kafka系列九、kafka事务原理、事务API和使用场景
一、事务场景
- 最简单的需求是producer发的多条消息组成一个事务这些消息需要对consumer同时可见或者同时不可见 。
- producer可能会给多个topic,多个partition发消息,这些消息也需要能放在一个事务里面,这就形成了一个典型的分布式事务。
- kafka的应用场景经常是应用先消费一个topic,然后做处理再发到另一个topic,这个consume-transform-produce过程需要放到一个事务里面,比如在消息处理或者发送的过程中如果失败了,消费位点也不能提交。
- producer或者producer所在的应用可能会挂掉,新的producer启动以后需要知道怎么处理之前未完成的事务 。
- 流式处理的拓扑可能会比较深,如果下游只有等上游消息事务提交以后才能读到,可能会导致rt非常长吞吐量也随之下降很多,所以需要实现read committed和read uncommitted两种事务隔离级别。
二、几个关键概念和推导
1.因为producer发送消息可能是分布式事务,所以引入了常用的2PC,所以有事务协调者(Transaction Coordinator)。Transaction Coordinator和之前为了解决脑裂和惊群问题引入的Group Coordinator在选举和failover上面类似。
2.事务管理中事务日志是必不可少的,kafka使用一个内部topic来保存事务日志,这个设计和之前使用内部topic保存位点的设计保持一致。事务日志是Transaction Coordinator管理的状态的持久化,因为不需要回溯事务的历史状态,所以事务日志只用保存最近的事务状态。
3.因为事务存在commit和abort两种操作,而客户端又有read committed和read uncommitted两种隔离级别,所以消息队列必须能标识事务状态,这个被称作Control Message。
4.producer挂掉重启或者漂移到其它机器需要能关联的之前的未完成事务所以需要有一个唯一标识符来进行关联,这个就是TransactionalId,一个producer挂了,另一个有相同TransactionalId的producer能够接着处理这个事务未完成的状态。注意不要把TransactionalId和数据库事务中常见的transaction id搞混了,kafka目前没有引入全局序,所以也没有transaction id,这个TransactionalId是用户提前配置的。
5. TransactionalId能关联producer,也需要避免两个使用相同TransactionalId的producer同时存在,所以引入了producer epoch来保证对应一个TransactionalId只有一个活跃的producer epoch
三、事务语义
2.1. 多分区原子写入
事务能够保证Kafka topic下每个分区的原子写入。事务中所有的消息都将被成功写入或者丢弃。例如,处理过程中发生了异常并导致事务终止,这种情况下,事务中的消息都不会被Consumer读取。现在我们来看下Kafka是如何实现原子的“读取-处理-写入”过程的。
首先,我们来考虑一下原子“读取-处理-写入”周期是什么意思。简而言之,这意味着如果某个应用程序在某个topic tp0的偏移量X处读取到了消息A,并且在对消息A进行了一些处理(如B = F(A))之后将消息B写入topic tp1,则只有当消息A和B被认为被成功地消费并一起发布,或者完全不发布时,整个读取过程写入操作是原子的。
现在,只有当消息A的偏移量X被标记为消耗时,消息A才被认为是从topic tp0消耗的,消费到的数据偏移量(record offset)将被标记为提交偏移量(Committing offset)。在Kafka中,我们通过写入一个名为offsets topic的内部Kafka topic来记录offset commit。消息仅在其offset被提交给offsets topic时才被认为成功消费。
由于offset commit只是对Kafkatopic的另一次写入,并且由于消息仅在提交偏移量时被视为成功消费,所以跨多个主题和分区的原子写入也启用原子“读取-处理-写入”循环:提交偏移量X到offset topic和消息B到tp1的写入将是单个事务的一部分,所以整个步骤都是原子的。
2.2. 粉碎“僵尸实例”
我们通过为每个事务Producer分配一个称为transactional.id的唯一标识符来解决僵尸实例的问题。在进程重新启动时能够识别相同的Producer实例。
API要求事务性Producer的第一个操作应该是在Kafka集群中显示注册transactional.id。 当注册的时候,Kafka broker用给定的transactional.id检查打开的事务并且完成处理。 Kafka也增加了一个与transactional.id相关的epoch。Epoch存储每个transactional.id内部元数据。
一旦这个epoch被触发,任何具有相同的transactional.id和更旧的epoch的Producer被视为僵尸,并被围起来, Kafka会拒绝来自这些Procedure的后续事务性写入。
2.3. 读事务消息
现在,让我们把注意力转向数据读取中的事务一致性。
Kafka Consumer只有在事务实际提交时才会将事务消息传递给应用程序。也就是说,Consumer不会提交作为整个事务一部分的消息,也不会提交属于中止事务的消息。
