性能测试工具loadrunner的使用
最近学了下loadrunner的基操,特此小记一下以防遗忘。
1、代理录制
看到辣鸡IE浏览器就烦,想用Chrome浏览器来录制脚本,遂选择代理录制模式。
在录制设置里面的代理设置中新增一个代理,输入目标IP,端口,协议类型,以及loadrunner的端口如8888;
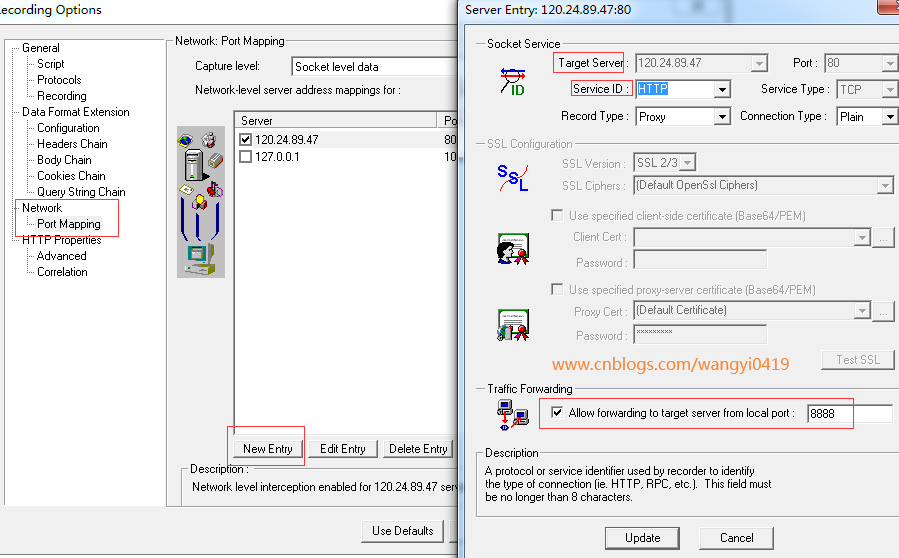
然后在chrome浏览器里设置好代理,127.0.0.1 8888;
录制时在Application type中选择默认,据我测试,选win32结果一样;
录制的项目里选择LD的bin目录下的wplus_init_wsock,点击OK开始录制。
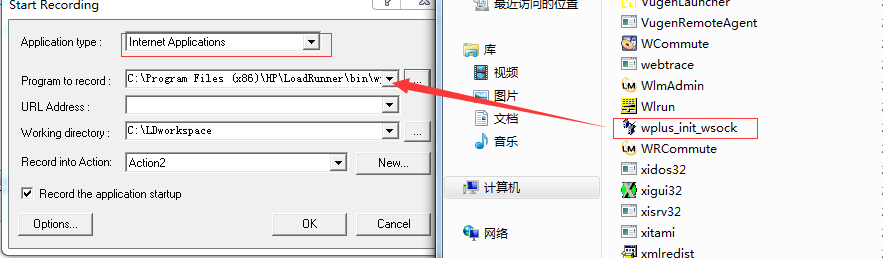
一开始我用Chrome浏览器访问网页时录制没脚本,后来将谷歌浏览器设置为默认浏览器后有了脚本。

2、Recording Options 录制选项
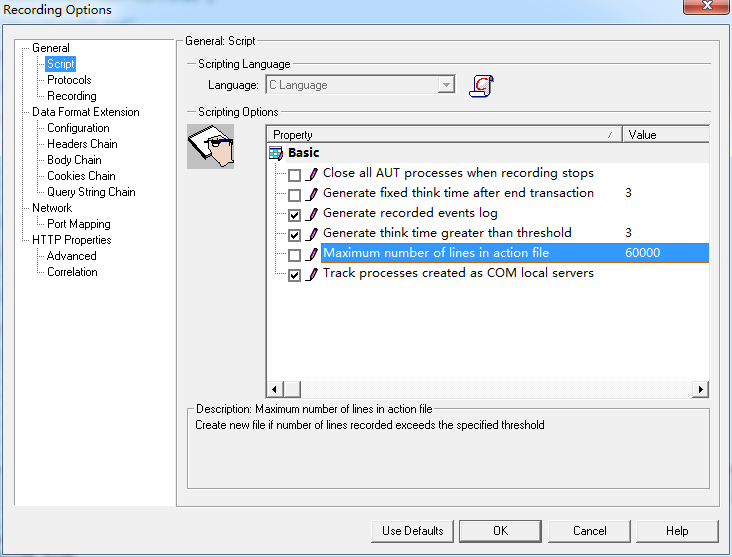
Script
Scripting Options
1.当VuGen停止录制时,自动关闭所有活动的应用程序进程
Close all AUT processes when recording stops
2.在每个事务结束后都生成一个固定的思考时间
Generate fixed think time after end transaction
3.描述所有捕获的事件并生成报告
Generate recorded events log
4.如果用户超过指定的界限,那么插入用户思考时间
Generate think time greater than threshold
5.如果一个action录制的行数超过指定的界限,那么创建一个新的文件
Maximum number of lines in action file
6.如果录制的一个应用程序的子进程创建为一个COM本地服务器,追踪它的活动
Track processes created as COM local servers
Protocols
协议列表,在这里列出录制前所选的协议,图为Web的HTTP协议。
Recording
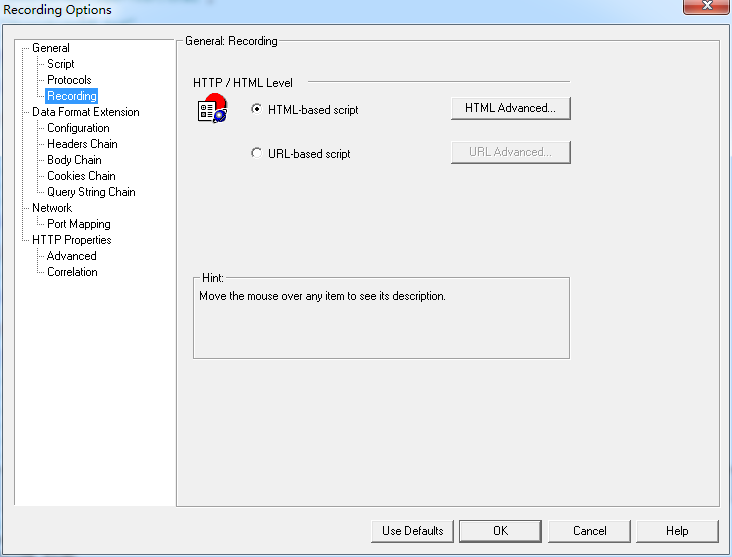
有两种录制模式,基于HTML的和基于URL的,以打开百度首页为例,来对比一下:
1、HTML-based script:这种方式录制的代码只生成了两个打开页面的函数,比较简洁。
Base_html() { web_add_cookie("BAIDUID=5CA75D7E4804139ED1381595FE964220:FG=1; DOMAIN=www.baidu.com"); web_add_cookie("BIDUPSID=5CA75D7E4804139EE3924BB8D7130653; DOMAIN=www.baidu.com"); web_add_cookie("PSTM=1580452306; DOMAIN=www.baidu.com"); web_url("www.baidu.com", "URL=http://www.baidu.com/", "TargetFrame=", "Resource=0", "RecContentType=text/html", "Referer=", "Snapshot=t65.inf", "Mode=HTML", LAST); web_url("百度首页", "URL=https://www.baidu.com/", "TargetFrame=", "Resource=0", "RecContentType=text/html", "Referer=", "Snapshot=t66.inf", "Mode=HTML", LAST); return 0; }
2、URL-based script:这种方式会生成很多函数,它将每个请求都单独成一个函数,这种方式更接近请求-响应的本质。
Base_url() { web_add_cookie("BAIDUID=5CA75D7E4804139ED1381595FE964220:FG=1; DOMAIN=www.baidu.com"); web_add_cookie("BIDUPSID=5CA75D7E4804139EE3924BB8D7130653; DOMAIN=www.baidu.com"); web_add_cookie("PSTM=1580452306; DOMAIN=www.baidu.com"); web_url("www.baidu.com", "URL=http://www.baidu.com/", "Resource=0", "RecContentType=text/html", "Referer=", "Snapshot=t67.inf", "Mode=HTTP", LAST); web_url("百度首页", "URL=https://www.baidu.com/", "Resource=0", "RecContentType=text/html", "Referer=", "Snapshot=t68.inf", "Mode=HTTP", LAST); web_concurrent_start(NULL); web_url("pcpad_e247c0f9a461b6394da20e308588818f.png", "URL=https://www.baidu.com/img/pcpad_e247c0f9a461b6394da20e308588818f.png", "Resource=1", "RecContentType=image/png", "Referer=https://www.baidu.com/", "Snapshot=t69.inf", LAST); web_url("baidu_jgylogo3.gif", "URL=https://www.baidu.com/img/baidu_jgylogo3.gif", "Resource=1", "RecContentType=image/gif", "Referer=https://www.baidu.com/", "Snapshot=t70.inf", LAST); web_url("pcpad_e247c0f9a461b6394da20e308588818f.png_2", "URL=https://www.baidu.com/img/pcpad_e247c0f9a461b6394da20e308588818f.png", "Resource=1", "RecContentType=image/png", "Referer=https://www.baidu.com/", "Snapshot=t71.inf", LAST); web_url("baidu_resultlogo@2.png", "URL=https://www.baidu.com/img/baidu_resultlogo@2.png", "Resource=1", "RecContentType=image/png", "Referer=https://www.baidu.com/", "Snapshot=t73.inf", LAST); web_concurrent_end(NULL); web_url("baidu_jgylogo3.gif_2", "URL=https://www.baidu.com/img/baidu_jgylogo3.gif", "Resource=1", "RecContentType=image/gif", "Referer=https://www.baidu.com/", "Snapshot=t72.inf", LAST); web_url("baidu_resultlogo@2.png_2", "URL=https://www.baidu.com/img/baidu_resultlogo@2.png", "Resource=1", "RecContentType=image/png", "Referer=https://www.baidu.com/", "Snapshot=t74.inf", LAST); return 0; }
注意:
基于浏览器的应用程序推荐使用HTML-based Script;
不是基于浏览器的应用程序推荐使用URL-based Script;
如果基于浏览器的应用程序中包含了JavaScript 并且该脚本向服务器产生了请求,比如DataGrid 的分页按钮等,flash等,也要使用URL-based 方式录制;
基于浏览器的应用程序中使用了HTTPS 安全协议,使用URL-based 方式录制。
在HTML下面也有两个选项:
1、A script. describing user actions(web_link,web_submit_form)
基于解释用户行为的脚本,注重描述用户做了什么操作,脚本简洁,基于用户操作模拟,浅显易懂,并且自身就包含了对象检查过程,无需校验;
2、A script. containing explicit URLs only(web_url,web_submit_data)
基于URL请求的脚本录制类型,这种方式不考虑用户的操作,只考虑客户端发送的请求,注重于实际上系统做了什么。
以系统给的购票网站为例:
第一种在注释掉第一个web_url函数之后,web_submit_form是无法登录成功的,里面没有地址。

