
SSE指令集学习:Compiler Intrinsic
大多数的函数是在库中,Intrinsic Function却内嵌在编译器中(built in to the compiler)。
1. Intrinsic Function
Intrinsic Function作为内联函数,直接在调用的地方插入代码,即避免了函数调用的额外开销,又能够使用比较高效的机器指令对该函数进行优化。优化器(Optimizer)内置的一些Intrinsic Function行为信息,可以对Intrinsic进行一些不适用于内联汇编的优化,所以通常来说Intrinsic Function要比等效的内联汇编(inline assembly)代码快。优化器能够根据不同的上下文环境对Intrinsic Function进行调整,例如:以不同的指令展开Intrinsic Function,将buffer存放在合适的寄存器等。
使用 Intrinsic Function对代码的移植性会有一定的影响,这是由于有些Intrinsic Function只适用于Visual C++,在其他编译器上是不适用的;更有些Intrinsic Function面向的是特定的CPU架构,不是全平台通用的。上面提到的这些因素对使用Intrinsic Function代码的移植性有一些不好的影响,但是和内联汇编相比,移植含有Intrinsic Function的代码无疑是方便了很多。另外,64位平台已经不再支持内联汇编。
2. SSE Intrinsic
VS和GCC都支持SSE指令的Intrinsic,SSE有多个不同的版本,其对应的Intrinsic也包含在不同的头文件中,如果确定只使用某个版本的SSE指令则只包含相应的头文件即可。
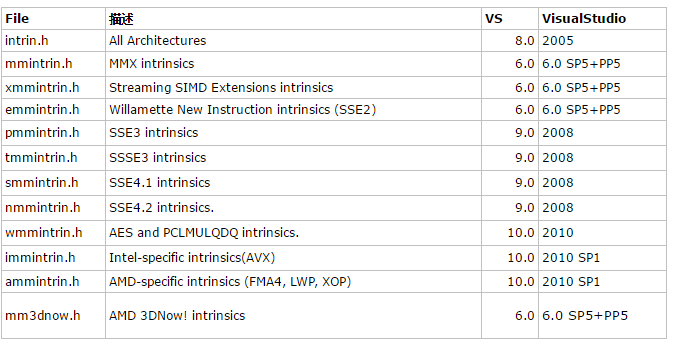
引用自:http://www.cnblogs.com/zyl910/archive/2012/02/28/vs_intrin_table.html
例如,要使用SSE3,则
#include <tmmintrin.h>
如果不关心使用那个版本的SSE指令,则可以包含所有
#include <intrin.h>
2.1 数据类型
Intrinsic使用的数据类型和其寄存器是想对应,有
- 64位 MMX指令集使用
- 128位 SSE指令集使用
- 256位 AVX指令集使用
甚至AVX-512指令集有512位的寄存器,那么相对应Intrinsic的数据也就有512位。
具体的数据类型及其说明如下:
- __m64 64位对应的数据类型,该类型仅能供MMX指令集使用。由于MMX指令集也能使用SSE指令集的128位寄存器,故该数据类型使用的情况较少。
- __m128 / __m128i / __m128d 这三种数据类型都是128位的数据类型。由于SSE指令集即能操作整型,又能操作浮点型(单精度和双精度),这三种数据类型根据所带后缀的不同代表不同类型的操作数。__m128是单精度浮点数,__m128i是整型,__m128d是双精度浮点数。
256和512的数据类型和128位的类似,只是存放的个数不同,这里不再赘述。
知道了各种数据类型的长度以及其代码的意义,那么它的表现形式到底是怎么样的呢?看下图
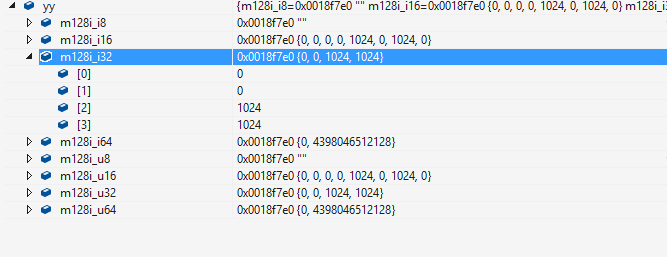
__m128i yy;
yy是__m128i型,从上图可以看出__m128i是一个联合体(union),根据不同成员包含不同的数据类型。看其具体的成员包含了8位、16位、32位和64位的有符号/无符号整数(这里__m128i是整型,故只有整型的成员,浮点数的使用__m128)。而每个成员都是一个数组,数组中填充着相应的数据,并且根据数据长度的不同数组的长度也不同(数组长度 = 128 / 每个数据的长度(位))。在使用的时候一定要特别的注意要操作数据的类型,也就是数据的长度,例如上图同一个变量yy当作4个32位有符号整型使用时其数据是:0,0,1024,1024;但是当做64位有符号整型时其数据为:0,4398046512128,大大的不同。
在MSVC下可以使用yy.m128i_i32[0]取出第一个32位整型数据,原生的Intrinsic函数是没有提供该功能的,这是在MSVC的扩展,比较像Microsoft的风格,使用及其的方便但是效率很差,所以这种方法在GCC/Clang下面是不可用的。在MSVC下面可以根据需要使用不使用这种抽取数据的方法,但是这种功能在调试代码时是非常方便的,如上图可以很容易的看出128位的数据在不同数据类型下其值的不同。
