工作笔记
总目录:
一、Log4j日志打印框架
目录 :
1、rootLogger根配置
2、log4j日志等级
3、log appender输出类型配置
4、layout格式
5、指定输出等级
log4j.rootLogger=debug,standard,Console
#standard
log4j.appender.standard = org.apache.log4j.RollingFileAppender
log4j.appender.standard.file = ./log/Client.log
log4j.appender.standard.MaxBackupIndex = 999
log4j.appender.standard.layout = org.apache.log4j.PatternLayout
log4j.appender.standard.layout.ConversionPattern = \n[%-5p] %d{yyyy-MM-dd HH\:mm\:ss,SSS} [%c{3}] %n%m%n
log4j.appender.standard.ThreadId=info//指定等级输出
log4j.appender.standard.Append= ture //当为false时会覆盖文件中原来的内容,默认为ture
#console
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=%d{ABSOLUTE} %-5p [%c{3}] %m%n
在测试、使用中:
public class test{ private static Logger logger=Logger.getLogger(Test.class); public static void Main(String arg[]){ logger.info("这是info",new exception("出错了!!")); } }
3、log appender输出类型配置
org.apache.log4j.ConsoleAppender(控制台)
org.apache.log4j.FileAppender(文件)
org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件)
org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件)
org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
log4j.appender.standard = org.apache.log4j.RollingFileAppender
4、layout格式
org.apache.log4j.PatternLayout(可以灵活地指定布局模式,重要),
org.apache.log4j.HTMLLayout(以HTML表格形式布局),
org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串),
org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
配置文件(栗子):
log4j.appender.Console=org.apache.log4j.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern =%d [%t] %-5p [%c] -%m%n
注:其中的%-5p 表示%p占5个字符长度,类似制表符,目的为使得输出格式一致。
- %c 输出日志信息所属的类的全名
- %d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyy-MM-dd HH:mm:ss },输出类似:2002-10-18- 22:10:28
- %f 输出日志信息所属的类的类名
- %l 输出日志事件的发生位置,即输出日志信息的语句处于它所在的类的第几行
- %m 输出代码中指定的信息,如log(message)中的message
- %n 输出一个回车换行符,Windows平台为“rn”,Unix平台为“n”
- %p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL。如果是调用debug()输出的,则为DEBUG,依此类推
- %r 输出自应用启动到输出该日志信息所耗费的毫秒数
- %t 输出产生该日志事件的线程名
5、指定输出等级
配置文件(栗子):
在每个输出位置的配置后追加:
log4j.appender.Console.ThreadId=info//或者其他等级,就只会输出该等级的日志
注:在指定时会有等级的层级关系
二、Redis
基本操作---笔记
主从复制:
搭建:
1、复制多个xxx.conf文件(在Linux中可用include)
2、修改日志文件
3、dbfilename dnmp.rdb
4、后台进程文件:pidfile redis80.pid
连接时 redis-cli -p port
认主机:slaveof 127.0.0.1 6379
注:成功后sync命令同步,使用redis-cli shutdown关闭服务器,否则数据会丢失
1、一仆二主
2、薪火相传
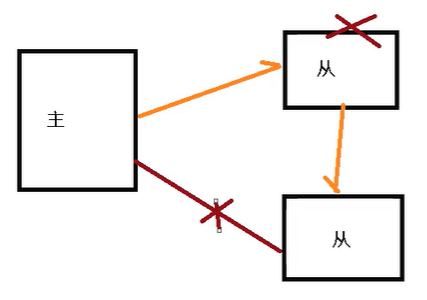
3、反客为主
当一个master当即后,后面的slave可以like升为master,其他后面的slave不用做任何修改。
slave no one //命令可以升为master,手动操作
4、哨兵模式(反客为主的自动版)
集群:
1、搭建(在这里6台服务器,一主一从。三个)
第一步:(搭建6个redis服务器)
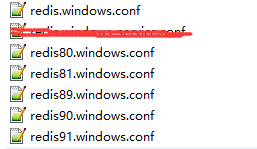
其中:(需要修改5个配置)
port:xxxx //端口号
dbfilename dumpXXX.rdb //数据文件

第二步:
启动6个集群(注意nodes-XXX.conf文件是否生成)
第三步:集群整合,其中1表示使用简单的配置方式
redis-cli --cluster create --cluster-replicas 1 10.1.112.85:6379 10.1.112.85:6380 10.1.112.85:6381 10.1.112.85:6389 10.1.112.85:6390 10.1.112.85:6391
