
深度学习与计算机视觉: 深度学习必知基本概念以及链式求导
深度学习与计算机视觉,开篇。
- 深度学习的几个基本概念
- 反向传播算法中的链式求导法则。
关于反向传播四个基本方程的推导过程,放在下一篇。
深度学习基础
深度学习的几度沉浮的历史就不多说了,这里梳理下深度学习的一些基本概念,做个总结记录,内容多来源于网络。
- 神经元 神经网络的基本组成单元
神经系统的基本组成单元,将接受后的信息处理后传递给下一个神经元。类似的在深度学习的网络结构中,最基本的组成单元也被称为神经元。神经元的作用是对输入的数据进行加权求和并应用于激活函数,处理后将输出数据传递给下一个神经元。神经元的结构如下图:
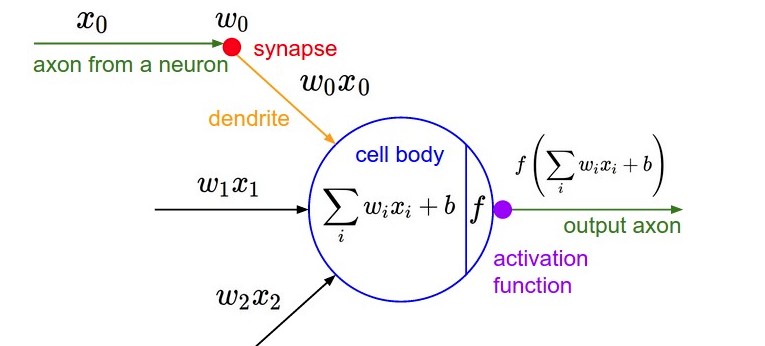
神经元接受到的数据为\((x_0,x_1,x_2)^T\),对接收到的数据进行如下处理后的输出为:
一个神经元的基本组成为:
-
权值矩阵(Wieghts) \(w\)
-
偏置(Bias) \(b\)
-
激活函数(Activate function) \(f\)
-
权值矩阵
输入的数据被神经元接收后,会乘以一个权值因子。在初始训练的时候,这些权值因子会被随机的设置。在训练的过程中,为了更好的拟合训练数据集,不断的调整这些权值因子。深度学习的训练过程,也就是调整这些权值因子的过程。
在神经网络中,一个输入具有的权重因子越大,就意味着它的重要性更大,对输出的影响越大。另一方面,当权重因子为0时意味着这个输入对输出没有任何影响。 -
偏置
输入数据和权值相乘后,通过和偏置相加,以此作为激活函数的输入。 -
激活函数
前面对输入数据的加权相乘以及和偏置相加,都是线性变换。如果没有激活函数,神经网络就是一些线性变换的叠加,最终仍然是对输入的数据进行的是线性变换。 所以需要加入非线性的激活函数,这样神经元对输入的数据进行的非线性变换。这样不但能提高神经网络的表达能力,也能解决线性模型不能解决的问题。 常用的激活函数是:sigmoid函数和ReLu函数。 -
神经网络
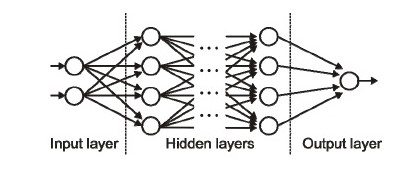
神经网络是由彼此相连的神经元组成,数据在这些神经元之间进行传递,随着训练的进行,神经元之间的权值也不断的进行调整。并且神经元之间有激活的阈值,当输入相应的数据和权值后神经元被激活,神经网络的学习过程就是不同神经元被激活组合。
-
输入层/隐藏层/输出层
神经网络包含很多的神经元,这些神经元以“层”的形式组合到一起,如上图。有三种类型的层:输入层,网络的第一层,接受输入的数据,不对数据做处理;输出层,网络的最后一层,也就是网络最后的输出结果;隐藏层,这个层次可以有1-n层,也是神经网络的主要部分,使用输入层传递的数据进行训练,然后将训练的结果传递到输出层。 -
正向传播
输入的数据沿着,输入层-隐藏层-输出层依次传递。在正向传播的过程中,数据沿着单一的方向进行传递。 -
成本函数
