

102302112王光诚作业2
作业①:
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
运行结果:
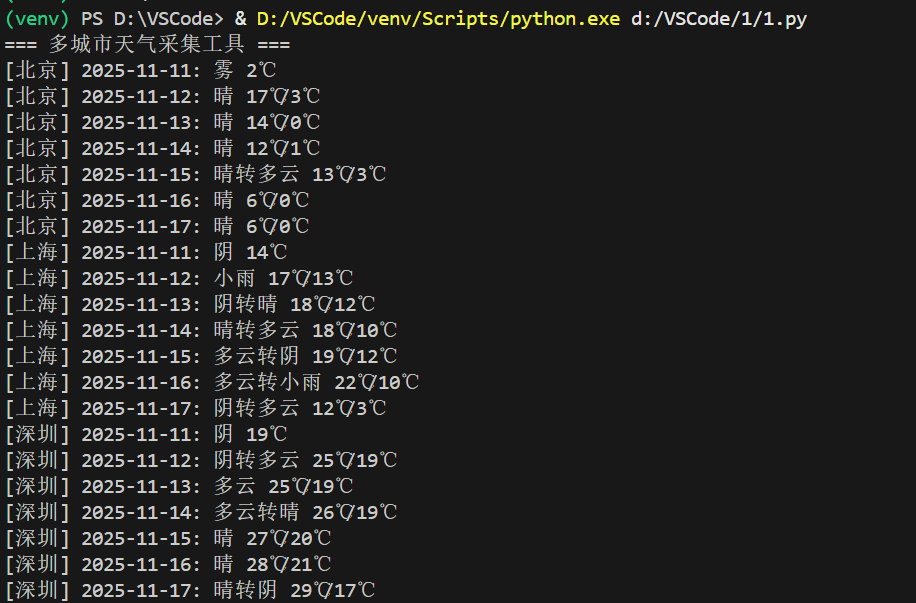
点击查看代码
import sqlite3
import requests
from bs4 import BeautifulSoup
from datetime import datetime, timedelta
CITY_INFO = {"北京": "101010100","上海": "101020100","深圳": "101280601"}
def init_database():
with sqlite3.connect("multi_city_weather.db") as conn:
conn.execute('''CREATE TABLE IF NOT EXISTS city_weather (city TEXT NOT NULL,date TEXT NOT NULL,weather TEXT,temp_range TEXT,PRIMARY KEY (city, date))''')
def parse_date(show_date):
day = int(show_date.split('日')[0])
today = datetime.now()
if day < today.day:
month = today.month + 1 if today.month < 12 else 1
else:
month = today.month
return f"{today.year}-{month:02d}-{day:02d}"
def fetch_weather(city_name, city_code):
url = f"http://www.weather.com.cn/weather/{city_code}.shtml"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
try:
response = requests.get(url, headers=headers, timeout=15)
response.encoding = "utf-8"
soup = BeautifulSoup(response.text, "lxml")
weather_list = []
for item in soup.find("ul", class_="t clearfix").find_all("li", limit=7):
raw_date = item.find("h1").get_text(strip=True)
std_date = parse_date(raw_date)
weather = item.find("p", class_="wea").get_text(strip=True)
temp_elem = item.find("p", class_="tem")
high_temp = temp_elem.find("span").get_text() if temp_elem.find("span") else None
low_temp = temp_elem.find("i").get_text()
temp_range = f"{high_temp}/{low_temp}" if high_temp else low_temp
weather_list.append((city_name, std_date, weather, temp_range))
print(f"[{city_name}] {std_date}: {weather} {temp_range}")
return weather_list
except Exception as e:
print(f"爬取{city_name}天气失败:{str(e)}")
return None
def batch_save_weather(data_list):
if not data_list:
return
with sqlite3.connect("multi_city_weather.db") as conn:
conn.executemany('''INSERT OR REPLACE INTO city_weather (city, date, weather, temp_range) VALUES (?, ?, ?, ?)''', data_list)
conn.commit()
def display_weather():
with sqlite3.connect("multi_city_weather.db") as conn:
cursor = conn.cursor()
for city in CITY_INFO.keys():
cursor.execute('''SELECT date, weather, temp_range FROM city_weather WHERE city = ? ORDER BY date''', (city,))
rows = cursor.fetchall()
print(f"\n===== {city} 7日天气预报 =====")
print(f"{'日期':<12} {'天气':<10} {'温度范围'}")
print("-" * 35)
for date, weather, temp in rows:
print(f"{date:<12} {weather:<10} {temp}")
if __name__ == "__main__":
print("=== 多城市天气采集工具 ===")
init_database()
all_weather_data = []
for city, code in CITY_INFO.items():
city_data = fetch_weather(city, code)
if city_data:
all_weather_data.extend(city_data)
if all_weather_data:
batch_save_weather(all_weather_data)
display_weather()
else:
print("未获取到任何天气数据")
作业②
要求:用requests和json解析方法定向爬取股票相关信息,并存储在数据库中。
运行结果:
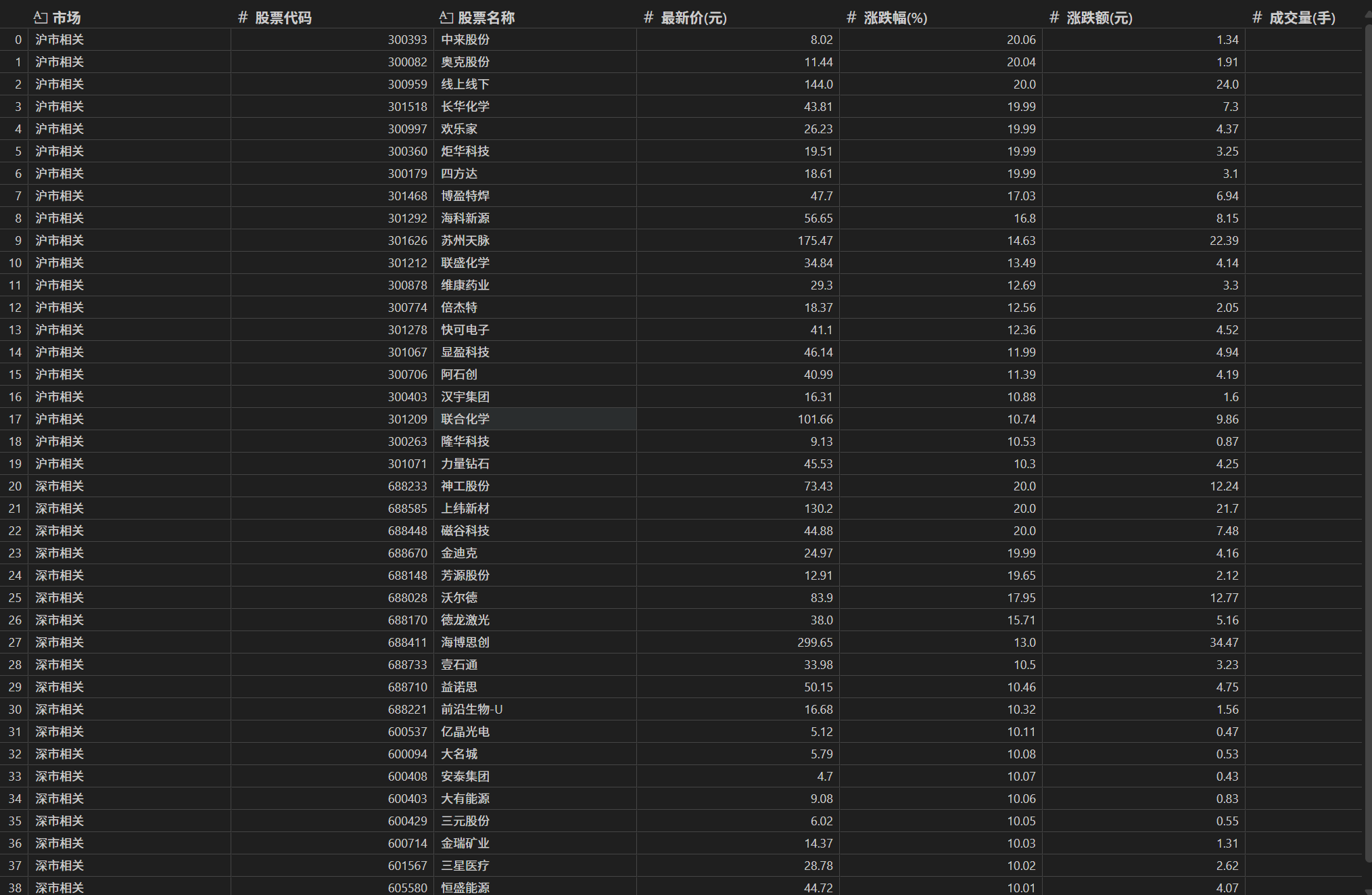
点击查看代码
import requests
import csv
import time
STOCK_API = "https://push2.eastmoney.com/api/qt/clist/get"
MARKETS = {"沪市相关": "m:0+t:6+f:!2,m:0+t:80+f:!2","深市相关": "m:1+t:2+f:!2,m:1+t:23+f:!2"}
def fetch_stock_data(market_code):
params = {"np": "1","fltt": "1","invt": "2","fs": market_code,"fields": "f12,f14,f2,f3,f4,f5,f6,f15,f16,f17,f18","fid": "f3","pn": "1","pz": "20","po": "1","dect": "1","ut": "fa5fd1943c7b386f172d6893dbfba10b","_": str(int(time.time() * 1000))}
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0","Referer": "https://quote.eastmoney.com/","Cookie": "fullscreengg=1; fullscreengg2=1; qgqp_b_id=10209ad2247be80fafc4af8af210a5b5; st_nvi=mEThlJ18zhrYSL8aEaDp9ebd5; st_si=87546796007713; st_asi=delete; nid=001779044e6a26d135f77f7e69a8f130; nid_create_time=1762855150680; gvi=wDXVAHYlwLDkik6UaDqET3805; gvi_create_time=1762855150680; st_pvi=31396518752565; st_sp=2025-11-11%2017%3A59%3A10; st_inirUrl=; st_sn=2; st_psi=20251111175918901-113200301321-7498034023"}
