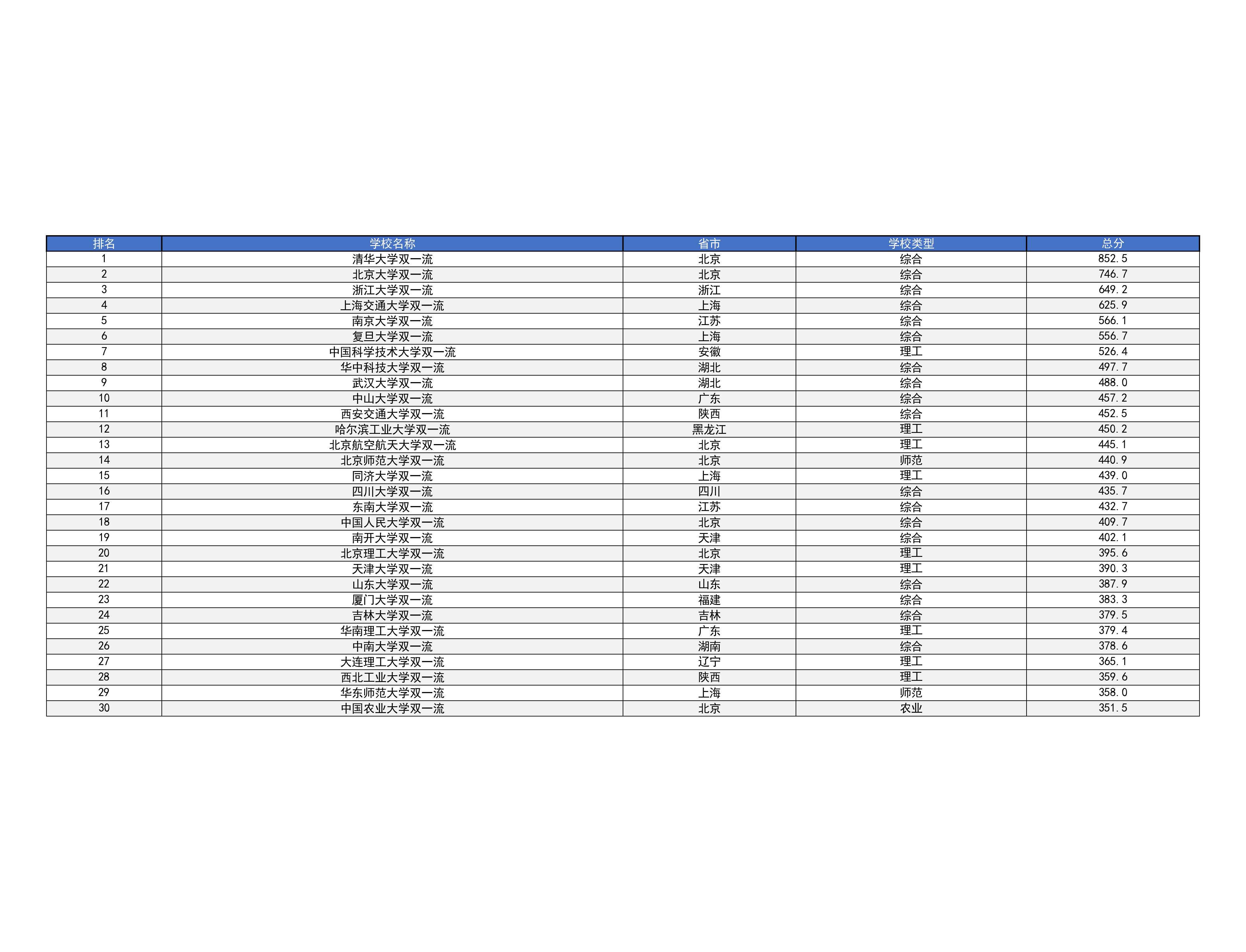
![2020中国大学排名表格]()
点击查看代码
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
import re
# 图片尺寸
FIG_SIZE = (16, 12)
# 图片清晰度
DPI = 300
# 图片保存路径
SAVE_PATH = '2020中国大学排名表格优化版.png'
# 爬取大学排名数据并处理学校名称
def crawl_university_ranking():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/120.0.0.0 Safari/537.36'
}
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
ranking_data = []
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('table', class_='rk-table')
if not table:
print("未找到排名表格!")
