
DMA
DMA是计算机系统的一个特性,它允许设备在没有CPU干预的情况下访问主系统内存RAM,然后允许它们投入到其他任务中。人们通常使用它来加速网络流量,但它支持任何类型的拷贝。
DMA控制器是负责DMA管理的外围设备。主要在现代处理器和微控制器中能看到它。DMA有一个用于执行内存读写操作而不占用CPU周期的特性。当需要传输数据块时,CPU 向DMA控制器提供源地址和目的地址以及总字节数。DMA控制器然后自动地将数据从源地址传输到目的地址,而不占用CPU周期。当剩余字节数为0时,块传输结束。
设置DMA映射
对于任何类型的 DMA 传输,都需要提供源地址和目的地址,以及要传输的字节数。在外围DMA的情况下,外围设备的 FIFO 既可以作为源,也可以作为目的。当外围设备作为源时,内存位置(内部或外部)作为目的地址。当外围设备作为目的地时,内存位置(内部或外部)作为源地址。
对于外设DMA,我们根据传输的方向指定源或目的地。换句话说,DMA传输需要合适的内存映射。
缓存一致性和DMA
根据内核内存管理的知识,最近访问的内存区域的副本存储在缓存中,这也适用于DMA内存。事实上,两个独立设备之间共享的内存通常是缓存一致性问题的根源。缓存不连贯的问题来自于其他设备可能不知道写入设备的更新这一事实。另一方面,缓存一致性确保每个写操作似乎是瞬间发生的,因此共享相同内存区域的所有设备看到完全相同的变化序列。
下面从LDD3摘录说明了一个解释良好的一致性问题场景:
让我们想象一个配备了缓存和外部内存的CPU,可以由使用DMA的设备直接访问。当CPU访问内存中的位置X时,当前值将存储在缓存中。假设是回写缓存,X 上的后续操作将更新 X 的缓存副本,但不会更新 X 的外部内存的版本。如果在下一次设备尝试访问X之前,缓存没有刷新到内存中,设备将收到过期的X值。类似地,如果当设备向内存写入新值时,X的缓存副本没有失效,那么CPU将对过时的X值进行操作。
有两种方法可以解决这个问题:
- 一个基于硬件的解决方案。这样的系统是一致的系统。
- 一种基于软件的解决方案,其中操作系统负责确保缓存一致性。人们称这种系统为非一致性系统。
DMA映射
任何合适的DMA传输都需要合适的内存映射。DMA映射包括分配DMA缓冲区并为其生成总线地址。设备实际上使用总线地址。总线地址是dma_addr_t类型的每个实例。
我们可以区分两种类型的映射:一致性DMA映射和流式DMA映射。可以在多个传输中使用前者,自动解决缓存一致性问题。但是一致DMA映射资源很宝贵。流映射有很多约束,并且不能自动解决一致性问题,尽管有一个解决方案,即在每个传输之间包含几个函数调用。一致性映射通常存在于驱动程序的生命周期中,而流式映射通常在DMA传输完成后取消映射。
我们应该尽可能地使用流式DMA映射,在必要情况下再使用一致性DMA映射。
代码中应该包括以下头文件当使用DMA映射时:
#include <linux/dma-mapping.h>
一致性映射
下面的函数用于设置一致性的映射:
void *dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *dma_handle, gfp_t flag)
这个函数处理缓冲区的分配和映射,并返回该缓冲区的内核虚拟地址,该地址的大小为 size 字节,可由CPU访问。dev 是你的设备结构体。第三个参数是指向相关总线地址的输出参数。为映射分配的内存保证在物理上是连续的,并且标志决定应该如何分配内存,通常是通过GFP_KERNEL或GFP_ATOMIC(如果我们是在原子上下文中)分配。
请注意,这个映射被称为:
- 一致性,因为它为设备分配未缓存和未缓冲的内存来执行DMA
- 同步,因为设备或CPU的写入可以立即被其中任何一个读取,而无需担心缓存一致性
释放一个映射时,可以使用以下函数:
void dma_free_coherent(struct device *dev, size_t size, void *cpu_addr, dma_addr_t dma_handle);
这里,cpu_addr对应于dma_alloc_coherent()返回的内核虚拟地址。这种映射是昂贵的,它可以分配的最小值是一个页面。实际上,它只分配2的幂的页面数。页面的顺序是通过int order = get_order(size)获得的。应该将此映射用于持续设备生命周期的缓冲区。
流式DMA映射
流式映射约束更多,与一致性映射不同,原因如下:
- 映射需要使用已经分配的缓冲区。
- 映射可以接受几个不相邻和分散的缓冲区。
- 一个映射的缓冲区不再属于CPU,而是属于设备。CPU可以使用缓冲区之前,它应该首先解除缓冲区映射(在dma_unmap_single() 或 dma_unmap_sg() 之后)。这是为了缓存的目的。
- 对于写事务(CPU到设备),驱动程序应该将数据放在映射之前的缓冲区中。
- 必须指定数据应该移动的方向,并且数据只能基于这个方向使用。
你可能想知道为什么在未映射之前不应该访问缓冲区。原因很简单: CPU映射是可缓存的。dma_map_*()家族函数,用于流映射,将首先清理/使缓存相关的缓冲区无效,并依赖CPU不访问它,直到相应的dma_unmap_*()。然后,在CPU可以读取设备写入内存的任何数据之前,如果有必要,将再次使缓存失效,以防在此期间发生任何投机性的取数据。现在CPU可以访问缓冲区。
实际上有两种形式的流式映射:
- 单缓冲区映射,只允许单页映射
- 分散/聚集映射,允许传递多个缓冲区(分散在内存中)
对于任何一个映射,方向都应该由 enum dma_data_direction 类型的符号指定,该符号在 include/linux/dma-direction.h 中定义:
enum dma_data_direction { DMA_BIDIRECTIONAL = 0, DMA_TO_DEVICE = 1, DMA_FROM_DEVICE = 2, DMA_NONE = 3, };
单缓冲区映射
这是为了偶尔映射。可以这样设置单个缓冲区:
dma_addr_t dma_map_single(struct device *dev, void *ptr, size_t size, enum dma_data_direction direction);
