102302112王光诚作业3
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
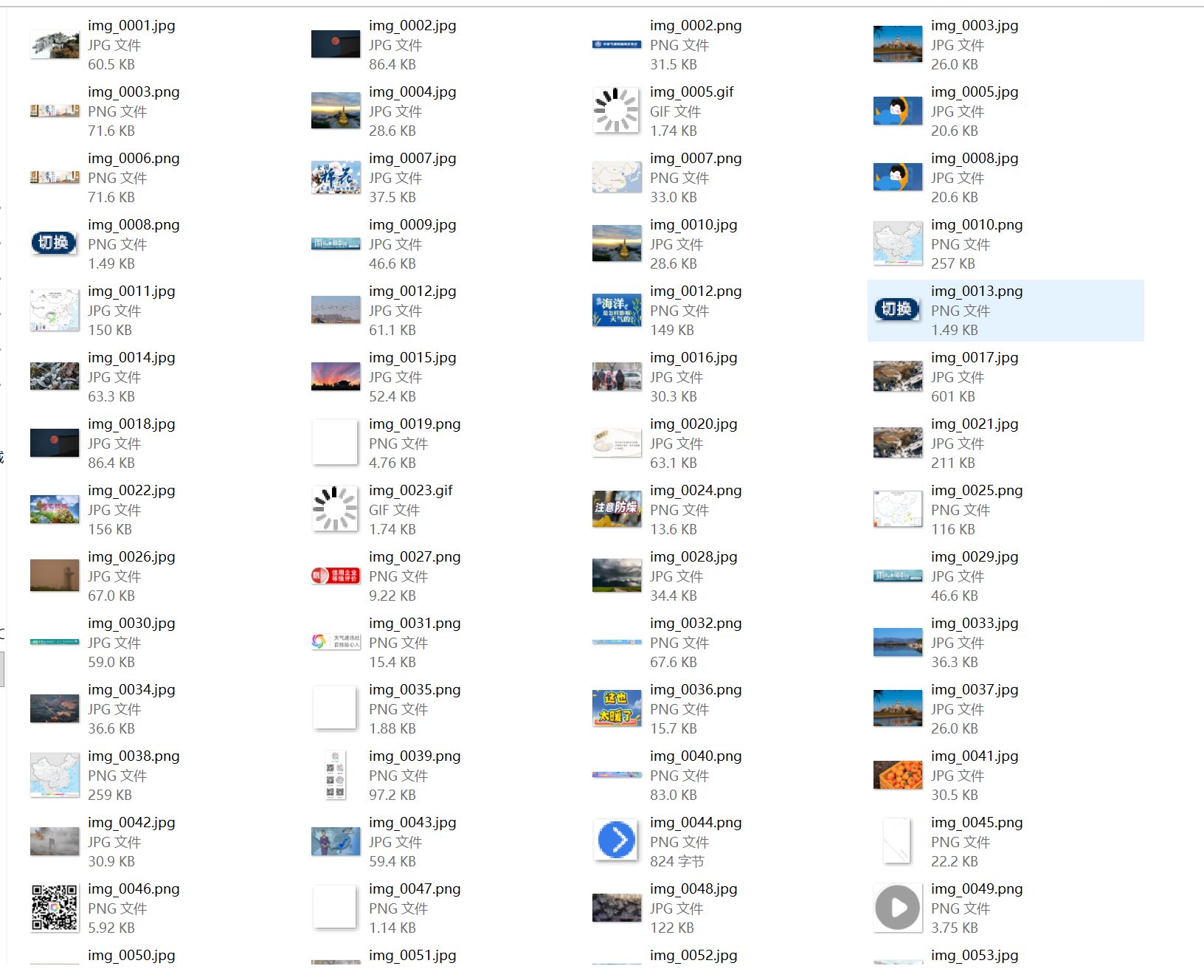
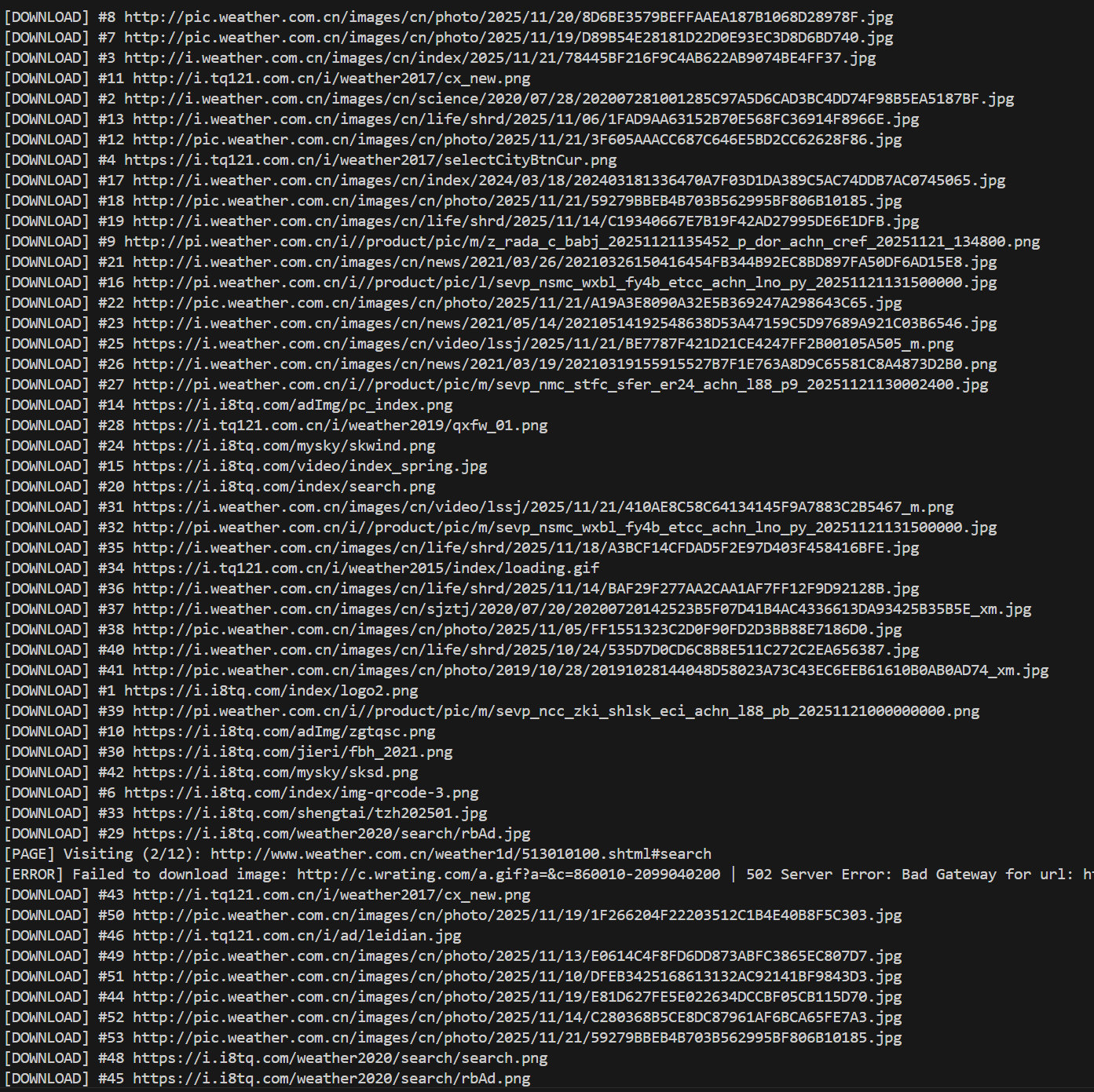
点击查看代码
import os
import threading
from urllib.parse import urljoin, urlparse
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor, as_completed
START_URL = "http://www.weather.com.cn"
STUDENT_ID = "102302112"
MAX_PAGES = int(STUDENT_ID[-2:])
MAX_IMAGES = int(STUDENT_ID[-3:])
IMAGE_DIR = "images"
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/123.0 Safari/537.36"
}
def ensure_image_dir():
if not os.path.exists(IMAGE_DIR):
os.makedirs(IMAGE_DIR)
def is_same_domain(url, base_netloc):
try:
netloc = urlparse(url).netloc
return netloc == "" or netloc == base_netloc
except Exception:
return False
def get_html(url):
try:
resp = requests.get(url, headers=HEADERS, timeout=10)
resp.raise_for_status()
resp.encoding = resp.apparent_encoding
return resp.text
except Exception as e:
print(f"[ERROR] Failed to get page: {url} | {e}")
return ""
def parse_links_and_images(current_url, html, base_netloc):
soup = BeautifulSoup(html, "html.parser")
new_page_urls = set()
img_urls = set()
for a in soup.find_all("a", href=True):
href = a["href"]
new_url = urljoin(current_url, href)
if is_same_domain(new_url, base_netloc):
new_page_urls.add(new_url)
for img in soup.find_all("img", src=True):
src = img["src"]
img_url = urljoin(current_url, src)
img_urls.add(img_url)
return new_page_urls, img_urls
def download_image(img_url, index):
try:
resp = requests.get(img_url, headers=HEADERS, timeout=10)
resp.raise_for_status()
path = urlparse(img_url).path
ext = os.path.splitext(path)[1]
if not ext:
ext = ".jpg"
filename = f"img_{index:04d}{ext}"
filepath = os.path.join(IMAGE_DIR, filename)
with open(filepath, "wb") as f:
f.write(resp.content)
print(f"[DOWNLOAD] #{index} {img_url}")
except Exception as e:
print(f"[ERROR] Failed to download image: {img_url} | {e}")
def crawl_single_thread(start_url, max_pages, max_images):
print("=" * 60)
print("Single-thread crawling started...")