return None
tbody = table.find('tbody')
for row in tbody.find_all('tr'):
cells = row.find_all('td')
if len(cells) < 5:
continue
rank = cells[0].text.strip() or "未知"
province = cells[2].text.strip() or "未知"
category = cells[3].text.strip() or "未知"
score = cells[4].text.strip() or "0"
name_tag = cells[1].find('a')
raw_name = name_tag.text.strip() if name_tag else cells[1].text.strip()
chinese_name = re.sub(r'[^\u4e00-\u9fa5]', '', raw_name)
name = chinese_name if chinese_name else raw_name.split()[0]
ranking_data.append([rank, name, province, category, score])
return ranking_data
except Exception as e:
print(f"爬取失败:{e}")
return None
# 生成表格图片(调整样式避免文字溢出)
def generate_table_image(ranking_data):
if not ranking_data:
print("无数据,无法生成图片!")
return
headers = ['排名', '学校名称', '省市', '学校类型', '总分']
fig, ax = plt.subplots(figsize=FIG_SIZE)
ax.axis('off')
table = ax.table(
cellText=ranking_data,
colLabels=headers,
cellLoc='center',
loc='center',
colWidths=[0.1, 0.4, 0.15, 0.2, 0.15]
)
table.auto_set_font_size(False)
table.set_fontsize(9)
for i in range(len(headers)):
header_cell = table[(0, i)]
header_cell.set_facecolor('#4472C4')
header_cell.set_text_props(weight='bold', color='white')
for row in range(1, len(ranking_data) + 1):
for col in range(len(headers)):
cell = table[(row, col)]
cell.set_facecolor('#F2F2F2' if row % 2 == 0 else 'white')
cell.set_linewidth(0.5)
cell.set_edgecolor('black')
cell.set_text_props(wrap=True)
plt.savefig(
SAVE_PATH,
dpi=DPI,
bbox_inches='tight',
pad_inches=0.5
)
plt.close()
print(f"优化后表格已保存:{SAVE_PATH}")
if __name__ == "__main__":
data = crawl_university_ranking()
if data:
generate_table_image(data)
一开始没加请求头,结果根本拿不到数据,后来加上浏览器标识才成功,这点挺重要的。处理学校名称时,用小技巧去掉了多余的非中文字符,不然名字会乱七八糟的。生成表格图片时,调了好多次字体大小和列宽,才解决文字溢出的问题。
![103AD564E222D582B054B95F29BB7D97]()
点击查看代码
import requests
import re
def crawl_suning_bookbags():
# 苏宁易购"书包"搜索结果页URL
url = "https://search.suning.com/书包/"
# 请求头:包含浏览器标识、来源页及Cookie(用于模拟正常访问)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36",
"Referer": "https://www.suning.com/",
