
内核中伙伴算法的实现
1.伙伴算法的引入
内核在频繁的请求和释放不同大小的一组连续页框,必然会导致在已经分配的块内分散了许多小块的空闲页框。由此带来的问题是,及时有足够的空闲页框可以满足请求,但是要分配一个大块的连续页框就无法满足。所以,内核应该为分配一组连续的页框而建立一种健壮,高校的分配策略。这样,内核就引入了伙伴算法。
2.伙伴算法的思想
Linux把所有的空闲页框分组为11个块链表,每个链表上的页框块是固定的。在第i条链表中每个页框块都包含2的i次方个连续页,其中i称为分配阶。下面以一个例子,讲述伙伴算法的思想:
假设要申请一个256个页,先从256个页框的链表中查找空闲块,如果没有,就去512个页框的链表中找,找到了则将页框块分为2个256个页框的块,一个分配给应用,另外一个移到256个页框的链表中。如果512个页框的链表中仍没有空闲块,继续向1024个页框的链表查找。如果1024块存在,则将其中的256页框作为请求返回,剩余的768分成256块和512块分别插到相应的链表中。如果仍然没有,则返回错误。
3.伙伴算法在内核中的数据结构
struct zone
{
struct free_area free_area[MAX_ORDER];
}
其中MAX_ORDER在内核中为:
#define MAX_ORDER 11 //即上文中提到的11个块链表
从上面可以看到free_area[]数组是一个struct free_area的结构体,其在内核中的定义为:
struct free_area
{
struct list_head free_list[MIGRATE_TYPES];/*说明了页的属性*/
unsigned long nr_free;/*来说明每个介中有多少个自由的页*/
};
在这个函数中有两个域,第一个是free_list,是个链表,它表示的就是当前分配阶所对应的页框块的链表。第二个nr_free指的是当前链表中空闲页框块的数目,比如free_area[2]中nr_free的值为5,表示有5个大小为4的页框块,那么总的空闲页为20.
对于free_list中的MIGRATE_TYPES表示的是迁移页的类型,在内核中的定义为:
#define MIGRATE_UNMOVABLE 0 //不可移动页:在内存中有固定位置,不能移动到其他地方
#define MIGRATE_RECLAIMABLE 1 //可回收页:不能直接移动,但可以删除,其内容可以从某些源重新生成
#define MIGRATE_MOVABLE 2 //可移动页:可以随意的移动
#define MIGRATE_RESERVE 3 //如果向具有特定可移动性地列表请求分配内存失败,这种紧急情况下可以从MIGRATE_RESERVE分配内存
#define MIGRATE_ISOLATE 4 //是一个特殊的虚拟区域,用于跨域NUMA结点移动物理内存页,在大型系统上,它有益于将物理内存页移动到接近于是用该页最频繁的CPU
#define MIGRATE_TYPES 5 //只是表示迁移类型的数目,不代表具体的区域
伙伴算法对应的示意图:

4.伙伴算法在内核分配页框时的实现
内核中分配页框的函数入口是:alloc_pages函数:
#define alloc_pages(gfp_mask, order) \
alloc_pages_node(numa_node_id(), gfp_mask, order)
alloc_pages_node()函数有三个参数:numa_node_id这个参数下文讲,gfp_mask这个参数指的是分配器的标志,也就是说分配的内存块所具有的属性(如果还是不懂,那就看看Linux内核设计与实现这本书,这里姑且认为是分配的内存块的属性),order指的是伙伴中的阶数。
下面来介绍下numa_node_id
首先,从硬件的角度说存在两种不同的机器,分别用两种不同的方式来管理机器。一种是UMA,另一种是NUMA,其示意图为:

由上面的分析可知:UMA指的是多个cpu共享一个内存,NUMA指的是每个cpu有自己的本地内存,然后处理器通过总线连接起来,进而可以访问其他cpu的本地内存。
那么内核是如何来组织这种不同的内存的呢?
Linux引入了一个概念称为node,一个node对应一个内存块,对于UMA系统,只有一个Node.其对应的数据结构为struct pglist_data.对于NUMA系统来讲,整个系统的内存由一个名为Node_data的struct pglist_data(page_data_t)指针数组来管理。
struct bootmem_data;
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
struct page *node_mem_map;
#ifdef CONFIG_CGROUP_MEM_RES_CTLR
struct page_cgroup *node_page_cgroup;
#endif
#endif
struct bootmem_data *bdata;
#ifdef CONFIG_MEMORY_HOTPLUG
/*
* Must be held any time you expect node_start_pfn, node_present_pages
* or node_spanned_pages stay constant. Holding this will also
* guarantee that any pfn_valid() stays that way.