名称比较多,还可以称为损失函数,目标函数等。在训练神经网络的过程中,希望输出的结果尽可能的接近真实的值,使用成本函数来描述训练后的输出结果和真实结果的相近程度。成本函数的值越小,表示神经网络的输出越接近真实值,所以神经网络的训练也就是最小化成本函数的过程。
常用的成本函数有:- 均方误差\(L = \frac{1}{2}\sum(y-y')\),\(y'\)神经网络输出的预测值;
- 交叉熵 \(L = -(y\ln y' + (1-y)\ln(1-y'))\)
-
梯度下降
梯度下降是一种求解函数局部最小值的优化方法。在深度学习通常使用梯度下降的优化方法,找到使成本函数达到最小值的权值矩阵。也可以说,神经网络的训练过程,就是使用梯度下降方法,调整权值矩阵,使成本函数达到最小值的过程。
在梯度下降中,从起始点\(x\)开始,每次移动一点距离(例如\(\Delta h\)),然后将权重值更换为\(x - \Delta h\),如此重复下去,直到达到局部的极小值,此时认为极小值就是成本最小的地方。 -
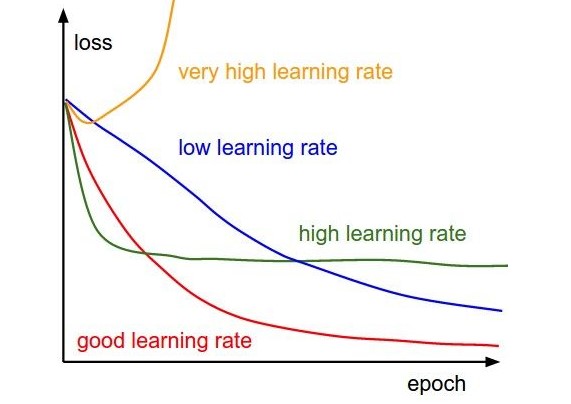
学习速率
学习速率定义了,梯度下降时每次移动的距离,进而影响训练过程中迭代的次数(也就是训练的时间长短)。简单来说,学习速率就是朝着成本函数最小值下降的速率。例如,每次迭代时,求解的误差关于权值的偏导值为\(\Delta h\),设\(\alpha\)为学习速率,则每次梯度下降的距离就是\(\alpha \Delta h\)。 学习速率的设置一定要慎重,过大的速率,也就是每次下降的步伐过大,有可能跳过最优解;而小的学习速率,下降的步伐太小,回导致训练时间过长。
-
反向传播
前面提到,神经网络的训练过程就是使用梯度下降的优化方法调整权值矩阵以使成本函数取得最小值的过程。在初始化网络的时候,每个神经元都会被随机的分配权值和偏置,一次正向传播后,可以根据产生的结果计算出整个网络的偏差(成本函数的值),然后用偏差结合成本函数的梯度,对权重因子进行相应的调整,使得下次迭代的过程中偏差变小。这样一个结合成本函数的梯度来调整权重因子的过程就叫做反向传播。
反向传播,数据的传递是反过来的,从输出层向输入层传递,传递误差连同成本函数的梯度从输出层沿着隐藏层向输入层传递,同时使用梯度下降的方法调整每个神经元的权值,以使下一次正向传播的输出值和真实值更近。 -
分批(Batches) 和 周期(Epochs)
在使用训练集训练神经网络的时候,相比于一次将所有的样本全部输入到网络中,一个更好的选择是:先将数据随机地分为几个大小一致的数据块,再分批次输入。跟一次性训练出来的模型相比,分批训练能够使模型的适用性更好。
一个Epoch表示,对所有的Batch都进行了一次训练。 -
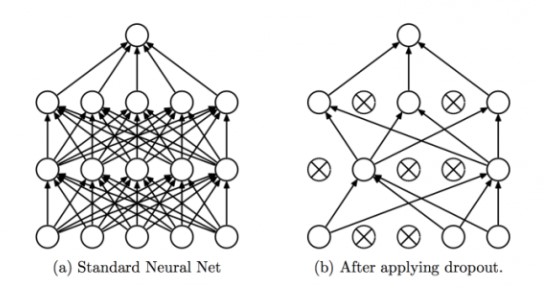
Dropout
防止网络过拟合的规则化方法,在训练的过程中,随机的忽略掉(drop)某些神经元。不断能够减少训练需要调整的权值矩阵,而且每次drop的神经元都是随机的,相当于改变了神经网络的结构,相当于多个不同的网络组合在一起完成最终的训练,得到输出结果。