第二种即使注释掉web_url函数,web_submit_data依旧可以登录,里面有登录的地址。

总结:
web_submit_form: 上下文相关的,依赖上下文才能提交,比较符合人们的操作习惯。
web_submit_data: 上下文不相关,每个函数都指定了具体的url地址,可以直接提交成功,如果只关注协议,不需要关注页面,可使用这种方式录制。
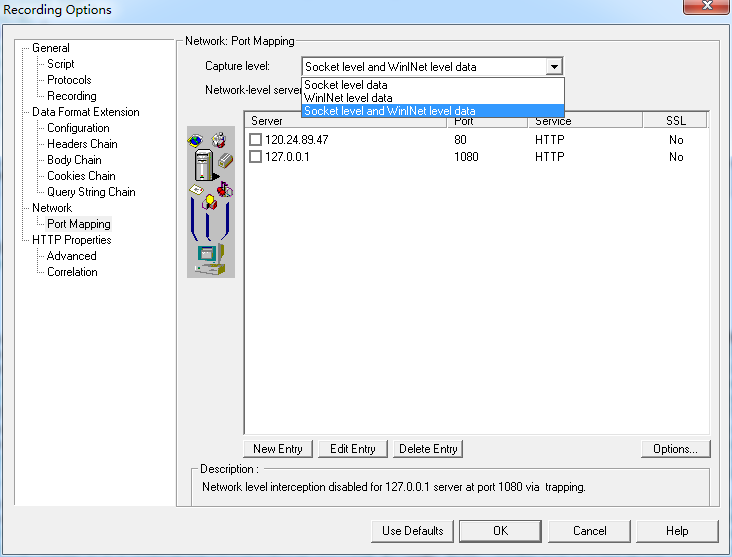
Port Mapping
这里面是设置代理的,上面有涉及。但是有个Capture level选项:
- Socket level data. Capture data using trapping on the socket level only. Port mappings apply in this case (default).
- WinINet level data. Capture data using hooks on the WinINet.dll API used by certain HTTP applications. The most common application that uses these hooks is Internet Explorer. Port mappings are not relevant for this level.
- Socket level and WinINet level data. Captures data using both mechanisms. WinINet level sends information for applications that use WinINet.dll. Socket level sends data only if it determines that it did not originate from WinINet.dll. Port mapping applies to data that did not originate from WinINet.dll.
对这几个的区别我不太理解,有时用socket录制脚本时没有内容的话换第二个或第三个就有了。
Advanced
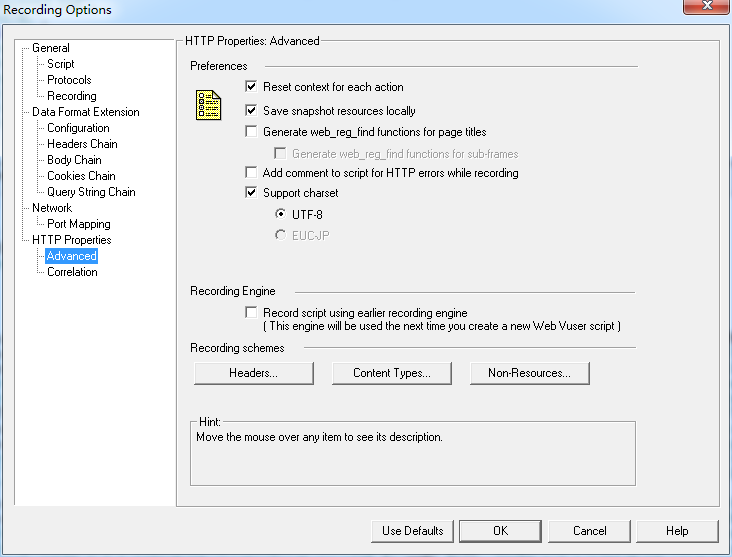
Reset context for each action:录制过程中每个action之间是否需要重置context,context中存放请求发送返回后的数据信息,比如服务器返回的html,cookie,session等。
Save snapshot resources locally:在本地保存快照
Generate web_reg_find functions for page titles:是否需要自动为每个标题生成web_reg_find检查点函数
Generate web_rege_find functions for sub-frames:为子框架也生成检查点函数
Add comment to script. for HTTP errors while recording:录制过程中出错了添加相关的注释内容
Support charset:编码规则选项,建议选上,解决中文乱码情况
Recording Engine:录制的兼容性选项,可以使用以前的录制引擎来录制脚本
Recording schemes:录制内容的过滤
Headers:对于Headers录制内容的过滤
Content Types:对于录制的正文内容进行过滤
Non-Resource:对于非资源的内容进行过滤
Correlation
关联,勾上Enable就自动关联了。
3、Run time setting运行时设置
Run Logic:
在loadrunner的vugen中,action是可以被迭代的,在init和end中也可以插入action,在action中也可以插入块Block,块中加入action。
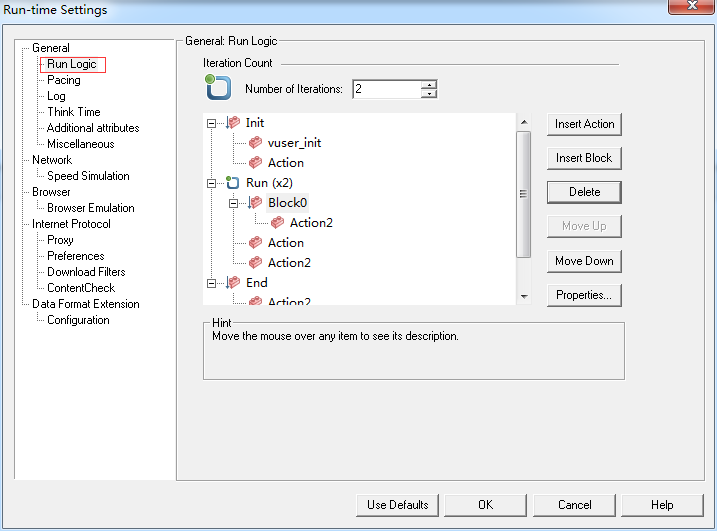
在Properties属性栏里可以改变Run和Block里的action的执行方式,顺序或者指定概率,也可直接双击Run或Block或action。

我们跑出的脚本中的行为方式如果跟用户实际的行为方式不一致,那么基于这个脚本的性能测试的结果将是毫无意义的。比如说某个论坛,我们录的脚本是登录论坛首页,然后去发个帖,然后退出。而实际上用户的使用行为可能并非如此,用户可能登录论坛后先看看自己的个人中心,看看是否有关于自己的动态,再去查看置顶的热门帖子,再去搜搜自己感兴趣的某些内容,然后再发个帖子,最后退出。这就要在LD的运行时设置里面构造运行逻辑了。虽然Properties属性可以构造一些简单的运行逻辑,但是复杂些的还是要靠c语言代码直接实行。
例如下面的逻辑,访问京东首页后有的人会是第一次访问,先去注册;
有的老客户先去登录,再去查找商品,添加购物车,支付;
有的人在没登录的情况下先去查找浏览,找到满意的商品后再去登录,添加购物车,支付。
用c先产生一个1-100之间的随机数,然后根据随机数的大小实现概率性的逻辑运行。
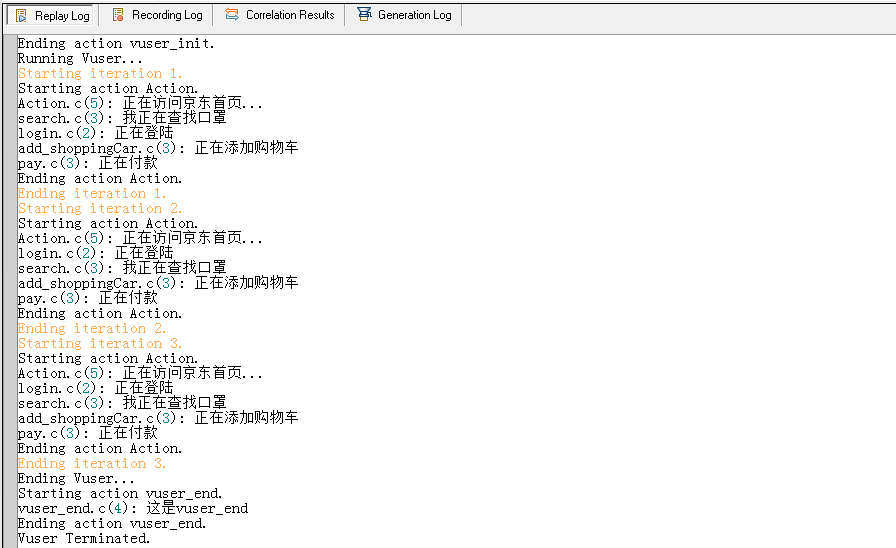
脚本如下:

运行结果:
Pacing:

Pacing,定义的是两个迭代之间的步长。有三个模式:
1、前面的迭代一结束后面的迭代就开始;
2、在前面的迭代结束后,等待一个固定的或者随机的时间延迟,才开始新的迭代;
3、是指前一次Starting Iteration到下一次Starting Iteration之间的时间,包含了前一次迭代执行的时间。在该模式下,一次迭代执行的时间若大Pacing的时间,则系统会提示无法达到Pacing的时间设置,脚本不做等待立即运行下一次迭代,可以用来验证下一次迭代的处理时间是否在期望的阀值内。
可以看出第一种选择对服务器的压力最大,因为这个选项在单位时间内所做的业务数最多,即单位时间内提交的请求数最多,所以服务器的压力最大。因此如果进行压力测试时,可以需要该选项。
补充:
性能需求经常都是这样定义的: “要求系统支持 100 个并发用户”。换个角度,“要求系统的事务处理能力达到 100 个 / 秒” ( 这里为了理解的方便,假定在测试脚本中的一个事务仅仅包含一次请求 ),面对以这样方式提出的性能需求,在 LoadRunner 中,我们又该如何去设置它的并发用户数呢?千万不要想当然地以为设置了 100 个并发用户数,它就会每秒向服务器提交 100 个请求(只限于1次迭代),这是两个不同的概念,因为 LoadRunner 模拟客户端向服务器发出请求,必须等待服务器对这个请求做出响应,并且客户端收到这个响应之后,才会重新发出新的请求,而服务器对请求的处理是需要一个时间的。我们换个说法,对于每个虚拟用户来说,它对服务器发出请求的频率将依赖于服务器对这个请求的处理时间。而服务器对请求的处理时间是不可控的,如果我们想要在测试过程中维持一个稳定的每秒请求数( RPS ),只有一个方法,那就是通过增加并发用户数的数量来达到这个目的。这个方法看起来似乎没有什么问题,如果我们在测试场景中只执行一次迭代的话。然而有经验的朋友都会知道,实际情况并不是这样,我们通常会对场景设置一个持续运行时间(duration,即多次迭代),通过多个事务 (transaction) 的取样平均值来保证测试结果的准确性。测试场景以迭代的方式进行,如果不设置步进值的话,那么对于每个虚拟用户来说,每一个发到服务器的请求得到响应之后,会马上发送下一次请求。同时,我们知道, LoadRunner 是以客户端的角度来定义“响应时间”的 ,当客户端请求发出去后, LoadRunner 就开始计算响应时间,一直到它收到服务器端的响应。这个时候问题就产生了:如果此时的服务器端的排队队列已满,服务器资源正处于忙碌的状态,那么该请求会驻留在服务器的线程中,换句话说,这个新产生的请求并不会对服务器端产生真正的负载,但很遗憾的是,该请求的计时器已经启动了,因此我们很容易就可以预见到,这个请求的响应时间会变得很长,甚至可能长到使得该请求由于超时而失败。等到测试结束后,我们查看一下结果,就会发现这样一个很不幸的现象:事务平均响应时间很长,最小响应时间与最大响应时间的差距很大,而这个时候的平均响应时间,其实也就失去了它应有的意义。也就是说,由于客户端发送的请求太快而导致影响了实际的测量结果。因此,为了解决这个问题,我们可以在每两个请求之间插入一个间隔时间,这将会降低单个用户启动请求的速度。间歇会减少请求在线程中驻留的时间,从而提供更符合现实的响应时间。这就是 Pacing 这个值的作用。
Log:
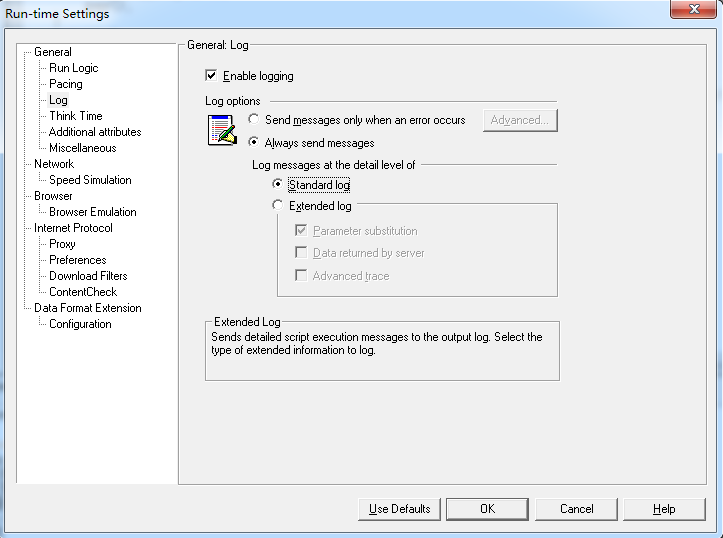
主要用于设置脚本回放时的日志格式。LR一共包括4类日志文件,即
replay log(回放日志):是脚本回放时lr记录的日志信息,包括客户端与服务器之间的通信日志和HTML源码录制时的快照信息,但该日志信息的内容取决于log选项卡中extended log选项的设置情况。
recording log(录制日志):是录制脚本时产生的日志,主要是客户端和服务器端通信时的一些交互信息。
correlation results(关联结果):是当脚本需要关联时,在回放脚本过程中会记录录制和回放时需要关联内容的值。
generation log(生成日志):脚本生成时产生的日志。
Enable Logging:是否启动日志功能 ,即在场景运行过程中是否收集日志信息。
Log message at the detail level of 日志的详细内容:
Additional attributes:
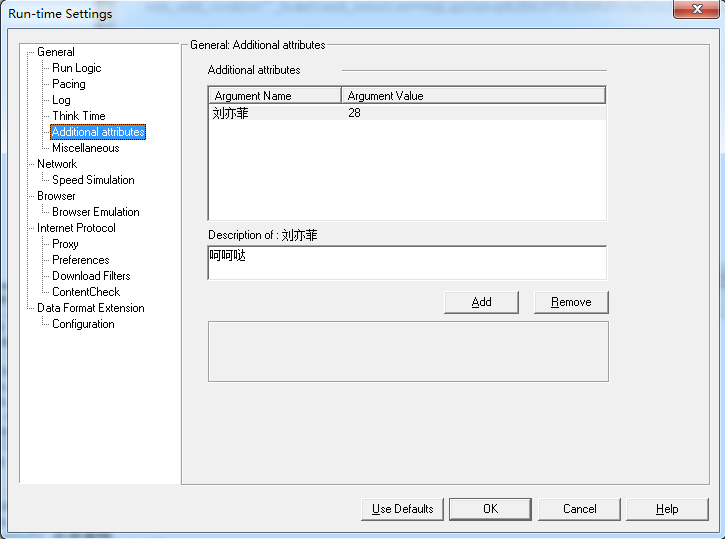
添加一些不是系统本来就有的属性参数,可以获得不同客户端的值。
Think Time:
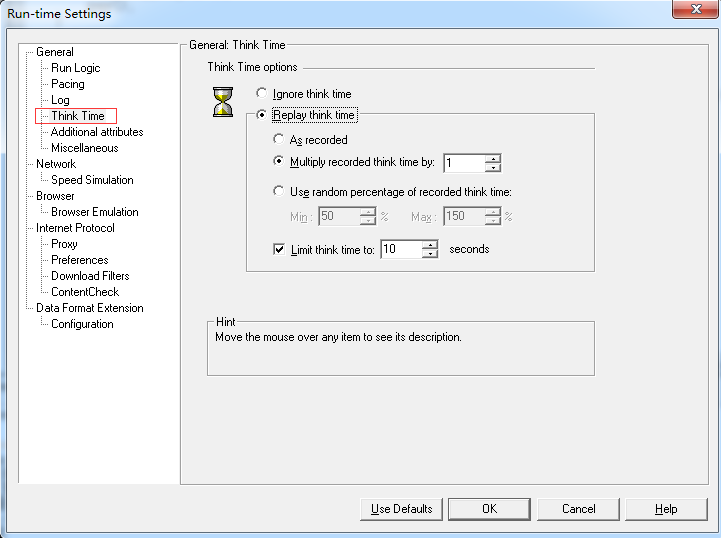
用来设置用户操作的思考时间(思考时间是指每个HTTP请求之间的时间间隔)
ignore think time:运行脚本时忽略思考时间,即上一个HTTP请求结束后,直接运行下一下HTTP请求,不等待。
replay think time:设置脚本回放时思考时间,包括as recorded、multiply record think time by 和use random percentage of recorded think time三种方式。
as recorded:按录制时的思考时间来回放,即如果录制时间思考时间为9s,那么回放时也按9s来计算(如图6所示):
multiply record think time by :根据录制时思考时间的整数倍来运行(如图7所示):
use random percentage of recorded think time:分别设置一个最大值和一个最小值,并从中选出一个随机值,在实际使用过程中一般会选择这种模式,设置最小值为50%,最大值为150%(如图8):
limit think time to:设置think time的最大值。如果上面的设置项,在回放时使用的思考时间超过所限制的时间,那么以该限制时间为准进行回放(如图9所示):
综合上面的情况,设置为忽略思考时间时,对服务器的压力最大,因为在同样的场景执行时间内,HTTP请求之间的时间缩短说明向服务器提交的请求数增多了,所以服务器的压力增加,如果进行压力测试时,可以选择该项设置。
思考时间的设置,多大为宜?
抽样,获取100个人的think time 时间分布,去掉最高值和最低值,对留下的80%核心数据做平均,比如得到的结果是3.8,那么取比3.8小一些的数据来作为脚本的思考时间,如3.5。思考时间越小则在某种程度上对服务器造成的压力就越大,测试时大的压力都扛得住,那么生产环境里的实际压力也应该没问题。但也不能过小,如2.5。过压也没有意义,浪费资源浪费钱。
Miscellaneous混合项:
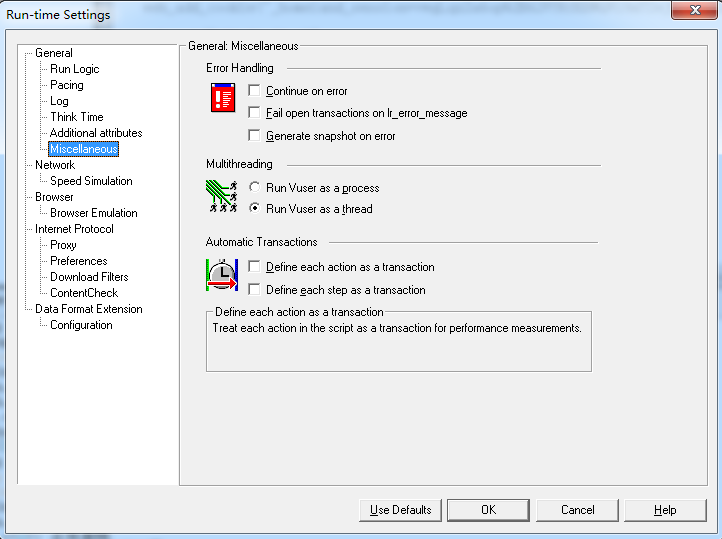
是一个混合项,包括3个设置项:
Error Handing (表示脚本运行出现错误时所采取的措施,默认使用缺省值):
continue on error:即使遇到错误也继续执行脚本.
Fail open transactions on lr_error_message: 当lr_error_message这个函数被transaction内部的脚本调用的时候,无法打开所有的transaction
Generate snapshot on error:当遇到error的时候就自动产生快照.
Multithreading (表示运行时把虚拟用户当作进程还是线程来处理):
Automatic Transactions(设置事务的模式):
Speed Simulation 带宽模拟 :
Browser Emulation浏览器仿真:
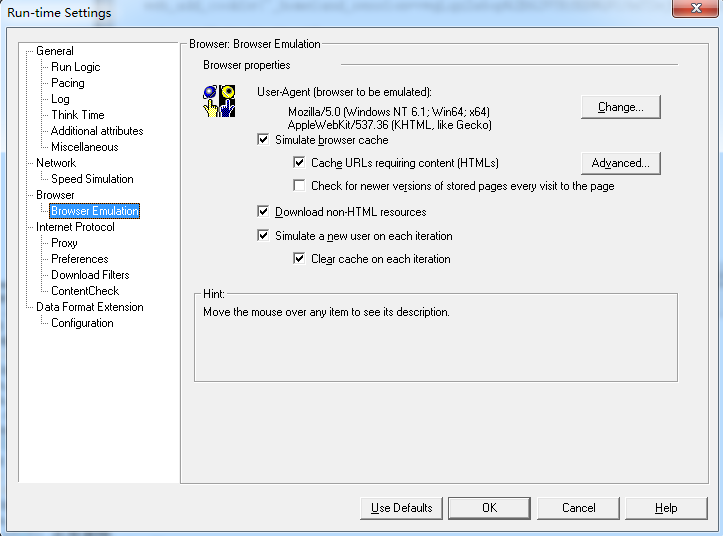
User-Agent中默认是win7的内核。可以更改。
Simulate browser cache:配置Vuser模拟带缓存的浏览器。缺省缓存是被允许的,可以通过禁止该选项来使得所有VUser模拟的浏览器都不带缓存。
Cache URLs requiring content(HTMLs):设置浏览器缓存URL的上下文(比如,HTML语法,认证或校验等),其他的URL的上下文不会被缓存,以减少内存使用。可以通过点击Advance来定义需要上下文的URLs。
Check for newer versions of stored pages every visit to the page:通过在header中添加If-Modified-Sinces属性来设置浏览器检查缓存中的资源是否是最新的页面资源。缺省情况下,浏览器不会自动检测。
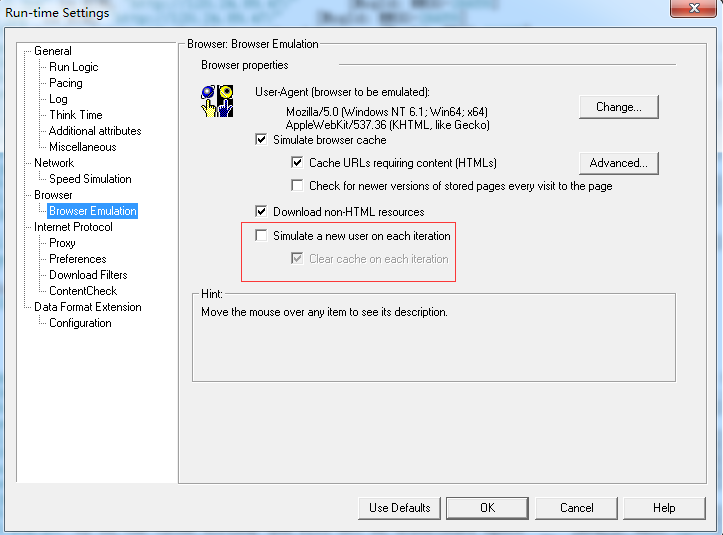
Simulate a new user on each iteraton:设置VuGen在每个迭代的init会话结束时,删除所有的cookie。这样使得Vuse更加真实的模拟一个新user开始一个浏览会话。迭代的过程是指一个操作的完整流程,新的一次迭代就是一个新的用户在新的电脑上重新做一次业务。
Clear cache on each iteration:迭代后清空缓存。当每次迭代模拟一个最新访问站点的user时,则要选中该选项。当每一个迭代模拟一个最近访问过站点的user,浏览器仍为该用户保留网页(从前面的迭代中使用缓存页面)的情况则不要选中该选项。
例如,访问如下网页两次,因为有缓存,第二次很多东西就不下载了,直接在缓存里面取:

回放日志:

关闭缓存后,所有页面上的资源都要下载两次:


迭代缓存关闭:
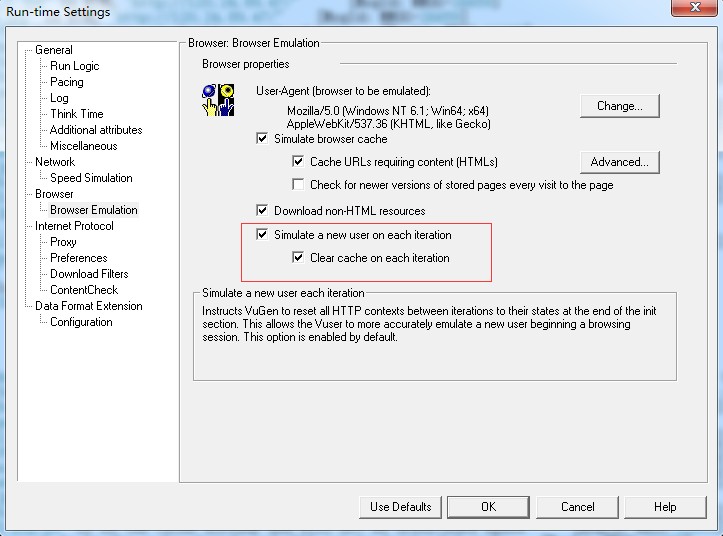

迭代缓存开启:

问题:登录和退出是放在init和end里面还是run里面呢?
假如对应的是在京东买东西的业务,登录和退出放在init和end里面多次迭代加上100个并发,则100个人同时在京东上买买买,买完电视买冰箱,买完冰箱买空调,然后退出。若放在run里面,每个用户买完电视后退出再登录买冰箱再退出登录买空调,有这种情况吗?难道是帮别人买?所以我觉得还是要放在init和end里面。
Proxy代理:
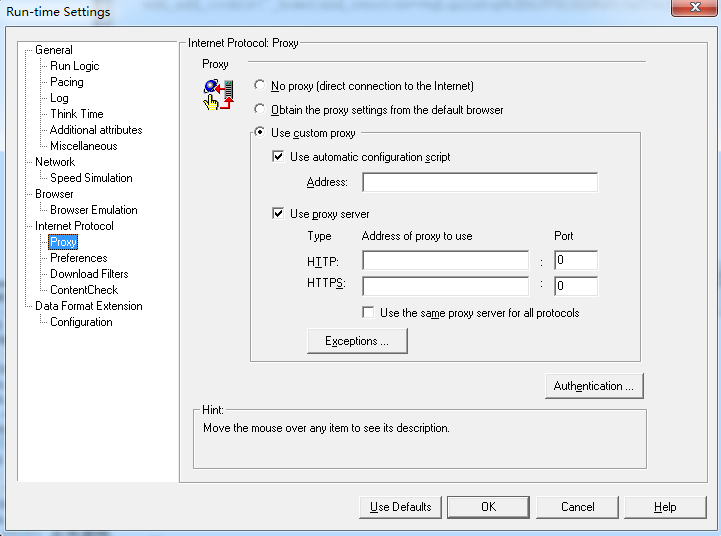
No proxy(direct connection to the Internet):所有的Vusers不使用代理,直接方式连接到互联网。
Obtain the proxy setting from the default browser:所有的Vusers使用机器上运行的浏览器的缺省代理设置。该选项为缺省选项。
Use custom proxy:所有Vusers使用自己设置的代理方式连接到互联网。
Preferences首选项:
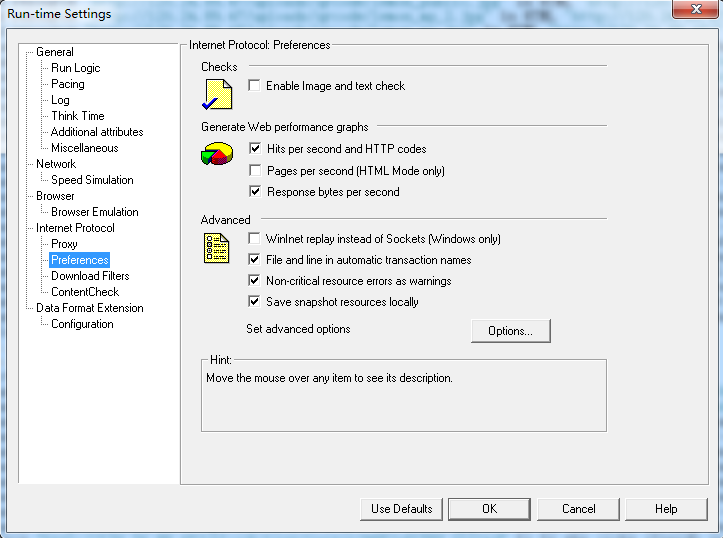
Enable Image and text check:允许Vuser执行期间通过执行web_find和web_image_check函数来做检查。该选项仅适用于Html类型的脚本。另外,使用该选项会使用更多的内存。因此,系统默认该项是不选的。
Hits Per Second and HTTP Codes:该选项用来显示每秒点击率以及每秒HTTP相应图。选中后,可以在场景运行的时候动态看到该图,也可以在Analysis分析中看到该图。
Pages Per Second(Html Mode Only):选择该项后,可以产生每秒页面图,可以在场景运行或者在Analysisi中看到该图。
Response Byte per Second:选择该项后,可以产生每秒接收字节图,可以在场景运行或者在Analysisi中看到该图。
Winlnet Replay Instead of Sockets(Windows only):仅仅用于Windows操作系统,选中该项后,使用Wininet Replay 引擎。注意:该选项在Socket Replay引擎失败后才可以使用。
File and Line in Automatic Transcation names:用文件名和行号给自动化的Transction命名,该选项默认是选中的,注意该项选中会使用更多的内存。
Non-critical Resource Errors As Warnings:当非关键性的Fail发生时返回Warning。例如:页面非关键的图片没有显示,或者某个非关键的JavaScript没有运行。该选项默认是选中的。
Save Snapshot Resources Locally:本地保存场景的运行状况。该选项可以使用户更快更精确的看到场景运行状况。
Options:

响应超时也没必要改这个时间,没意义:

其他的一些东西没必要动它。
DNS Catching:保存DNS的IP地址。
Http Version:表明你的程序使用的Http版本。
Keep Alive Http Connections:允许长期保存Http连接,这样可以使多个需求通过相同的TCP连接。
Step Timeout Caused by Resources is a Warning:对于资源申请超时发布Warning而不是Error。
Parse HTMLContent-Type:对于HTML,当反馈内容是text/html(HTML),’text/’(TEXT)或者Content-type(ANY)时才进行解析。注意:text/xml不会被解析为XML类型。
Accept Server-Side Compression: 表明回放的时候Server端可以接收压缩数据的情况。注意,接收压缩数据会引起额外的开销。
Accept-Language request header: 可以接受语言,以逗号分隔。
HTTP –Request Connect Timeout(Sec):对HTTP要求的连接操作时间限制,或者连接失败的时间限制。
HTTP –Request Receive Timeout(Sec):对HTTP要求的接收时间限制,或者失败时间限制。
Step download timeout(sec):一个完成的Script功能的完成时间限制,或者失败时间限制。
Network buffet size:Vuser可以使用的最大网络buffer大小,默认为12288。
Fixed think time upop authentication retry(mesc):模仿用户输入用户名和密码的时间。注意,这个作为事务时间的一部分。
Request Zlib Headers:当送到Server的需求数据是压缩的时,包含Zlib压缩库的头部。
Max Number of <META Refresh> to the same page:同一个页面可以打开的个数。
GUI-Mode default block size for DOM memory allocations:默认的DOM Blocak内存分配大小,太小会出现一些额外的内存调用失败以及操作,太大会造成内存浪费。
GUI-Mode single setTimeout/setInterval thresh hold:超过了SetTimeout设置的值,SetInterval的设置无效。该设置模拟了用户在等待超过一定时间后会点击下一个元素。
GUI-Mode Accumulative setTimeout/setInterval threshold:超过了SetTimeout设置的值,忽略SetInterval。
GUI-Mode fail on javascript error:对于Javacript的错误,如果选择Yes,提交一个Fail;如果选择No,提交一个Warning。
GUI-Mode History Support:是否支持历史记录。如果选择Auto,则仅仅记录第一次循环的情况。
GUI-Mode Maximum history size:最到可以保存在历史记录中的步骤。
Download Filters:
如果选择Include Only Addresses In List, 表示重放只能限制在列出的WebSite或者是hosts中。
Exclude Address in lists:重放地址要排除列出的Website或者是hosts。 有些页面中存在一些响应时间很长的链接如外网的,可以把它过滤掉。

ContentCheck:
Enable ContentCheck During Replay:选择该项可以是用户得到Web Server发送回的Error。

4、参数化
单参
假设一个dat文件中有多列值,Select column中设置取值的标识:
by number是按第一列、第二列、第三列的方式取列值;
by name是按列名取值。
File format中column定义分列方式,是按逗号,tab还是空格;First data定义取值从列表的第几行开始取值,默认是第一行。
与参数取值方式相关的设置有两个:
1、Select next row:
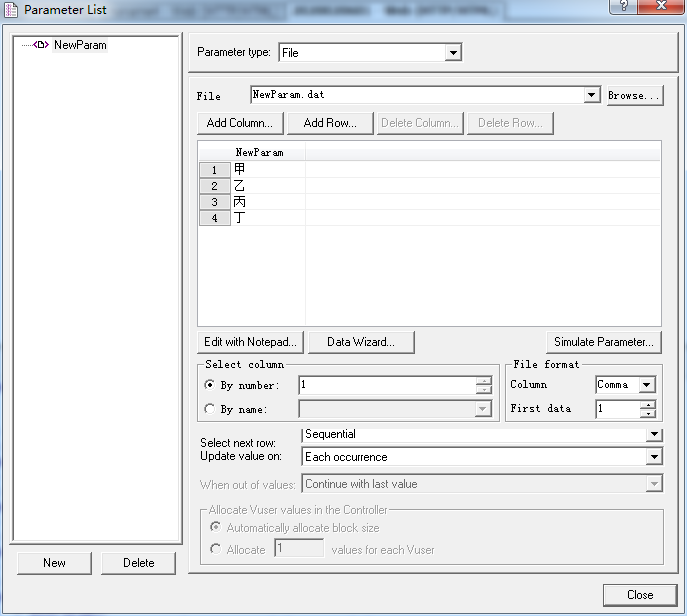
(1)Sequential:按照顺序一行行的读取。每一个虚拟用户都会按照相同的顺序读取;
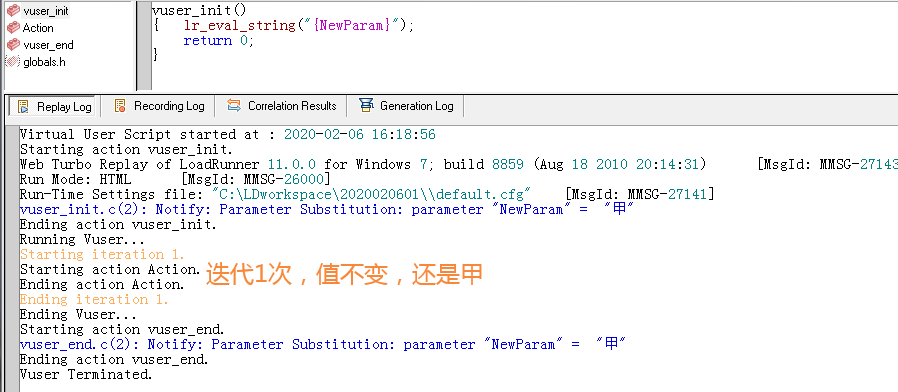
(2)Random:在每次迭代里随机的读取一个,但是在迭代中一直保持不变;
(3)Unique :每个VU取唯一的值。
2、Update value on:
(1)once :在所有的反复中都使用同一个值;
(2)eachiteration :每次反复都要取新值;
(3)eachoccurrence :则只要发现该参数就要重新取值,即如果一个action中有多个该参数,每遇到一个就要重新取一个值。
组合方式如下:
Sequential + Each iteration:每迭代一次取一行值;当所有的值取完后,再从第一行开始取。
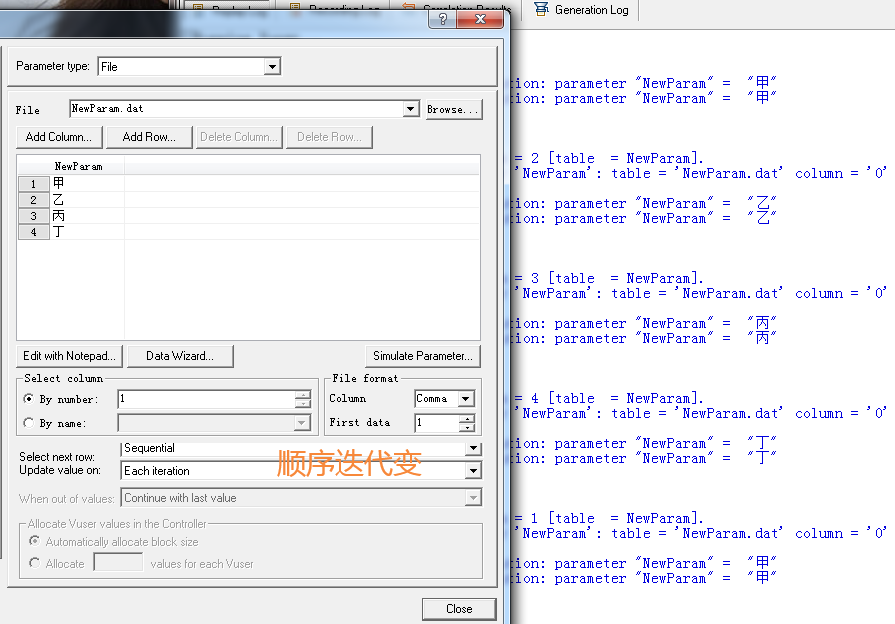
Sequential + Each occurrence:每调用一次取一行值;当所有的值取完后,再从第一行开始取。
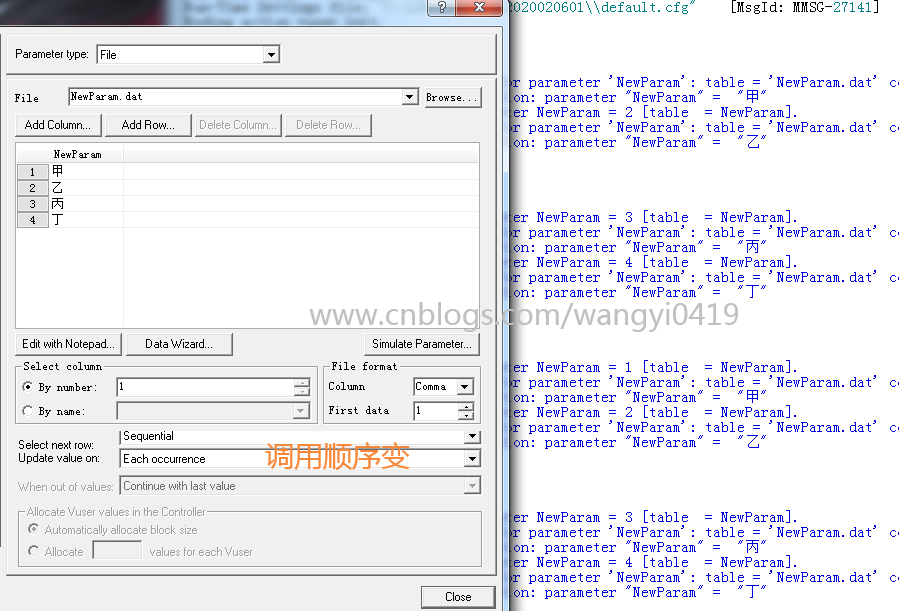
Sequential + once:每次调用都是同一个值,即设置的第一个取值。