或者
redis-cli --cluster create --cluster-replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6389 127.0.0.1:6390 127.0.0.1:6391
2、集群使用和故障修复
1、连接时使用 redis-cli -c -p 6379 //表示使用集群连接
2、cluster nodes //查看集群信息。当主节点宕机,从节点升为主节点,原主节点恢复,成为现主节点的从节点

3、cluster-require-full-coverage:yes //redis.conf配置中开启后,主从宕机后,集群宕机,否则只是该插槽不能用。
3、java使用集群
依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.3.1</version>
</dependency>
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
<version>5.1.8.RELEASE</version>
</dependency>
jedis:
public static void main(String[] args) { //集群 HashSet<HostAndPort> hostAndPorts = new HashSet<HostAndPort>(); hostAndPorts.add(new HostAndPort("10.1.50.207", 9001)); JedisCluster jedisCluster = new JedisCluster(hostAndPorts, "default","redis123"); // 单节点 // Jedis jedisCluster = new Jedis("10.1.50.207", 9001); // jedisCluster.auth("redis123"); Map<String, String> stringStringMap = jedisCluster.hgetAll("FRONT_R_TMNL_RUN:19980909"); for (Map.Entry<String, String> entry : stringStringMap.entrySet()) { System.out.println(entry.getKey()+":"+entry.getValue()); } }
Lettuce:
public static void main(String[] args) { RedisURI uri = RedisURI.builder().withHost("10.1.50.209").withPort(9001).withPassword("").build(); // RedisURI uri = RedisURI.builder().withHost("10.1.50.209").withPort(9001).withPassword("redis123").build(); ArrayList<RedisURI> redisURIS = new ArrayList<>(); redisURIS.add(uri); //非集群 RedisClient redisClient = RedisClient.create(uri);// <2> 创建客户端 StatefulRedisConnection<String, String> connection = redisClient.connect(); // <3> 创建线程安全的连接 RedisCommands<String, String> redisCommands = connection.sync(); // <4> 创建同步命令 //集群 RedisClusterClient redisClusterClient = RedisClusterClient.create(redisURIS); StatefulRedisClusterConnection<String, String> connect = redisClusterClient.connect(); RedisAdvancedClusterCommands<String, String> sync = connect.sync(); //相关命令 Map<String, String> hgetall = sync.hgetall("FRONT_R_TMNL_RUN:19980909"); for (Map.Entry<String, String> entry : hgetall.entrySet()) { System.out.println(entry.getKey() + ":" + entry.getValue()); } connection.close(); // <5> 关闭连接 redisClient.shutdown(); // <6> 关闭客户端 }
三、Mondodb(21/1/21---)
基本概念:数据库<---集合<---文档(数据库和集合都不用手动创建,在创建插入文档时,自动创建数据库和文档)
1、操作命令:
----基本操作
show dbs/collections - -展示所有的数据库/集合
db --展示当前所处的数据库
use dbname --进入(创建)dbname数据库
db.dropDatabase() --删除该数据库
db.createCollection("collName") --创建collName集合
db.collName.drop() --删除collName集合
----数据库CRUD(增删改查)操作
增
db.user.insert({name:"wang",age:21,sex:"man"}) --插入一条数据 wang 为collection ,
db.user.insertMany([{name:"wang",age:21,sex:"man"},{...},{..}.....]) --当插入多条数据时,添加多条文档时
将用中括号[ {... },{... },{ ...},... ]用逗号隔开
插入数据时会自动生成唯一_id,用来唯一确定一条数据,但是也可以指定
db.user.save({...}) --其用法与insert()相同,但是_id存在时insert会报错,但是save会将元数据覆盖。