*
* Nests above zone->lock and zone->size_seqlock.
*/
spinlock_t node_size_lock;
#endif
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
int node_id;
wait_queue_head_t kswapd_wait;
struct task_struct *kswapd;
int kswapd_max_order;
} pg_data_t;
node_zones:当前节点中内存管理区的描述符数组,node_list;指的是zonelist结构的数组。
由以上结构体可以推断每个node中又被分成多个zone(区),每个zone对应一片内存区域。NUMA系统的内存划分如图:
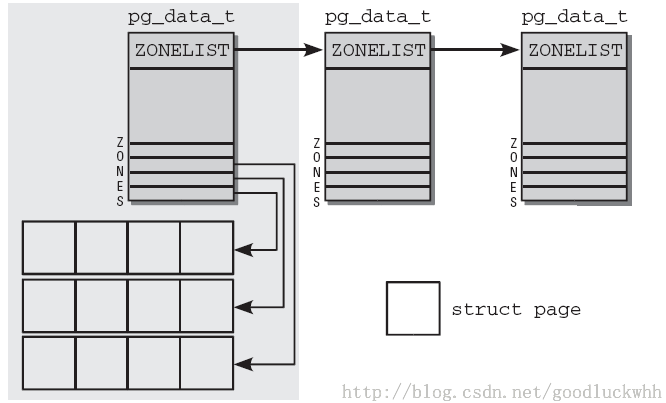
这里又引入了zone(区)这个概念,Linux引入了枚举类型描述zone的类型:
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
__MAX_NR_ZONES
};
- ZONE_DMA:可用作DMA的内存区域。该类型的内存区域在物理内存的低端,主要是ISA设备只能用低端的地址做DMA操作。
- ZONE_NORMAL:直接被内核直接映射到自己的虚拟地址空间的地址。
- ZONE_HIGHMEM:不能被直接映射到内核的虚拟地址空间的地址。
- ZONE_MOVABLE:伪zone,在防止物理内存碎片机制中使用
- MAX_NR_ZONES:结束标记
很显然,当我们在分配内存时,是按区进行分配的,一般我们会从zone_normal这个区上申请。
由上面得到numa_node_id参数的作用:获取节点id
4.1.__alloc_pages()函数
继续追踪内核代码,进入alloc_pages()函数后,发现调用的是__alloc_pages()函数
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,
unsigned int order)
{
/* Unknown node is current node */
if (nid < 0)
nid = numa_node_id();
return __alloc_pages(gfp_mask, order, node_zonelist(nid, gfp_mask));
}
我们发现其调用的是__alloc_pages()函数,在这个函数中调用了node_zonelist()函数,这个函数会根据节点号找到对应的zone,正好验证了我们上边说的:每个node又分成了好多个区,我们的内存其实是从具体的区上拿的。
4.2.__alloc_pages_nodemask()函数
在__alloc_pages函数中没有做任何的事情,就进入了__alloc_pages_nodemask()函数:
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist, nodemask_t *nodemask)
{
enum zone_type high_zoneidx = gfp_zone(gfp_mask);
struct zone *preferred_zone;
struct page *page;
int migratetype = allocflags_to_migratetype(gfp_mask);
gfp_mask &= gfp_allowed_mask;
lockdep_trace_alloc(gfp_mask);
might_sleep_if(gfp_mask & __GFP_WAIT);
if (should_fail_alloc_page(gfp_mask, order))
return NULL;
/*
* Check the zones suitable for the gfp_mask contain at least one
* valid zone. It's possible to have an empty zonelist as a result
* of GFP_THISNODE and a memoryless node
*/
if (unlikely(!zonelist->_zonerefs->zone))
return NULL;
/* The preferred zone is used for statistics later */
first_zones_zonelist(zonelist, high_zoneidx, nodemask, &preferred_zone);
if (!preferred_zone)
return NULL;
/* First allocation attempt核心函数 */
page = get_page_from_freelist(gfp_mask|__GFP_HARDWALL, nodemask, order,
zonelist, high_zoneidx, ALLOC_WMARK_LOW|ALLOC_CPUSET,
preferred_zone, migratetype);
if (unlikely(!page))
page = __alloc_pages_slowpath(gfp_mask, order,
zonelist, high_zoneidx, nodemask,