方向应该是DMA_TO_DEVICE、DMA_FROM_DEVICE 或 DMA_BIDIRECTIONAL,如上述代码所述。ptr 是缓冲区的内核虚拟地址,dma_addr_t 是设备返回的总线地址。确保使用真正适合您需求的方向,而不是总是 DMA_BIDIRECTIONAL。
我们应该这样释放映射:
void dma_unmap_single(struct device *dev, dma_addr_t dma_addr, size_t size, enum dma_data_direction direction);
分散/聚集映射
分散/聚集映射是一种特殊类型的流式DMA映射,在这种映射中,可以一次性传输多个缓冲区区域,而不是逐个映射每个缓冲区并逐个传输。假设您有几个缓冲区,它们在物理上可能不是连续的,所有这些缓冲区都需要同时传输到设备或从设备传输出去。出现这种情况的原因可能是:
- readv 或者 writev 系统调用
- 磁盘 I/O 请求
- 或者,只是映射的内核I/O缓冲区中的页面列表
内核将散列表表示为一个一致性结构,struct scatterlist:
struct scatterlist { unsigned long page_link; unsigned int offset; unsigned int length; dma_addr_t dma_address; unsigned int dma_length; };
为了建立散列表映射,应该:
- 分配分散的缓冲区。
- 创建一个散列表的数组,使用 sg_set_buf() 用分配的内存填充它。
- 调用散列表上的 dma_map_sg()。
- 完成DMA之后,调用 dma_unmap_sg() 来取消散列表的映射。
虽然可以通过DMA发送多个缓冲区的内容,每次一个,逐个映射每个缓冲区,分散/聚集映射可以通过向设备发送指向散列表的指针以及长度(即列表中条目的数量)来一次性发送它们:
1 u32 *wbuf, *wbuf2, *wbuf3; 2 wbuf = kzalloc(SDMA_BUF_SIZE, GFP_DMA); 3 wbuf2 = kzalloc(SDMA_BUF_SIZE, GFP_DMA); 4 wbuf3 = kzalloc(SDMA_BUF_SIZE/2, GFP_DMA); 5 struct scatterlist sg[3]; 6 sg_init_table(sg, 3); 7 sg_set_buf(&sg[0], wbuf, SDMA_BUF_SIZE); 8 sg_set_buf(&sg[1], wbuf2, SDMA_BUF_SIZE); 9 sg_set_buf(&sg[2], wbuf3, SDMA_BUF_SIZE/2); 10 ret = dma_map_sg(NULL, sg, 3, DMA_MEM_TO_MEM);
在“单缓冲区映射”中描述的规则同样适用于分散/聚集映射:
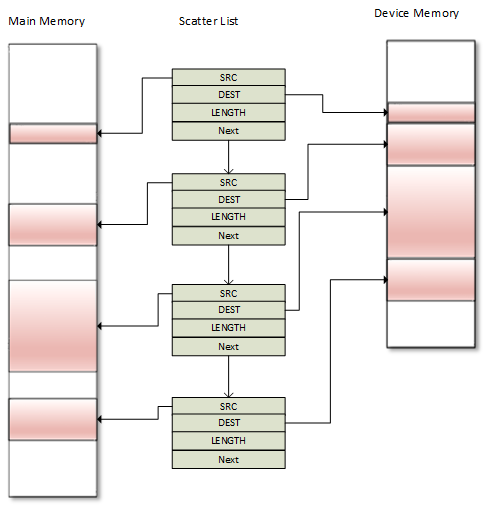
分散/聚集 DMA
dma_map_sg() 和 dma_unmap_sg() 负责缓存一致性。但是,如果需要使用相同的映射来访问(读/写)DMA传输之间的数据,则必须以适当的方式在每次传输之间同步缓冲区,如果CPU需要访问缓冲区,则使用 dma_sync_sg_for_cpu(); 如果是设备,则使用dma_sync_sg_for_device()。类似的单个区域映射函数有 dma_sync_single_for_cpu() 和 dma_sync_single_for_device():
1 void dma_sync_sg_for_cpu(struct device *dev, 2 struct scatterlist *sg, 3 int nents, 4 enum dma_data_direction direction); 5 void dma_sync_sg_for_device(struct device *dev, 6 struct scatterlist *sg, int nents, 7 enum dma_data_direction direction); 8 void dma_sync_single_for_cpu(struct device *dev, dma_addr_t addr, 9 size_t size, 10 enum dma_data_direction dir) 11 void dma_sync_single_for_device(struct device *dev, 12 dma_addr_t addr, size_t size, 13 enum dma_data_direction dir)
在缓冲区被解除映射后,不需要再次调用前面的函数。
完成的概念
本节将简要描述DMA传输使用的完成和必要的API部分。要获得完整的描述,请参阅 documentation /scheduler/completion.txt 中的内核文档。内核编程中的一个常见模式是在当前线程之外初始化一些活动,然后等待该活动完成。
在等待使用缓冲区时,Completion是sleep()的一个很好的替代方法。它适合于感知数据,这正是DMA回调所做的。需要包含这个头文件:
<linux/completion.h>
像其他内核设施数据结构一样,可以静态或动态地创建 struct completion 结构的实例:
- 静态声明和初始化方法如下:
DECLARE_COMPLETION(my_comp);
- 动态分配是这样的:
struct completion my_comp; init_completion(&my_comp);
当驱动程序开始一些必须等待完成的工作(在我们的例子中是DMA事务)时,它只需要将完成事件传递给 wait_for_completion() 函数:
void wait_for_completion(struct completion *comp);
当代码的其他部分已经完成时(事务完成),它可以唤醒任何(实际上代码需要访问DMA缓冲区)正在等待的人:
void complete(struct completion *comp); void complete_all(struct completion *comp);
可以猜到,complete() 将只唤醒一个等待的进程,而 complete_all() 将唤醒每个等待该事件的进程。完成的实现方式是,即使在wait_for_completion()之前调用complete(),它们也能正常工作。