db.user.insert({"name":"wanglala",friend:["wgy1","wgy"]}) --插入数组使用 [ ]
查
db.user.find({name:"wang"},{name:1,age:0}) --查询数据 wang 是被查询的collection ,{...}中为查询条件,
例如:name字段是“wang”,类似于where name="wang"
db.user.findOne({过滤条件}) --查询第一条数据
db.user.find({cj:{$gte:"60"}}) --大于小于等于等等等,判断符合使用.(pretty(),是分为多行输出,否则一行输出)
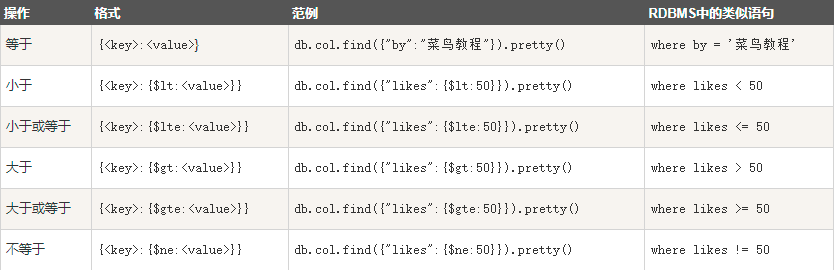
db.user.find({ cj:{$gte:"60"} , $or:[ {name:"wgy4"} , {name:"wgy3"} ] }) --or连接,
类似于select * from user where cj>"60" and (name="wgy4" or name="wgy3")
关于mongodb中数组:
db.user.find({friend:["wgy","wgy1"]}) --查找数组,数组元素必须为查询中的元素,不能少,且顺序不能颠倒(完全等于)
db.user.find( {friend: { $all:["wgy","123"] }} ) -- 增加$all ,表示被查的数组中有查询数组中的元素即可(必须全部都有,否则No)
db.user.find({num:{$gt:20,$lt:100}}) --数组中每个元素只满足一部分条件但加起来满足了所有条件
db.user.find({num:{$elemMatch:{$gt:20,$lt:100}}}) --数组中至少一个元素满足所有条件
db.user.find({"num.0":{$gt:20,$lt:100}}) --数组的下标为0的元素满足条件
db.user.find({num:{$size:8}}) --$size表示根据要求数组长度满足某条件
关于mongodb中时间:
db.user.insert({"time":new Date()}) --插入现在时间,但是因为时区原因会缺少8小时
db.user.insert({"time":new Date("2021-11-13T11:23:00Z")}) --自定义插入时间
改
db.user.update({"name":"wgy"},{"name":"wlala","age":23}) --覆盖原数据,前括号是查询条件,后括号是数据(其他数据清除)
db.user.update({"name":"wgy"},{$set:{"name":"wlala"}},{multi:true}) --修改原数据,第一个括号是查询条件,
第二个括号修改的字段名称和数据(其他数据不变),
第三个括号是是否修改多条(默认修改第一条数据)
db.user.update({name:"wanglala"},{$inc:{age:1}},{multi:true}) --$inc代表增加,age自增1,类似于set age=age+1;
db.user.replaceOne() --替换除_id属性外的所有属性,其参数应为一个全新的文档
删
db.user.remove({name:"wgy"}) --删除,删除多条,当没有条件书删除全部数据。
db.user.deleteMany(); --
db.user.deleteOne() --
聚合函数
aggregate() 方法:
db.user.aggregate([{ $group:{_id:"$cj",num:{$sum:1}} }]) -- _id必需写,根据后边的字段分组,结合其他函数使用(类似group by,sum类似count(*)算总行数)
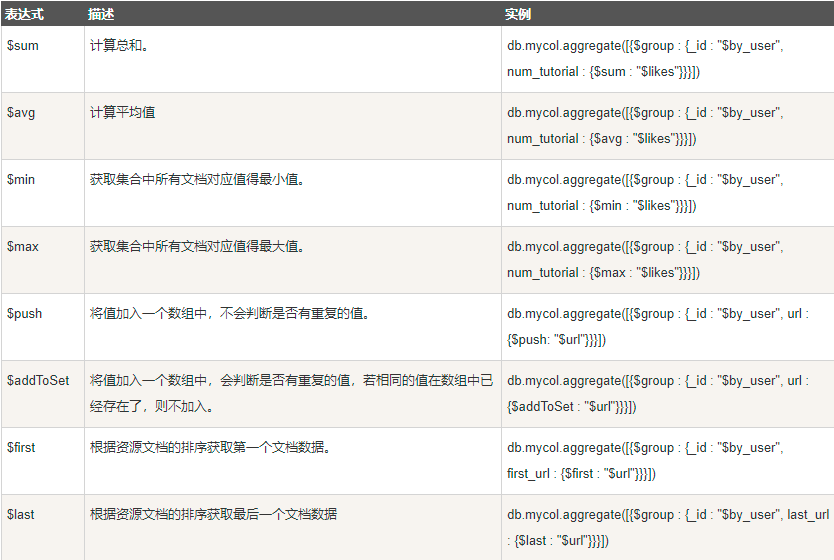
管道操作:
四、Spring Security
目录:
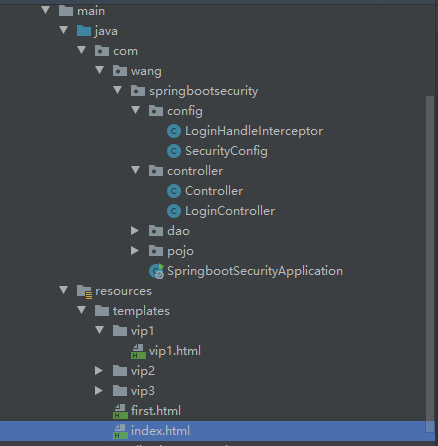
1、使用基本步骤
- 加入Maven依赖:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-security</artifactId> </dependency>
<dependency> <groupId>org.thymeleaf.extras</groupId> <artifactId>thymeleaf-extras-springsecurity4</artifactId> <version>3.0.4.RELEASE</version> </dependency>
- 编写SecurityConfig类
package com.wang.springbootsecurity.config; import org.springframework.security.config.annotation.authentication.builders.AuthenticationManagerBuilder; import org.springframework.security.config.annotation.web.builders.HttpSecurity; import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity; import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter; import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder; @EnableWebSecurity public class SecurityConfig extends WebSecurityConfigurerAdapter { @Override protected void configure(HttpSecurity http) throws Exception { //首页所有人可见,VIP页面不对外开放 http.authorizeRequests() .antMatchers("/").permitAll() .antMatchers("/vip1/**").hasRole("vip1") .antMatchers("/vip2/**").hasRole("vip2") .antMatchers("/vip3/**").hasRole("vip3"); //无权限到登录页面 