"Cookie": "SN_SESSION_ID=81242af7-4eaf-41db-8ce1-ad6e7ab08762; streetCode=5910199; _snvd=1761561518311bvASEcVh4hP; cityId=9018; districtId=10124; cityCode=591; _snzwt=THv2k119a253f9f0dMNdMa5a2; hm_guid=c01836c8-b745-4f39-9d76-521f5e539c5f; _df_ud=14e355b1-82cc-414d-ba51-b44993d54c22; tradeMA=130; totalProdQty=0; route=2abc71cbebfe1f96c864f000154963e8; sesab=ACBACBEBBAEABB; sesabv=24%2C12%2C9%2C1%2C28%2C8%2C4%2C21%2C4%2C4%2C8%2C1%2C1%2C2; _snsr=www.doubao.com%7Creferral%7C%7C%7C; authId=sivckx8XKGl1QfEwIAly8XQf6R9dfd4Hfa; secureToken=1DC02C0DD70A565E82076C12A2F71364; ssotbrd=TGTPbEwjtdV3DxkNSSp5LxiG228H6wg5L00SoioOX2A; _snmc=1; _device_session_id=p_2d98e6e9-9d9f-4c11-86d6-8616bbd7c768; ariaDefaultTheme=null; _snadtp=1; _snadid=107750173210000000620251027; smhst=11226571823|0000000000; SN_CITY=150_591_1000018_9018_01_10124_1_1_99_5910199; _snma=1%7C176156151744637041%7C1761561517446%7C1761567907393%7C1761567912841%7C16%7C4; _snmp=176156791270562872; _snmb=176156684607463668%7C1761567912852%7C1761567912842%7C8; _snms=176156791285261848; token=6267113b-f780-4360-ad34-998a28fda379"
}
try:
# 发送请求并获取页面内容
response = requests.get(url, headers=headers, timeout=15)
print(f"请求状态:{'成功' if response.status_code == 200 else f'失败(状态码:{response.status_code})'}")
response.encoding = "utf-8"
html = response.text
# 提取所有商品最外层容器(<li class="item-wrap...">)
product_blocks = re.findall(r'<li class="item-wrap[^>]*>(.*?)</li>', html, re.DOTALL)
print(f"识别到商品总数:{len(product_blocks)}")
# 存储提取的商品数据(名称+价格)
data_list = []
for block in product_blocks:
# 提取价格(匹配<span class="def-price">中的数字,格式xx.xx)
price_match = re.search(r'<span class="def-price[^>]*><i>¥</i>(\d+)<i>\.(\d+)</i></span>', block, re.DOTALL)
# 提取商品名(匹配<a class="sellPoint yibao">中的文本)
name_match = re.search(r'<a class="sellPoint yibao[^>]*>(.*?)</a>', block, re.DOTALL | re.UNICODE)
# 过滤并整理有效数据
if price_match and name_match:
price = f"{price_match.group(1)}.{price_match.group(2)}"
name = re.sub(r'\s+', ' ', name_match.group(1).strip())
data_list.append((name, price))
# 按格式输出商品表格
print(f"\n{'序号':<6}{'价格':<10}{'商品名'}")
for idx, (name, price) in enumerate(data_list, 1):
print(f"{idx:<6}{price:<10}{name[:50]}")
print(f"\n爬取完成!共获取 {len(data_list)} 个有效书包商品数据")
except Exception as e:
print(f"爬取过程出错:{str(e)}")
if __name__ == "__main__":
crawl_suning_bookbags()