通过在下一节中使用的代码示例,我们将更好地理解这是如何工作的。
DMA引擎API
DMA引擎是用于开发DMA控制器驱动程序的通用内核框架。DMA的主要目标是在复制内存时解放CPU。一种通过使用通道将事务(I/O数据传输)委托给DMA引擎。一个DMA引擎,通过它的驱动程序/API,公开了一组可以被其他人使用的通道设备(从机)。DMA引擎布局如下图所示:
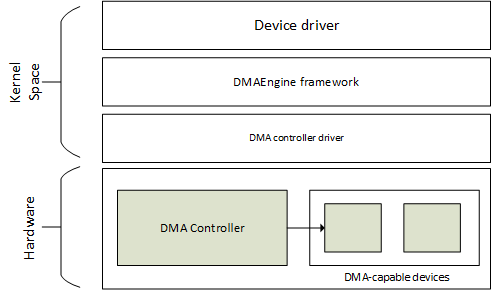
DMA引擎布局
在这里,我们将简单地浏览(从)API,它只适用于从DMA的使用。这里的强制性头文件如下:
#include <linux/dmaengine.h>
使用从DMA很简单,包括以下步骤:
- 分配一个DMA从通道
- 设置从 和 控制器特定的参数
- 获取事务的描述符
- 提交事务
- 发出挂起的请求并等待回调通知
可以将DMA通道视为I/O数据传输的高速公路。
分配DMA从通道
可以使用 dma_request_channel() 请求一个通道。其原型如下:
struct dma_chan *dma_request_channel(const dma_cap_mask_t *mask, dma_filter_fn fn, void *fn_param);
mask 是位掩码,表示信道必须满足的功能。人们基本上使用它来指定驱动程序需要执行的传输类型:
1 enum dma_transaction_type { 2 DMA_MEMCPY, /* Memory to memory copy */ 3 DMA_XOR, /* Memory to memory XOR*/ 4 DMA_PQ, /* Memory to memory P+Q computation */ 5 DMA_XOR_VAL, /* Memory buffer parity check using XOR */ 6 DMA_PQ_VAL, /* Memory buffer parity check using P+Q */ 7 DMA_INTERRUPT, /* The device is able to generate dummy transfer that 8 will generate interrupts */ 9 DMA_SG, /* Memory to memory scatter gather */ 10 DMA_PRIVATE, /* channels are not to be used for global memcpy. 11 Usually used with DMA_SLAVE */ 12 DMA_SLAVE, /* Memory to device transfers */ 13 DMA_CYCLIC, /* Device is able to handle cyclic transfers */ 14 DMA_INTERLEAVE, /* Memory to memory interleaved transfer */ 15 }
dma_cap_zero() 和 dma_cap_set() 函数用于清除掩码并设置我们需要的功能。例如:
1 dma_cap_mask_t my_dma_cap_mask; 2 struct dma_chan *chan; 3 dma_cap_zero(my_dma_cap_mask); 4 dma_cap_set(DMA_MEMCPY, my_dma_cap_mask); /* Memory to memory copy */ 5 chan = dma_request_channel(my_dma_cap_mask, NULL, NULL);
在前面的摘录中,dma_filter_fn 定义如下:
typedef bool (*dma_filter_fn)(struct dma_chan *chan, void *filter_param);
如果filter_fn参数(可选)为NULL, dma_request_channel() 将简单地返回满足能力掩码的第一个通道。否则,当掩码参数不足以指定必要的通道时,可以使用filter_fn例程作为系统中可用通道的过滤器。内核为系统中的每个空闲通道调用一次filter_fn例程。在看到合适的通道时,filter_fn应该返回DMA_ACK,该ack将标记给定的通道为 dma_request_channel() 的返回值。
在调用dma_release_channel()之前,通过该接口分配的通道都是调用方独占的:
void dma_release_channel(struct dma_chan *chan)
设置从和控制器特定的参数
这一步引入了一个新的数据结构,struct dma_slave_config,它表示DMA从通道的运行时配置。这允许客户端为外围设备指定设置,如DMA方向、DMA地址、总线宽度、DMA突发长度等。
int dmaengine_slave_config(struct dma_chan *chan, struct dma_slave_config *config)
结构体 dma_slave_config 如下所示:
/* * Please refer to the complete description in * include/linux/dmaengine.h */ struct dma_slave_config { enum dma_transfer_direction direction; phys_addr_t src_addr; phys_addr_t dst_addr; enum dma_slave_buswidth src_addr_width; enum dma_slave_buswidth dst_addr_width; u32 src_maxburst; u32 dst_maxburst; [...] };
以下是该结构中每个元素的含义:
- direction: 指示数据是否应该立即在这个从属通道上输入或输出。取值包括:
