map
MAP
非thread-safe
数据结构
┌─────────────┐
│ hmap │
├─────────────┴──────────────────┐ ┌───────────────┐ ┌─────────┐ ┌─────────┐
│ count int │ │ │ ┌─────────────────▶│ bmap │ ┌───▶│ bmap │
│ │ │ ▼ │ ├─────────┴─────────────────────┐ │ ├─────────┴─────────────────────┐
├────────────────────────────────┤ │ ────────┬─────┐ │ │ tophash [bucketCnt]uint8 │ │ │ tophash [bucketCnt]uint8 │
│ flags uint8 │ │ ▲ │ 0 │ │ │ │ │ │ │
│ │ │ │ │ │──────────────────┘ ├──────────┬────────────────────┤ │ ├──────────┬────────────────────┤
├────────────────────────────────┤ │ │ ├─────┤ │ keys │ │ │ │ keys │ │
│ B uint8 │ │ │ │ 1 │ ├───┬───┬──┴┬───┬───┬───┬───┬───┤ │ ├───┬───┬──┴┬───┬───┬───┬───┬───┤
│ │ │ │ │ │──────────────────┐ │ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │ │ │ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │
├────────────────────────────────┤ │ │ ├─────┤ │ ├───┴───┴──┬┴───┴───┴───┴───┴───┤ │ ├───┴───┴──┬┴───┴───┴───┴───┴───┤
│ noverflow uint16 │ │ │ │ 2 │ │ │ values │ │ │ │ values │ │
│ │ │ │ │ │ │ ├───┬───┬──┴┬───┬───┬───┬───┬───┤ │ ├───┬───┬──┴┬───┬───┬───┬───┬───┤
├────────────────────────────────┤ │ │ ├─────┤ │ │ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │ │ │ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │
│ hash0 uint32 │ │ │ │ 3 │ │ ├───┴───┴───┴───┴───┴───┴───┴───┤ │ ├───┴───┴───┴───┴───┴───┴───┴───┤
│ │ │ │ │ │ │ │ overflow *bmap │ │ │ overflow *bmap │
├────────────────────────────────┤ │ │ ├─────┤ │ │ │────┘ │ │
│ buckets unsafe.Pointer │ │ │ │ 4 │ │ ├─────────┬─────────────────────┘ └───────────────────────────────┘
│ │───────────┘ │ │ │ └─────────────────▶│ bmap │
├────────────────────────────────┤ ├─────┤ ├─────────┴─────────────────────┐
│ oldbuckets unsafe.Pointer │ │ 5 │ │ tophash [bucketCnt]uint8 │
│ │ │ │ │ │
├────────────────────────────────┤ size = 2 ^ B ├─────┤ ├──────────┬────────────────────┤
│ nevacuate uintptr │ │ 6 │ │ keys │ │
│ │ │ │ ├───┬───┬──┴┬───┬───┬───┬───┬───┤
├────────────────────────────────┤ │ ├─────┤ │ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │
│ extra *mapextra │ │ │ 7 │ ├───┴───┴──┬┴───┴───┴───┴───┴───┤
┌──│ │ │ │ │ │ values │ │
│ └────────────────────────────────┘ │ └─────┘ ├───┬───┬──┴┬───┬───┬───┬───┬───┤
│ │ .... │ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │
│ │ ├───┴───┴───┴───┴───┴───┴───┴───┤
│ │ ┌─────┐ │ overflow *bmap │
│ │ │ 61 │ │ │
│ │ │ │ └───────────────────────────────┘
▼ │ ├─────┤ ............