总结
深度学习的网络结构可以很复杂,但是其是由基本的神经元组成的。 一个神经元就是对输入的输入加权求和,再加上个偏置,将最终的结果输入到激活函数中,激活函数的结果作为下一层神经元的输入。一个神经元有三部分组成:权值矩阵,偏置以及激活函数,通常整个网络中的所有神经元都是用相同的激活函数。一个神经元的数学表示
整个神经网络就是有上述的公式堆叠而成。
神经网络的训练就是将已有的训练样本输入到神经网络中,使用梯度下降的方法不断调整各个神经元的权值和偏置,使得成本函数达到最小值,这样神经网络输出的预测数据和真实的结果最为接近。
在训练的时候,并不是将所有的训练数据一次全部输入到网络中,而是随机的将训练集分为多个相同大小的Batch,每次训练的时候只使用一个Batch。 这样,训练集包含的所有Batch都使用一次后,就完成了一个周期(Epoch)的训练。
在训练的过程中,可以设置合适的学习速率,来加快训练过程。并可以使用Dropout等正则化方法,防止过拟合。
反向传播
上面提到,深度学习网络的训练过程实际上是梯度下降的方法不断调整各个神经元的权值和偏置,使得成本函数达到最小值。这里提到了三个量:成本函数,神经元的权值和偏置,也就是对每个神经元找到合适的权值和偏置,使得成本函数的值最小。有了函数(成本函数,可以是均方误差),也知道了变量(神经元权值和偏置),下面就是求梯度了。 但是深度学习网络通常有很多个层(不然怎么叫“深度”学习呢),求误差相对于权值和偏置的梯度是非常复杂的。反向传播使用链式求导法则,求解多层神经网络中误差关于神经元权值和偏置的梯度的方法。
下面以三层神经网络(只有一个隐层)为例,推导下反向传播过程中,各个神经元梯度的求解过程。其网络结构如下:
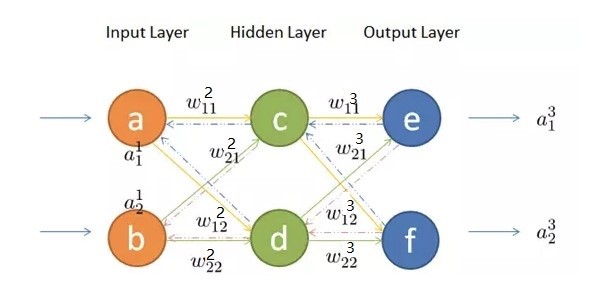
神经元使用的激活函数为\(sigmoid\),要推导反向传播的链式求导过程,首先要明确各个量的表示。各个量的符号表示如下:
- \(w_{jk}^l\)表示第\(l\)层的第\(j\)个神经元与上一层(\(l-1\))第\(k\)个神经元之间的权值。
- \(a_j^l\)表示第\(l\)层的第\(j\)个神经元的输出,上一层的输出就是下一层的输入
- \(z_j^l\)表示第\(l\)层的第\(j\)个神经元输入到激活函数中的值
- \(b_j^l\)表示第\(l\)层的第\(j\)个神经元的偏置
各个量的表示都很明确,上标\(l\)表示所在的层,下标\(j\)表示层中神经元的位置。 这里要注意下\(w_{jk}^l\)中\(j,k\)的位置,\(j\)的第\(l\)层的第\(j\)个神经元,\(k\)表示的是\(l-1\)层的第\(k\)个神经元。
首先来看看正向传播的过程,输入层的数据经过隐藏层的加权激活后,传播到输出层。
正向传播
\((a_1^1,a_2^1)\)为第一层输入层的输入与输出,则隐藏层第一个神经元C的输到激活函数中的值为
则该神经元的输出为