2.2 Intrinsic 函数的命名
Intrinsic函数的命名也是有一定的规律的,一个Intrinsic通常由3部分构成,这个三个部分的具体含义如下:
- 第一部分为前缀_mm,表示是SSE指令集对应的Intrinsic函数。_mm256或_mm512是AVX,AVX-512指令集的Intrinsic函数前缀,这里只讨论SSE故略去不作说明。
- 第二部分为对应的指令的操作,如_add,_mul,_load等,有些操作可能会有修饰符,如loadu将未16位对齐的操作数加载到寄存器中。
- 第三部分为操作的对象名及数据类型,_ps packed操作所有的单精度浮点数;_pd packed操作所有的双精度浮点数;_pixx(xx为长度,可以是8,16,32,64)packed操作所有的xx位有符号整数,使用的寄存器长度为64位;_epixx(xx为长度)packed操作所有的xx位的有符号整数,使用的寄存器长度为128位;_epuxx packed操作所有的xx位的无符号整数;_ss操作第一个单精度浮点数。....
将这三部分组合到以其就是一个完整的Intrinsic函数,如_mm_mul_epi32 对参数中所有的32位有符号整数进行乘法运算。
SSE指令集对分支处理能力非常的差,而且从128位的数据中提取某些元素数据的代价又非常的大,因此不适合有复杂逻辑的运算。
3. Intrinsic版双线性插值
在上一篇文章SSE指令集优化学习:双线性插值 使用SSE汇编指令对双线性插值算法进行了优化,这里将其改成为Intrinsic版的。
3.1 计算 (y * width + x) * depth
目的像素需要其映射到源像素周围最近的4个像素插值得到,这里同时计算源像素的最近的4个像素值的偏移量。
__m128i wwidth = _mm_set_epi32(0, width, 0, width);
__m128i yy = _mm_set_epi32(0, y2, 0, y1);
yy = _mm_mul_epi32(yy, wwidth); //y1 * width 0 y2 *width 0
yy = _mm_shuffle_epi32(yy, 0xd8); // y1 * width y2 * width 0 0
yy = _mm_unpacklo_epi32(yy, yy); // y1 * width y2 * width y1 * width y2 * width
yy = _mm_shuffle_epi32(yy, _MM_SHUFFLE(3, 1, 2, 0));
__m128i xx = _mm_set_epi32(x2, x2, x1, x1);
xx = _mm_add_epi32(xx, yy); // (x1,y1) (x1,y2) (x2,y1) (x2,y2)
__m128i x1x1 = _mm_shuffle_epi32(xx, 0x50); // (x1,y1) (x1,y2)
__m128i x2x2 = _mm_shuffle_epi32(xx, 0xfa); // (x2,y1) (x2,y2)
- 使用set函数将需要的数据填充到__m128Intel中
- mul函数进行乘法运算,两个32位的整型相乘的结果是一个64位整型。
- 由于计算的是像素的偏移量,使用32位整型也就足够了,使用shffule对__m128i中的数据进行重新排列,使用unpack函数再重新组合,将数据组合为需要的结构。
_MM_SHUFFLE是一个宏,能够方便的生成shuffle中所需要的立即数。例如
_mm_shuffle_epi32(yy,_MM_SHUFFLE(3,1,2,0);
将yy中存放的第2和第3个32位整数交换顺序。
3.2 数据类型的转换
SSE汇编指令和其Intrinsic函数之间基本存在这一一对应的关系,有了汇编的实现再改为Intrinsic是挺简单的,再在这罗列代码也乜嘢什么意义了。这里就记录下使用的过程中遇到的最大的问题:数据类型之间的转换。
做图像处理,由于像素通道值是8位的无符号整数,而与其运算的往往又是浮点数,这就需要将8位无符号整数转换为浮点数;运算完毕后,得到的结果又要写回图像通道,就要是8位无符号整数,还要涉及到超出8位的截断。开始不注意时吃了大亏....