爬苏宁书包数据的时候,最开始没加 Cookie 和 Referer,请求一直失败,加上之后才顺利拿到页面内容,提取价格和商品名时,得对着网页源码找准确的匹配格式,不然会漏数据或者提错。
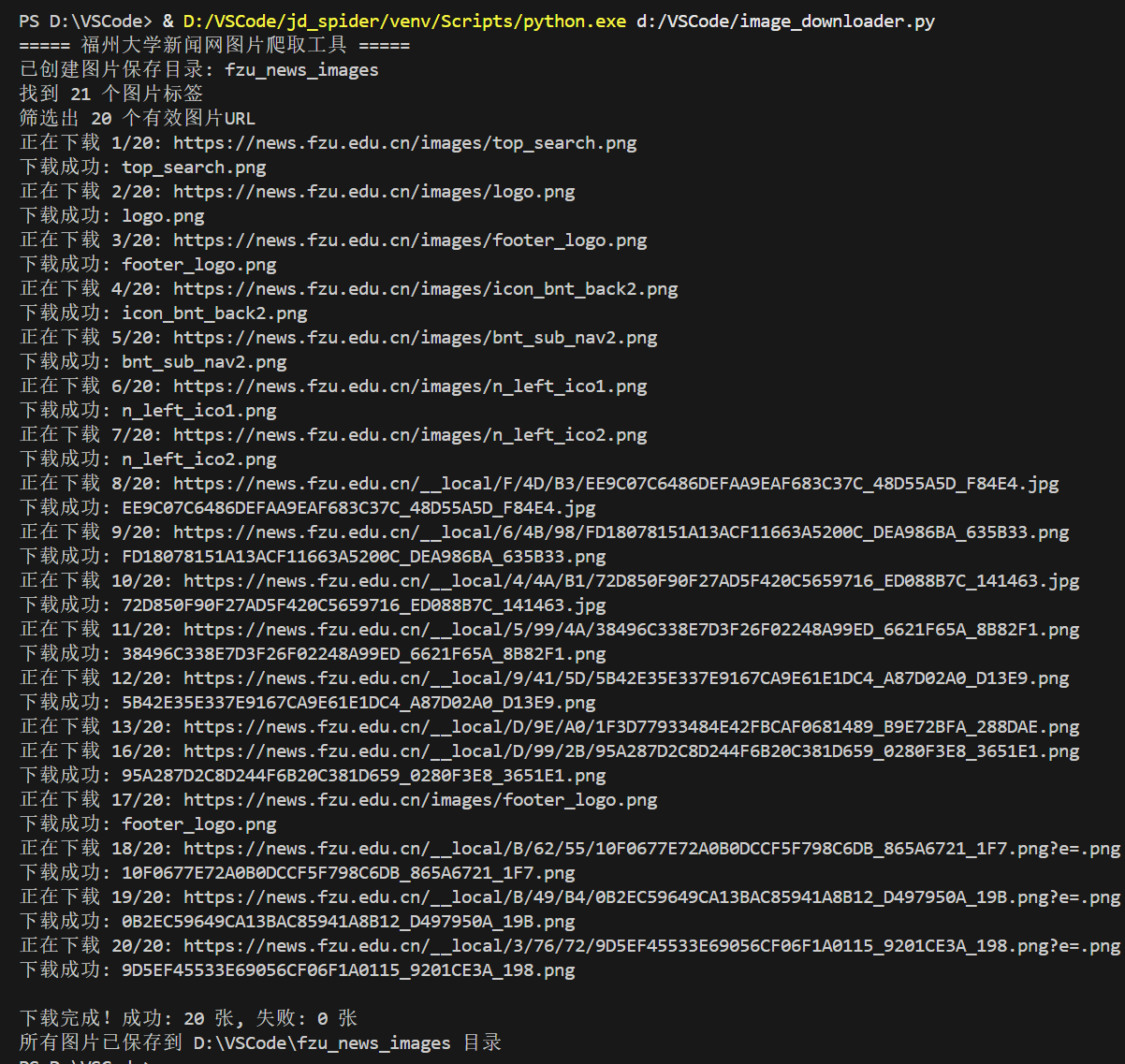
![EBCF2264BCF02D3228F78B677C7944FA]()
点击查看代码
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import time
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
base_url = "https://news.fzu.edu.cn/yxfd.htm"
save_dir = "fzu_news_images"
def create_save_directory():
if not os.path.exists(save_dir):
os.makedirs(save_dir)
print(f"已创建图片保存目录: {save_dir}")
else:
print(f"图片保存目录已存在: {save_dir}")
def get_all_image_urls(url):
try:
response = requests.get(url, headers=headers, timeout=10)
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, 'html.parser')
img_tags = soup.find_all('img')
print(f"找到 {len(img_tags)} 个图片标签")
image_urls = []
for img in img_tags:
img_url = img.get('src')
if img_url:
full_url = urljoin(base_url, img_url)
if full_url.lower().endswith(('.jpg', '.jpeg', '.png')):
image_urls.append(full_url)
print(f"筛选出 {len(image_urls)} 个有效图片URL")
return image_urls
except Exception as e:
print(f"获取图片URL时出错: {str(e)}")
return []
def download_images(image_urls):
if not image_urls:
print("没有可下载的图片URL")
return
success_count = 0
fail_count = 0
for i, url in enumerate(image_urls, 1):
try:
print(f"正在下载 {i}/{len(image_urls)}: {url}")
filename = os.path.basename(url).split('?')[0]
save_path = os.path.join(save_dir, filename)
response = requests.get(url, headers=headers, timeout=15, stream=True)
if response.status_code == 200:
with open(save_path, 'wb') as f:
for chunk in response.iter_content(1024):
f.write(chunk)
success_count += 1
print(f"下载成功: {filename}")
else:
fail_count += 1
print(f"下载失败,状态码: {response.status_code}")
time.sleep(1)
except Exception as e:
fail_count += 1
print(f"下载 {url} 时出错: {str(e)}")
print(f"\n下载完成!成功: {success_count} 张, 失败: {fail_count} 张")
print(f"所有图片已保存到 {os.path.abspath(save_dir)} 目录")
def main():
print("===== 福州大学新闻网图片爬取工具 =====")
create_save_directory()
image_urls = get_all_image_urls(base_url)
download_images(image_urls)
if __name__ == "__main__":
main()
跟课上作业差不多,区别在于不仅提取jpg,还要提取jpeg和png,在代码图片提取那需要增加对应的规则
gitee文件链接:https://gitee.com/wangguangcheng/data-harvesting/tree/master/%E4%BD%9C%E4%B8%9A1



 浙公网安备 33010602011771号
浙公网安备 33010602011771号