隐藏层第二个神经元d的输入为\(a_1^2\),加权输入到激活函数中的值是
该神经元的输出为
写成矩阵的形式如下:
输出层的输出的最终结果,为\((a_1^2,a_2^2)\)加权后的值\(z^3\)输入到激活函数
这里大写的字母,表示矩阵。经过上述的中间步骤输入层的\((a_1^1,a_2^1)\)经过隐藏层的处理,在输出层变成了\((a_1^3,a_2^3)\)。
误差的反向传播
在反向传播的过程,不只是梯度的计算,其中还伴随着,输出误差的反向传播。输出误差从输出层依次经过隐藏层传播到输入层。
按照权值分配的原则,可以将输出层的误差\(e_{o1},e_{o2}\)按照下面的公式反向传播到隐藏层。
写成矩阵的形式有
在不破坏比例的情况,可以除掉上式的分母,让公式更简洁些
更简单点
链式求导
梯度下降的优化方法,需要求成本函数关于神经元权值和偏置的偏导数。上面也看到,神经元被组织成多个层,从输入层开始,到输出层终。我们的目的是求成本函数关于每个神经元的权值和偏置的偏导数,需要从输出层的输出得到成本函数,依次向隐藏层,输入层,求成本函数(也可以叫着误差)关于各个权值的偏导,其数据的传递方向和正向传播是相反的。
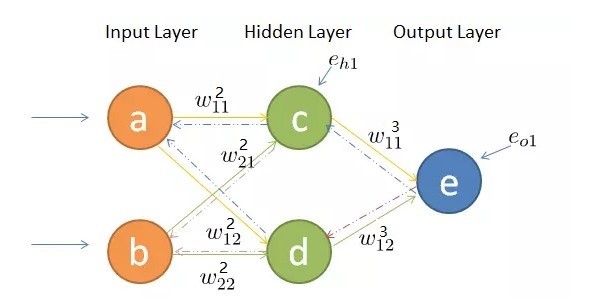
首先从输出层的第一个神经元开始,向前推到误差关于第二层第一个神经元和输出层第一个神经元之间的权值\(w_{11}^2\)和偏置\(b_1^2\)的偏导数。
\(e_{o1}\)是第一个输出神经元的输出误差,\(y_1\)是真实值。
应用链式求导法则,\(e_{o1}\)关于权值\(w_{11}^2\)的偏导数为
展开可以得到
同样,可以得到\(e_{o1}\)关于权值\(w_{12}^2\)的偏导数
\(e_{o1}\)关于权值\(b_1^3\)的偏导数
上述公式只是求得了误差\(e_{o1}\)关于隐藏层的神经元的权值和偏置,还需要继续的往前“传播”求得关于输入层和隐藏层之间的权值和偏导的导数,
求\(e_{o1}\)关于\(w_{11}^2\)的导数
求\(e_{o1}\)关于\(b_1^2\)的导数
同样的方法,可以求得误差关于其他神经元的权值和偏置的导数,这里不再赘述。
下面将上面链式求导得到的所有每层第一个神经元的权值和偏置的导数放到一起
前两个公式是,隐藏层和输出层之间的权值和偏置的偏导数;后两个是输入层和隐藏层之间的权值和偏置的偏导数
上面只是每层第一个神经元权值和偏置的偏导数,深度学习的神经网络通常有上百上千甚至更多的神经元,按照上述公式一个个神经元去求解导数,然后在利用梯度下降的方法更新每个权值和偏置,这样神经网络的效率肯定是非常的低的。 但是观察上述的公式,有很多重复的部分,利用这些重复的部分,就让更新各个权值和偏置不再那么的麻烦。
待续
下篇文章会以本文的链式求导为基础,一步步的推到下反向传播的四个基本方程....
本文图及部分推导过程引自网络,侵删。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号