Random+Each iteration:每次迭代随机选择一行数据进行赋值。
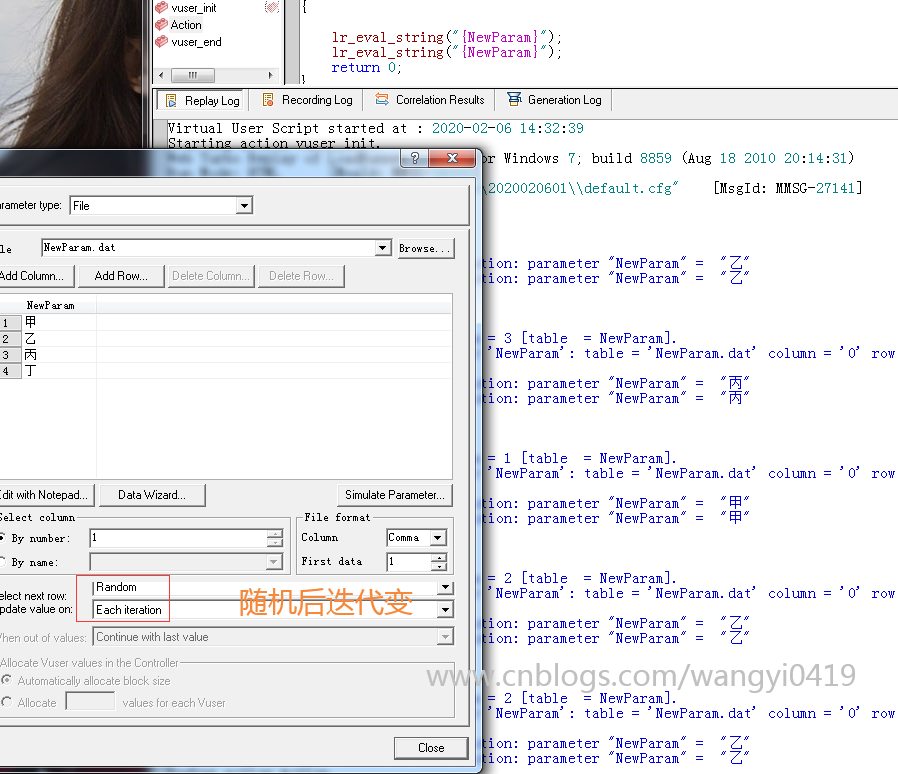
Random + Each occurrence:每次调用随机选择一行数据进行赋值。

Random + once:第一次迭代时随机取一行数据,后面每次都用第一次的数据。
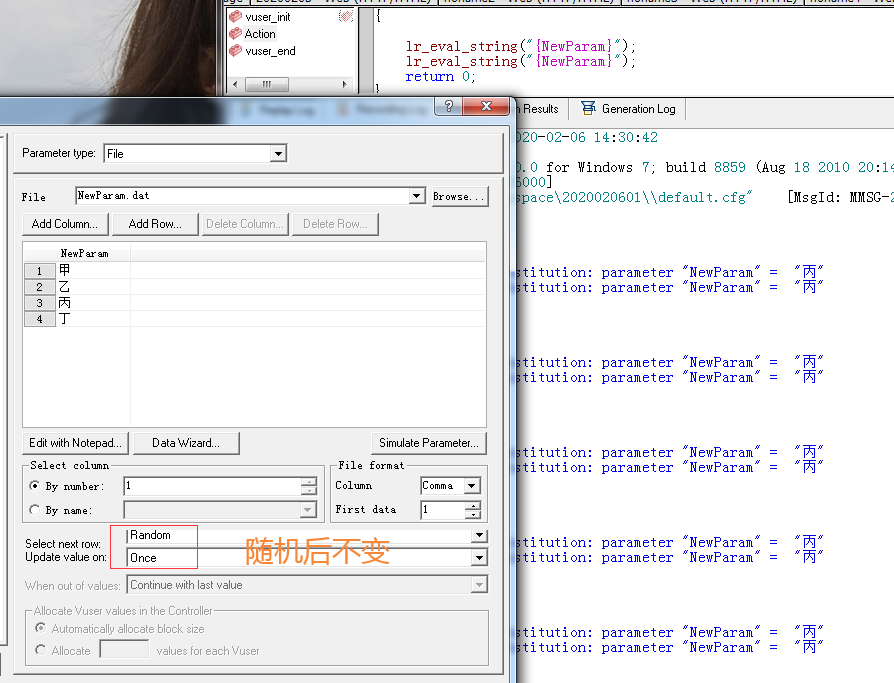
问题:
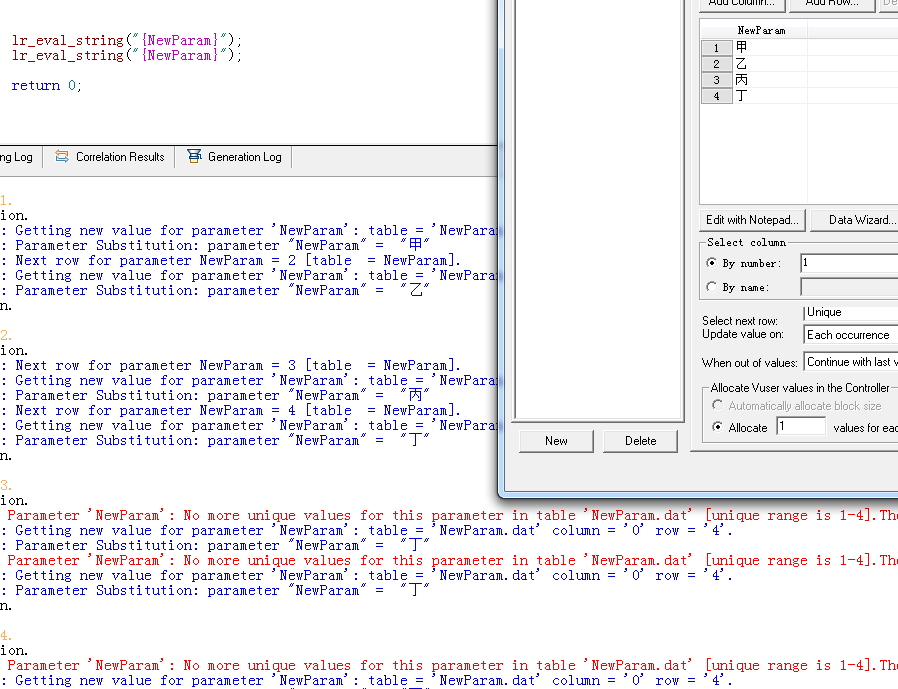
1、把lr_eval_string函数放在init和end里面,action里面为空,迭代一次的最后取值是多少?
2、脚本加for循环,迭代里嵌套块,参数属性里选择顺序和每次调用,则最后一次取值是多少?

