数据同步canal客户端
1、增量订阅、消费设计
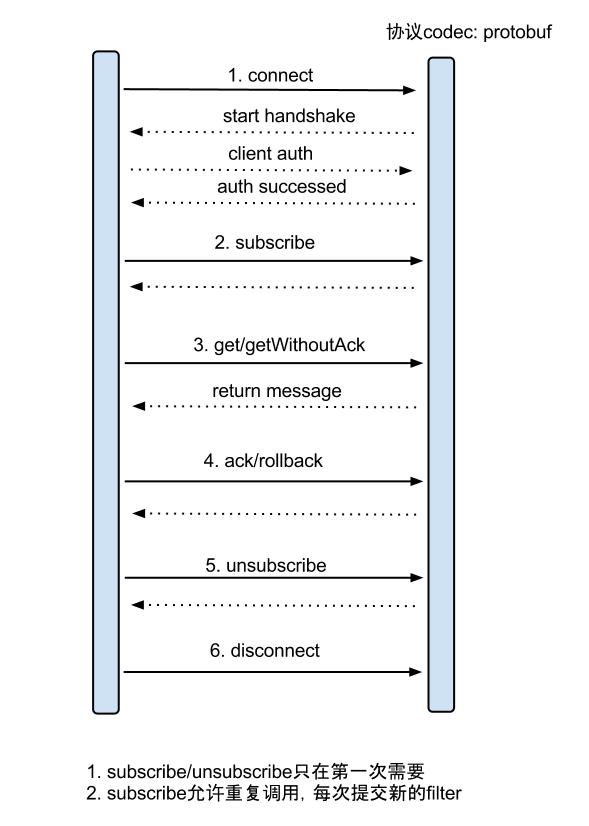
get/ack/rollback协议介绍:
① Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:
a. batch id 唯一标识
b. entries 具体的数据对象,对应的数据对象格式:EntryProtocol.proto
② void rollback(long batchId),顾命思议,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作
③ void ack(long batchId),顾命思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
2、数据对象格式:EntryProtocol.proto
1 Entry 2 Header 3 logfileName [binlog文件名] 4 logfileOffset [binlog position] 5 executeTime [binlog里记录变更发生的时间戳] 6 schemaName [数据库实例] 7 tableName [表名] 8 eventType [insert/update/delete类型] 9 entryType [事务头BEGIN/事务尾END/数据ROWDATA] 10 storeValue [byte数据,可展开,对应的类型为RowChange] 11 RowChange 12 isDdl [是否是ddl变更操作,比如create table/drop table] 13 sql [具体的ddl sql] 14 rowDatas [具体insert/update/delete的变更数据,可为多条,1个binlog event事件可对应多条变更,比如批处理] 15 beforeColumns [Column类型的数组] 16 afterColumns [Column类型的数组] 17 18 19 Column 20 index [column序号] 21 sqlType [jdbc type] 22 name [column name] 23 isKey [是否为主键] 24 updated [是否发生过变更] 25 isNull [值是否为null] 26 value [具体的内容,注意为文本]
insert只有after columns, delete只有before columns,而update则会有before / after columns数据.
3、client使用例子
3.1 创建Connector
a. 创建SimpleCanalConnector (直连ip,不支持server/client的failover机制)
1 CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),11111), destination, "", "");
b. 创建ClusterCanalConnector (基于zookeeper获取canal server ip,支持server/client的failover机制)
1 CanalConnector connector = CanalConnectors.newClusterConnector("10.20.144.51:2181", destination, "", "");
c. 创建ClusterCanalConnector (基于固定canal server的地址,支持固定的server ip的failover机制,不支持client的failover机制
1 CanalConnector connector = CanalConnectors.newClusterConnector(Arrays.asList(new InetSocketAddress(AddressUtils.getHostIp(),11111)), destination,"", "");
如上可见,创建client connector的时候需要指定destination,即对应于一个instance,一个数据库。所以canal client和数据库是一一对应的关系。
3.2 get/ack/rollback使用
1 // 创建链接 2 CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(canal_ip, 11111), destination, canal_username, canal_password); 3 4 try { 5 6 // 连接canal,获取数据 7 connector.connect(); 8 connector.subscribe(); 9 connector.rollback(); 10 log.info("数据同步工程启动成功,开始获取数据"); 11 while (true) { 12 13 // 获取指定数量的数据 14 Message message = connector.getWithoutAck(1000); 15 16 // 数据批号 17 long batchId = message.getId(); 18 19 // 获取该批次数据的数量 20 int size = message.getEntries().size(); 21 22 // 无数据 23 if (batchId == -1 || size == 0) { 24 25 // 等待1秒后重新获取 26 try { 27 Thread.sleep(1000); 28 } catch (InterruptedException e) { 29 log.error(e); 30 Thread.currentThread().interrupt(); 31 } 32 33 // 提交确认 34 connector.ack(batchId); 35 36 // 数据存在,执行方法 37 } else { 38 try { 39 40 // 处理数据 41 HandleData.handleEntry(message.getEntries()); 42 43 // 提交确认 44 connector.ack(batchId); 45 } catch (KafkaException e) { 46 log.error(e); 47 48 // 处理失败, 回滚数据 49 connector.rollback(batchId); 50 } catch (Exception e1) { 51 log.error(e1); 52 53 // 提交确认 54 connector.ack(batchId); 55 } 56 } 57 } 58 } catch (Exception e) { 59 60 log.error(e); 61 } finally { 62 63 // 断开连接 64 connector.disconnect(); 65 }