┌─────────────┐ │ │ 62 │ ┌─────────┐ ┌─────────┐ ┌─────────┐
│ mapextra │ │ │ │────────────────────────────────────▶│ bmap │ ┌───▶│ bmap │ ┌───▶│ bmap │
├─────────────┴──────────────┐ │ ├─────┤ ├─────────┴─────────────────────┐ │ ├─────────┴─────────────────────┐ │ ├─────────┴─────────────────────┐
│ overflow *[]*bmap │ │ │ 63 │ │ tophash [bucketCnt]uint8 │ │ │ tophash [bucketCnt]uint8 │ │ │ tophash [bucketCnt]uint8 │
│ │ ▼ │ │──────────────────┐ │ │ │ │ │ │ │ │
├────────────────────────────┤ ────────┴─────┘ │ ├──────────┬────────────────────┤ │ ├──────────┬────────────────────┤ │ ├──────────┬────────────────────┤
│ oldoverflow *[]*bmap │ │ │ keys │ │ │ │ keys │ │ │ │ keys │ │
│ │ │ ├───┬───┬──┴┬───┬───┬───┬───┬───┤ │ ├───┬───┬──┴┬───┬───┬───┬───┬───┤ │ ├───┬───┬──┴┬───┬───┬───┬───┬───┤
├────────────────────────────┤ │ │ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │ │ │ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │ │ │ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │
│ nextoverflow *bmap │ │ ├───┴───┴──┬┴───┴───┴───┴───┴───┤ │ ├───┴───┴──┬┴───┴───┴───┴───┴───┤ │ ├───┴───┴──┬┴───┴───┴───┴───┴───┤
│ │ │ │ values │ │ │ │ values │ │ │ │ values │ │
└────────────────────────────┘ │ ├───┬───┬──┴┬───┬───┬───┬───┬───┤ │ ├───┬───┬──┴┬───┬───┬───┬───┬───┤ │ ├───┬───┬──┴┬───┬───┬───┬───┬───┤
│ │ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │ │ │ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │ │ │ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │
│ ├───┴───┴───┴───┴───┴───┴───┴───┤ │ ├───┴───┴───┴───┴───┴───┴───┴───┤ │ ├───┴───┴───┴───┴───┴───┴───┴───┤
│ │ overflow *bmap │ │ │ overflow *bmap │ │ │ overflow *bmap │
│ │ │────┘ │ │───┘ │ │
│ ├─────────┬─────────────────────┘ └───────────────────────────────┘ └───────────────────────────────┘
└─────────────────▶│ bmap │
├─────────┴─────────────────────┐
│ tophash [bucketCnt]uint8 │
│ │
├──────────┬────────────────────┤
│ keys │ │
├───┬───┬──┴┬───┬───┬───┬───┬───┤
│ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │
├───┴───┴──┬┴───┴───┴───┴───┴───┤
│ values │ │
├───┬───┬──┴┬───┬───┬───┬───┬───┤
│ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │
├───┴───┴───┴───┴───┴───┴───┴───┤
│ overflow *bmap │
│ │
└───────────────────────────────┘
const (
// 一个 bucket 最多能放的元素数
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// load factor = 13/2
loadFactorNum = 13
loadFactorDen = 2
// 超过这两个 size 的对应对象,会被转为指针
maxKeySize = 128
maxValueSize = 128
// data offset should be the size of the bmap struct, but needs to be
// aligned correctly. For amd64p32 this means 64-bit alignment
// even though pointers are 32 bit.
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)
// tophash 除了放正常的高 8 位的 hash 值
// 还会在空闲、迁移时存储一些特征的状态值
// 所以合法的 tophash(指计算出来的那种),最小也应该是 4
// 小于 4 的表示的都是我们自己定义的状态值
empty = 0 // cell is empty
evacuatedEmpty = 1 // cell is empty, bucket is evacuated.
evacuatedX = 2 // key/value is valid. Entry has been evacuated to first half of larger table.
evacuatedY = 3 // same as above, but evacuated to second half of larger table.
minTopHash = 4 // minimum tophash for a normal filled cell.