http.formLogin().loginPage("/toLogin").loginProcessingUrl("/login"); //注销 http.logout().logoutSuccessUrl("/first"); //关闭防止网站工具 http.csrf().disable(); //记住我 http.rememberMe().rememberMeParameter("remember"); } @Override protected void configure(AuthenticationManagerBuilder auth) throws Exception { auth.inMemoryAuthentication().passwordEncoder(new BCryptPasswordEncoder()) .withUser("wang").password(new BCryptPasswordEncoder().encode("132456")).roles("vip1","vip2").and() .withUser("root").password(new BCryptPasswordEncoder().encode("132456")).roles("vip1","vip2","vip3").and() .withUser("yu").password(new BCryptPasswordEncoder().encode("132456")).roles("vip1"); } }
注:继承WebSecurityConfigurerAdapter,并加注解 @EnableWebSecurity
- Controller类
package com.wang.springbootsecurity.controller; import org.springframework.ui.Model; import org.springframework.web.bind.annotation.RequestMapping; import java.util.Arrays; @org.springframework.stereotype.Controller public class Controller { @RequestMapping("/vip1") public String vip1() { return "vip1/vip1"; } @RequestMapping("/vip2") public String vip2() { return "vip2/vip2"; } @RequestMapping("/vip3") public String vip3() { return "vip3/vip3"; } @RequestMapping({"/", "/first"}) public String first() { return "first"; } @RequestMapping({"/toLogin"}) public String toLogin() { return "index"; } }
- 登录界面
<!DOCTYPE html> <html lang="en"> <html xmlns:th="http://www.thymeleaf.org"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <h1>登录界面!!</h1> <form th:action="@{/login}" method="post"> <div>用户:</div><input name="username" type="text" value=""/> <br> <div>密码:</div><input name="password" type="password"/> <br> <input type="checkbox" name="remember"> <span>记住我!</span> <br> <input type="submit" value="提交!"> <br> <input type="reset" value="重置!"> <br> </form> </body> </html>
- 首页界面
<!DOCTYPE html> <html xmlns:th="http://www.thymeleaf.org" xmlns:sec="http://www.thymeleaf.org/thymeleaf-extras-springsecurity4"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <h1>首页</h1> <div sec:authorize="!isAuthenticated()"> <a th:href="@{/toLogin}">登录</a> </div> <div sec:authorize="isAuthenticated()"> <a th:href="@{/logout}">注销</a> </div> <div sec:authorize="isAuthenticated()"> <a> 用户名:<span sec:authentication="name"></span> <br> <!-- 角色:<span sec:authentication=""></span>--> </a> </div> <hr> <div sec:authorize="hasRole('vip1')"> <a href="/vip1">我是VIP1</a> <br> </div> <div sec:authorize="hasRole('vip2')"> <a href="/vip2">我是VIP2</a> <br> </div> <div sec:authorize="hasRole('vip3')"> <a href="/vip3">我是VIP3</a> </div> </body> </html>
2、使用问题
- 登出失败原因:
需要关闭防止网站工具 。在SecurityController类中加入
http.csrf().disable();
- 角色菜单动态改变
<div sec:authorize="hasRole('vip1')">
<a href="/vip1">我是VIP1</a> <br>