preferred_zone, migratetype);
trace_mm_page_alloc(page, order, gfp_mask, migratetype);
return page;
}
在这个函数中,首先,gfp_zone()会根据gfp_mask选取适当类型的zone.下面接着是几项参数的检测以及安全性的检测。然后通过zonelist->_zonerefs->zone判断zone是否为空,由unlike知道,一般情况下不会是空。接着是first_zones_zonelist()函数来确定在该zone中优先分配内存的内存管理区。可以发现核心的分配的函数是在get_page_from_freelist()这个函数中。
4.3. get_page_from_freelist
这个函数可以看作是计入伙伴算法的前置函数,它通过传递进来的分配标志和分配阶,寻找适合的区(zone),如果找到了满足条件的区,则进行伙伴算法,进行分配。我们来看下这个函数的主要功能:
首先是通过函数for_each_zone_zonelist_nodemask()函数来遍历zonelist
for_each_zone_zonelist_nodemask(zone, z, zonelist,
high_zoneidx, nodemask) {
if (NUMA_BUILD && zlc_active &&
!zlc_zone_worth_trying(zonelist, z, allowednodes))/*检查zlc(zone list cache),当前zone是否有freepage*/
continue;
if ((alloc_flags & ALLOC_CPUSET) && /*当前分配标志不允许在该管理区中分配页面*/
!cpuset_zone_allowed_softwall(zone, gfp_mask))
goto try_next_zone;
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
if (!(alloc_flags & ALLOC_NO_WATERMARKS)) {
unsigned long mark;
int ret;
mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK];
if (zone_watermark_ok(zone, order, mark,/*如果freepage够,开始伙伴算法*/
classzone_idx, alloc_flags))
goto try_this_zone;
该函数一进来首先是对zlc(zone list cache)的检测,检测当前zone是否有足够的freepage,如果没有,直接continue,进入下一个zone .
接着是对分配标志位的一个检测,检查当前分配标志是否允许在该管理区中分配页面。接着是对当前zone的一个水位线的获取,这个水位线是什么呢?来看下内核的定义:
enum zone_watermarks {
WMARK_MIN, //说明当前可以用的内存已经达到最低限度了
WMARK_LOW, //可用内存很少了,但是还没有最底线,不是很紧急的情况下,就不要占用内存了
WMARK_HIGH, //剩余的内存还有很多,大家放心使用吧
NR_WMARK
};
可以知道,水位线其实就是个标志,标志这个区域的内存的剩余量情况。那么zone_watermark_ok函数的作用就很明显了,就是检查这个区域的水位线是否有足够的free_page.如果够的话,就直接try_this_zone,进入我们的伙伴算法。
继续跟着我们的代码走:
if (zone_reclaim_mode == 0)/*等于0表明该zone已经满*/
goto this_zone_full;
ret = zone_reclaim(zone, gfp_mask, order);/*内存回收函数*/
switch (ret) {
case ZONE_RECLAIM_NOSCAN:/*没有进行回收直接尝试下一个zone*/
/* did not scan */
goto try_next_zone;
case ZONE_RECLAIM_FULL:/*回收了但是没有回收到*/
/* scanned but unreclaimable */
goto this_zone_full;
default: /*zone_watermark_ok扫描是否有足够的free page*/
/* did we reclaim enough */
if (!zone_watermark_ok(zone, order, mark,
classzone_idx, alloc_flags))
goto this_zone_full;
}
}
紧接着是对zone_reclaim_mode标志域的判断,如果等于0,表示该zone已经满了,就去执行this_zone_full将其标记为已经满了,下次再检测这个区的时候,直接忽略掉。接着zone_reclamin()函数,这个函数的作用是内存回收,如果执行到了这里,说明内存时不够的,需要进行回收再分配,它的返回值有三个:
ZONE_RECLAIM_NOSCAN
表示没有进行回收,执行try_next_zone,尝试下一个zone
ZONE_RECLAIM_FULL
表示回收了,但是没有回收到,执行this_zone_full,将这个zone标记为满,下一次直接忽略。
其他:
再次执行zone_watermark_ok扫描是否有足够的free page .