// flags
iterator = 1 // there may be an iterator using buckets
oldIterator = 2 // there may be an iterator using oldbuckets
hashWriting = 4 // a goroutine is writing to the map
sameSizeGrow = 8 // the current map growth is to a new map of the same size
// sentinel bucket ID for iterator checks
noCheck = 1<<(8*sys.PtrSize) - 1
)
//src/runtime/map.go
type hmap struct {
// 元素个数,调用 len(map) 时,直接返回此值
count int
flags uint8
// buckets 的对数 log_2
B uint8
// overflow 的 bucket 近似数
noverflow uint16
// 计算 key 的哈希的时候会传入哈希函数
hash0 uint32
// 指向 buckets 数组,大小为 2^B
// 如果元素个数为0,就为 nil
buckets unsafe.Pointer
// 扩容的时候,buckets 长度会是 oldbuckets 的两倍
oldbuckets unsafe.Pointer
// 指示扩容进度,小于此地址的 buckets 迁移完成
nevacuate uintptr
extra *mapextra // optional fields
}
type mapextra struct {
// 如果 key 和 value 都不包含指针,并且可以被 inline(<=128 字节)
// 使用 extra 来存储 overflow bucket,这样可以避免 GC 扫描整个 map
// 然而 bmap.overflow 也是个指针。这时候我们只能把这些 overflow 的指针
// 都放在 hmap.extra.overflow 和 hmap.extra.oldoverflow 中了
// overflow 包含的是 hmap.buckets 的 overflow 的 bucket
// oldoverflow 包含扩容时的 hmap.oldbuckets 的 overflow 的 bucket
overflow *[]*bmap
oldoverflow *[]*bmap
