GitHub地址
GitHub
实现代码
public class Simicalcu_2{
public static void main(String[] args) throws IOException{
String str1="";
File file1=new File(args[0]);
FileInputStream in1= null;
in1 = new FileInputStream(file1);
// size 为字串的长度 ,这里一次性读完
int size1=in1.available();
byte[] buffer1=new byte[size1];
in1.read(buffer1);
in1.close();
str1=new String(buffer1,"utf8");
String str2="";
File file2=new File(args[1]);
FileInputStream in2=new FileInputStream(file2);
// size 为字串的长度 ,这里一次性读完
int size2=in2.available();
byte[] buffer2=new byte[size2];
in2.read(buffer2);
in2.close();
str2=new String(buffer2,"utf8");
DecimalFormat df= new DecimalFormat("######0.00");
String result = df.format(Computeclass.SimilarDegree(str1, str2));
System.out.print("重复率:"+result);
String str3 = args[2];
FileOutputStream ou = new FileOutputStream(str3);
ou.write(result.getBytes());
ou.close();
}
}
public class Computeclass {
/*
* 计算相似度
* */
public static double SimilarDegree(String strA, String strB){
String newStrA = removeSign(strA);
String newStrB = removeSign(strB);
//用较大的字符串长度作为分母,相似子串作为分子计算出字串相似度
int temp = Math.max(newStrA.length(), newStrB.length());
int temp2 = longestCommonSubstring(newStrA, newStrB);
return temp2 * 1.0 / temp;
}
/*
* 将字符串的所有数据依次写成一行
* */
public static String removeSign(String str) {
StringBuffer sb = new StringBuffer();
//遍历字符串str,如果是汉字数字或字母,则追加到ab上面
for (char item : str.toCharArray())
if (charReg(item)){
sb.append(item);
}
return sb.toString();
}
/*
* 判断字符是否为汉字,数字和字母,
* 因为对符号进行相似度比较没有实际意义,故符号不加入考虑范围。
* */
public static boolean charReg(char charValue) {
return (charValue >= 0x4E00 && charValue <= 0X9FA5) || (charValue >= 'a' && charValue <= 'z')
|| (charValue >= 'A' && charValue <= 'Z') || (charValue >= '0' && charValue <= '9');
}
/*
* 求公共子串,采用动态规划算法。
* 其不要求所求得的字符在所给的字符串中是连续的。
*
* */
public static int longestCommonSubstring(String str1, String str2) {
char[] chars_strA = strA.toCharArray();
char[] chars_strB = strB.toCharArray();
int m = chars_strA.length;
int n = chars_strB.length;
/*
* 初始化矩阵数据,matrix[0][0]的值为0,
* 如果字符数组chars_strA和chars_strB的对应位相同,则matrix[i][j]的值为左上角的值加1,
* 否则,matrix[i][j]的值等于左上方最近两个位置的较大值,
* 矩阵中其余各点的值为0.
*/
int[][] matrix = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (chars_strA[i - 1] == chars_strB[j - 1])
matrix[i][j] = matrix[i - 1][j - 1] + 1;
else
matrix[i][j] = Math.max(matrix[i][j - 1], matrix[i - 1][j]);
}
}
/*
* 矩阵中,如果matrix[m][n]的值不等于matrix[m-1][n]的值也不等于matrix[m][n-1]的值,
* 则matrix[m][n]对应的字符为相似字符元,并将其存入result数组中。
*
*/
char[] result = new char[matrix[m][n]];
int currentIndex = result.length - 1;
while (matrix[m][n] != 0) {
if (matrix[n] == matrix[n - 1])
n--;
else if (matrix[m][n] == matrix[m - 1][n])
m--;
else {
result[currentIndex] = chars_strA[m - 1];
currentIndex--;
n--;
m--;
}
}
return new String(result);
}
}
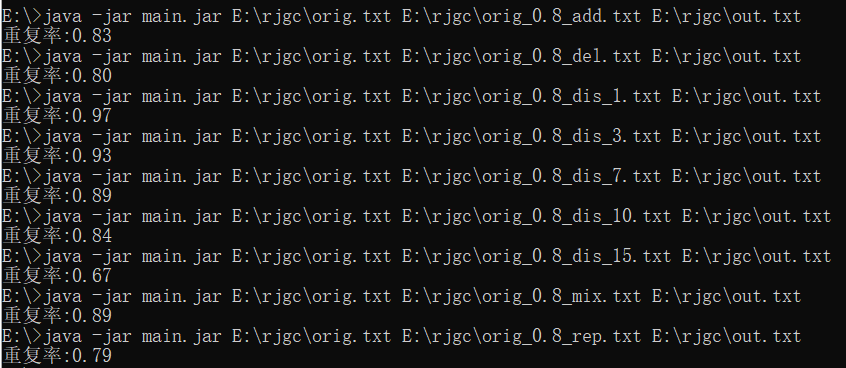
实验结果
![]()
PSP表格记录
| PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
| Planning |
计划 |
120 |
150 |
| · Estimate |
· 估计这个任务需要多少时间 |
120 |
150 |
| Development |
开发 |
480 |
600 |
| · Analysis |
· 需求分析 (包括学习新技术) |
120 |
180 |
| · Design Spec |
· 生成设计文档 |
30 |
60 |
| · Design Review |
· 设计复审 |
30 |
60 |
| · Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
20 |
30 |
| · Design |
· 具体设计 |
20 |
30 |
| · Coding |
· 具体编码 |
600 |
700 |
| · Code Review |
· 代码复审 |
120 |
180 |
| · Test |
· 测试(自我测试,修改代码,提交修改) |
30 |
60 |
| Reporting |
报告 |
60 |
120 |
| · Test Repor |
· 测试报告 |
20 |
10 |
| · Size Measurement |
· 计算工作量 |
30 |
50 |
| · Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 |
50 |
|
· 合计 |
1830 |
2430 |