

python 处理数据的一些记录
最近莫名其妙同时处于浑浑噩噩和工作到深夜两个状态,当然干的还是男朋友的工作,至于我自己的学业,可能已经毁了吧。
在给他整理数据过程中,学习到一些技巧,这边记录下来,不然以后又要忘记。
我写代码太喜欢复制粘贴,导致后来连最简单的打开文件都不会写,我现在在有意改正这个习惯,多手打几次,希望能记住吧。
1.按照某一列的值,分组,fillna
有这个需求是因为这个数据是以年和公司名作为一行记录的关键词,就是一个公司的好几年为一段,然后又是下一个公司的好几年,年数也不固定。这时有一个值,把之前记录的结果匹配上来之后,出现了某几年有结果,某几年是空值。因为这个指标是累加值,所以某个公司如果有值,后面就不应该有空值,就应该按照之前的值填充。但是也有可能这个公司就是没有这个指标,那就都是nan。
数据大概长这样:
图一:关键字
图二:原来的数据
图三:处理结果



我想了一下这个怎么实现,众所周知,我是编程婴儿,我大概只能想到疯狂写 while 循环和 if 来把这一列填充好,但是感觉好烦,这个逻辑还得想一下。
后来我想到 fillna 好像有可以按上一个值填充的方法,但是网上没有分组 fillna 填充的。
我又百度,怎么样按某一列的值,把一个 dataframe 分成很多 dateframe ,然后再 fillna, 然后再合并到一起。
下面是我的代码:
classinformation=match_0619['conm'].unique() #先把公司名'conm'那一列不重复的名单弄出来一份 #print(classinformation) df=[] for temp_classinformation in classinformation: temp_data=match_0619[match_0619['conm'].isin([temp_classinformation])] #判断公司名在不在那个名单里,这种代码我就根本不会写,唉 df.append(temp_data) #把这个小dataframe加到大dataframe里 #exec("df%s=temp_data"%temp_classinformation)
#原本网上的代码是直接把这些输出为很多个小dataframe,然后命名为df1,df2,df3...,我这边运行的时候总出错,而且我也不需要这样,算了。其实我很想学这个功能,我到现在都不会写变量名怎么变化。以后有机会学习吧
patent_num=[]
for i in range (0,len(df)):
a=df[i]['累积到当年总专利数'].fillna(method='ffill') #ffill 就是向前取值填充空值,我只想填充这一列,本来想能不能整个表只填充这一列,然后把表合并起来就行。没做到,还是把这列取出来做,然后弄完之后,整列再放回去。
patent_num.append(a)
match_patent_cum= pd.concat(patent_num) #大dataframe 里面很多小dataframe,就这样合并,这还是之前分块导入数据的时候学会的。编程婴儿在成长。返回再把这一列放回去就好了。
如果有人搜到我的博客想找解决办法,我现在这道歉,我写这些是为了自己记录的,很乱,不容易参考,对不起!
2.一行数据里包含好几个数据, 把这一行变成几行,还要带上别的指标
这个功能我之前手动做过,因为真的不想想怎么编程,宁愿做苦工。结果做完之后,用来匹配的名单有一点改动,之前做的就白做了。不知道我这是何必,好好研究编程其实很快。这里讲一句金句:人必须懒,不懒就不会进步。
下面图1是处理前的数据,第二列这一列很烦,有很多,而且数量不定。
图2是结果,分成一行一行的了。 里面那个level_3是说明这一列是第几个数据。
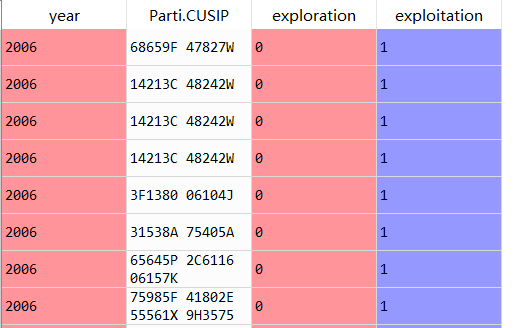
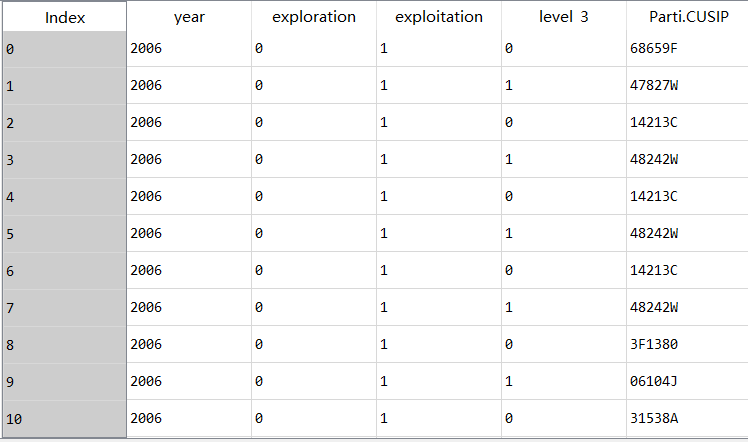
这是我的代码:
dft = (t.set_index(['year','exploration', 'exploitation'])[ 'Parti.CUSIP']
.str.split(' ', expand=True)
.stack() .reset_index(name='Parti.CUSIP'))
#其实我这边到现在还是没有完全懂这个代码的写法,不知道 set_index 括号外面再写个方括号是什么意思
一步一步试试,分解开看看:
数据一开始长这样:
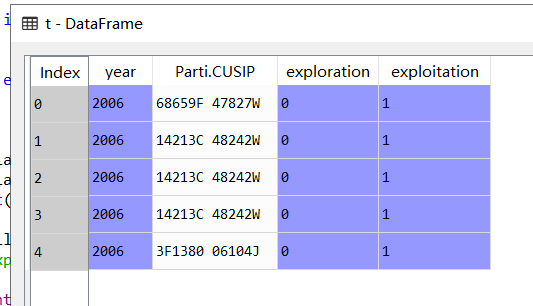
第一步:s=t.set_index(['year','exploration', 'exploitation'])[ 'Parti.CUSIP']
结果:
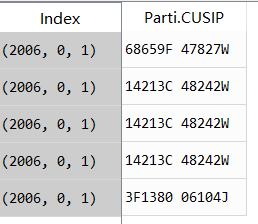
就是把括号里面那几列变成一个index,括号外面是值
set_index():https://www.cnblogs.com/lichunl/p/9285464.html
第二步:r=s.str.split(' ', expand=True)
结果:

就是把一列列成几列,这个excel也能做。
第三步:c=r.stack()
结果:

stack():https://www.jianshu.com/p/74ac592b95c9
stack就是栈,在这就是把他拉开,我是这么理解的。其实感觉这个好像很复杂,之前学最基础知识的时候,就不太懂这个。看看别人写的:

-
表格在行列方向上均有索引,花括号结构只有“列方向”上的索引。
-
其实,应用stack和unstack只需要记住下面的知识点即可:
- stack: 将数据从”表格结构“变成”花括号结构“,即将其列索引变成行索引。
- unstack: 数据从”花括号结构“变成”表格结构“,即要将其中一层的行索引变成列索引。如果是多层索引,则以上函数是针对内层索引(这里是store)。利用level可以选择具体哪层索引。
第四步:e=c.reset_index(name='Parti.CUSIP')
结果:就是最终结果
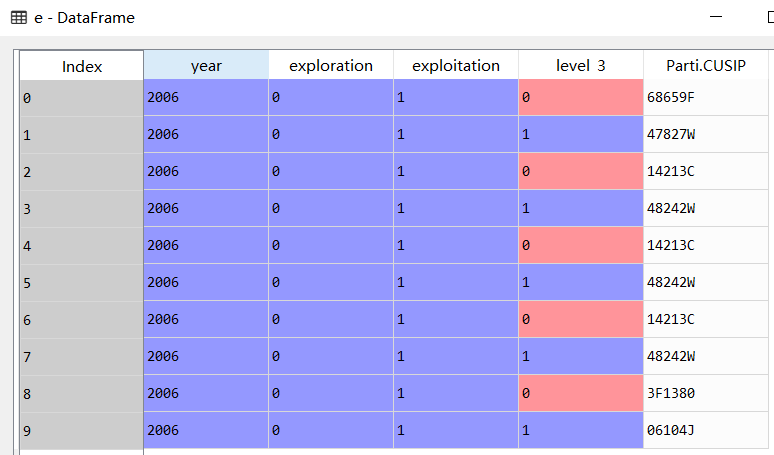
我不知道 reset_index(name='Parti.CUSIP') 这么厉害,这就是重新加一个索引,然后命名内容那一列?前面那几个的列名居然还在?
reset_index可以还原索引,从新变为默认的整型索引
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill=”)
level控制了具体要还原的那个等级的索引
drop为False则索引列会被还原为普通列,否则会丢失
本来网上的代码里有一个 level=2,还有drop,我删掉了,不然我的数据会少一列。当时就是懵懂着改的,现在才知道为什么。
我经常用 reset_index()这个函数,但是我居然到今天才知道这个函数里的参数什么意思。
3.dataframe重命名
这个功能简单到我都不好意思写在这,我经常用这个,但是还是记不住怎么写。
colNameDict = { 'year':'fyear', '公司名':'conm', } cited_results.rename(columns = colNameDict,inplace=True)
4.按某列的值分段求累加和
这是我自己写的,记录一下,不知道很厉害的人看到我的代码会不会觉得很可笑。我好可怜,越编程越自卑。
patent_num_year=patent_num_year.sort_index(axis=0,by=['上市公司数据库公司名','year'],ascending=True).reset_index(drop=True) patent_num_cum=[] for i in range(0,len(patent_num_year)): y=patent_num_year.iloc[i,1] if i ==0: s=patent_num_year.iloc[i,2] patent_num_cum.append(s) if i>0: if patent_num_year.iloc[i,0]==patent_num_year.iloc[i-1,0]: s=s+patent_num_year.iloc[i,2] patent_num_cum.append(s) else: s=patent_num_year.iloc[i,2] patent_num_cum.append(s)
还用到什么新的数据处理功能,现在也想不起来了,好像没了。最经常用的也就是 pd.merge , groupby ,其实不难,是我比较弱,做起来磕磕绊绊的。
每次完成编程任务后,学习到新技能的欣喜和完成任务的成就感加起来有五分,而挫败感也有五分。
永远都觉得自己会的这一点点东西只是整个知识海洋里的一滴水,不会的东西太多了。是不是有一句古文还是成语是说这种心感悟的,想不起来了。
我什么时候才能不当编程婴儿。我想站起来走路。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号