// 指向空闲的 overflow bucket 的指针
nextOverflow *bmap
}
B:是buckets数组的长度的对数,也就是说 buckets 数组的长度就是 2^B。bucket 里面存储了 key 和 value;buckets:是一个指针,最终它指向的是一个结构体:
type bmap struct {
tophash [bucketCnt]uint8
}
但这只是表面(src/runtime/hashmap.go)的结构,编译期间会给它加料,动态地创建一个新的结构:
type bmap struct {
topbits [8]uint8//哈希值相同的键(准确的说是哈希值低位相同的键)存入当前bucket时会将哈希值的高位存储在该数组中,以方便后续匹配
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr //指向的是下一个bucket,据此将所有冲突的键连接起来
}
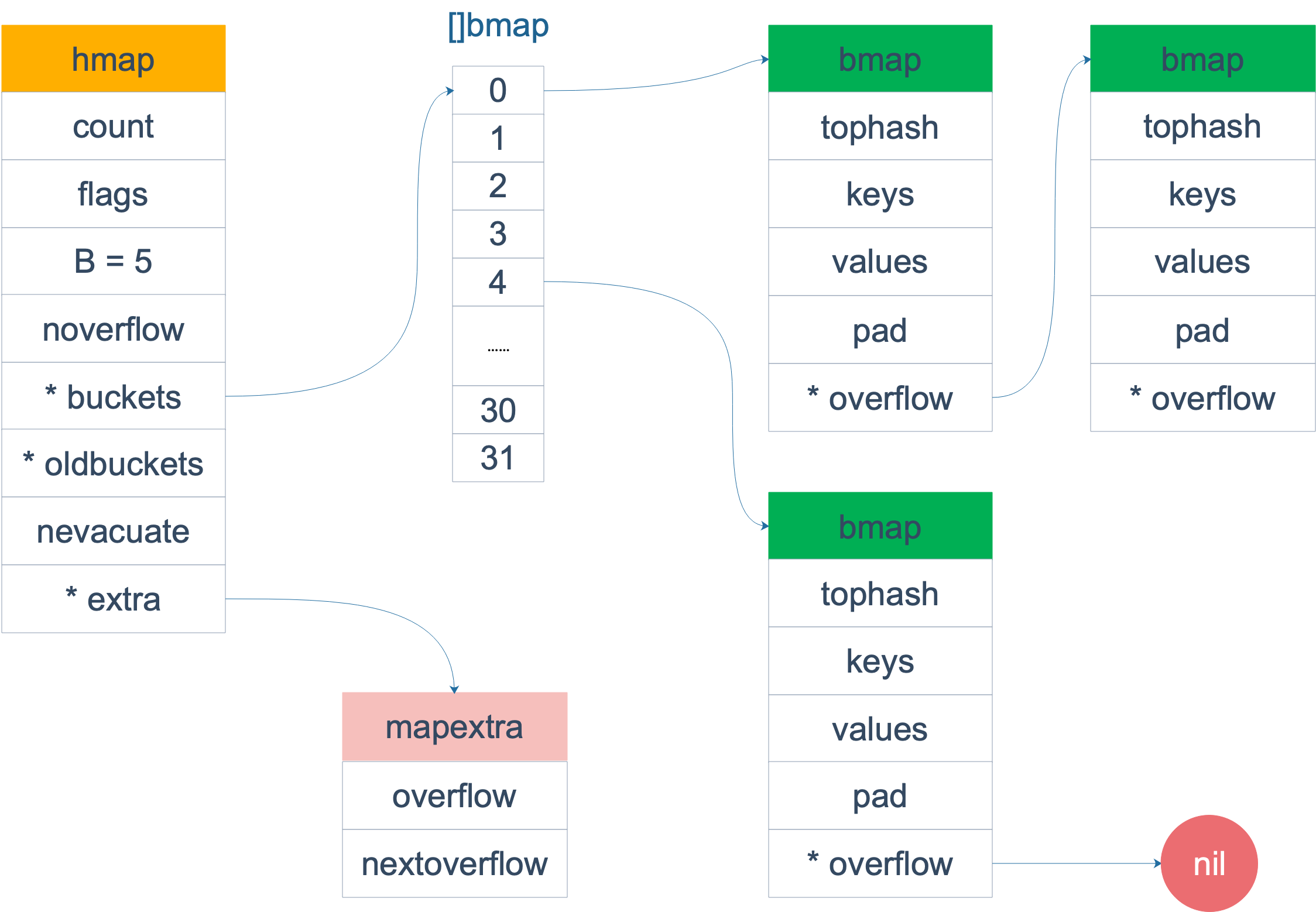
- bmap:就是常说的“桶”,桶里面会最多装 8 个 key,这些 key 之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果是“一类”的。在桶内,又会根据 key 计算出来的 hash 值的高 8 位来决定 key 到底落入桶内的哪个位置(一个桶内最多有8个位置)
bmap 是存放 k-v 的地方:
![]()
key 和 value 是各自放在一起的,并不是 key/value/key/value/... 这样的形式。源码里说明这样的好处是在某些情况下可以省略掉 padding 字段,节省内存空间。
每个 bucket 设计成最多只能放 8 个 key-value 对,如果有第 9 个 key-value 落入当前的 bucket,那就需要再构建一个 bucket ,通过 overflow 指针连接起来。

创建
https://my.oschina.net/renhc/blog/2208417
ageMp := make(map[string]int)
// 指定 map 长度
ageMp := make(map[string]int, 8)
// ageMp 为 nil,不能向其添加元素,会直接panic
var ageMp map[string]int
作参数
makemap 和 makeslice 的区别,带来一个不同点:当 map 和 slice 作为函数参数时,在函数参数内部对 map 的操作会影响 map 自身;而对 slice 却不会.