print(f"Start URL : {start_url}")
print(f"Max pages : {max_pages}")
print(f"Max images: {max_images}")
print("=" * 60)
ensure_image_dir()
base_netloc = urlparse(start_url).netloc
visited_pages = set()
to_visit = [start_url]
downloaded_count = 0
while to_visit and len(visited_pages) < max_pages and downloaded_count < max_images:
current_url = to_visit.pop(0)
if current_url in visited_pages:
continue
print(f"[PAGE] Visiting ({len(visited_pages)+1}/{max_pages}): {current_url}")
visited_pages.add(current_url)
html = get_html(current_url)
if not html:
continue
new_pages, img_urls = parse_links_and_images(current_url, html, base_netloc)
for new_url in new_pages:
if new_url not in visited_pages and len(visited_pages) + len(to_visit) < max_pages:
to_visit.append(new_url)
for img_url in img_urls:
if downloaded_count >= max_images:
break
downloaded_count += 1
download_image(img_url, downloaded_count)
print("=" * 60)
print(f"Single-thread crawling finished. Visited pages: {len(visited_pages)}, "
f"Downloaded images: {downloaded_count}")
print("=" * 60)
def crawl_multi_thread(start_url, max_pages, max_images, max_workers=8):
print("=" * 60)
print("Multi-thread crawling started...")
print(f"Start URL : {start_url}")
print(f"Max pages : {max_pages}")
print(f"Max images: {max_images}")
print(f"Threads : {max_workers}")
print("=" * 60)
ensure_image_dir()
base_netloc = urlparse(start_url).netloc
visited_pages = set()
to_visit = [start_url]
lock = threading.Lock()
downloaded_count = {"value": 0}
def worker_page(url):
html = get_html(url)
if not html:
return set(), set()
new_pages, img_urls = parse_links_and_images(url, html, base_netloc)
return new_pages, img_urls
with ThreadPoolExecutor(max_workers=max_workers) as executor:
while to_visit and len(visited_pages) < max_pages and downloaded_count["value"] < max_images:
current_url = to_visit.pop(0)
if current_url in visited_pages:
continue
print(f"[PAGE] Visiting ({len(visited_pages)+1}/{max_pages}): {current_url}")
visited_pages.add(current_url)
future = executor.submit(worker_page, current_url)
new_pages, img_urls = future.result()
for new_url in new_pages:
if new_url not in visited_pages and new_url not in to_visit and len(visited_pages) + len(to_visit) < max_pages:
to_visit.append(new_url)
futures = []
for img_url in img_urls:
with lock:
if downloaded_count["value"] >= max_images:
break
downloaded_count["value"] += 1
index = downloaded_count["value"]
futures.append(executor.submit(download_image, img_url, index))
for f in as_completed(futures):
_ = f.result()
print("=" * 60)
print(f"Multi-thread crawling finished. Visited pages: {len(visited_pages)}, "
f"Downloaded images: {downloaded_count['value']}")
print("=" * 60)
if __name__ == "__main__":
crawl_single_thread(START_URL, MAX_PAGES, MAX_IMAGES)
crawl_multi_thread(START_URL, MAX_PAGES, MAX_IMAGES, max_workers=8)
print("All tasks done.")
