第一次个人编程作业
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 第一次个人编程作业 |
| 这个作业的目标 | 实现论文查重算法,掌握PSP的记录,Git的提交,单元测试 |
1.作业GitHub链接
https://github.com/Binezis/3121005099
2.PSP表格
| PSP2.1 | ersonal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 600 | 435 |
| Development | 开发 | 310 | 370 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 30 |
| · Design Spec | · 生成设计文档 | 20 | 25 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| · Design | · 具体设计 | 15 | 20 |
| · Coding | · 具体编码 | 100 | 120 |
| · Code Review | · 代码复审 | 30 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 100 | 120 |
| Reporting | 报告 | 40 | 45 |
| · Test Repor | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 10 |
| · 合计 | 106 | 380 | 435 |
3.模块接口的设计与实现过程
代码的模块接口设计与实现过程可以分为以下几个步骤,包括模块的组织、类与函数的定义、模块之间的关系、关键函数的算法描述以及是否需要绘制流程图。
1. 模块组织
首先,将代码组织成一个主模块(例如,命名为main.py),并将相关函数和常量放在这个主模块中。可以使用其他模块来封装相关功能,但在这种小型脚本中,可以将所有功能集中在主模块中。
2. 类与函数的定义
在主模块中,定义了以下函数和类:
- getSimhash(keyword):计算Simhash值的函数。
- get_similarity(orig_hash, copy_hash):计算两个Simhash值之间相似度的函数。
- subWord(text, loc):对文本进行分词、处理的函数。
- read_path():从命令行读取文件路径的函数。
- output_result(result_path, similarity):将相似度结果写入输出文件的函数。
- process(orig_path, copy_path, result_path, loc):查重过程的函数。
- main():主函数,是程序的入口点。
3. 模块之间的关系
主要模块之间的关系如下:
- main() 函数是程序的入口,它调用了 read_path() 函数来获取文件路径,然后调用 process() 函数进行查重操作。
- process() 函数内部调用了 subWord() 函数来分词和处理原始文本和抄袭文本。
- getSimhash() 函数用于计算Simhash值,并且在 process() 中被调用。
- get_similarity() 函数用于计算相似度,同样也在 process() 中被调用。
- output_result() 函数用于将结果写入输出文件,也在 process() 中被调用。
4. 关键函数算法描述