处理数据的方法封装到HandleData类中,且看handleEntry如何处理
1 // 获取日志行 2 RowChange rowChage = null; 3 try { 4 rowChage = RowChange.parseFrom(entry.getStoreValue()); 5 } catch (Exception e) { 6 log.error(e); 7 } 8 9 // 获取执行事件类型 10 EventType eventType = rowChage.getEventType(); 11 12 // 日志打印,数据明细 13 log.info(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s", entry 14 .getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(), entry.getHeader() 15 .getSchemaName(), entry.getHeader().getTableName(), eventType)); 16 17 // 获取表名 18 String tableName = entry.getHeader().getTableName(); 19 20 21 // 遍历日志行,执行任务 22 for (RowData rowData : rowChage.getRowDatasList()) { 23 Map<String, Object> data; 24 25 // 删除操作 26 if (eventType == EventType.DELETE) { 27 28 // 解析数据 29 data = DataUtils.parseData(tableName, "delete", rowData.getBeforeColumnsList()); 30 31 // 插入操作 32 } else if (eventType == EventType.INSERT) { 33 34 // 解析数据 35 data = DataUtils.parseData(tableName, "insert", rowData.getAfterColumnsList()); 36 37 // 更新操作 38 } else { 39 40 // 解析数据 41 data = DataUtils.parseData(tableName, "update", rowData.getAfterColumnsList()); 42 } 43 44 // 数据解析成功 45 if (data != null && data.size() > 0) { 46 47 48 // 内容转接json格式发送 49 JSONObject json = JSONObject.fromObject(data); 50 try { 51 Productor.send("canal_" + tableName = "_topic", json.toString(), tableName + "|" + data.get("canal_kafka_key")); 52 } catch (Exception e) { 53 throw new KafkaException("kafka发送异常:" + e); 54 } 55 56 log.info("数据成功发送kafka"); 57 } 58 }
Entry数据被解析成Map格式数据,然后转为json字符串,发到kafka。为什么要借用消息中间件kafka呢,不用kafka可以吗?当然可以,直接写数据同步的逻辑没有问题。但是如果一个数据用到多个业务场景,势必导致一个类中有多套同步逻辑,对于后期的维护很不利,多套业务掺杂在一起势必会互相影响。合理的做法应该是业务隔离,每套业务都能接受到数据变更的消息,然后做自己需要的同步,这样就需要在数据接受和数据处理形成1对n的关系。消息中间件的消息接受和消费模型正好可以完成这个功能。
一个canal client的消息分发给多个kafka消费者消费。每个kafka消费者代表一种业务场景,架构清晰、利于维护,同时一个kafka消费者可以消费多个canal client的topic。
上面的解析数据逻辑比较简单,将list解析成map
1 Map<String, Object> result = new HashMap<String, Object>(); 2 try { 3 int index = 0; 4 for (Column column : columns) { 5 String value = column.getIsNull() ? null : column.getValue(); 6 7 // kafka在消息为10K时吞吐量达到最大 8 if (value != null && value.length() > 10240) { 9 value = value.substring(0, 10240); 10 } 11 if (index == 0) { 12 result.put("canal_kafka_key", value); 13 } 14 result.put(column.getName(), value); 15 index++; 16 } 17 result.put("operate_type", "delete"||"insert"||"update"); 18 } catch (Exception e) { 19 log.error(e); 20 } 21 if (logStr.lastIndexOf(",") == logStr.length() - 1) { 22 logStr = logStr.substring(0, logStr.length() - 1); 23 } 24 return result;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号