接着一次for循环遍历完毕,执行下面的代码:
if (unlikely(NUMA_BUILD && page == NULL && zlc_active)) {
/* Disable zlc cache for second zonelist scan */
zlc_active = 0;
goto zonelist_scan;
}
return page;
意思很明确:如果第一次循环结束后page还是NULL, 则进行第二次分配,goto zonelist_scan重新进行遍历。
4.4buffered_rmqueue(伙伴算法的入口函数)
这个函数判断如果order(阶)等于0的话,那么会使用per_cpu这种机制。(本文不涉及,其实是自己不懂),这个函数最终会进入__rmqueue这个函数。
static struct page *__rmqueue(struct zone *zone, unsigned int order,
int migratetype)
{
struct page *page;
retry_reserve:
page = __rmqueue_smallest(zone, order, migratetype);//核心函数
if (unlikely(!page) && migratetype != MIGRATE_RESERVE) {
page = __rmqueue_fallback(zone, order, migratetype);
/*
* Use MIGRATE_RESERVE rather than fail an allocation. goto
* is used because __rmqueue_smallest is an inline function
* and we want just one call site
*/
if (!page) {
migratetype = MIGRATE_RESERVE;
goto retry_reserve;
}
}
trace_mm_page_alloc_zone_locked(page, order, migratetype);
return page;
}
这个函数的参数zone表明伙伴算法将从该内存管理区域中分配页框,order即分配阶,migratetype表示迁移类型。该函数首选__rmqueue_smallest()进行内存分配,如果分配失败的话,会通过__rmqueue_fallback()进行分配,总之,内核总是在竭尽全力保证分配内存的请求。
4.5__rmqueue_smallest
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area * area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);//找到我们的区域
if (list_empty(&area->free_list[migratetype]))
continue;
page = list_entry(area->free_list[migratetype].next,/*从双向链表中取出页框*/
struct page, lru);
list_del(&page->lru);
rmv_page_order(page);
area->nr_free--;
expand(zone, page, order, current_order, area, migratetype);/**/
return page;
}
return NULL;
}
这个函数的实现比较简单,首先从当前的order链表中根据migratetype类型查找空闲的页框,该链表不为空的时候,说明可以分配该分配阶对应的页框块。如果这个链表为空,则order++,在下一个更大的阶上对应的链表中查找空闲的页框块。一旦选定在当前遍历的分配阶级上分配页框块,那么就通过list_entry()获取这个页框,表示要分配出去,然后通过list_del将这个页框从链表上删除。rmv_page_order()函数会设置页框描述符中的private为0,该字段中本来保存的是其所处页框块的分配阶。此外更新nr_free的值。
4.6.expand()函数
__rmqueue_smallest函数中还有一个核心的函数expand(),进入这个函数的条件是在当前的order中没有找到,在更大的阶中找到了,这就需要根据伙伴算法的分割原理将比较大的页框块分割成较小的块。
static inline void expand(struct zone *zone, struct page *page,
int low, int high, struct free_area *area,
int migratetype)
{
unsigned long size = 1 << high;
while (high > low) {
area--;
high--;
size >>= 1;
VM_BUG_ON(bad_range(zone, &page[size]));
list_add(&page[size].lru, &area->free_list[migratetype]);
area->nr_free++;
set_page_order(&page[size], high);/*设置页的阶*/
}
}
这里以一个例子,进行分析expand()函数的执行过程:
比如之前需要从order为2的阶上分配,但是order为2的free_area的free_list上没有page块了,则去order为3的链表上找,如果此时为3的链表上也没有空闲的page块,则到oeder为4的链表上去找,如果此时正好找到了则停止。这样就获得了一个有16个page的page块,但是只请求了4个page块,那么此时多余的page要放到order为2和order为3的链表上。看程序size = 1 << high;这里我们的high是4,那么1往左移动4位就是16.接着就进入了while循环,area和high都是自减1,接着size >>= 1;刚才size为16,现在王右移动1位编程8,用list_add函数将这个8个页框添加到area为3的链表中,更新area为3的nr_free数。同样的道理将其他的4个块添加到area为2的链表中。
下面的set_page_order函数:
static inline void set_page_order(struct page *page, int order)
{
set_page_private(page, order);
__SetPageBuddy(page);
}
设置新添加进去的页框的private值(order值),这个值在每个页框中的第一个页中保存。
5.总结
到这里,伙伴算法的分析已经完毕。感觉内核很神奇,我开始并不是要看伙伴算法的,我只是想看看分配内存的流程,看着看着就看到了alloc_pages,看到这引出了很多不懂的问题,比如什么是区(zone),内核组织内存的方式是什么。看了很多的资料了,在一知半解中继续往下走,一直走到了伙伴算法。以前只是知道原理,现在切实感受了内核的实现。
当然,这远远不够,现在只是看了内存分配页框的流程,那么释放页框的流程又是什么样的呢?这还需要自己去继续研究,go on!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号