主要原因:一个是指针(hmap),一个是结构体(slice)。Go 语言中的函数传参都是值传递,在函数内部,参数会被 copy 到本地。hmap指针 copy 完之后,仍然指向同一个 map,因此函数内部对 map 的操作会影响实参。而 slice 被 copy 后,会成为一个新的 slice,对它进行的操作不会影响到实参
哈希函数
哈希函数的选择。在程序启动时,会检测 cpu 是否支持 aes,如果支持,则使用 aes hash,否则使用 memhash。这是在函数 alginit() 中完成,位于路径:src/runtime/alg.go
hash 函数,有加密型和非加密型。
加密型的一般用于加密数据、数字摘要等,典型代表就是 md5、sha1、sha256、aes256 这种;
非加密型的一般就是查找。在 map 的应用场景中,用的是查找。
选择 hash 函数主要考察的是两点:性能、碰撞概率。
key定位
https://github.com/cch123/golang-notes/blob/master/map.md
https://my.oschina.net/renhc/blog/2208417
key 经过哈希计算后得到哈希值,共 64 个 bit 位,计算它到底要落在哪个桶时,只会用到最后 B 个 bit 位。hmap.B,如果 B = 5,那么桶的数量,也就是 buckets 数组的长度是 2^5 = 32
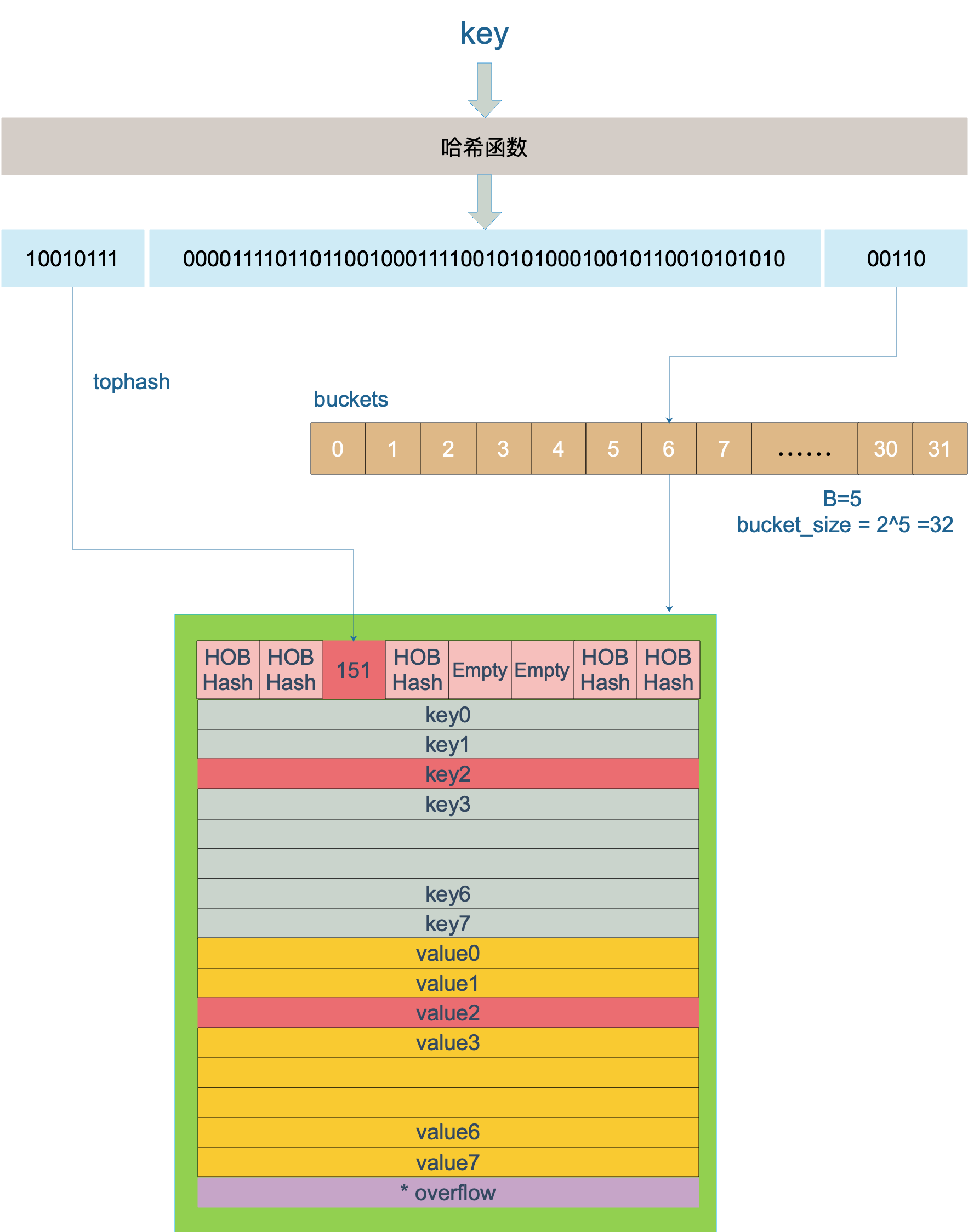
假定 B = 5,所以 bucket 总数就是 2^5 = 32。首先计算出待查找 key 的哈希,使用低 5 位 00110,找到对应的 6 号 bucket,使用高 8 位 10010111,对应十进制 151,在 6 号 bucket 中寻找 tophash 值(HOB hash)为 151 的 key,找到了 2 号槽位,这样整个查找过程就结束了。
如果在 bucket 中没找到,并且 overflow 不为空,还要继续去 overflow bucket 中寻找,直到找到或是所有的 key 槽位都找遍了,包括所有的 overflow bucket
map 的两种 get 操作
Go 语言中读取 map 有两种语法:带 comma 和 不带 comma。当要查询的 key 不在 map 里,带 comma 的用法会返回一个 bool 型变量提示 key 是否在 map 中;而不带 comma 的语句则会返回一个 value 类型的零值。如果 value 是 int 型就会返回 0,如果 value 是 string 类型,就会返回空字符串.
package main
import "fmt"
func main() {
ageMap := make(map[string]int)
ageMap["qcrao"] = 18
// 不带 comma 用法
age1 := ageMap["stefno"]
fmt.Println(age1)
// 带 comma 用法
age2, ok := ageMap["stefno"]
fmt.Println(age2, ok)
0
0 false
两种语法对应到底层函数
// src/runtime/hashmap.go
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)
根据 key 的不同类型