try:
response = requests.get(STOCK_API, params=params, headers=headers, timeout=10)
return response.json().get("data", {}).get("diff", [])
except Exception as e:
print(f"请求失败:{e}")
return []
def parse_stock_data(raw_data, market_name):
parsed = []
for item in raw_data:
parsed.append({"市场": market_name,"股票代码": item.get("f12", ""),"股票名称": item.get("f14", ""),"最新价(元)": round(item.get("f2", 0) / 100, 2),"涨跌幅(%)": round(item.get("f3", 0) / 100, 2),"涨跌额(元)": round(item.get("f4", 0) / 100, 2),"成交量(手)": round(item.get("f5", 0) / 100, 0),"成交额(万元)": round(item.get("f6", 0) / 10000, 2),"今开(元)": round(item.get("f15", 0) / 100, 2),"昨收(元)": round(item.get("f16", 0) / 100, 2),"最高(元)": round(item.get("f17", 0) / 100, 2),"最低(元)": round(item.get("f18", 0) / 100, 2)})
return parsed
def save_to_csv(stocks, filename="stock_data.csv"):
if not stocks:
return
fieldnames = stocks[0].keys()
with open(filename, "w", encoding="utf-8-sig", newline="") as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(stocks)
print(f"\n数据已保存到 {filename}(可用Excel、记事本打开)")
def print_to_console(stocks):
if not stocks:
print("无数据")
return
print(f"\n{'市场':<8} {'代码':<8} {'名称':<8} {'最新价':<8} {'涨跌幅(%)':<10}")
print("-" * 45)
for s in stocks[:5]:
print(f"{s['市场']:<8} {s['股票代码']:<8} {s['股票名称']:<8} {s['最新价(元)']:<8} {s['涨跌幅(%)']:<10}")
if len(stocks) > 5:
print(f"... 省略{len(stocks)-5}条数据")
if __name__ == "__main__":
print("===== 开始爬取股票数据 =====")
all_stocks = []
for market_name, market_code in MARKETS.items():
print(f"\n爬取{market_name}中...")
raw_data = fetch_stock_data(market_code)
parsed_data = parse_stock_data(raw_data, market_name)
all_stocks.extend(parsed_data)
print(f"已获取{len(parsed_data)}条{market_name}数据")
print("\n===== 爬取结果(前5条) =====")
print_to_console(all_stocks)
save_to_csv(all_stocks)