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
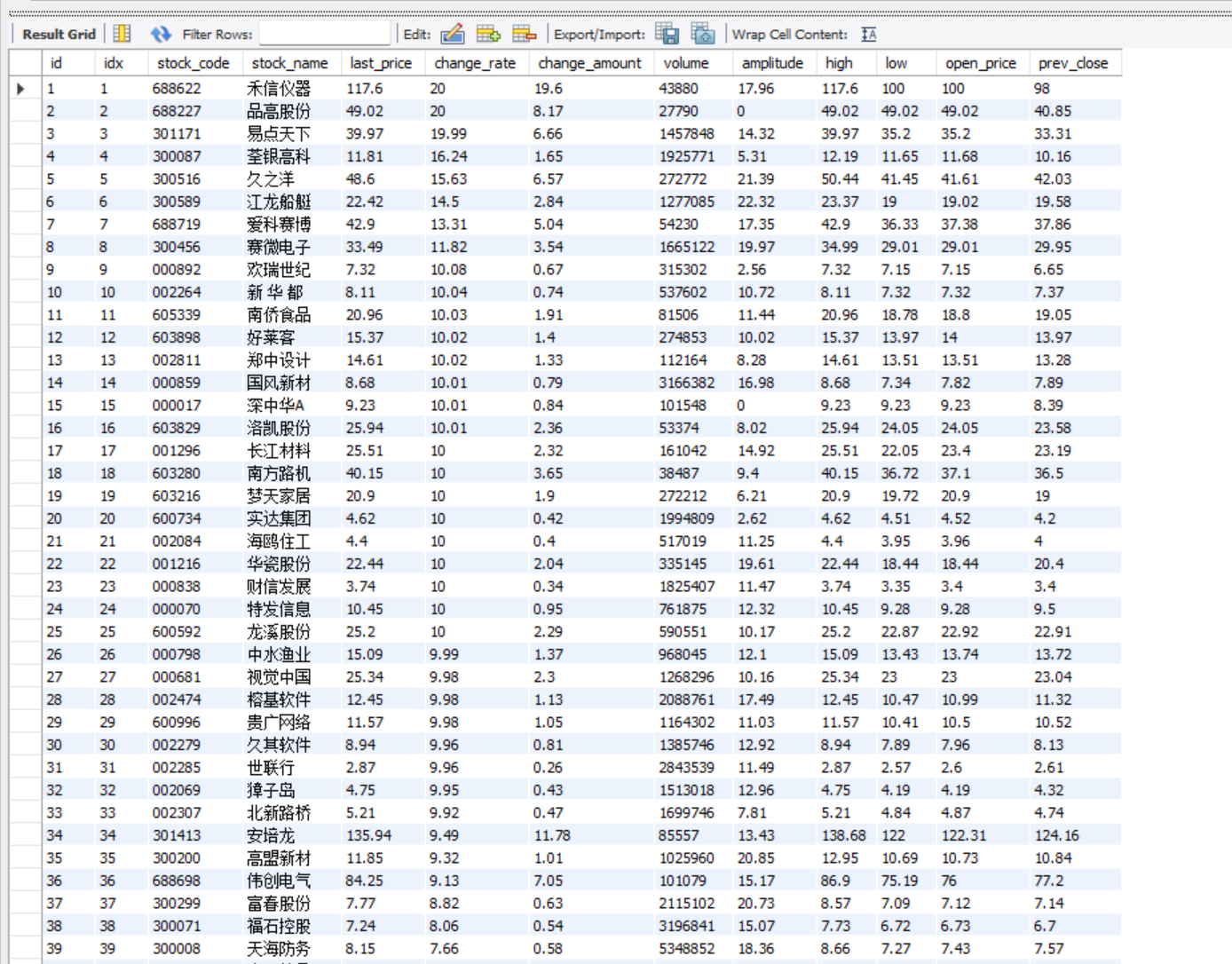
点击查看代码
import scrapy
import json
from stockspider.items import StockItem
class StocksSpider(scrapy.Spider):
name = "stocks"
allowed_domains = ["eastmoney.com"]
start_urls = [
"http://80.push2.eastmoney.com/api/qt/clist/get?pn=1&pz=100&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152"
]
def parse(self, response):
try:
data = json.loads(response.text)
if data.get('data') and data['data'].get('diff'):
stocks = data['data']['diff']
for index, stock in enumerate(stocks, start=1):
item = StockItem()
item['index'] = index
item['stock_code'] = stock.get('f12', '')
item['stock_name'] = stock.get('f14', '')
item['last_price'] = stock.get('f2', '')
item['change_rate'] = stock.get('f3', '')
item['change_amount'] = stock.get('f4', '')
item['volume'] = stock.get('f5', '')
item['amplitude'] = stock.get('f7', '')
item['high'] = stock.get('f15', '')
item['low'] = stock.get('f16', '')
item['open_price'] = stock.get('f17', '')
item['prev_close'] = stock.get('f18', '')
yield item
self.logger.info(f'成功解析 {len(stocks)} 条股票数据')
else:
self.logger.warning('未找到股票数据')