src/runtime/hashmap_fast.go
| key类型 | 查找 |
|---|---|
| uint32 | mapaccess1_fast32(t *maptype, h *hmap, key uint32) unsafe.Pointer |
| uint32 | mapaccess2_fast32(t *maptype, h *hmap, key uint32) (unsafe.Pointer, bool) |
| uint64 | mapaccess1_fast64(t *maptype, h *hmap, key uint64) unsafe.Pointer |
| uin64 | mapaccess2_fast64(t *maptype, h *hmap, key uint64) (unsafe.Pointer, bool) |
| string | mapaccess1_faststr(t *maptype, h *hmap, ky string) unsafe.Pointer |
| string | mapaccess2_faststr(t *maptype, h *hmap, ky string) (unsafe.Pointer, bool) |
哈希冲突(碰撞问题)
不同的key,哈希结果在同一个bucket中,解决有两种方法。链表法,开放地址法;
链表法
链表法将一个 bucket 实现成一个链表,落在同一个 bucket 中的 key 都会插入这个链表
开放地址法
碰撞发生后,通过一定的规律,在数组的后面挑选“空位”,用来放置新的 key。
扩容
哈希冲突会影响哈希表的读写效率,选择散列均匀的哈希函数可以减少哈希冲突的发生,适时对哈希表进行扩容也是保障读写效率的有效手段
扩容前提条件
为了保证访问效率,当新元素将要添加进map时,都会检查是否需要扩容,扩容实际上是以空间换时间的手段。
触发扩容的条件有二个:
- 负载因子 > 6.5时,也即平均每个bucket存储的键值对达到6.5个。
负载因子:hmap.count(键值对总数)/hmap.buckets(bucket总数) - overflow数量 > 2^15时,也即overflow数量超过32768时。
渐进式扩容
增量扩容
等量扩容
缩容
GO的map是不会缩容的,除非你把整个map删掉
查找过程
- 跟据key值算出哈希值
2.取哈希值低位与hmpa.B取模确定bucket位置
3.取哈希值高位在tophash数组中查询
4.如果tophash[i]中存储值也哈希值相等,则去找到该bucket中的key值进行比较
5.当前bucket没有找到,则继续从下个overflow的bucket中查找。
6.如果当前处于搬迁过程,则优先从oldbuckets查找
注:如果查找不到,也不会返回空值,而是返回相应类型的0值。
插入过程
1.跟据key值算出哈希值
2.取哈希值低位与hmap.B取模确定bucket位置
3.查找该key是否已经存在,如果存在则直接更新值
4.如果没找到key,将key插入
哈希查表
返回的 key 序列,哈希查找表则是乱序的
搜索树
自平衡搜索树
返回的 key 序列,一般会按照从小到大的顺序
AVL树
红黑树
实例1
func mapAddr() {
var mp = map[int]int{1: 2, 2: 3, 3: 4}
fmt.Printf("初始化map地址:%p\n", &mp)
fmt.Println("循环取值")
