Elasticsearch实战一
一、简介
Elasticsearch是一个分布式、可扩展、近实时的高性能搜索和数据分析引擎。基于Java编写,其内部使用Lucene作为索引和搜索。
Elasticsearch提供了搜集、分析、存储数据三大功能,其主要特点有:分布式、零配置、易装易用、自动发现、索引自动分片、索引副本机制、RESTful风格接口、多数据源和自动搜索负载等。
Lucene是一个免费、开源、高性能、纯Java编写的全文检索引擎。主要模块有Analysis模块、Index模块、Store模块、QueryParser模块、Search模块和Similarity模块。
1、数据搜索方式
数据类型有两种类型,即结构化数据和非结构化数据。与数据类型相对应,数据的搜索分为两种,即结构化数据搜索和非结构化数据搜索。
因为结构化数据可以基于关系型数据库存储(支持索引),通过关系型数据进行检索。
非结构化数据主要有顺序扫描(效率低)和全文检索两种方式。
2、搜索引擎工作原理
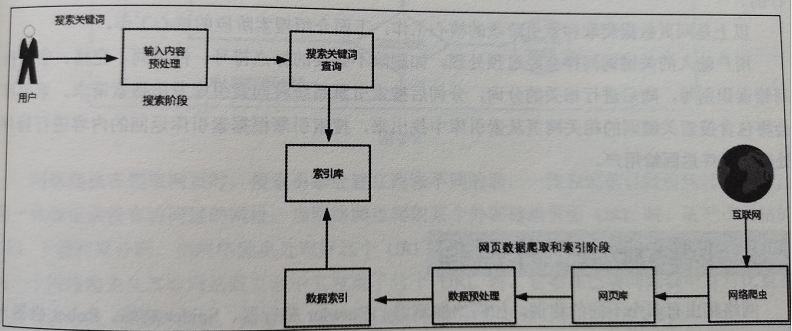
图来自《Elasticsearch实战与原理分析》
数据索引过程先后经历正向索引和倒排索引阶段,最终建立索引库。
3、理解倒排索引
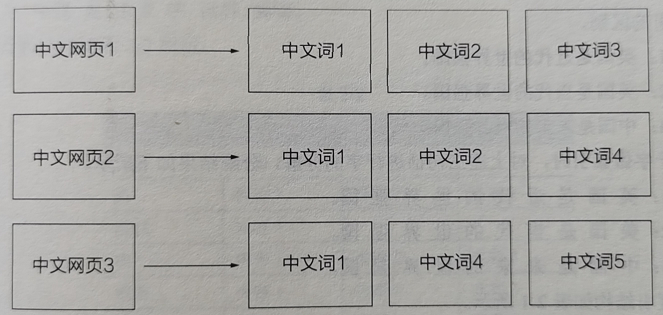
正排索引:以网页或文章映射关系为Key、以分词的列表为Value。
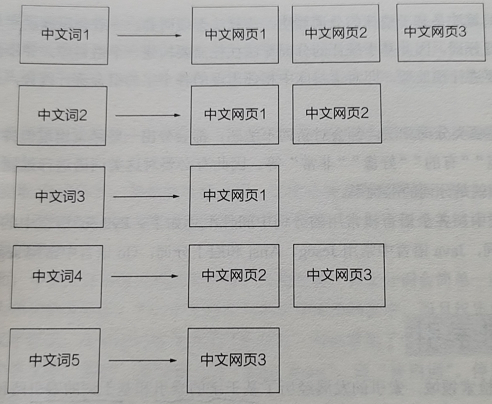
倒排索引:以分词为Key、以网页或文章映射关系为Value。
二、环境搭建
1、下载与启动
版本:elasticsearch-7.2.0-windows-x86_64.zip
启动使用解压后压缩包中有自带的jdk11,修改bin/elasticsearch-env.bat中JAVA_HOME配置。
if defined JAVA_HOME ( rem set JAVA="%JAVA_HOME%\bin\java.exe" set JAVA="%ES_HOME%\jdk\bin\java.exe" ) else ( set JAVA="%ES_HOME%\jdk\bin\java.exe" set JAVA_HOME="%ES_HOME%\jdk" )
解压后目录:
查看帮助命令:-d后台启动
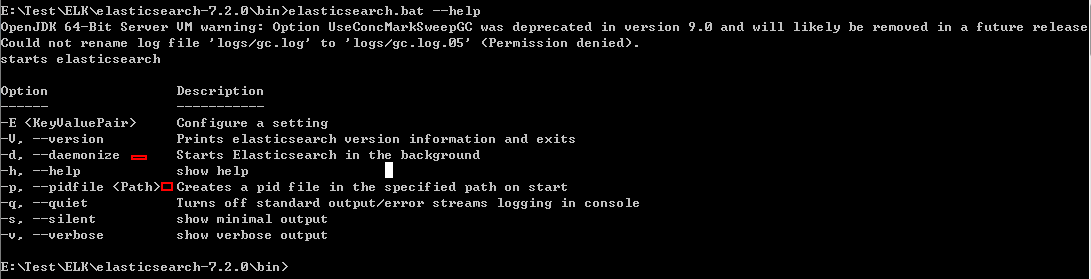
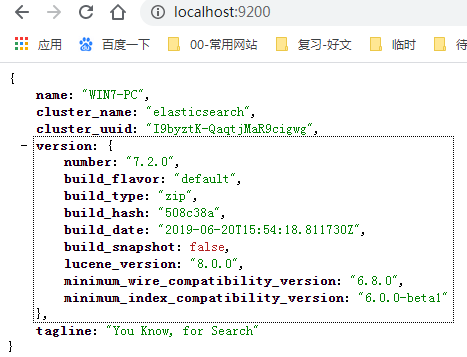
浏览器验证:
2、核心概念
Elasticsearch的核心概念有Node、Cluster、Shards、Replicas、Index、Type、Document、Settings、Mapping和Analyzer。
(1)Node:即节点,组成集群的基本服务单元,节点类型有两种:master(主)节点和data(数据)节点。
(2)Cluster:即集群,同一个集群内节点的名字不能重复,但是集群名称一定要相同。集群中节点状态有三种:Green(健康)、Yellow(预警)、Red(无法使用)。