- getSimhash(keyword):该函数的关键在于计算每个关键词的Simhash值,并根据权重合并这些值。它对文本进行分词,并使用MD5哈希算法计算每个词的哈希值,然后根据词频和权重进行合并。
- get_similarity(orig_hash, copy_hash):该函数的算法关键在于计算两个Simhash值之间的汉明距离,并将汉明距离转化为相似度百分比。
- subWord(text, loc):该函数关键在于文本的分词和中文字符的正则表达式过滤。
- process(orig_path, copy_path, result_path, loc):该函数是整个查重流程的核心,将文件的路径传递给其他函数,执行查重操作。
- 流程图
graph LR
A[Input: Original and Copied Text Paths] --> B[Read Paths]
B --> C[Process Documents]
C --> D[SubWord - Preprocess Text]
D --> E[Get Simhash]
E --> F[Calculate Similarity]
F --> G[Output Result]
style A fill:#77DD77,stroke:#000000;
style B fill:#77DD77,stroke:#000000;
style C fill:#77DD77,stroke:#000000;
style D fill:#77DD77,stroke:#000000;
style E fill:#77DD77,stroke:#000000;
style F fill:#77DD77,stroke:#000000;
style G fill:#77DD77,stroke:#000000;
总体来说,这个代码的独到之处在于它使用Simhash算法来计算文本相似度,同时还包含了文本预处理和中文分词的功能,使得对中文文本的查重更加准确。此外,它还通过命令行参数接受文件路径,使得代码可以方便地用于不同的文本查重任务。这种组织方式使得代码结构清晰,易于维护和扩展。
4.模块接口部分的性能改进
性能分析图
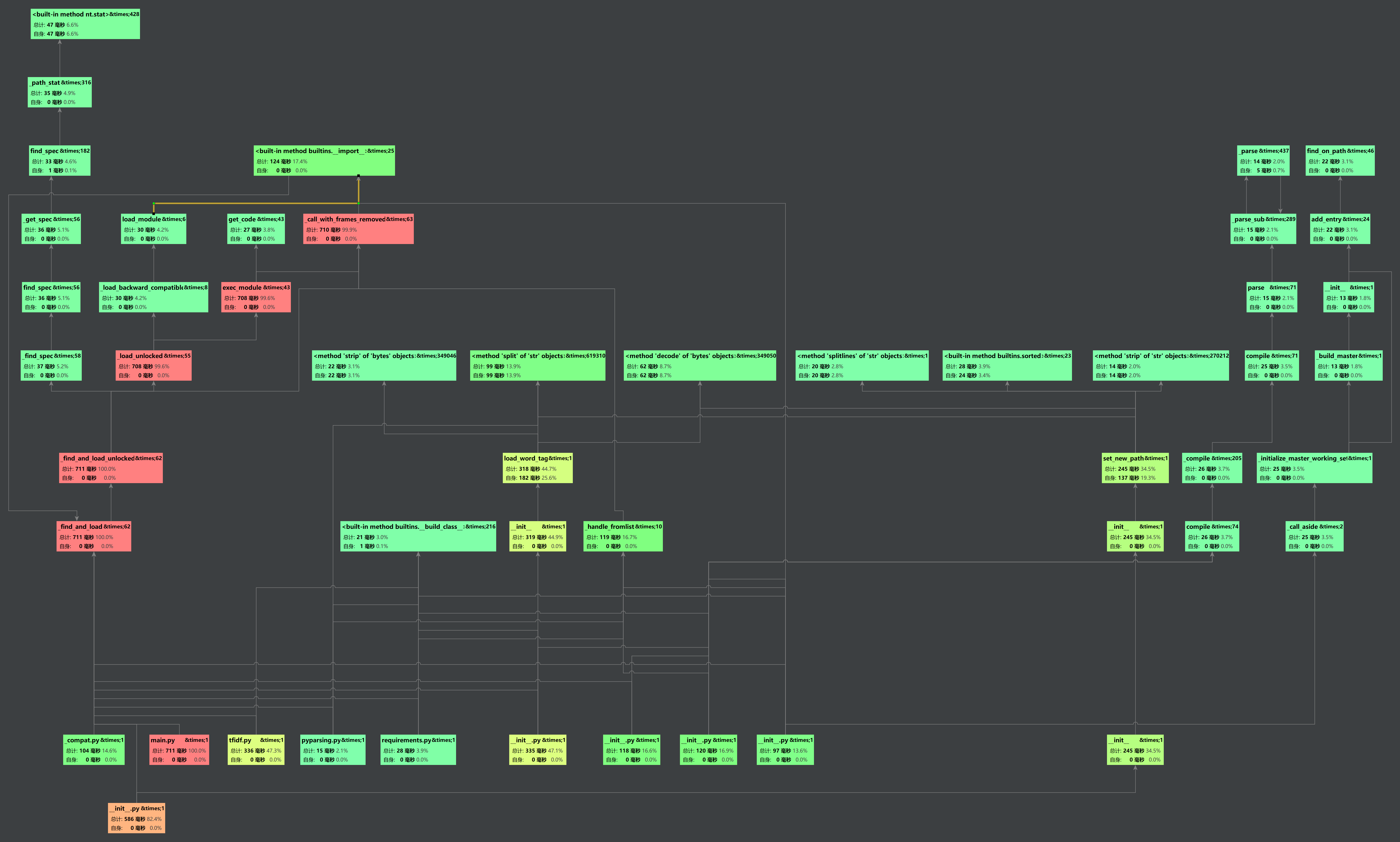
对于性能改进,我将关注以下几个方面:
1.文本处理优化:在代码中,文本处理的部分主要是subWord函数,其中包括文本分词和正则表达式处理。为了提高性能,可以考虑以下改进:
- 使用缓存:将已经分词过的文本保存到缓存中,以避免重复分词相同的文本。
- 异步处理:如果处理大量文本,可以考虑使用异步处理来提高处理速度。
2.Simhash计算优化:getSimhash函数用于计算Simhash值,可以尝试以下改进:
- 并行计算:如果有多个文本需要处理,可以使用并行计算来加速Simhash计算。
- 优化哈希计算:考虑使用更快的哈希算法或者对MD5计算进行批量化以提高效率。
5.模块部分单元测试展示
项目部分单元测试代码
- test_subWord_none:测试文件路径未输入的情况
def test_subWord_none(self):
orig_path = ""
copy_path = ""
result_path = ""
loc = locals()
self.assertEqual(subWord(orig_path, loc), FileNotFoundError)
2.test_getSimhash:测试获得的simhash是否为01字符串
def test_getSimhash(self):
orig_path = "text/orig.txt"
copy_path = ""
result_path = ""
loc = locals()
key_word = subWord(orig_path, loc)