// Tip 注意range中的k是不能保证顺序的
for k, v := range mp {
// Tip k,v 是为了遍历、另外开辟内存的一对变量,不是map中key/value保存的地址
fmt.Printf("k地址:%p,v地址:%p\n", &k, &v)
// Tip 修改k/v后,map中所对应的k/v不会生效
k++
v++
// Tip 如果在这里加上一个delete操作,在k=1且++后,删除的是k=2的元素,在次遍历就是k=3的元素
// map的delete是安全的,不会存在race等竞争问题,这里用到的k,v是值复制,删除是针对hmap的操作
delete(mp, k)
// 编译错误,value不可寻址,因为这个在内部是频繁变化的
// fmt.Printf("&mp[k]:%p\n", &mp[k])
}
fmt.Println("输出mp:", mp)
}
1.输出结果,循环k:1,2,3
初始化map地址:0xc00000e028
循环取值
k地址:0xc0000160b0,v地址:0xc0000160b8
k地址:0xc0000160b0,v地址:0xc0000160b8
输出mp: map[1:2 3:4]
2.输出结果,循环k:2,1
初始化map地址:0xc00000e028
循环取值
k地址:0xc0000160b0,v地址:0xc0000160b8
k地址:0xc0000160b0,v地址:0xc0000160b8
输出mp: map[1:2]
说明range中的k不是顺序获取的
实例2
func mapModify() {
//Tip 初始化map时指定size,会减少hmap扩容时带来的内存重新分配,减少性能损失
// var mp=make(map[int]int,1000)
var mp = make(map[int]int)
mp[1] = 2
mp[2] = 3
mp[3] = 4
var count int
fmt.Printf("循环前map长度:%d\n", len(mp))
for k, v := range mp {
count++
// Tip 在range的过程中,如果不断扩容,何时退出是不确定的
mp[k+1] = v + 1
}
fmt.Printf("循环后map长度:%d\n", len(mp))
fmt.Printf("循环次数:%d\n", count)
}
1. 输出结果
循环前map长度:3
循环后map长度:9
循环次数:8
2. 输出结果
循环前map长度:3
循环后map长度:5
循环次数:4
3. 输出结果
循环前map长度:3
循环后map长度:4
循环次数:3
实例3
func mapReplace() {
o := make(map[string]string) //原map
r := make(map[string]string) //替换map
o["a"] = "x"
o["b"] = "y"
r["a"] = "1"
r["b"] = "2"
fmt.Printf("输出o:%v,长度:%d\n", o, len(o))
// Tip 因为o的k-v是在不断增加的,所以遍历何时结束是不确定的
// 此是k可能为"1"或"2",对应的r[k]是不存在的,返回定义时类型的默认值,空字符串""
for k, v := range o {
o[r[k]] = v
}
// Tip 为什么每次运行结果会不一致?