except json.JSONDecodeError as e:
self.logger.error(f'JSON解析错误: {e}')
except Exception as e:
self.logger.error(f'解析过程出错: {e}')
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
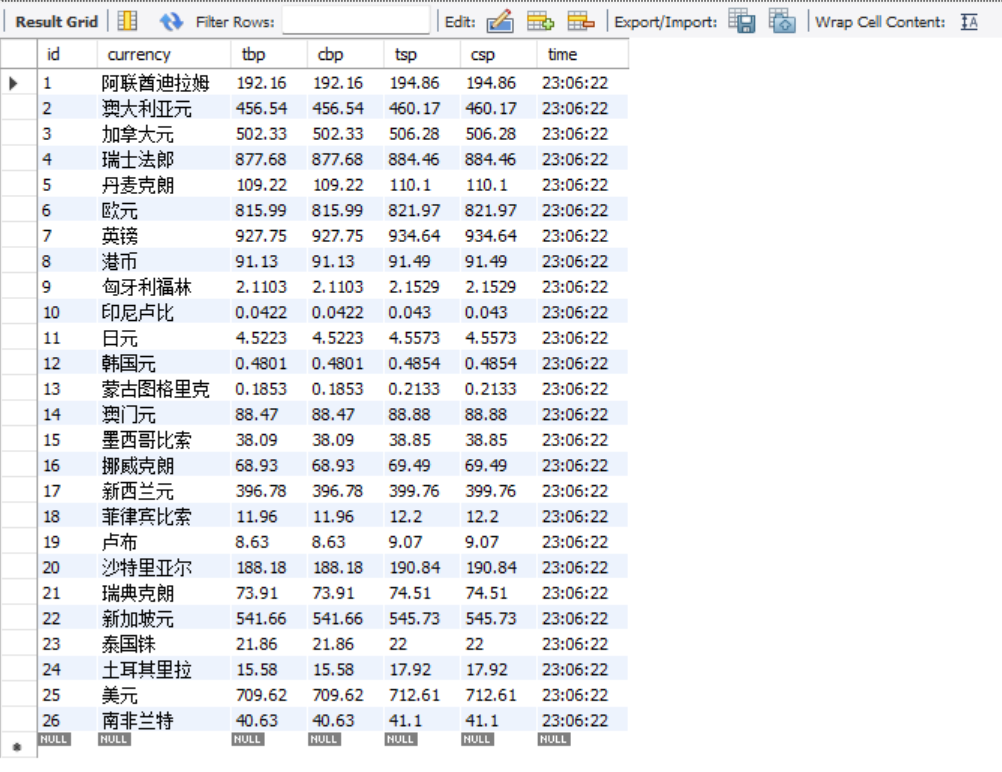
点击查看代码
import scrapy
from bocfx.items import BocRateItem
class BocSpider(scrapy.Spider):
name = "boc_rate"
allowed_domains = ["boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
self.logger.info("Page title: %s", response.xpath("//title/text()").get())
table = response.xpath('//table[.//text()[contains(."货币名称")]]')
if not table:
self.logger.warning("没有找到包含【货币名称】的表格,检查一下页面结构或 XPath")
return
rows = table.xpath(".//tr[position()>1]")
self.logger.info("找到 %d 行数据", len(rows))
for row in rows:
cols = row.xpath("./td//text()").getall()
cols = [c.strip() for c in cols if c.strip()]
if len(cols) < 8:
continue
item = BocRateItem()
item["currency"] = cols[0]
item["tbp"] = cols[1]
item["cbp"] = cols[2]
item["tsp"] = cols[3]
item["csp"] = cols[4]
item["time"] = cols[-1]
yield item
gitee文件链接:https://gitee.com/wangguangcheng/data-harvesting/tree/master/作业3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号