simhash = getSimhash(key_word)
for i in simhash:
self.assertIn(i, ('0', '1'))
3.test_output_result:测试输出
def test_output_result(self):
result_path = "text/test_result.txt"
result = output_result(result_path, 0.8)
self.assertEqual(result, None)
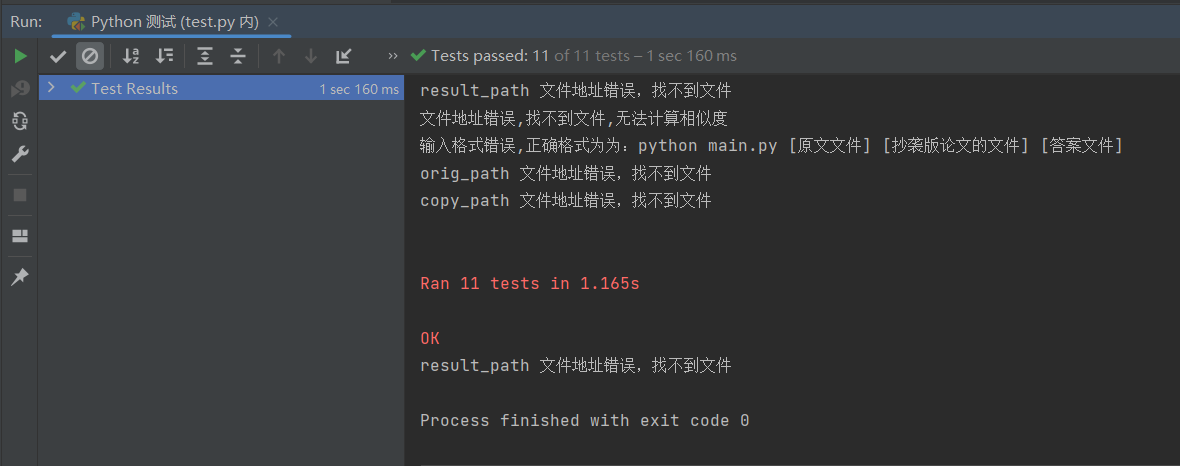
测试结果
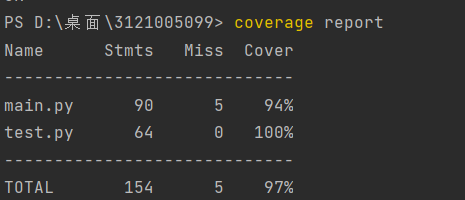
测试覆盖率
6.模块部分异常处理说明
1.参数输入不全,导致异常
try:
orig_path = sys.argv[1]
copy_path = sys.argv[2]
result_path = sys.argv[3]
except IndexError:
print('输入格式错误,正确格式为为:python main.py [原文文件] [抄袭版论文的文件] [答案文件]')
return IndexError
对应单元测试:
def test_read_path_none(self):
self.assertEqual(read_path(), IndexError)
2.参数输入错误,路径找不到,打不开文件导致异常
try:
file = open(text, 'r', encoding='utf-8')
seg_text = file.read()
except FileNotFoundError:
for key in loc:
if loc[key] == text:
print(key, "文件地址错误,找不到文件")
return FileNotFoundError
对应单元测试:
def test_subWord_none(self):
orig_path = ""
copy_path = ""
result_path = ""
loc = locals()
self.assertEqual(subWord(orig_path, loc), FileNotFoundError)
3.输出答案到文本中由于路径输入错误或,文件已打开造成的异常
try:
result_file = open(result_path, 'w', encoding='utf-8')
except (FileNotFoundError, PermissionError):
print('输出文件路径错误')
return FileNotFoundError, PermissionError
对应单元测试:
def test_output_result_none(self):
result_path = ""
result = output_result(result_path, 0.8)
self.assertEqual(result, (FileNotFoundError, PermissionError))
4.由于参数输入不全,导致返回值无法赋值异常
try:
orig_path, copy_path, result_path = read_path()
except TypeError:
return TypeError
对应单元测试:
def test_parm_none(self):
self.assertEqual(main(), TypeError)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号