

[论文阅读笔记] Network Embedding with Attribute Refinement
[论文阅读笔记] Network Embedding with Attribute Refinement
本文结构
- 解决问题
- 主要贡献
- 算法原理
- 参考文献
(1) 解决问题
根据同质性假设,相似的节点往往会连到一起,属性上相似的节点往往在拓扑上也会由相连。但是有些真实网络的属性并不是很好,即节点属性和拓扑结构常常会存在不一致的问题,这就使得某些节点对虽然在拓扑结构上相似,但是在节点属性上并不一定相似,反之亦然。
(2) 主要贡献
Contribution 1: 发现节点属性中存在与节点拓扑不一致的问题。
Contribution 2: 提出一个新颖的无监督框架NEAR,其通过一个由同质性指导学习的属性过滤器来做属性优化解决节点属性和节点拓扑不一致的问题,从而提升属性网络表征的精度。
(3) 算法原理
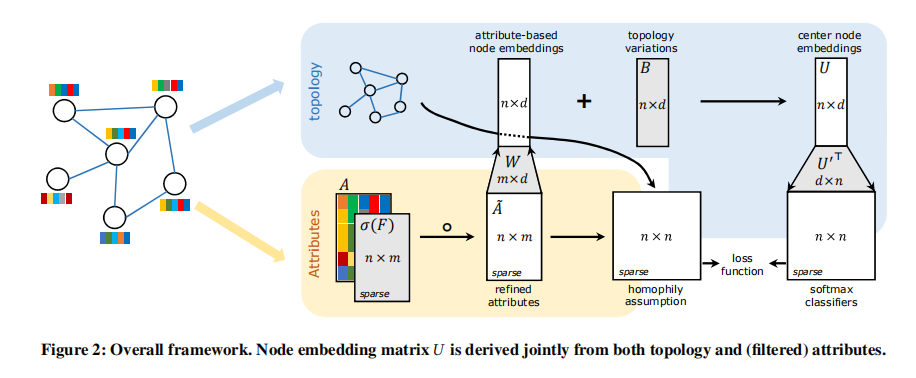
NEAR算法主要的框架如下图所示: 从该框架图中我们可以看出该算法的大体思路:(首先明确网络要学习的参数为过滤器F、隐层权重矩阵W、拓扑信息矩阵B以及节点上下文向量U')其次来看属性信息的引入,属性矩阵A与一个过滤器F相乘得到优化后的数据矩阵A,A与网络中对应的权重矩阵W相乘得到一个 n x d 的基于属性的节点表示向量矩阵,再加上网络中的偏置矩阵B(表示基于拓扑信息的网络嵌入矩阵)可以得到节点中心向量(该神经网络中的节点由两个向量表示,中心节点向量和上下文向量,类比于Skip-Gram),节点中心向量矩阵与节点上下文向量矩阵求点积得到一个类似节点相似度的矩阵,再softmax归一化可以预测中心节点的可能上下文(即Skip-Gram模型),该部分的损失函数为Skip-Gram的损失函数(最大化节点共现概率)。再者,我们来看拓扑信息的引入,拓扑信息用来计算节点相似度矩阵 n x n (文后介绍)与A~属性矩阵 n x n 结合,作为损失函数中的一项。可以看到,最终损失函数由两部分构成,Skip-Gram损失函数 + 基于同质性假设的用来优化节点属性(解决属性和拓扑不一致问题的)损失函数(文后介绍)。关于网络训练部分,训练样本的生成要么是采样邻居要么是通过随机游走。
损失函数由两部分组成,以下对各个部分分别进行介绍:
- Skip-Gram损失函数如下(详细推导过程请看DeepWalk原始论文): 最小化该目标函数即求节点向量,使得窗口内节点的共现概率最大化。
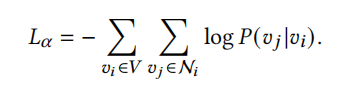
- 基于同质性假设的用来优化节点属性(解决属性和拓扑不一致问题的)损失函数: sim_t 为节点对在拓扑结构上的相似度(同质性假设可以由节点邻域的相似性表达),本文中是以 Adar index 来衡量的(两节点的 Adar index度量计算:两节点的所有共同邻居的logk分之1求和)。sim_a是节点对的属性相似度,本文中用节点属性向量的余弦来衡量。则最小化下述目标函数所要表达的意思是:以某种方式(如过滤器F)调整节点对的属性向量,使得节点对的结构相似度与属性相似度的乘积最大(相等时最大),这样就保证了节点在结构(属性)上相似的同时在属性(结构)上也相似,即解决了节点属性和节点拓扑不一致的问题。
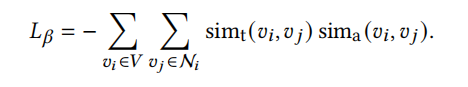
最终的目标函数如下(为上述两个目标函数加权求和):

(4) 参考文献
Xiao T, Fang Y, Yang H, et al. Network Embedding with Attribute Refinement[J].

 浙公网安备 33010602011771号
浙公网安备 33010602011771号