// 1. 遍历在hmap中是通过buckets进行的
// 2. 每次运行时,分配的bucket是有随机的
// 3. hash0是个随机值,确认其对分配
fmt.Printf("替换输出o:%v,长度:%d\n", o, len(o))
delete(o, "a")
delete(o, "b")
fmt.Printf("删除k:a,b输出o:%v,长度:%d\n", o, len(o))
}
1. 结果输出
输出o:map[a:x b:y],长度:2
替换输出o:map[:y 1:x 2:y a:x b:y],长度:5 //:y k可能为"1"或"2",对应的r[k]是不存在的,返回定义时类型的默认值,空字符串""
删除k:a,b输出o:map[:y 1:x 2:y],长度:3
2. 结果输出
输出o:map[a:x b:y],长度:2
替换输出o:map[1:x 2:y a:x b:y],长度:4
删除k:a,b输出o:map[1:x 2:y],长度:2
3. 结果输出
输出o:map[a:x b:y],长度:2
替换输出o:map[:x 1:x 2:y a:x b:y],长度:5
删除k:a,b输出o:map[:x 1:x 2:y],长度:3
实例4-实现set
- struct{}
func mapSet() {
// 空struct是不占用空间的
var mp = make(map[string]struct{})
fmt.Println(mp)
var s1 struct{}
fmt.Println(unsafe.Sizeof(s1)) // prints 0
type S struct {
a uint16
b uint32
}
var s S
fmt.Println(unsafe.Sizeof(s)) // prints 8, not 6
a := struct{}{}
b := struct{}{}
fmt.Println(a == b) // true
fmt.Printf("%p, %p\n", &a, &b) // 0x55a988, 0x55a988
}
- Set实现
//map key放置数据
type Set struct {
m map[interface{}]struct{}
}
//获取Set
func GetSet() *Set {
return &Set{
m: make(map[interface{}]struct{}),
}
}
//返回key的数组
func (s *Set) GetArray() *[]interface{} {
l := len(s.m)
array := make([]interface{}, l)
sum := 0
for k, _ := range s.m {
array[sum] = k
sum++
}
return &array
}
//增加元素,判断是否存在
func (s *Set) Add(i interface{}) bool {
if _, ok := s.m[i]; ok {
return false
} else {
s.m[i] = struct{}{}
return true
}
}
//删除元素
func (s *Set) Remove(i interface{}) {
delete(s.m, i)
}
//清除元素
func (s *Set) Clear() {
s.m = make(map[interface{}]struct{})
}
//获取长度
func (s *Set) GetLen() int {
return len(s.m)
}
func main(){
s := GetSet()
b := s.Add(1)
s.Add(2)
s.Add(3)
s.Add("5")
s.Add(1.1)
fmt.Println(b)
fmt.Println("s len:", s.GetLen())
a := s.GetArray()
fmt.Println("key arr:", *a)
}
结果输出
true
s len: 5
key arr: [5 1.1 1 2 3]
实例5-嵌套map
func nestMap() {
// 只会初始化第一层map
var mp = make(map[string]map[string]string)
fmt.Println("第一层初始化:", mp)
//使第二层时初始化
mp["test"] = make(map[string]string)
fmt.Println("第二层初始化:", mp)
}
结果输出
第一层初始化: map[]
第二层初始化: map[test:map[]]
map示例总结:
- map读取某个值时-返回结果可以为value,bool或者value.注意后者,在key不存在时,会返回value对应类型的默认值(channel相同)
- map的range方法需要注意-key,value或者key.注意后者,可以和slice的使用结合起来
- map的range操作-key,value都是值复制
- map如何保证按key的某个顺序遍历?
分两次遍历,第一次取出所有key并排序;第二次按排序后的key去遍历(可将map和slice封装到一个结构体中) - map的使用上,需要注意?
遍历时,尽量只修改或删除当前key,操作非当前key会带来不可预知的结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号