


Accurate Image Super-Resolution Using Very Deep Convolutional Networks(阅读笔记)22.10.04 ——AlexNet
摘要:本论文训练了一个5层卷积3层全连接层的网络,卷积层后面有最大池化层,全连接层最后有Softmax。使用了dropout正则化。
- 介绍:
网络层数很重要,使用了一些技术防止过拟合。这个网络减少了训练时间。
- 数据集:
ImageNet、ILSVRC-2010(测试集标签可用)。网络需要恒定输入维度,因此将ImageNet的图像裁剪到256x256的固定分辨率。在RGB上训练图像。
- 结构:
8个学习层,5个卷积层,3个FC layer。
ReLu(非线性激活函数) 具有relu的网络始终比饱和神经元的网络学习速度快几倍。饱和非线性比非饱和非线性f(x) = max(0, x)要慢得多。
多GPU训练
局部响应归一化
aix,y表示在(x,y)处采用卷积核i处理然后使用ReLu激活得到数据。Bix,y是归一化后的数据。N是层中核的总数。内核映射顺序是任意的,训练之前确定。常数k, n, α和β是超参数,其值由验证集确定;论文使用k=2,n=5, α=10-4, β=0.75.
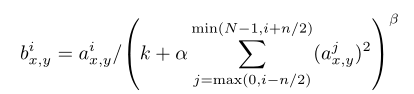
池化单元间隔s个像素,每个单元汇总池化单元中心大小的zxz的邻域。论文s=2,z=3。
总体结构:
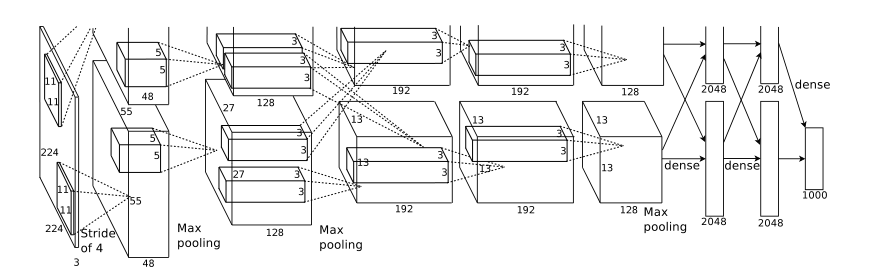
第一层卷积用96个11*11*3的核过滤图像224*224*3的图像,步幅为4像素(怎么算这个步幅)。
第二层将第一层的输出归一化和池化,用256个5*5*96的核进行滤波。
第三(384个3*3*256)、四(384,3*3*192)、五(256,3*3*192)层卷积相互连接,没有干涉池化核归一化。
全连接层每层有4096个神经元。
- 减少过拟合:
4.1人为的扩大数据集:1.图像平移和水平反射后面的具体内容看不太懂,怎么就数据集扩大2048倍了?答:本来数据集一个256*256的图像只能提取一个224*224的patch,经过平移和水平反射,2*(256-224)*(256-224)=2048倍;2.改变训练集图像中RGB通道的强度。(PCA提取出特征的主要成分来降维?不理解PCA)
4.2 Dropout:将每个隐藏神经元的输出设置为0的概率为0.5,就是每一个隐藏神经元都有0.5的概率被丢弃。由于测试时使用所有的神经元,因此最终的预测值也要乘以这个概率(0.5)。在前两个全连接层使用dropout,dropout大约使收敛所需的迭代次数翻倍。
- 学习细节:
使用随机梯度下降,批次大小(batch-size)为128个样本,动量(v)为0.9,权重衰减为0.0005来实现正则化,权重衰减不仅仅实现正则化,还减小了模型训练误差。色他是学习率。
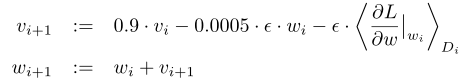
论文从标准差为0.01的零均值高斯分布初始化每一层的权重。论文用常数1初始化了第二、第四和第五卷积层以及全连接隐层中的神经元偏差。论文用常数0初始化其余层中的神经元偏差。所有层使用相同学习率,手动调制学习率。当验证错误率随着当前学习率停止改善时,学习率除以10。学习率初始值为0.01,终止前降低3倍。
6.代码复现的时候发现将一个数据集切成训练集和测试集,每次迭代的时候切的都是一样的吗?就是循环访问数据集时的各个样本顺序是一样的吗?
本文来自博客园,作者:键盘侠牧师,转载请注明原文链接:https://www.cnblogs.com/wangzhe52xia/p/17699842.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号