/* dma transfer mode and direction indicator */ enum dma_transfer_direction { DMA_MEM_TO_MEM, /* Async/Memcpy mode */ DMA_MEM_TO_DEV, /* From Memory to Device */ DMA_DEV_TO_MEM, /* From Device to Memory */ DMA_DEV_TO_DEV, /* From Device to Device */ [...] };
- src_addr: 这是应该读取DMA从数据(RX)的缓冲区的物理地址(实际上是总线地址)。如果源是内存,则忽略此元素。dst_addr是应该写入DMA从数据(TX)的缓冲区的物理地址(实际上是总线地址),如果源是内存,则忽略该缓冲区.
- src_addr_width: 这是以字节为单位的源(RX)寄存器的宽度,DMA数据应该在该寄存器中读取。如果源是内存,根据架构的不同,这可能会被忽略。合法值为1、2、4或8。因此,dst_addr_width与src_addr_width相同,但是用于目的目标(TX)。
- 任何总线宽度必须是下列枚举之一:
enum dma_slave_buswidth { DMA_SLAVE_BUSWIDTH_UNDEFINED = 0, DMA_SLAVE_BUSWIDTH_1_BYTE = 1, DMA_SLAVE_BUSWIDTH_2_BYTES = 2, DMA_SLAVE_BUSWIDTH_3_BYTES = 3, DMA_SLAVE_BUSWIDTH_4_BYTES = 4, DMA_SLAVE_BUSWIDTH_8_BYTES = 8, DMA_SLAVE_BUSWIDTH_16_BYTES = 16, DMA_SLAVE_BUSWIDTH_32_BYTES = 32, DMA_SLAVE_BUSWIDTH_64_BYTES = 64, };
- src_maxburst:这是可以一次性发送到设备的最大字数(这里,将words作为src_addr_width成员的单位,而不是字节),通常是I/O外设的FIFO深度的一半,这样就不会溢出。这在内存源上可能适用,也可能不适用。 dst_maxburst 与 src_maxburst 相同,但用于目的目标。
例如:
1 struct dma_chan *my_dma_chan; 2 dma_addr_t dma_src, dma_dst; 3 struct dma_slave_config my_dma_cfg = {0}; 4 5 /* No filter callback, neither filter param */ 6 my_dma_chan = dma_request_channel(my_dma_cap_mask, 0, NULL); 7 8 /* scr_addr and dst_addr are ignored in this structure for mem to mem copy 9 */ 10 my_dma_cfg.direction = DMA_MEM_TO_MEM; 11 my_dma_cfg.dst_addr_width = DMA_SLAVE_BUSWIDTH_32_BYTES; 12 13 dmaengine_slave_config(my_dma_chan, &my_dma_cfg); 14 15 char *rx_data, *tx_data; 16 /* No error check */ 17 rx_data = kzalloc(BUFFER_SIZE, GFP_DMA); 18 tx_data = kzalloc(BUFFER_SIZE, GFP_DMA); 19 20 feed_data(tx_data); 21 22 /* get dma addresses */ 23 dma_src = dma_map_single(NULL, tx_data, 24 BUFFER_SIZE, DMA_MEM_TO_MEM); 25 dma_dst = dma_map_single(NULL, rx_data, 26 BUFFER_SIZE, DMA_MEM_TO_MEM);
在前面的节选中,我们调用 dma_request_channel() 函数以获得DMA通道的所有权,在该通道上我们调用 dmaengine_slave_config() 来应用它的配置。调用dma_map_single()是为了映射rx和tx缓冲区,以便它们可以用于DMA。
获取事务的描述符
如果您还记得本节的第一步,当请求DMA通道时,返回值是 struct dma_chan 结构体的一个实例。如果查看 include/linux/dmaengine.h 中的定义,就会注意到它包含一个struct dma_device *device字段,表示提供通道的DMA设备(实际上是控制器)。该控制器的内核驱动程序负责(这是内核API对DMA控制器驱动程序施加的规则)公开一组函数来准备DMA事务,其中每个函数对应一个DMA事务类型(在步骤1中枚举)。人们别无选择,只能选择专用功能。其中一些函数是:
- device_prep_dma_memcpy(): 准备memcpy操作
- device_prep_dma_sg(): 准备一个分散/聚集memcpy操作
- device_prep_dma_xor(): 用于xor操作
- device_prep_dma_xor_val(): 准备xor验证操作
- device_prep_dma_pq(): 准备pq操作
- device_prep_dma_pq_val(): 准备一个pqzero_sum操作
- device_prep_dma_memset(): 准备一个memset操作
- device_prep_dma_memset_sg(): 用于分散列表上的memset操作
- device_prep_slave_sg(): 准备从DMA操作
- device_prep_interleaved_dma(): 以通用方式传输表达式
让我们看看drivers/dma/imx-sdma.c,这是i.MX6 dma控制器(SDMA)驱动程序。这些函数都返回一个指向struct dma_async_tx_descriptor结构体的指针,该结构体对应于事务描述符。
对于内存到内存复制,将使用device_prep_dma_memcpy:
1 struct dma_device *dma_dev = my_dma_chan->device; 2 struct dma_async_tx_descriptor *tx = NULL; 3 4 tx = dma_dev->device_prep_dma_memcpy(my_dma_chan, dma_dst_addr, 5 dma_src_addr, BUFFER_SIZE, 0); 6 7 if (!tx) { 8 printk(KERN_ERR "%s: Failed to prepare DMA transfer\n", 9 __FUNCTION__); 10 /* dma_unmap_* the buffer */ 11 }
事实上,我们应该使用dmaengine_prep_* DMA引擎API。只需注意,这些函数在内部执行我们刚才执行的操作。例如,对于内存-内存,可以使用dmaengine_prep_dma_memcpy()函数:
static inline struct dma_async_tx_descriptor *dmaengine_prep_dma_memcpy(struct dma_chan *chan, dma_addr_t dest, dma_addr_t src, size_t len, unsigned long flags)
例子如下:
1 struct dma_async_tx_descriptor *tx = NULL; 2 tx = dmaengine_prep_dma_memcpy(my_dma_chan, dma_dst_addr, 3 dma_src_addr, BUFFER_SIZE, 0); 4 if (!tx) { 5 printk(KERN_ERR "%s: Failed to prepare DMA transfer\n", 6 __FUNCTION__); 7 /* dma_unmap_* the buffer */ 8 }
请查看 include/linux/dmaengine.h,在struct dma_device 结构体的定义中,了解所有这些回调是如何实现的。
提交事务
要将事务放入驱动程序挂起队列中,可以使用dmaengine_submit()。一旦准备好了描述符并添加了回调信息,就应该把它放在DMA引擎驱动程序等待队列上:
dma_cookie_t dmaengine_submit(struct dma_async_tx_descriptor *desc)
该函数返回一个cookie,可以使用该cookie通过其他DMA引擎检查DMA活动的进度。dmaengine_submit()不会启动DMA操作,它只是将其添加到挂起队列中。下一步将讨论如何启动传输事务:
1 struct completion transfer_ok; 2 init_completion(&transfer_ok); 3 tx->callback = my_dma_callback; 4 5 /* Submit our dma transfer */ 6 dma_cookie_t cookie = dmaengine_submit(tx); 7 8 if (dma_submit_error(cookie)) { 9 printk(KERN_ERR "%s: Failed to start DMA transfer\n", __FUNCTION__); 10 /* Handle that */ 11 12 [...] 13 }
发出挂起的DMA请求并等待回调通知
启动事务是DMA传输设置的最后一步。可以通过调用通道上的 dma_async_issue_pending() 来激活通道的挂起队列中的事务。如果通道是空闲的,那么队列中的第一个事务将启动,随后的事务将排队。DMA操作完成后,队列中的下一个操作将启动,并触发一个微线程。这个微线程负责调用客户端驱动完成回调例程来通知,如果设置了的话:
void dma_async_issue_pending(struct dma_chan *chan);
示例如下:
1 dma_async_issue_pending(my_dma_chan); 2 wait_for_completion(&transfer_ok); 3 4 dma_unmap_single(my_dma_chan->device->dev, dma_src_addr, 5 BUFFER_SIZE, DMA_MEM_TO_MEM); 6 dma_unmap_single(my_dma_chan->device->dev, dma_src_addr, 7 BUFFER_SIZE, DMA_MEM_TO_MEM); 8 9 /* Process buffer through rx_data and tx_data virtualaddresses. */
wait_for_completion() 函数将阻塞,直到DMA回调函数被调用,它将更新(complete)我们的completion变量,以恢复之前阻塞的代码。这是一个合适的替代while (!done) msleep(SOME_TIME);
static void my_dma_callback() { complete(transfer_ok); return; }
实际发出挂起事务的DMA引擎API函数是 dmaengine_issue_pending(struct dma_chan *chan),它是对 dma_async_issue_pending() 的一个封装。
NXP SDMA (i.MX6)
SDMA引擎是i.MX6中的一个可编程控制器,每个外设在这个控制器中都有自己的复制功能。可以使用这个枚举来确定它们的地址:
enum sdma_peripheral_type { IMX_DMATYPE_SSI, /* MCU domain SSI */ IMX_DMATYPE_SSI_SP, /* Shared SSI */ IMX_DMATYPE_MMC, /* MMC */ IMX_DMATYPE_SDHC, /* SDHC */ IMX_DMATYPE_UART, /* MCU domain UART */ IMX_DMATYPE_UART_SP, /* Shared UART */ IMX_DMATYPE_FIRI, /* FIRI */ IMX_DMATYPE_CSPI, /* MCU domain CSPI */ IMX_DMATYPE_CSPI_SP, /* Shared CSPI */ IMX_DMATYPE_SIM, /* SIM */ IMX_DMATYPE_ATA, /* ATA */ IMX_DMATYPE_CCM, /* CCM */ IMX_DMATYPE_EXT, /* External peripheral */ IMX_DMATYPE_MSHC, /* Memory Stick Host Controller */ IMX_DMATYPE_MSHC_SP, /* Shared Memory Stick Host Controller */ IMX_DMATYPE_DSP, /* DSP */ IMX_DMATYPE_MEMORY, /* Memory */ IMX_DMATYPE_FIFO_MEMORY,/* FIFO type Memory */ IMX_DMATYPE_SPDIF, /* SPDIF */ IMX_DMATYPE_IPU_MEMORY, /* IPU Memory */ IMX_DMATYPE_ASRC, /* ASRC */ IMX_DMATYPE_ESAI, /* ESAI */ IMX_DMATYPE_SSI_DUAL, /* SSI Dual FIFO */ IMX_DMATYPE_ASRC_SP, /* Shared ASRC */ IMX_DMATYPE_SAI, /* SAI */ }
尽管有通用的DMA引擎API,任何构造函数都可以提供自己的自定义数据结构。这是imx_dma_data结构的情况,它是私有数据(用于描述一个需要使用的DMA设备类型),将在过滤器回调中传递给struct dma_chan的.private字段:
1 struct imx_dma_data { 2 int dma_request; /* DMA request line */ 3 int dma_request2; /* secondary DMA request line */ 4 enum sdma_peripheral_type peripheral_type; 5 int priority; 6 }; 7 8 enum imx_dma_prio { 9 DMA_PRIO_HIGH = 0, 10 DMA_PRIO_MEDIUM = 1, 11 DMA_PRIO_LOW = 2 12 };
这些结构和枚举都是特定于i.MX的,并在include/linux/platform_data/dma-imx.h中定义。现在,让我们编写内核DMA模块。它分配两个缓冲区(源和目的)。用预定义的数据填充源,并执行一个事务以将src复制到dst。可以通过使用来自用户空间的数据(copy_from_user())来改进这个模块。这个驱动程序的灵感来自于imx-test包中提供的一个:
1 #include <linux/module.h> 2 #include <linux/slab.h> /* for kmalloc */ 3 #include <linux/init.h> 4 #include <linux/dma-mapping.h> 5 #include <linux/fs.h> 6 #include <linux/version.h> 7 #if (LINUX_VERSION_CODE >= KERNEL_VERSION(3,0,35)) 8 #include <linux/platform_data/dma-imx.h> 9 #else 10 #include <mach/dma.h> 11 #endif 12 13 14 #include <linux/dmaengine.h> 15 #include <linux/device.h> 16 17 18 #include <linux/io.h> 19 #include <linux/delay.h> 20 21 static int gMajor; /* major number of device */ 22 static struct class *dma_tm_class; 23 u32 *wbuf; /* source buffer */ 24 u32 *rbuf; /* destination buffer */ 25 26 27 struct dma_chan *dma_m2m_chan; /* our dma channel */ 28 struct completion dma_m2m_ok; /* completion variable used in the DMA 29 callback */ 30 #define SDMA_BUF_SIZE 1024 //对于单个映射,缓冲区大小不需要是页面大小的倍数。
让我们定义过滤器函数。当请求DMA通道时,控制器驱动程序可以在通道列表中执行查找(它已经有了)。对于细粒度查找,可以提供一个回调方法,该方法将在找到的每个通道上调用。然后由回调函数选择一个合适的通道来使用:
1 static bool dma_m2m_filter(struct dma_chan *chan, void *param) 2 { 3 if (!imx_dma_is_general_purpose(chan)) 4 return false; 5 6 chan->private = param; 7 return true; 8 }
imx_dma_is_general_purpose 是一个特殊的函数,用于检查控制器驱动程序的名称。open函数将分配缓冲区并请求DMA通道,给定我们的回调过滤器函数:
1 int sdma_open(struct inode * inode, struct file * filp) 2 { 3 dma_cap_mask_t dma_m2m_mask; 4 struct imx_dma_data m2m_dma_data = {0}; 5 6 init_completion(&dma_m2m_ok); 7 /* 初始化功能 */ 8 dma_cap_zero(dma_m2m_mask); 9 dma_cap_set(DMA_MEMCPY, dma_m2m_mask); /* Set channel capacities */ 10 m2m_dma_data.peripheral_type = IMX_DMATYPE_MEMORY; /* choose the dma 11 device type. This is proper to i.MX */ 12 m2m_dma_data.priority = DMA_PRIO_HIGH; /* we need high priority */ 13 /* 分配一个DMA slave 通道 */ 14 dma_m2m_chan = dma_request_channel(dma_m2m_mask, dma_m2m_filter, 15 &m2m_dma_data); 16 if (!dma_m2m_chan) { 17 printk("Error opening the SDMA memory to memory channel\n"); 18 return -EINVAL; 19 } 20 21 wbuf = kzalloc(SDMA_BUF_SIZE, GFP_DMA); 22 if(!wbuf) { 23 printk("error wbuf !!!!!!!!!!!