
Prometheus监控k8s(4)-grafana监控k8s集群/node/资源对象
Prometheus监控k8s(4)-grafana监控k8s集群/node/资源对象
https://blog.51cto.com/14143894/2438026
1 K8S监控指标
对于集群的监控一般我们需要考虑以下几个方面:
- Kubernetes 节点的监控:比如节点的 cpu、load、disk、memory 等指标
- 内部系统组件的状态:比如 kube-scheduler、kube-controller-manager、kubedns/coredns 等组件的详细运行状态
- 编排级的 metrics:比如 Deployment 的状态、资源请求、调度和 API 延迟等数据指标
node监控
• Node资源利用率 :一般生产环境几十个node,几百个node去监控
• Node数量 :一般能监控到node,就能监控到它的数量了,因为它是一个实例,一个node能跑多少个项目,也是需要去评估的,整体资源率在一个什么样的状态,什么样的值,所以需要根据项目,跑的资源利用率,还有值做一个评估的,比如再跑一个项目,需要多少资源。
• Pods数量(Node):其实也是一样的,每个node上都跑多少pod,不过默认一个node上能跑110个pod,但大多数情况下不可能跑这么多,比如一个128G的内存,32核cpu,一个java的项目,一个分配2G,也就是能跑50-60个,一般机器,pod也就跑几十个,很少很少超过100个。
• 资源对象状态 :比如pod,service,deployment,job这些资源状态,做一个统计。
Pod监控
• Pod数量(项目):你的项目跑了多少个pod的数量,大概的利用率是多少,好评估一下这个项目跑了多少个资源占有多少资源,每个pod占了多少资源。
• 容器资源利用率 :每个容器消耗了多少资源,用了多少CPU,用了多少内存
• 应用程序:这个就是偏应用程序本身的指标了,这个一般在我们运维很难拿到的,所以在监控之前呢,需要开发去给你暴露出来,这里有很多客户端的集成,客户端库就是支持很多语言的,需要让开发做一些开发量将它集成进去,暴露这个应用程序的想知道的指标,然后纳入监控,如果开发部配合,基本运维很难做到这一块,除非自己写一个客户端程序,通过shell/python能不能从外部获取内部的工作情况,如果这个程序提供API的话,这个很容易做到。
如果想监控node的资源,就可以放一个node_exporter,这是监控node资源的,node_exporter是Linux上的采集器,你放上去你就能采集到当前节点的CPU、内存、网络IO,等待都可以采集的。
如果想监控容器,k8s内部提供cAdvisor采集器,pod呀,容器都可以采集到这些指标,都是内置的,不需要单独部署,只知道怎么去访问这个Cadvisor就可以了。
如果想监控k8s资源对象,会部署一个kube-state-metrics这个服务,它会定时的API中获取到这些指标,帮你存取到Prometheus里,要是告警的话,通过Alertmanager发送给一些接收方,通过Grafana可视化展示。
2 POD容器监控—cAdvisor
目前cAdvisor集成到了kubelet组件内,可以在kubernetes集群中每个启动了kubelet的节点使用cAdvisor提供的metrics接口获取该节点所有容器相关的性能指标数据。
cAdvisor对外提供服务的默认端口为***4194***,主要提供两种接口:
- Prometheus格式指标接口:nodeIP:4194/metrics(或者通过kubelet暴露的cadvisor接口nodeIP:10255/metrics/cadvisor);
- WebUI界面接口:nodeIP:4194/containers/
以上接口的数据都是按prometheus的格式输出的。
- kubelet的节点使用cAdvisor提供的metrics接口获取该节点所
- 有容器相关的性能指标数据。
暴露接口地址:
https://NodeIP:10255/metrics/cadvisor
https://NodeIP:10250/metrics/cadvisor

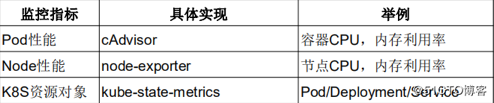
切换到 Graph 路径下面查询容器相关数据,比如我们这里来查询集群中所有 Pod 的 CPU 使用情况,这里用的数据指标是
container_cpu_usage_seconds_total,然后去除一些无效的数据,查询1分钟内的数据,由于查询到的数据都是容器相关的,最好要安装 Pod 来进行聚合,对应的promQL语句如下:
sum by (pod_name)(rate(container_cpu_usage_seconds_total{image!="", pod_name!=""}[1m] )) 
可以看到上面的结果就是集群中的所有 Pod 在1分钟之内的 CPU 使用情况的曲线图
3 Node节点监控—node_exporter