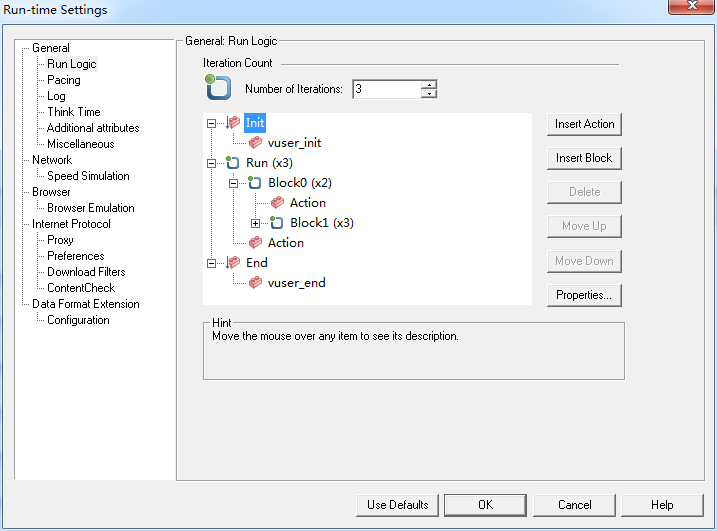
不用多想,是丁,被4整除啦!
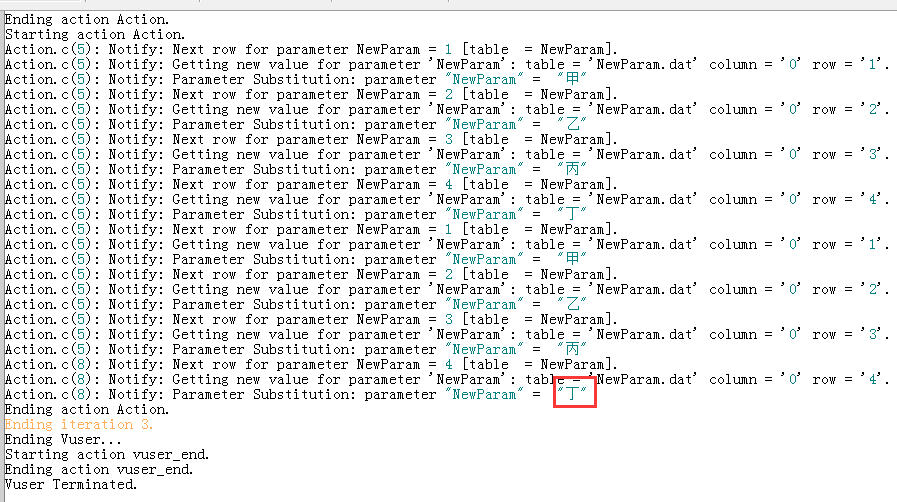
现在来个最简单的情况,放在场景里面跑,10个虚拟用户,运行模式换成basic:


10个pass,打开log,十个日志,每个里面都是甲乙丙丁甲:
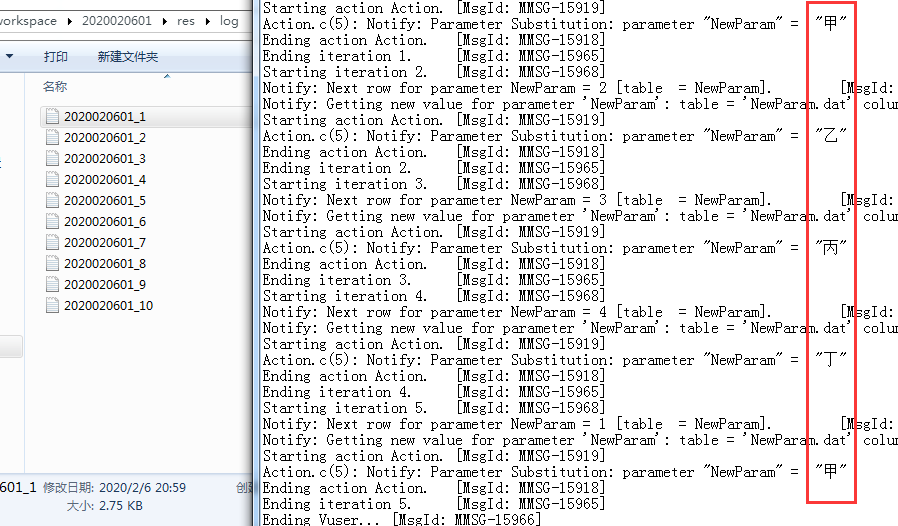
Unique实际上是压力测试中更为常用的设置。如果选择unique的设置,每个数据只会用一次,当调用的次数或迭代次数超过值的个数时就可能会报错。
下方的when out of value可以选择当数值个数不够的情况系统改如何取值。
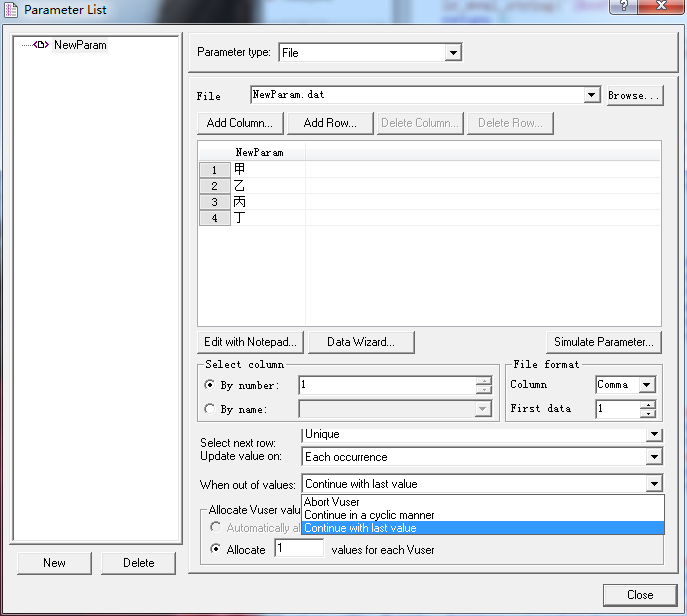
(1)abort Vuser:停止测试
(2)continue in a cyclic manner:循环取值
(3)continue with last value:沿用最后一个值