值得注意的是,上述保证不足以保证整个消息读取的原子性,当使用Kafka consumer来消费来自topic的消息时,应用程序将不知道这些消息是否被写为事务的一部分,因此他们不知道事务何时开始或结束;此外,给定的Consumer不能保证订阅属于事务一部分的所有Partition,并且无法发现这一点,最终难以保证作为事务中的所有消息被单个Consumer处理。
简而言之:Kafka保证Consumer最终只能提供非事务性消息或提交事务性消息。它将保留来自未完成事务的消息,并过滤掉已中止事务的消息。
四 、事务处理Java API
producer提供了五个事务方法:
- initTransactions
- beginTransaction
- sendOffsets
- commitTransaction
- abortTransaction
1、api分类
在一个原子操作中,根据包含的操作类型,可以分为三种情况,前两种情况是事务引入的场景,最后一种情况没有使用价值。
- 只有Producer生产消息;
- 消费消息和生产消息并存,这个是事务场景中最常用的情况,就是我们常说的“consume-transform-produce ”模式
- 只有consumer消费消息,这种操作其实没有什么意义,跟使用手动提交效果一样,而且也不是事务属性引入的目的,所以一般不会使用这种情况
2、事务配置
1、创建消费者代码,需要:
- 将配置中的自动提交属性(auto.commit)进行关闭
- 而且在代码里面也不能使用手动提交commitSync( )或者commitAsync( )
- 设置isolation.level
2、创建生成者,代码如下,需要:
- 配置transactional.id属性
- 配置enable.idempotence属性
3、“只有写”应用程序示例
package com.example.demo.transaction; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.util.Properties; import java.util.concurrent.Future; public class TransactionProducer { private static Properties getProps(){ Properties props = new Properties(); props.put("bootstrap.servers", "47.52.199.53:9092"); props.put("retries", 2); // 重试次数 props.put("batch.size", 100); // 批量发送大小 props.put("buffer.memory", 33554432); // 缓存大小,根据本机内存大小配置 props.put("linger.ms", 1000); // 发送频率,满足任务一个条件发送 props.put("client.id", "producer-syn-2"); // 发送端id,便于统计 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("transactional.id","producer-1"); // 每台机器唯一 props.put("enable.idempotence",true); // 设置幂等性 return props; } public static void main(String[] args) { KafkaProducer<String, String> producer = new KafkaProducer<>(getProps()); // 初始化事务 producer.initTransactions();try { Thread.sleep(2000); // 开启事务 producer.beginTransaction(); // 发送消息到producer-syn producer.send(new ProducerRecord<String, String>("producer-syn","test3")); // 发送消息到producer-asyn Future<RecordMetadata> metadataFuture = producer.send(new ProducerRecord<String, String>("producer-asyn","test4")); // 提交事务 producer.commitTransaction(); }catch (Exception e){ e.printStackTrace(); // 终止事务 producer.abortTransaction(); } } }
4、消费-生产并存(consume-Transform-Produce)