</div>
- 登出成功转向指定界面
http.logout().logoutSuccessUrl("/first");
- 定制登录界面
http.formLogin().loginPage("/toLogin").loginProcessingUrl("/login");
注:loginPage("/??")为转向的URL ,loginProcessingUrl("/login")为真正的登录url
五、Scheduler定时器(cron表达式用法)
1、首先下载quartz和slf4j依赖包
2、创建 任务、管理器器、启动器
(1)在任务中:
public class MyJob implements Job{ @Override public void execute(JobExecutionContext arg0) throws JobExecutionException { System.out.println("执行方法!需要执行的任务") } }
(2)管理器器中:
public class QuartzManage { private static SchedulerFactory gSchedulerFactory = new StdSchedulerFactory(); @SuppressWarnings("rawtypes") public static void addJob(String jobName, Class cls, String time) { System.out.println("进入管理器!"); try { // 创建调度器 Scheduler sched = gSchedulerFactory.getScheduler(); //定义一个工作对象 设置工作名称与组名 JobDetail job =JobBuilder.newJob(cls).withIdentity(jobName,"group1").build(); //定义一个触发器 简单Trigger 设置工作名称与组名 5秒触发一次 // Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1","group1").startNow().withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5)).build(); //定义一个任务调度的Trigger 这里可用CronSchedule格式 Trigger trigger = TriggerBuilder.newTrigger(). withIdentity("trigger1","group1") .withSchedule(CronScheduleBuilder.cronSchedule(time)).build(); //设置工作 与触发器 sched.scheduleJob(job, trigger); //开始定时任务 if(!sched.isShutdown()) { sched.start(); } } catch (Exception e) { throw new RuntimeException(e); } } }
(3)启动器
public class Start { public static String CallTime = "0 30 16 * * ?"; public static void main(String[] args) { try { QuartzManage.addJob("myTest", MyJob.class, CallTime); Thread.sleep(5000); } catch (Exception e) { e.printStackTrace(); } } }
其中的
 表示触发的时间
表示触发的时间
cron(CronTrigger)表达式用法
Cron Expressions的表达有7部分组成:
1、 Seconds(秒) :可以用数字0-59 表示
2、 Minutes(分) :可以用数字0-59 表示,
3、Hours(时) :可以用数字0-23表示,
4、Day-of-Month(天) :可以用数字1-31 中的任一一个值,但要注意一些特别的月份
5、Month(月) :可以用0-11 或用字符串 “JAN, FEB, MAR, APR, MAY, JUN, JUL, AUG, SEP, OCT, NOV and DEC” 表示
6、Day-of-Week(每周) :可以用数字1-7表示(1 = 星期日)或用字符口串“SUN, MON, TUE, WED, THU, FRI and SAT”表示
7、Year (可选字段)
特别的:
(1)
“/”:为特别单位,表示为“每”如“0/15”表示每隔15分钟执行一次,“0”表示为从“0”分开始, “3/20”表示表示每隔20分钟执行一次,“3”表示从第3分钟开始执行
“?”:表示每月的某一天,或第周的某一天
“L”:用于每月,或每周,表示为每月的最后一天,或每个月的最后星期几如“6L”表示“每月的最后一个星期五”
“W”:表示为最近工作日,如“15W”放在每月(day-of-month)字段上表示为“到本月15日最近的工作日”
““#”:是用来指定“的”每月第n个工作日,例 在每周(day-of-week)这个字段中内容为"6#3" or "FRI#3" 则表示“每月第三个星期五”
(2)
Cron表达式的格式:秒 分 时 日 月 周 年(可选)。
字段名 允许的值 允许的特殊字符
秒 0-59 , - * /
分 0-59 , - * /
小时 0-23 , - * /
日 1-31 , - * ? / L W C
月 1-12 or JAN-DEC , - * /
周几 1-7 or SUN-SAT , - * ? / L C #
年 (可选字段) empty, 1970-2099 , - * /
“?”字符:表示不确定的值
“,”字符:指定数个值
“-”字符:指定一个值的范围
“/”字符:指定一个值的增加幅度。n/m表示从n开始,每次增加m
“L”字符:用在日表示一个月中的最后一天,用在周表示该月最后一个星期X
“W”字符:指定离给定日期最近的工作日(周一到周五)
“#”字符:表示该月第几个周X。6#3表示该月第3个周五
(栗子)
每隔5秒执行一次:*/5 * * * * ?
每隔1分钟执行一次:0 */1 * * * ?
每天23点执行一次:0 0 23 * * ?
每天凌晨1点执行一次:0 0 1 * * ?