类型转换主要以下几种:
- 浮点数和整数的转换及32位浮点数和64位浮点数之间的转换。 这种转换简单直接,只需要调用相应的函数指令即可。
- 有符号整数的高位扩展将8位、16位、32位有符号整数扩展为16位、32位、64位。
- 有符号整数的截断 将16位、32位、64位有符号压缩
- 无符号整数到有符号整数的扩展
在Intrinsic函数中 上述类型转换的格式
- _mm_cvtepixx_epixx (xx是位数8/16/32/64)这是有符号整数之间的转换
- _mm_cvtepixx_ps / _mm_cvtepixx_pd 整数到单精度/双精度浮点数之间的转换
- _mm_cvtepuxx_epixx 无符号整数向有符号整数的扩展,采用高位0扩展的方式,这些函数是对无符号高位0扩展变成相应位数的有符号整数。没有32位无符号整数转换为16位有符号整数这样的操作。
- _mm_cvtepuxx_ps / _mm_cvtepuxx_pd 无符号整数转换为单精度/双精度浮点数。
上面的数据转换还少了一种,整数的饱和转换。什么是饱和转换呢,超过的最大值的以最大值来计算,例如8位无符号整数最大值为255,则转换为8位无符号时超过255的值视为255。
整数的饱和转换有两种:
- 有符号之间的 SSE的Intrinsic函数提供了两种
__m128i _mm_packs_epi32(__m128i a, __m128i b)
__m128i _mm_packs_epi16(__m128i a , __m128i b)
用于将16/32位的有符号整数饱和转换为8/16位有符号整数。
- 有符号到无符号之间的
__m128i _mm_packus_epi32(__m128i a, __m128i b)
__m128i _mm_packus_epi16(__m128i a , __m128i b)
用于将16/32位的有符号整数饱和转换为8/16位无符号整数
4. SSE汇编指令和Intrinsic函数的对比
这里只是做了一个粗略的对比,毕竟还只是个初学者。先说结果吧,在Debug下使用纯汇编的SSE代码会快不少,应该是由于没有编译器的优化,汇编代码的效率还是有很大的优势的。但是在Release下面,前面也有提到过优化器内置了Intrinsic函数的行为信息,能够对Intrinsic函数提供很强大的优化,两者没有什么差别。PS:应该是由于选用数据的问题 ,普通的C++代码,SSE汇编代码以及Intrinsic函数三者在Release下的速度相差无几,编译器本身的优化功能是很强大的。
4.1 Intrinsic 函数进行多次内存读写操作
在对比时发现使用Intrinsic函数另一个问题,就是数据的存取。使用SSE汇编时,可以将中间的计算结果保存到xmm寄存器中,在使用的时候直接取出即可。Intrinsic函数不能操作xmm寄存器,也就不能如此操作,它需要将每次的计算结果写回内存中,使用的时候再次读取到xmm寄存器中。
yy = _mm_mul_epi32(yy, wwidth);
上述代码是进行32位有符号整数乘法运算,计算的结果保存在yy中,反汇编后其对应的汇编代码:
000B0428 movaps xmm0,xmmword ptr [ebp-1B0h]
000B042F pmuldq xmm0,xmmword ptr [ebp-190h]
000B0438 movaps xmmword ptr [ebp-7A0h],xmm0
000B043F movaps xmm0,xmmword ptr [ebp-7A0h]
000B0446 movaps xmmword ptr [ebp-1B0h],xmm0
上述汇编代码中有多次的movaps操作。而上述操作在使用汇编时只需一条指令
pmuludq xmm0, xmm1;
在使用Intrinsic函数时,每一个函数至少要进行一次内存的读取,将操作数从内存读入到xmm寄存器;一次内存的写操作,将计算结果从xmm寄存器写回内存,也就是保存到变量中去。由此可见,在只有很简单的计算中(例如:同时进行4个32位浮点数的乘法运算)和使用SSE汇编指令不会有很大的差别,但是如果逻辑稍微复杂些或者调用的Intrinsic函数较多,就会有很多的内存读写操作,这在效率上还是有一部分损失的。
4.2 简单运算的Intrinsic和SSE指令的对比
一个比较极端的例子,未经过优化的C++代码如下:
_MM_ALIGN16 float a[] = { 1.0f,2.0f,3.0f,4.0f };
_MM_ALIGN16 float b[] = { 5.0f,6.0f,7.0f,8.0f };
const int count = 1000000000;
float c[4] = { 0,0,0,0 };
cout << "Normal Time(ms):";