Prometheus 来采集节点的监控指标数据,可以通过node_exporter来获取,顾名思义,node_exporter 就是抓取用于采集服务器节点的各种运行指标,目前 node_exporter 支持几乎所有常见的监控点,比如 conntrack,cpu,diskstats,filesystem,loadavg,meminfo,netstat等,详细的监控点列表可以参考其Github repo。
我们可以通过 DaemonSet 控制器来部署该服务,这样每一个节点都会自动运行一个这样的 Pod,如果我们从集群中删除或者添加节点后,也会进行自动扩展。
https://www.cnblogs.com/zqj-blog/p/10895901.html
一个linux系统下的采集硬件和操作系统指标的组件,由Go语言编写。
在默认情况下,会显示所有收集到的指标,可以使用“collect[]”过滤指标,在prometheus的配置下使用词语法。
node_exporter会收集许多信息,但是默认情况下,由于内核的安全性设置,它不能收集linux上的perf,若要允许,需要开启linux系统的sysctl配置
sysctl -w kernel.perf_event_paranoid=X
#一般 =1
其中,
2 允许用户
1 允许内核和用户
0 允许访问特定的CPU,但不允许访问原始跟踪点
-1 无限制
3.1 安装node-exporter(用于收集节点的数据指标)
[root@k8s-master node-exporter]# grep image: * node-exporter-ds.yml: image: "prom/node-exporter" #用最新版本的,否则有的插件不兼容 [root@k8s-master node-exporter]# [root@k8s-master prometheus]# cd node-exporter/ [root@k8s-master node-exporter]# ls node-exporter-ds.yml node-exporter-service.yaml [root@k8s-master node-exporter]# kubectl apply -f . daemonset.apps/node-exporter created service/node-exporter created [root@k8s-master node-exporter]# kubectl get svc,pod,ds -n kube-system |grep node service/node-exporter ClusterIP None <none> 9100/TCP 23s pod/node-exporter-f2m5k 1/1 Running 0 23s pod/node-exporter-fk7vs 1/1 Running 0 23s pod/node-exporter-hz5m4 1/1 Running 0 23s daemonset.extensions/node-exporter 3 3 3 3 3 <none> 23s [root@k8s-master node-exporter]#
3.2 后台访问
http://10.6.76.23:9100/metrics
3.3 Prometheus显示
4 资源状态监控—kube-state-metrics
kube-state-metrics是一个简单的服务,它监听Kubernetes API服务器并生成有关对象状态的指标。它不关注单个Kubernetes组件的运行状况,而是关注内部各种对象的运行状况,例如部署,节点和容器。
采集了k8s中各种资源对象的状态信息:
kube-state-metrics kube_daemonset_* kube_deployment_* kube_job_* kube_namespace_* kube_node_* kube_persistentvolumeclaim_* kube_pod_container_* kube_pod_* kube_replicaset_* kube_service_* kube_statefulset_*
4.1 安装kube-state-metrics
[root@k8s-master kube-state-metrics]# ls kube-state-metrics-deployment.yaml kube-state-metrics-rbac.yaml kube-state-metrics-service.yaml [root@k8s-master kube-state-metrics]# grep image * #修改一下镜像地址 kube-state-metrics-deployment.yaml: image: quay.io/coreos/kube-state-metrics:v1.3.0 kube-state-metrics-deployment.yaml: image: mirrorgooglecontainers/addon-resizer:1.8.5 kube-state-metrics-deployment.yaml: #image: registry.cn-hangzhou.aliyuncs.com/criss/addon-resizer [root@k8s-master kube-state-metrics]# cd .. [root@k8s-master prometheus]# kubectl apply -f kube-state-metrics deployment.apps/kube-state-metrics created configmap/kube-state-metrics-config created serviceaccount/kube-state-metrics created clusterrole.rbac.authorization.k8s.io/kube-state-metrics created role.rbac.authorization.k8s.io/kube-state-metrics-resizer created clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created rolebinding.rbac.authorization.k8s.io/kube-state-metrics created service/kube-state-metrics created [root@k8s-master prometheus]# [root@k8s-master kube-state-metrics]# kubectl get all -n kube-system -o wide| grep kube-state-metrics pod/kube-state-metrics-65f56956dd-xmngf 2/2 Running 0 123m 10.254.1.149 k8s-node-1 <none> <none> service/kube-state-metrics ClusterIP 10.103.120.166 <none> 8080/TCP,8081/TCP 129m k8s-app=kube-state-metrics deployment.apps/kube-state-metrics 1/1 1 1 123m kube-state-metrics,addon-resizer quay.io/coreos/kube-state-metrics:v1.3.0,mirrorgooglecontainers/addon-resizer:1.8.5 k8s-app=kube-state-metrics,version=v1.3.0 replicaset.apps/kube-state-metrics-65f56956dd 1 1 1 123m kube-state-metrics,addon-resizer quay.io/coreos/kube-state-metrics:v1.3.0,mirrorgooglecontainers/addon-resizer:1.8.5 k8s-app=kube-state-metrics,pod-template-hash=65f56956dd,version=v1.3.0 replicaset.apps/kube-state-metrics-6d5589454b 0 0 0 123m kube-state-metrics,addon-resizer quay.io/coreos/kube-state-metrics:v1.3.0,mirrorgooglecontainers/addon-resizer:1.8.5 k8s-app=kube-state-metrics,pod-template-hash=6d5589454b,version=v1.3.0 [root@k8s-master kube-state-metrics]#
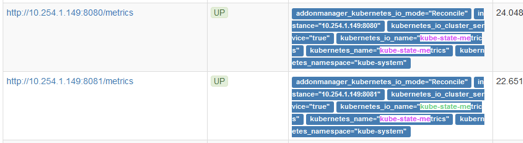
4.2 Prometheus显示
没有安装之前也能搜索kube_这种语句,但没有图形

5 用Grafana模板可视化展示Prometheus监控数据
推荐模板: 也就是在grafana共享中心里面的,也就是别人写的模版上传到这里库里面的,自己也可以写,写完上传上去,别人也可以访问到,下面是模版的id,只要获取这个ID,就能使用这个模版了,只要这个模版,后端提供执行promeQL,只要有数据就能帮你展示出来
Grafana.com
• 集群资源监控:3119
• 资源状态监控 :6417
• Node监控 :9276
这是常用的,也可以根据自己的需要去官网https://grafana.com/grafana/dashboards
模板的使用
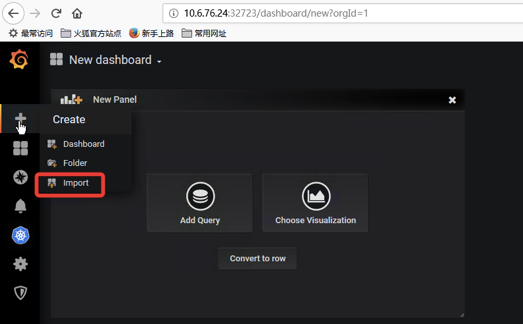
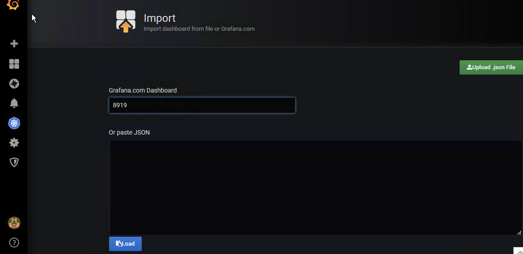


这里只是部署了grafana,图形模板确实不好用,建议采用k8s插件,下文

 浙公网安备 33010602011771号
浙公网安备 33010602011771号