每月1号凌晨1点执行一次:0 0 1 1 * ?
每月最后一天23点执行一次:0 0 23 L * ?
每周星期天凌晨1点实行一次:0 0 1 ? * L
在26分、29分、33分执行一次:0 26,29,33 * * * ?
每天的0点、13点、18点、21点都执行一次:0 0 0,13,18,21 * * ?
七、Flink(2022-1-18----)
Flink是一个框架和分布式的处理引擎,用于对无界和有界数据流进行状态计算
1、meven仓库
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.10.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.12</artifactId> <version>1.10.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka-0.11_2.12</artifactId> <version>1.10.1</version> </dependency>
2、获取流
主方法:
public static void main(String[] args) throws Exception {
//获取流环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1、从kafka消费数据流
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", "localhost:9092");
kafkaProps.put("acks", "all");
kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
DataStream<String> kafkaDataStream = env.addSource(
new FlinkKafkaConsumer011<String>("topic_test", new SimpleStringSchema(), kafkaProps)
);
//2、从集合中获取数据流
DataStream<Per> arrayDataStream= env.fromCollection(Arrays.asList(
new Per("wgy", 12345L, 80.3),
new Per("wgy2", 12346L, 70.3),
new Per("wy", 12348L, 93.8),
new Per("wgy3", 12347L, 83.3)
));
//3、自定义数据流
DataStream<String> myDataStream = env.addSource(new MySource());
//4、从文件中读取数据流
String path="D:\\ideaTest\\src\\main\\resources\\test.txt";
DataStream<String> fileDataSource = env.readTextFile(path);
//flatMap操作,之后详述
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = kafkaDataStream
.flatMap(new MyFlatMapper())
.keyBy(0)
.sum(1);
//输出相关信息
sum.print();
myDataStream.print();
//执行操作
env.execute();
}
MyFlatMapper.java(flatMap操作)
public class MyFlatMapper implements FlatMapFunction<String, Tuple2<String,Integer>> {
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = s.split(" ");
for(String word:words){
collector.collect(new Tuple2<String, Integer>(word,1));
}
}
}
MySource.java(自定义数据流)
public class MySource implements SourceFunction<String> {
public void run(SourceContext<String> sourceContext) throws Exception {
while (true){
sourceContext.collect("123");
sleep(1000);
}
}
public void cancel() {
}
}
3、转换算子
(1)map_映射
可以使用lanmbda,也可以实现MapFunction<T,O>接口,其中T为传入参数的类型,O为输出参数的类型
kafkaDataStream.map(new MapFunction<String,Per>(){ @Override public Per map(String info) throws Exception { Per per = new Per(); per.setName(info); return per; } }).print();
(2)flatMap_扁平映射
如上MyFlatMapper.java文件,实现FlatMapFunction<T, O>接口即可,其中T泛型为传入参数的类型,O为输出参数,与map极其相似。区别在于,map输入一个只会输出一个结果,flatMap输入一个会得到0个、1个或者多个结果。flatMap()方法返回类型是Collector<O> var2,是一个集合。
kafkaDataStream.flatMap(new FlatMapFunction<Per, String>(){ public void flatMap(Per per, Collector<String> collector) throws Exception { for(char c:per.getName().toCharArray()){ collector.collect(String.valueOf(c)); } } }).print();
(3)Filter_过滤
实现FilterFunction<T>接口,返回true留下,false丢弃。生成的新数据库和元数据流的数据类型是相同的。
kafkaDataStream.filter(new FilterFunction<Per>() { @Override public boolean filter(Per per) throws Exception { String name = per.getName(); return !name.equals("wgy"); } }).print();
(4)聚合算子
1、按键分区(KeyBy):总的来说一共分为三类:1、Tuple 2、POJO类 3、键选择器(KeySeletor),示例:
//Tuple选择 dataStream.keyBy(1); //对POJO使用属性名聚合 dataStream.keyBy("f0"); //使用键选择器聚合 dataStream.keyBy(new KeySelector<Tuple3<String, Double, Per>, String>() { @Override public String getKey(Tuple3<String, Double, Per> tuple3) throws Exception { return tuple3.f0; } });
2、简单聚合:概括有
sum() :对指定的字段叠加,是指把指定的字段叠加的分组中,其他字段均取自第一个值。
min()、minBy() :取最小值,两者区别是,前者其他字段保留第一个数值,后者会返回最小值的整条数据。
max()、maxBy():同上。
keyedStream.print("输入结果:");
keyedStream.minBy("f1").print("聚合结果(方式1):");
keyedStream.sum(1).print("聚合结果(方式2):");
3、归约聚合(reduce)
更高级的聚合,第一条数据到达时仅仅更新累加器的值并不会执行reduce()方法,当第二条数据到达时会执行代码。