唯一取值是以用户为基础的,希望用户之间是唯一的。
在Vuser中参数取值在压力测试中是不同的,以下简单列举常用的2个压力类型:
(1)50个用户压力测试,要求测试时间内,用户登录的账号没有重复:
取值选择unique,each interaction;由于需要全部为不重复账号,一定要保证参数化文件中的账号充足,或者设置好合理的缺值处理方式。
(2)50个用户压力测试,且要求每个用户用一个固定账号,在整个测试周期中,各个用户之间的账号不重复:
取值选择unique,once;每个用户用一个账号,一定要保证参数化文件中的账号大于50个。
注:要用于压力测试的场景中的脚本的用户账号等信息使用each interaction的情况更为普遍,账号信息很少会使用each occurrence。测试中需要每个虚拟用户都不同的情况就需要用到unique,其他两种取值方式(顺序、随机)都可能出现重复。
跑场景:
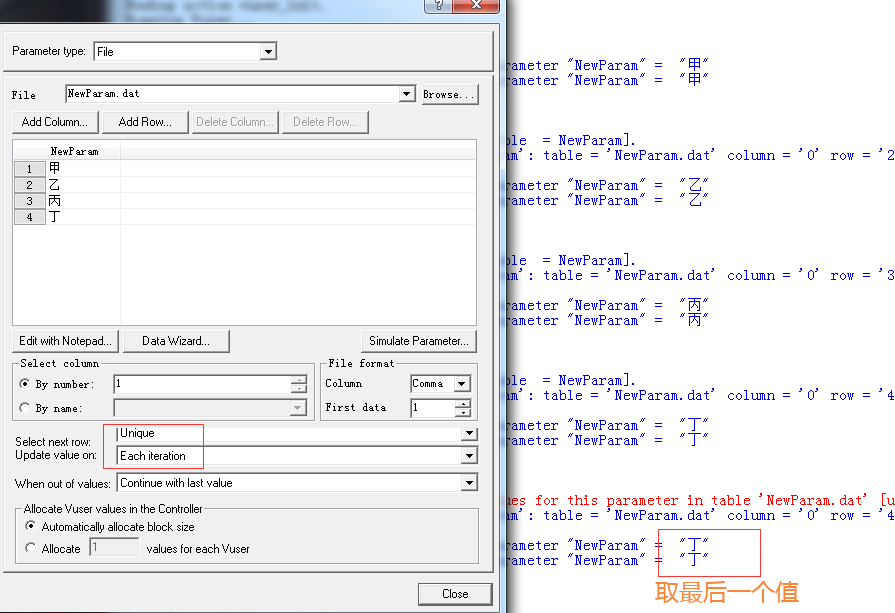
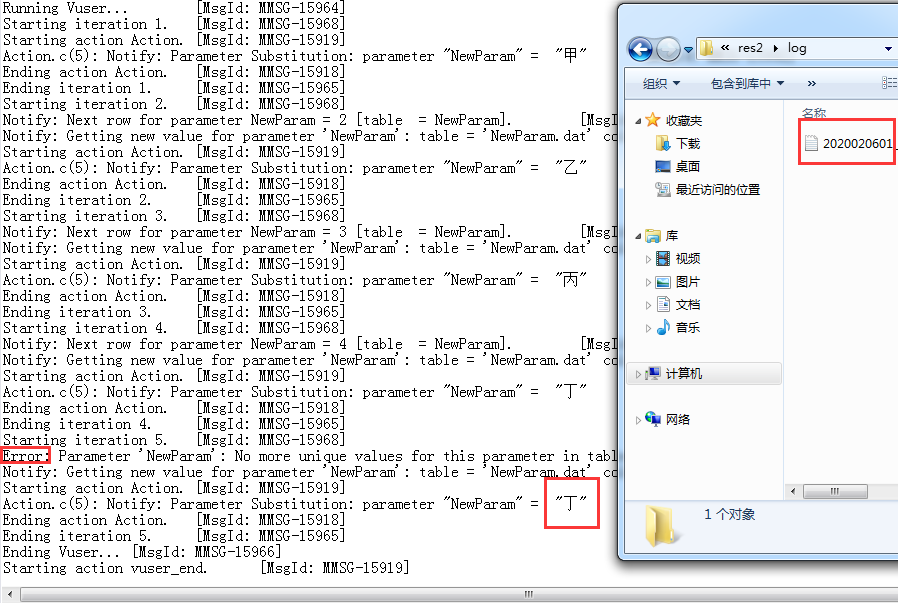
1、跟上面一样,10个用户,basic,不过这里用的是Unique+Each iteration+取最后值:
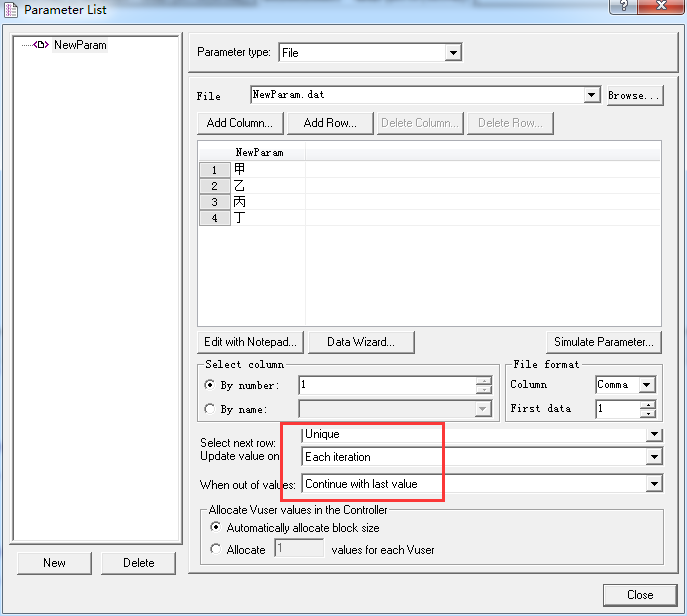
10个都报错了:
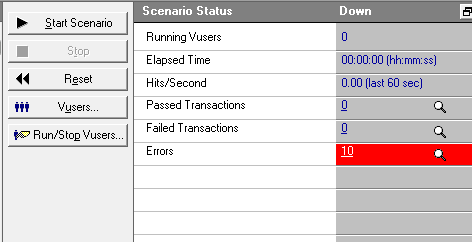
看日志,只有一个,里面甲乙丙丁丁,有个错误:
2、Unique+once:
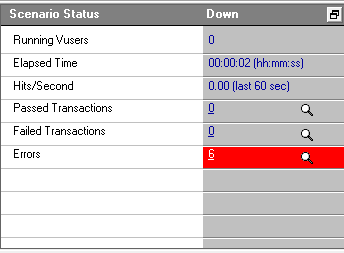
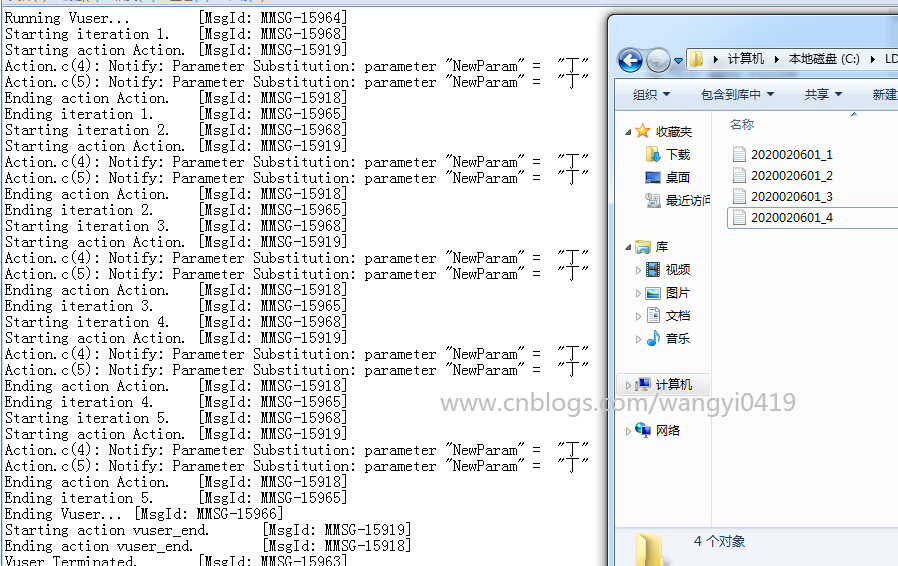
3、Unique + occurrence,每个用户只能用两个值:
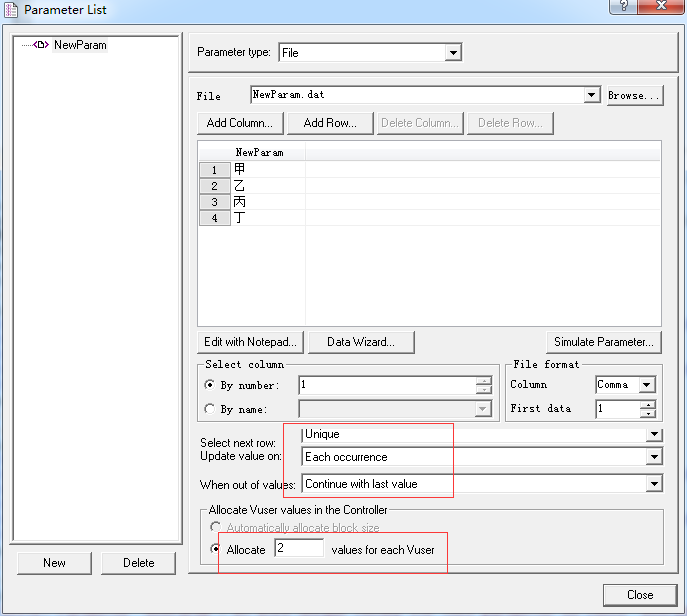
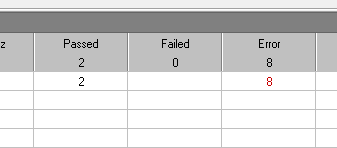

24个错误,前两个用户每个8个共16个,后面8个用户直接报错,共24个。

多参
如下,参数aaa和bbb共用一个文件,分为两列,逗号隔开,取值可以按列号也可以按列名,行值的变化可以选择aaa跟bbb一样,这样如果bbb随机变化,aaa也会跟随它取同一行的值,两者对应起来了。
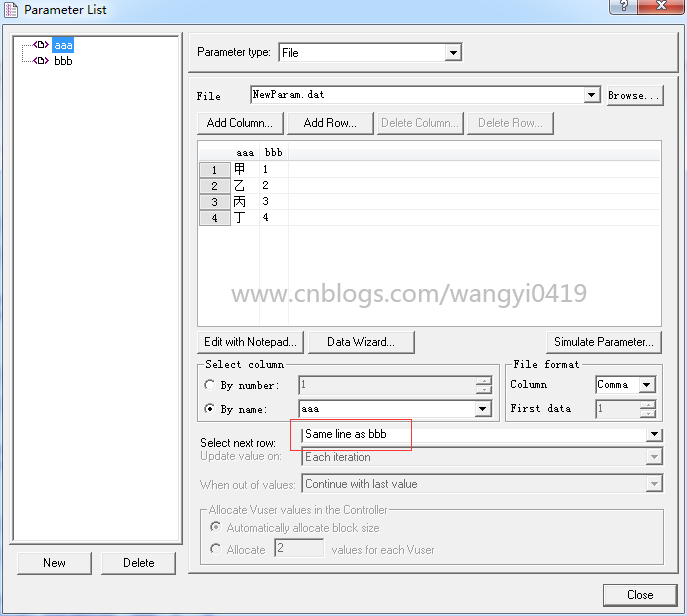

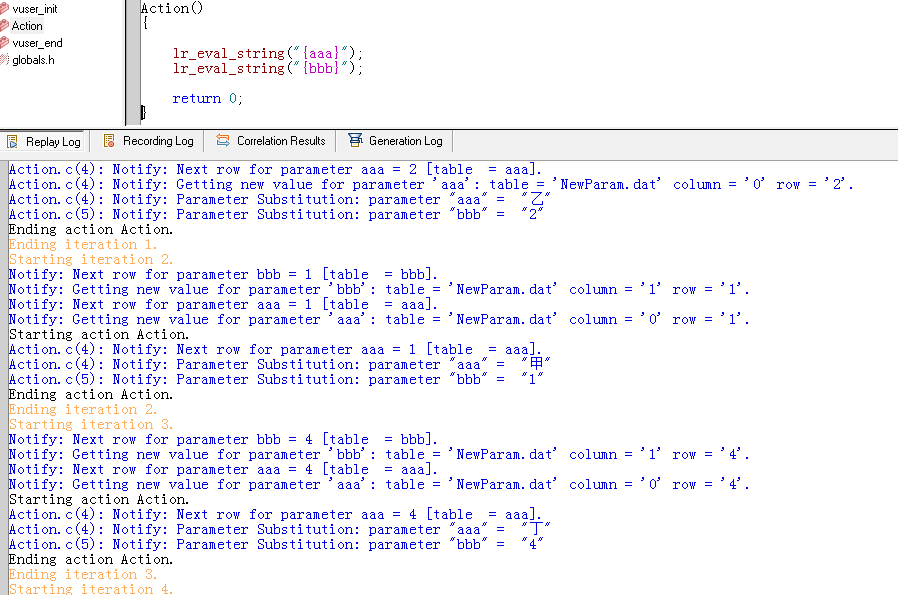
这样在登录的测试中用户名和密码就对应起来了。
至于如何生成参数中的值,可以用excel表格cvs格式的文件,复制到参数文本中,也可以使用c语言脚本生产数据或者使用数据源Data Wizard.
另外,参数与变量之间的转化,基本的几个函数要会用:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号