package com.example.demo.transaction; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.clients.consumer.OffsetAndMetadata; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import org.apache.kafka.common.TopicPartition; import java.util.Arrays; import java.util.HashMap; import java.util.Map; import java.util.Properties; import java.util.concurrent.Future; public class consumeTransformProduce { private static Properties getProducerProps(){ Properties props = new Properties(); props.put("bootstrap.servers", "47.52.199.51:9092"); props.put("retries", 3); // 重试次数 props.put("batch.size", 100); // 批量发送大小 props.put("buffer.memory", 33554432); // 缓存大小,根据本机内存大小配置 props.put("linger.ms", 1000); // 发送频率,满足任务一个条件发送 props.put("client.id", "producer-syn-2"); // 发送端id,便于统计 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("transactional.id","producer-2"); // 每台机器唯一 props.put("enable.idempotence",true); // 设置幂等性 return props; } private static Properties getConsumerProps(){ Properties props = new Properties(); props.put("bootstrap.servers", "47.52.199.51:9092"); props.put("group.id", "test_3"); props.put("session.timeout.ms", 30000); // 如果其超时,将会可能触发rebalance并认为已经死去,重新选举Leader props.put("enable.auto.commit", "false"); // 开启自动提交 props.put("auto.commit.interval.ms", "1000"); // 自动提交时间 props.put("auto.offset.reset","earliest"); // 从最早的offset开始拉取,latest:从最近的offset开始消费 props.put("client.id", "producer-syn-1"); // 发送端id,便于统计 props.put("max.poll.records","100"); // 每次批量拉取条数 props.put("max.poll.interval.ms","1000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("isolation.level","read_committed"); // 设置隔离级别 return props; } public static void main(String[] args) { // 创建生产者 KafkaProducer<String, String> producer = new KafkaProducer<>(getProducerProps()); // 创建消费者 KafkaConsumer<String, String> consumer = new KafkaConsumer<>(getConsumerProps()); // 初始化事务 producer.initTransactions(); // 订阅主题 consumer.subscribe(Arrays.asList("consumer-tran")); for(;;){ // 开启事务 producer.beginTransaction(); // 接受消息 ConsumerRecords<String, String> records = consumer.poll(500); // 处理逻辑 try { Map<TopicPartition, OffsetAndMetadata> commits = new HashMap<>(); for(ConsumerRecord record : records){ // 处理消息 System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value()); // 记录提交的偏移量 commits.put(new TopicPartition(record.topic(), record.partition()),new OffsetAndMetadata(record.offset())); // 产生新消息 Future<RecordMetadata> metadataFuture = producer.send(new ProducerRecord<>("consumer-send",record.value()+"send")); } // 提交偏移量 producer.sendOffsetsToTransaction(commits,"group0323"); // 事务提交 producer.commitTransaction(); }catch (Exception e){ e.printStackTrace(); producer.abortTransaction(); } } } }