\n"); 24 return -1; 25 } 26 27 rbuf = kzalloc(SDMA_BUF_SIZE, GFP_DMA); 28 if(!rbuf) { 29 printk("error rbuf !!!!!!!!!!!\n"); 30 return -1; 31 } 32 33 return 0; 34 }
release函数与open函数完全相反;它释放缓冲区并释放DMA通道:
1 int sdma_release(struct inode * inode, struct file * filp) 2 { 3 dma_release_channel(dma_m2m_chan); 4 dma_m2m_chan = NULL; 5 kfree(wbuf); 6 kfree(rbuf); 7 return 0; 8 }
在read函数中,我们只是比较源和目标缓冲区,并将结果通知用户。
1 ssize_t sdma_read (struct file *filp, char __user * buf, 2 size_t count, loff_t * offset) 3 { 4 int i; 5 for (i=0; i<SDMA_BUF_SIZE/4; i++) { 6 if (*(rbuf+i) != *(wbuf+i)) { 7 printk("Single DMA buffer copy falled!,r=%x,w=%x,%d\n", 8 *(rbuf+i), *(wbuf+i), i); 9 return 0; 10 } 11 } 12 printk("buffer copy passed!\n"); 13 return 0; 14 }
我们使用completion是为了在事务终止时获得通知(唤醒)。这个回调函数在我们的事务完成后被调用,并将completion变量设置为complete状态:
1 static void dma_m2m_callback(void *data) 2 { 3 printk("in %s\n",__func__); 4 complete(&dma_m2m_ok); 5 return ; 6 }
在write函数中,我们用数据填充源缓冲区,执行DMA映射以获取与源和目标缓冲区对应的物理地址,并调用device_prep_dma_memcpy来获取事务描述符。然后用dmaengine_submit将该事务描述符提交给DMA引擎,它还不会执行我们的事务。只有在我们调用了dma_async_issue_pending待处理事务的DMA通道之后才会执行:
1 ssize_t sdma_write(struct file * filp, const char __user * buf, 2 size_t count, loff_t * offset) 3 { 4 u32 i; 5 struct dma_slave_config dma_m2m_config = {0}; 6 struct dma_async_tx_descriptor *dma_m2m_desc; /* transaction descriptor 7 */ 8 9 dma_addr_t dma_src, dma_dst; 10 11 /* No copy_from_user, we just fill the source buffer with predefined 12 data */ 13 for (i=0; i<SDMA_BUF_SIZE/4; i++) { 14 *(wbuf + i) = 0x56565656; 15 } 16 /* 设置 slave 和 controller 的具体参数 */ 17 dma_m2m_config.direction = DMA_MEM_TO_MEM; 18 dma_m2m_config.dst_addr_width = DMA_SLAVE_BUSWIDTH_4_BYTES; 19 dmaengine_slave_config(dma_m2m_chan, &dma_m2m_config); 20 21 dma_src = dma_map_single(NULL, wbuf, SDMA_BUF_SIZE, DMA_TO_DEVICE); 22 dma_dst = dma_map_single(NULL, rbuf, SDMA_BUF_SIZE, DMA_FROM_DEVICE); 23 dma_m2m_desc = 24 dma_m2m_chan->device->device_prep_dma_memcpy(dma_m2m_chan, dma_dst, 25 dma_src, SDMA_BUF_SIZE,0); //获取事务的描述符 26 if (!dma_m2m_desc) 27 printk("prep error!!\n"); 28 dma_m2m_desc->callback = dma_m2m_callback; 29 dmaengine_submit(dma_m2m_desc); //提交事务 30 dma_async_issue_pending(dma_m2m_chan); //发出挂起的DMA请求并等待回调通知 31 wait_for_completion(&dma_m2m_ok); //也可以使用wait_for_completion_timeout() 32 dma_unmap_single(NULL, dma_src, SDMA_BUF_SIZE, DMA_TO_DEVICE); //一旦DMA传输事务完成,我们所需要做的 33 dma_unmap_single(NULL, dma_dst, SDMA_BUF_SIZE, DMA_FROM_DEVICE); 34 35 return 0; 36 } 37 38 struct file_operations dma_fops = { 39 open: sdma_open, 40 release: sdma_release, 41 read: sdma_read, 42 write: sdma_write, 43 };