double tStart = static_cast<double>(clock());
for (int i = 0; i < count; i++)
for (int j = 0; j < 4; j++)
c[j] = a[j] + b[j];
double tEnd = static_cast<double>(clock());
对两个有4个单精度浮点数的数组做多次加法运算,并且这种加法是重复进行,进行1次和进行1000次的结果是相同的。使用SSE汇编指令的代码如下:
for(int i = 0; i < count; i ++)
_asm
{
movaps xmm0, [a];
movaps xmm1, [b];
addps xmm0, xmm1;
}
使用Intrinsic函数的代码:
__m128 a1, b2;
__m128 c1;
for (int i = 0; i < count; i++)
{
a1 = _mm_load_ps(a);
b2 = _mm_load_ps(b);
c1 = _mm_add_ps(a1, b2);
}
在Debug下的运行
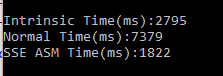
这个结果应该在意料之中的,SSE汇编指令 < Intrinsic函数 < C++。SSE汇编指令比Intrinsic函数快了近1/3,下面是Intrinsic函数的反汇编代码
a1 = _mm_load_ps(a);
00FB2570 movaps xmm0,xmmword ptr [a]
00FB2574 movaps xmmword ptr [ebp-220h],xmm0
00FB257B movaps xmm0,xmmword ptr [ebp-220h]
00FB2582 movaps xmmword ptr [a1],xmm0
b2 = _mm_load_ps(b);
00FB2586 movaps xmm0,xmmword ptr [b]
00FB258A movaps xmmword ptr [ebp-240h],xmm0
00FB2591 movaps xmm0,xmmword ptr [ebp-240h]
00FB2598 movaps xmmword ptr [b2],xmm0
c1 = _mm_add_ps(a1, b2);
00FB259F movaps xmm0,xmmword ptr [a1]
00FB25A3 addps xmm0,xmmword ptr [b2]
00FB25AA movaps xmmword ptr [ebp-260h],xmm0
00FB25B1 movaps xmm0,xmmword ptr [ebp-260h]
00FB25B8 movaps xmmword ptr [c1],xmm0
可以看到共有12个movaps指令和1个addps指令。而SSE的汇编代码只有2个movaps指令和1个addps指令,可见其时间的差别应该主要是由于Intrinsic的内存读写造成的。
Debug下面的结果是没有出意料之外的,那么Release下的结果则真是出乎意料的

使用SSE汇编的最慢,C++实现都比起快很好,可见编译器的优化还是非常给力的。而Intrinsic的时间则是0,是怎么回事。查看反汇编的代码发现,那个加法只执行了一次,而不是执行了很多次。应该是优化器根据Intrinsic行为做了预测,后面的多次循环都是无意义的(一同学告诉我的,他是做编译器生成代码优化的,做的是分支预测,不过也是在实现中,不知道他说的对不对)。
5. 总结
学习SSE指令将近两个周了,做了两篇学习笔记,差不多也算入门了吧。这段时间的学习总结如下:
- SSE指令集正如其名字 Streaming SIMD Extensions,最强大的是其能够在一条指令并行的对多个操作数进行相同的运算,根据操作数长度和寄存器长度的不同能够同时运算的个数也不同。以32位有符号整数为例,128位寄存器(也是最常用的SSE指令集的寄存器)能够同时运算4个;AVX指令集的256位寄存器能够同时运算8个;AVX-512 的512位寄存器能够同时运算16个。
- 在使用SSE指令时要特别主要操作数的类型,整型则要区分是有符号还是无符号;浮点数则注意其精度是单精度还是双精度。另外就是操作数的长度。即使是同样的128位二进制串,根据其类型和长度也有多种不同的解释。
- 前面多次提到,编译器的优化能力是很强的,不要刻意的使用SSE指令优化。而在要必须使用SSE的时候,要谨记SSE的强大之处是其并行能力。
又是一个阳光明媚的周五下午,说好的今天要下大暴雨呢,早晨都没敢骑自行车来上班,回去的得挤公交啊。话说,为啥不说坐公交或者乘公交,而要挤公交呢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号