在一个事务中,既有生产消息操作又有消费消息操作,即常说的Consume-tansform-produce模式。如下实例代码
五、事务工作原理
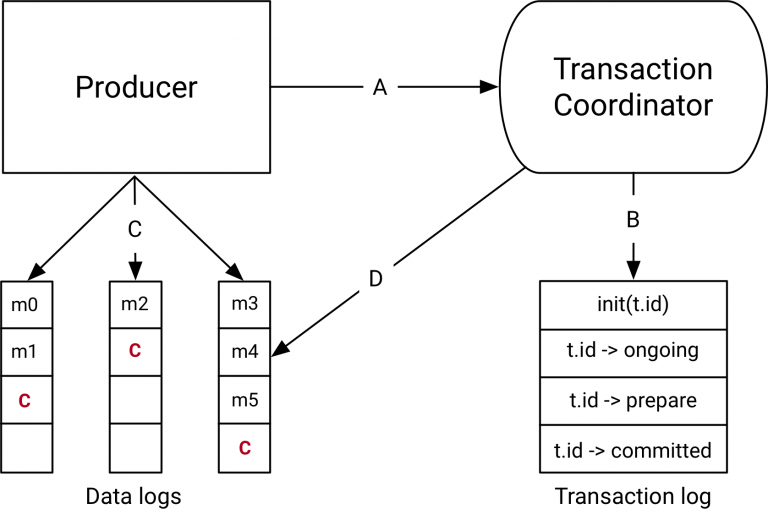
1、事务协调器和事务日志
在Kafka 0.11.0中与事务API一起引入的组件是上图右侧的事务Coordinator和事务日志。
事务Coordinator是每个KafkaBroker内部运行的一个模块。事务日志是一个内部的Kafka Topic。每个Coordinator拥有事务日志所在分区的子集,即, 这些borker中的分区都是Leader。
每个transactional.id都通过一个简单的哈希函数映射到事务日志的特定分区,事务日志文件__transaction_state-0。这意味着只有一个Broker拥有给定的transactional.id。
通过这种方式,我们利用Kafka可靠的复制协议和Leader选举流程来确保事务协调器始终可用,并且所有事务状态都能够持久存储。
值得注意的是,事务日志只保存事务的最新状态而不是事务中的实际消息。消息只存储在实际的Topic的分区中。事务可以处于诸如“Ongoing”,“prepare commit”和“Completed”之类的各种状态中。正是这种状态和关联的元数据存储在事务日志中。
2、事务数据流
数据流在抽象层面上有四种不同的类型。
A. producer和事务coordinator的交互
执行事务时,Producer向事务协调员发出如下请求:
- initTransactions API向coordinator注册一个transactional.id。 此时,coordinator使用该transactional.id关闭所有待处理的事务,并且会避免遇到僵尸实例,由具有相同的transactional.id的Producer的另一个实例启动的任何事务将被关闭和隔离。每个Producer会话只发生一次。
- 当Producer在事务中第一次将数据发送到分区时,首先向coordinator注册分区。
- 当应用程序调用commitTransaction或abortTransaction时,会向coordinator发送一个请求以开始两阶段提交协议。
B. Coordinator和事务日志交互
随着事务的进行,Producer发送上面的请求来更新Coordinator上事务的状态。事务Coordinator会在内存中保存每个事务的状态,并且把这个状态写到事务日志中(这是以三种方式复制的,因此是持久保存的)。
事务Coordinator是读写事务日志的唯一组件。如果一个给定的Borker故障了,一个新的Coordinator会被选为新的事务日志的Leader,这个事务日志分割了这个失效的代理,它从传入的分区中读取消息并在内存中重建状态。
C.Producer将数据写入目标Topic所在分区
在Coordinator的事务中注册新的分区后,Producer将数据正常地发送到真实数据所在分区。这与producer.send流程完全相同,但有一些额外的验证,以确保Producer不被隔离。
D.Topic分区和Coordinator的交互
- 在Producer发起提交(或中止)之后,协调器开始两阶段提交协议。
- 在第一阶段,Coordinator将其内部状态更新为“prepare_commit”并在事务日志中更新此状态。一旦完成了这个事务,无论发生什么事,都能保证事务完成。
- Coordinator然后开始阶段2,在那里它将事务提交标记写入作为事务一部分的Topic分区。
- 这些事务标记不会暴露给应用程序,但是在read_committed模式下被Consumer使用来过滤掉被中止事务的消息,并且不返回属于开放事务的消息(即那些在日志中但没有事务标记与他们相关联)。
- 一旦标记被写入,事务协调器将事务标记为“完成”,并且Producer可以开始下一个事务。
六、事务相关配置
1、Broker configs
1、ransactional.id.timeout.ms:
在ms中,事务协调器在生产者TransactionalId提前过期之前等待的最长时间,并且没有从该生产者TransactionalId接收到任何事务状态更新。默认是604800000(7天)。这允许每周一次的生产者作业维护它们的id
2、max.transaction.timeout.ms
事务允许的最大超时。如果客户端请求的事务时间超过此时间,broke将在InitPidRequest中返回InvalidTransactionTimeout错误。这可以防止客户机超时过大,从而导致用户无法从事务中包含的主题读取内容。
默认值为900000(15分钟)。这是消息事务需要发送的时间的保守上限。
3、transaction.state.log.replication.factor
事务状态topic的副本数量。默认值:3
4、transaction.state.log.num.partitions
事务状态主题的分区数。默认值:50
5、transaction.state.log.min.isr
事务状态主题的每个分区ISR最小数量。默认值:2
2、Producer configs
1、enable.idempotence:开启幂等
2、transaction.timeout.ms:事务超时时间
事务协调器在主动中止正在进行的事务之前等待生产者更新事务状态的最长时间。