DMA DT绑定
DMA通道的DT绑定依赖于DMA控制器节点,该节点依赖于SoC,而且某些参数(如DMA单元)可能因SoC而异。这个例子只关注i.m xsdma控制器,你可以在内核源代码中找到它,文档/devicetree/bindings/dma/fsl-imx-sdma.txt。
消费者绑定
根据SDMA事件映射表,下面的代码显示了i.m x6dual / 6Quad中外设的DMA请求信号:
1 uart1: serial@02020000 { 2 compatible = "fsl,imx6sx-uart", "fsl,imx21-uart"; 3 reg = <0x02020000 0x4000>; 4 interrupts = <GIC_SPI 26 IRQ_TYPE_LEVEL_HIGH>; 5 clocks = <&clks IMX6SX_CLK_UART_IPG>, 6 <&clks IMX6SX_CLK_UART_SERIAL>; 7 clock-names = "ipg", "per"; 8 dmas = <&sdma 25 4 0>, <&sdma 26 4 0>; 9 dma-names = "rx", "tx"; 10 status = "disabled"; 11 };
DMA属性中的第二个单元格(25和26)对应于DMA请求/事件ID。这些值来自SoC手册(在我们的案例中是i.MX53)。请查看https:/ / community. nxp. com/ servlet/ JiveServlet/ download/ 614186- 1- 373516/ iMX6_Firmware_指南。和Linux参考手册https://community.nxp.com/servlet/JiveServlet/download/614186-1-373515/i.MX_Lin ux_Reference_Manual.pdf。
第三个单元格表示要使用的优先级。接下来定义请求指定参数的驱动程序代码。你可以在内核源代码树的drivers/tty/serial/imx.c中找到完整的代码:
1 static int imx_uart_dma_init(struct imx_port *sport) 2 { 3 struct dma_slave_config slave_config = {}; 4 struct device *dev = sport->port.dev; 5 int ret; 6 7 /* Prepare for RX : */ 8 sport->dma_chan_rx = dma_request_slave_channel(dev, "rx"); 9 if (!sport->dma_chan_rx) { 10 [...] /* cannot get the DMA channel. handle error */ 11 } 12 13 slave_config.direction = DMA_DEV_TO_MEM; 14 slave_config.src_addr = sport->port.mapbase + URXD0; 15 slave_config.src_addr_width = DMA_SLAVE_BUSWIDTH_1_BYTE; 16 /* one byte less than the watermark level to enable the aging timer */ 17 slave_config.src_maxburst = RXTL_DMA - 1; 18 ret = dmaengine_slave_config(sport->dma_chan_rx, &slave_config); 19 if (ret) { 20 [...] /* handle error */ 21 } 22 23 sport->rx_buf = kzalloc(PAGE_SIZE, GFP_KERNEL); 24 if (!sport->rx_buf) { 25 [...] /* handle error */ 26 } 27 28 /* Prepare for TX : */ 29 sport->dma_chan_tx = dma_request_slave_channel(dev, "tx"); 30 if (!sport->dma_chan_tx) { 31 [...] /* cannot get the DMA channel. handle error */ 32 } 33 34 slave_config.direction = DMA_MEM_TO_DEV; 35 slave_config.dst_addr = sport->port.mapbase + URTX0; 36 slave_config.dst_addr_width = DMA_SLAVE_BUSWIDTH_1_BYTE; 37 slave_config.dst_maxburst = TXTL_DMA; 38 ret = dmaengine_slave_config(sport->dma_chan_tx, &slave_config); 39 if (ret) { 40 [...] /* handle error */ 41 } 42 [...] 43 }
这里的神奇调用是 dma_request_slave_channel() 函数,它将根据DMA名称,使用 of_dma_request_slave_channel() 来解析设备节点(在DT中),以收集通道设置。
本文来自博客园,作者:闹闹爸爸,转载请注明原文链接:https://www.cnblogs.com/wanglouxiaozi/p/15045622.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号