作业③:
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
运行结果:
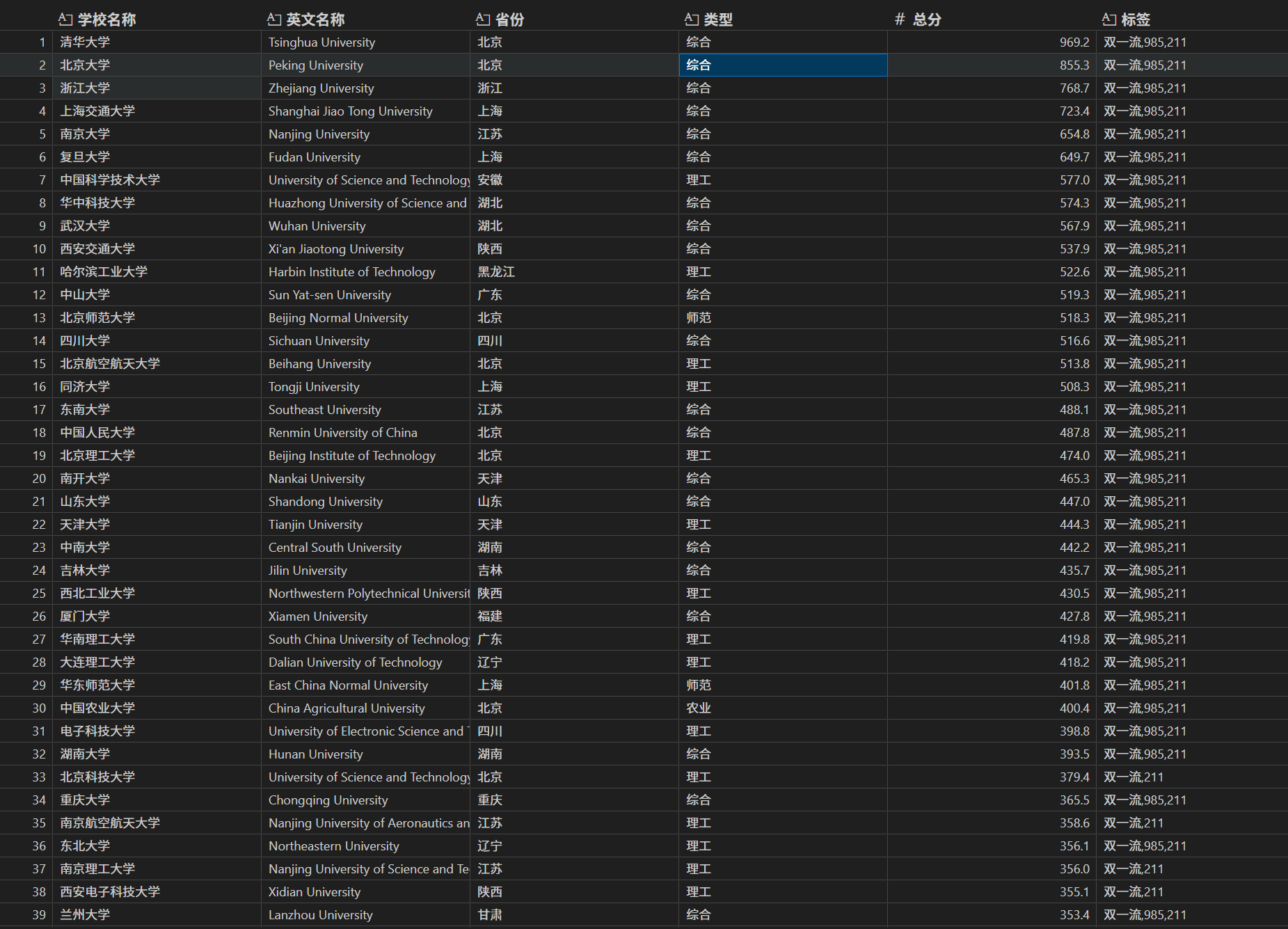

点击查看代码
import requests
import csv
import execjs
API_URL = "https://www.shanghairanking.cn/_nuxt/static/1762223212/rankings/bcur/2021/payload.js"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/126.0.0.0 Safari/537.36","Referer": "https://www.shanghairanking.cn/rankings/bcur/2021"}
def crawl_universities():
all_data = []
try:
response = requests.get(API_URL, headers=headers, timeout=15)
js_content = response.text
func_str = js_content.split(",", 1)[1].rsplit(")", 1)[0].strip()
ctx = execjs.compile(f"var data = {func_str}; data;")
raw_data = ctx.eval("data")
data_list = raw_data.get("data", [])
if not data_list:
print("data列表为空!")
return all_data
first_item = data_list[0]
universities = first_item.get("univData", [])
print(f"找到的学校数量:{len(universities)}")
if not universities:
print("univData为空,检查是否有其他字段!")
return all_data
for univ in universities:
all_data.append({"排名": univ.get("ranking", ""),"学校名称": univ.get("univNameCn", ""),"英文名称": univ.get("univNameEn", ""),"省份": univ.get("province", ""),"类型": univ.get("univCategory", ""),"总分": univ.get("score", ""),"标签": ",".join(univ.get("univTags", [])) if isinstance(univ.get("univTags"), list) else ""})
print(f"共爬取到{len(all_data)}所学校")
except Exception as e:
print(f"爬取出错:{e}")
return all_data
def save_to_csv(data, filename="中国大学2021主榜.csv"):
if not data:
print("没有数据可保存!")
return
headers = ["排名", "学校名称", "英文名称", "省份", "类型", "总分", "标签"]
with open(filename, "w", encoding="utf-8-sig", newline="") as f:
writer = csv.DictWriter(f, fieldnames=headers)
writer.writeheader()
writer.writerows(data)
print(f"数据已保存到 {filename}")
if __name__ == "__main__":
print("开始爬取中国大学2021主榜...")
universities = crawl_universities()
save_to_csv(universities)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号