这个配置值将与InitPidRequest一起发送到事务协调器。如果该值大于max.transaction.timeout。在broke中设置ms时,请求将失败,并出现InvalidTransactionTimeout错误。
默认是60000。这使得交易不会阻塞下游消费超过一分钟,这在实时应用程序中通常是允许的。
3、transactional.id
用于事务性交付的TransactionalId。这支持跨多个生产者会话的可靠性语义,因为它允许客户端确保使用相同TransactionalId的事务在启动任何新事务之前已经完成。如果没有提供TransactionalId,则生产者仅限于幂等交付。
3、Consumer configs
1、isolation.level
- read_uncommitted:以偏移顺序使用已提交和未提交的消息。
- read_committed:仅以偏移量顺序使用非事务性消息或已提交事务性消息。为了维护偏移排序,这个设置意味着我们必须在使用者中缓冲消息,直到看到给定事务中的所有消息。
七、事务性能以及如何优化
1、Producer打开事务之后的性能
让我们把注意力转向事务如何执行。首先,事务只造成中等的写入放大。
额外的写入在于:
- 对于每个事务,我们都有额外的RPC向Coordinator注册分区。
- 在完成事务时,必须将一个事务标记写入参与事务的每个分区。同样,事务Coordinator在单个RPC中批量绑定到同一个Borker的所有标记,所以我们在那里保存RPC开销。但是在事务中对每个分区进行额外的写操作是无法避免的。
- 最后,我们将状态更改写入事务日志。这包括写入添加到事务的每批分区,“prepare_commit”状态和“complete_commit”状态。
我们可以看到,开销与作为事务一部分写入的消息数量无关。所以拥有更高吞吐量的关键是每个事务包含更多的消息。
实际上,对于Producer以最大吞吐量生产1KB记录,每100ms提交消息导致吞吐量仅降低3%。较小的消息或较短的事务提交间隔会导致更严重的降级。
增加事务时间的主要折衷是增加了端到端延迟。回想一下,Consum阅读事务消息不会传递属于公开传输的消息。因此,提交之间的时间间隔越长,消耗的应用程序就越需要等待,从而增加了端到端的延迟。
2、Consumer打开之后的性能
Consumer在开启事务的场景比Producer简单得多,它需要做的是:
- 过滤掉属于中止事务的消息。
- 不返回属于公开事务一部分的事务消息。
因此,当以read_committed模式读取事务消息时,事务Consumer的吞吐量没有降低。这样做的主要原因是我们在读取事务消息时保持零拷贝读取。
此外,Consumer不需要任何缓冲等待事务完成。相反,Broker不允许提前抵消包括公开事务。
因此,Consumer是非常轻巧和高效的。感兴趣的读者可以在本文档(链接2)中了解Consumer设计的细节。
八、进一步阅读
我们刚刚讲述了Apache Kafka中事务的表面。 幸运的是,几乎所有的设计细节都保存在在线文档中。 相关文件是:
最初的Kafka KIP(链接3):它提供了关于数据流的设计细节,并且详细介绍了公共接口,特别是与事务相关的配置选项。
原始设计文档(链接4):不是为了内核,这是源代码之外的权威地方 - 了解每个事务性RPC如何处理,如何维护事务日志,如何清除事务性数据等等。
KafkaProducerjavadocs(链接5):这是学习如何使用新API的好地方。页面开始处的示例以及send方法的文档是很好的起点。
九、结论
在这篇文章中,我们了解了ApacheKafka中关于事务API的关键设计目标,我们理解了事务API的语义,并对API的实际工作有了更高层次的理解。
如果我们考虑“读取-处理-写入”周期,这篇文章主要介绍了读写路径,处理本身就是一个黑盒子。事实是,在处理阶段中可以做很多事情,使得一次处理不可能保证单独使用事务API。例如,如果处理对其他存储系统有副作用,则这里覆盖的API不足以保证exactly once。
Kafka Streams框架使用事务API向上移动整个价值链,并为各种各样的流处理应用提供exactly once,甚至能够在处理期间更新某些附加状态并进行存储。
后续的博客文章将介绍KafkaStreams如何提供一次处理语义,以及如何编写利用它的应用程序。
最后,对于那些渴望了解上述API实现细节的人,我们将会有另一篇博客文章,其中涵盖了这里描述的一些更有趣的解决方案。
十、链接
1. https://www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/
2. https://docs.google.com/document/d/1Rlqizmk7QCDe8qAnVW5e5X8rGvn6m2DCR3JR2yqwVjc/edit?usp=sharing
4. https://docs.google.com/document/d/11Jqy_GjUGtdXJK94XGsEIK7CP1SnQGdp2eF0wSw9ra8/edit?usp=sharing
6. https://my.oschina.net/xiaominmin/blog/1816437
7. https://blog.csdn.net/ransom0512/article/details/78840042
8. https://blog.csdn.net/mlljava1111/article/details/81180351


 浙公网安备 33010602011771号
浙公网安备 33010602011771号