Kaggle、企业内部数据库)。
- 推荐资源:
- 教材:《Python 编程:从入门到实践》(夯实编程基础)、《深入浅出统计学》(通俗讲解统计核心概念);
- 课程:Coursera《Python for Everybody》(密歇根大学,免费,侧重实战)、B 站 “黑马程序员 Python 数据分析”(配套案例 + 代码,适合零基础);
- 工具:Anaconda(集成 Python 环境 + 常用库,避免环境配置难题)、Jupyter Notebook(代码 + 笔记一体化,方便复盘)。
核心工具与技能落地(3-4 个月)
用 “工具 + 方法” 打通数据处理全流程,形成 “数据清洗→分析→可视化→建模” 的完整技能链,避免单一工具学习导致的 “碎片化能力”。
| 学习环节 | 核心方法 | 推荐工具/库 | 学习重点 |
|---|---|---|---|
| 数据清洗 | 缺失值处理(删除 / 填充)、异常值识别(箱线图 / IQR)、数据标准化(Min-Max/Z-Score) | Pandas(数据处理核心库)、NumPy(数值计算) | 理解 “为什么清洗” 比 “怎么清洗” 更重要,避免过度处理丢失关键信息 |
| 数据可视化 | 单变量分析(直方图 / 箱线图)、双变量分析(散点图 / 折线图)、多变量分析(热力图 / 雷达图) | Matplotlib(基础绘图)、Seaborn(美化 + 统计图表)、GitHub/GitLab(团队协作) | 用 “简洁清晰” 原则选择图表,避免为了美观堆砌特效 |
| 数据分析 | 描述性分析(数据分布 / 趋势)、探索性分析(相关性分析 / 归因分析) | Pandas(分组统计)、SciPy(统计检验) | 结合业务场景解读数据结论,比如 “用户活跃度下降 30%” 需关联运营动作 |
| 数据建模 | 回归分析(线性回归预测连续值)、分类算法(逻辑回归 / 决策树识别类别) | Scikit-learn(机器学习基础库) | 掌握 “模型参数调优”“模型评估指标(MAE/RMSE/ 准确率 / 召回率)”,不追求复杂算法 |
阶段3:实战项目深化(2-3 个月)
通过 “场景化项目” 验证学习成果,优先从 “贴近生活的小项目” 入手,再过渡到 “模拟企业场景的综合项目”,避免 “学完工具却不会用” 的困境。
- 个人项目(入门,1-1.5 个月):
- 示例 1:“外卖订单数据分析”(用 Kaggle 外卖数据集,分析订单量时间分布、用户偏好菜品、配送时长影响因素,输出可视化报告);
- 示例 2:“房价预测小工具”(用某城市房价数据集,通过线性回归模型预测房价,用 Flask 搭建简单网页界面,支持输入面积 / 户型等参数输出预测结果);
- 目标:练手数据清洗流程、可视化逻辑、基础模型落地,学会用 “Markdown 写项目报告”,明确 “数据来源→分析步骤→结论→改进方向”。
- 综合项目(进阶,1-1.5 个月,可 2-3 人协作):
- 示例:“电商用户流失预警系统”(分工 “数据采集(模拟用户行为数据)、特征工程(提取用户活跃度 / 消费频率等指标)、模型训练(用决策树 / 随机森林做分类)、可视化看板(用 Tableau 展示流失率趋势)”);
- 关键动作:用 GitHub 管理项目代码,按 “需求文档→数据字典→清洗方案→模型报告→可视化成果” 输出完整资料,模拟企业 “数据分析师 + 算法工程师” 协作流程。
三、避坑与高效学习建议
- 拒绝 “数学焦虑”:新手常因数学基础薄弱放弃,其实初期无需深入推导公式,比如用 “身高体重相关性” 理解线性回归,用 “掷骰子” 理解概率,先会 “用” 再学 “原理”;
- 避免 “工具堆砌”:不要盲目学 Python、R、SQL、Tableau 等所有工具,先精通 “Python(Pandas/Scikit-learn)+SQL”(企业最常用组合),再根据需求补充其他工具,比如需要复杂可视化再学 Tableau;
- 别跳过 “业务理解”:很多人沉迷建模却忽略业务,比如 “用户复购率低”,不能只看数据显示 “复购率 20%”,还要结合 “是否有复购优惠活动”“客服售后体验” 等业务信息,否则结论毫无价值;
- 坚持 “每日小练习”:每天花 30 分钟做 “数据小任务”,比如用 Pandas 处理一份 Excel 表格、用 Matplotlib 画一张趋势图,或在 LeetCode Database 板块刷 1 道 SQL 题,保持数据处理手感。
四、总结
数据科学的核心不是 “学多少算法、会多少工具”,而是 “建立‘用数据解决问题’的思维闭环”。从基础能力搭建打地基,用工具技能形成落地能力,靠实战项目积累经验,逐步实现 “从数据新手到能输出有价值数据结论的从业者” 的跨越,满足企业对 “能干活、懂业务” 的数据人才的核心需求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号