(3)Shards:即分片(分布式存储)。集群默认为一个索引创建5个主分片,并且为每个主分片创建一个副本。
(4)Replicas:即副本(高可用性)。
(5)Index:即索引。
(6)Type:即类别。
(7)Document:即文档。
(8)Settings:索引的定义信息,包含分片、副本等。
(9)Mapping:索引字段(Field)的存储类型、分词方法、是否存储等信息。
(10)Analyzer:表示字段分词方式的定义。
三、Elasticsearch的架构设计
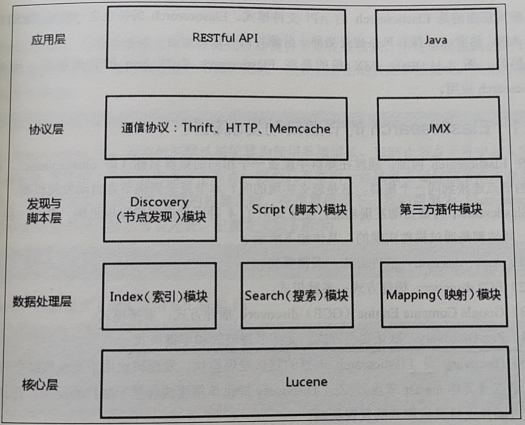
1、节点自动发现机制
Elasticsearch内嵌自动发现功能,主要提供了4种可供选择的发现机制。其中一种是默认实现,其他都是通过插件实现的,具体如下:
(1)Azure discovery插件方式:多播模式。
(2)EC2 discovery插件方式:多播模式。
(3)Google Compute Engine(GCE)discovery插件方式:多播模式。
(4)Zen discovery:默认实现方式,支持单播模式和多播模式(不推荐:大多数操作系统不支持,安全性不高)。
集群构建及主节点选举过程:
(1)节点启动后先执行ping命令(RPC命令),discovery.zen.ping.unicast.hosts配置中ip。ping命令返回结果包含该节点的基本信息及该节点认为的主节点。
(2)选举开始是,主节点现充各节点认为的master节点中选。规则表简单,即按照节点ID(不知道是什么,感觉应该是节点名称)的字典顺序排序,取第一个。
注意:集群主节点存在最小值限制条件,discovery.zen.ping.minimum_master控制。未达到数量要求,循环上述(2)步骤。
2、分片和路由
对文档的新建、索引和删除请求等操作,必须在主分片上完成之后才能被复制到相关的副本分配。
索引数据路由到分片算法:shard_num=hash(routing) % num_primary_shards。
routing字段的取值默认是id字段或者parent字段。
3、数据写入过程
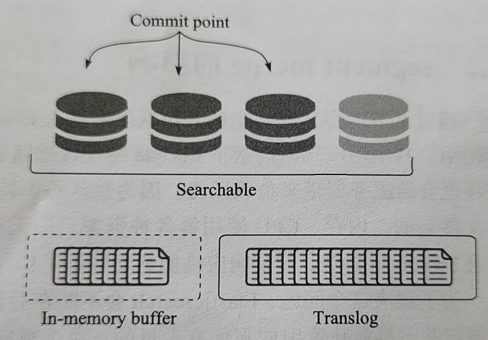
图来自《ELK Stack权威指南》
(1)内存和translog
写入数据生成倒排索引segment(分段),进入内存buffer;
同时记录translog文件。()
(2)磁盘缓存
内存buffer生成新的segment分段,刷到文件系统缓存中(默认设置为1秒间隔,也提供_refresh接口)。
(3)分段存储
segment(分段)写入磁盘,commit文件更新记录;清空translog文件(默认设置:30分钟或当translog文件大于512M,也提供_flush接口)。
4、分段合并


 浙公网安备 33010602011771号
浙公网安备 33010602011771号