keyedStream.reduce(new ReduceFunction<Tuple3<String, Double, Per>>() { @Override public Tuple3<String, Double, Per> reduce(Tuple3<String, Double, Per> tuple3, Tuple3<String, Double, Per> t1) throws Exception { return Tuple3.of(t1.f0,tuple3.f1+t1.f1,t1.f2); } }).print();
注:方法中的第一个参数是累加器中的值,第二个参数是最新到达数据。
(5)多流转换算子
//状态描述器 MapStateDescriptor broadcast = new MapStateDescriptor("notice", Types.STRING, TypeInformation.of(pojo.class)); //生成广播流 BroadcastStream<Tuple2<String, pojo>> broadcastStream = env .addSource(notic) .flatMap(new CfgNoticeFlatMapFunction()) .broadcast(broadcast); //将广播流和任务流合流 env.addSource(message) .flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception { System.out.println("this a message "); } }) .connect(broadcastStream) .process(new BroadcastProcessFunction()).setParallelism(3);
分流:
SplitStream<Per> split = stream.split(new OutputSelector<Per>() { @Override public Iterable<String> select(Per s) {//返回类型为迭代器,即集合类均可(List、Set) List<String> list = new ArrayList<>(); if(s.getCj() > 5 ){ list.add("nb"); }else{ list.add("Unnb"); } return list; } });
合流:
1、connect之后跟 .map合流(MapFunction、FlatMapFunction等)
DataStream<Per> nb = split.select("nb");//获取第一条流
SingleOutputStreamOperator<Tuple2<String, Double>> map = nb.map(new MapFunction<Per, Tuple2<String, Double>>() {
@Override
public Tuple2<String, Double> map(Per per) throws Exception {
return new Tuple2<String, Double>(per.getName(), per.getCj());
}
});//获取第二条流,注意在这里的两条流类型不同
ConnectedStreams<Tuple2<String, Double>, Per> connect = map.connect(nb);//获取连接,连接上边的两条流,返回的类型中为两条流的返回类型
SingleOutputStreamOperator<Object> map1 = connect.map(new CoMapFunction<Tuple2<String, Double>, Per, Object>() {//此处的Object是合并的流返回类型
@Override
public Object map1(Tuple2<String, Double> value) throws Exception {
return new Tuple3<>(value.f0, value.f1, "这孩子打小就行!");
}
@Override
public Object map2(Per per) throws Exception {
return new Tuple2<>(per.getName(), "这孩子...哎!!");
}
});
2、connect之后跟 .process合流
SingleOutputStreamOperator<String> a = userInfo .connect(messageInfo) .process(new CoProcessFunction<Message, Message, String>() { private Map<String, Tuple2<String, LocalDateTime>> infoMap; private Boolean timerFlag = false; @Override public void open(Configuration parameters) throws Exception { super.open(parameters); infoMap = new HashMap<>(); timerFlag = true; } @Override public void processElement1(Message message, Context ctx, Collector<String> out) throws Exception { infoMap.put(message.getKey(), Tuple2.of(message.getValue(), LocalDateTime.now())); if (timerFlag) { timerFlag = false; //开启定时 ctx.timerService().registerProcessingTimeTimer(System.currentTimeMillis() + 10000); } } @Override public void processElement2(Message message, Context context, Collector<String> out) throws Exception { if (infoMap.containsKey(message.getKey())) { Tuple2<String, LocalDateTime> userInfo = infoMap.get(message.getKey()); out.collect(userInfo.f0 + message.getValue()); userInfo.f1 = LocalDateTime.now(); } else { out.collect("没有对应相关消息"); } } @Override public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception { LocalDateTime now = LocalDateTime.now(); Iterator<Map.Entry<String, Tuple2<String, LocalDateTime>>> it = infoMap.entrySet().iterator(); while (it.hasNext()) { String id = it.next().getKey(); Tuple2<String, LocalDateTime> userInfo = infoMap.get(id); if (now.isAfter(userInfo.f1.plusSeconds(5))) { it.remove(); out.collect(userInfo.f0 + "很长时间没说话了,把它移除"); } } //继续定时循环 ctx.timerService().registerProcessingTimeTimer(System.currentTimeMillis() + 10000); } });
注:要想进行定时器操作,两流合并前要keyBy操作,否则报错。
3.union
DataStream<Per> nb = split.select("nb");//获取第一条流
DataStream<Per> Unnb = split.select("Unnb");//获取第二条流
DataStream<Per> union = nb.union(Unnb);//联合为一跳流
union.print();
注意:connect只能连接两条流,但是两条流返回类型可以为不同类型的 ,在map1和map2中分别处理
union可以连接多条流,如 DataStream<Per> union = nb.union(Unnb); ,但是返回类型必须一致,否则报错。
(6)广播流
//状态描述器 MapStateDescriptor broadcast = new MapStateDescriptor("notice", Types.STRING, TypeInformation.of(pojo.class)); //生成广播流 BroadcastStream<Tuple2<String, pojo>> broadcastStream = env .addSource(notic) .flatMap(new CfgNoticeFlatMapFunction()) .broadcast(broadcast); //将广播流和任务流合流 env.addSource(message) .flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception { System.out.println("this a message "); } }) .connect(broadcastStream) .process(new BroadcastProcessFunction()).setParallelism(3);
/** *广播 */ public class BroadcastProcessFunction extends org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction<Tuple2<String, pojo>,Tuple2<String, pojo>,String> { public void processElement(Tuple2<String, pojo> tuple2, ReadOnlyContext readOnlyContext, Collector<String> collector) throws Exception { System.out.println("this is a Taskcast:"+tuple2.f1); } public void processBroadcastElement(Tuple2<String, pojo> tuple2, Context context, Collector<String> collector) throws Exception { System.out.println("this is a processBroadcast:"+tuple2.f1.toString()); } }
(7)开窗
时间窗口:
TumblingProcessingTimeWindows w = TumblingProcessingTimeWindows.of(Time.seconds(5)); env.addSource(message) .flatMap(new FlatMapFunction<String, Integer>() { public void flatMap(String record, Collector<Integer> out) { out.collect(record.length()); } }) .keyBy(t->t.toString())//开窗时,必须要使用keyby .window(w) // .windowAll(w) .process(new TestProcessWindowFunction()).setParallelism(3);
public class TestProcessWindowFunction extends ProcessWindowFunction<Integer,Integer,String,TimeWindow> { // public class TestProcessWindowFunction extends ProcessAllWindowFunction<Integer,Integer,TimeWindow> {//不分线程窗口,没有key private int num=0; public void process(String key, Context context, Iterable<Integer> iterable, Collector<Integer> collector) throws Exception { Iterator<Integer> iterator = iterable.iterator(); num++; System.out.println("第"+num+"次轮训窗,key:"+key); while (iterator.hasNext()) System.out.println("ss:"+iterator.next()); } // public void process(Context context, Iterable<Integer> iterable, Collector<Integer> collector) throws Exception { // num++; // System.out.println("第"+num+"次轮训窗口"); // Iterator<Integer> iterator = iterable.iterator(); // while (iterator.hasNext()) // System.out.println("ss:"+iterator.next()); // } }
注:当使用windowAll时不需要keyby,所有数据会汇到同一个线程中。
计数窗口:
FlinkKafkaConsumer011<String> message = new FlinkKafkaConsumer011<String>("message", new SimpleStringSchema(), kafkaProps); TumblingProcessingTimeWindows w = TumblingProcessingTimeWindows.of(Time.seconds(5)); env.addSource(message) .keyBy(t->t) .countWindow(3) // .countWindowAll(3) .apply(new CountProcessWindowFunction()); env.execute();
public class CountProcessWindowFunction implements WindowFunction<String, Integer,String, GlobalWindow> { // public class CountProcessWindowFunction implements AllWindowFunction<String, Integer, GlobalWindow> {//全部汇总到一个窗口 private int num = 0; public void apply(String s, GlobalWindow globalWindow, Iterable<String> iterable, Collector<Integer> collector) throws Exception { num++; System.out.println("第" + num + "次轮训窗,key:" + s); iterable.forEach(lengh -> System.out.println("ss:" + lengh)); } // public void apply(GlobalWindow globalWindow, Iterable<String> iterable, Collector<Integer> collector) throws Exception { // num++; // System.out.println("第" + num + "次轮训窗" ); // iterable.forEach(lengh -> System.out.println("ss:" + lengh)); // } }
滑动窗口:
.countWindow(5, 3)
4、Sink
//1、sink到kafka stream.addSink(new FlinkKafkaProducer011<String>("localhost:9092","test",new SimpleStringSchema())); //2、sink到Redis //3、sink到JDBC env.execute();

 浙公网安备 33010602011771号
浙公网安备 33010602011771号