
字节码的组成
之前看了美团技术团队推送的一篇文章,介绍了字节码增强技术,写的很好,自己也记录一下,增强一下记忆,也方便日后巩固学习,有兴趣的可以去搜索美团技术团队的原文
字节码是JVM的底层基础知识,如果能够掌握对于排查问题会有更深层次的理解
1.什么是字节码
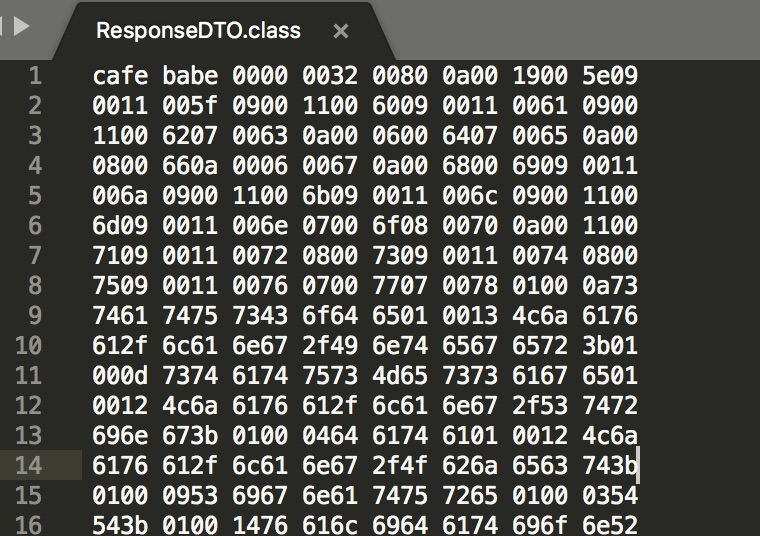
首先我们看看什么是字节码,找到一个.class文件,看看长什么样子
Java之所以可以一次编译,到处运行,首先是因为JVM针对各种操作系统和平台都进行了定制,二是无论在什么平台,都可以通过javac命令将一个.java文件编译成固定格式的字节码(.class文件)供JVM使用
之所以被称之为字节码,是因为.class文件是由十六进制值组成的,JVM以两个十六进制值为一组,就是以字节为单位进行读取
2.字节码的结构
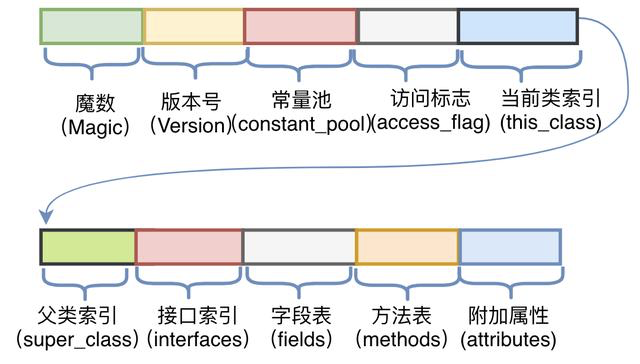
.java文件编译后生成的字节码文件,打开如上图,JVM对字节码是有规范要求的,要求每一个字节码文件都要有十部分按照固定的顺序组成,整体的结构和顺序如下图:
(1)魔数
所有的.class文件的前4个字节都是魔数,魔数以一个固定值:0xCAFEBABE,放在文件的开头,JVM就可以根据这个文件的开头来判断这个文件是否可能是一个.class文件,如果是这个开头,才会往后执行下面的操作

一直困惑的java的图标为什么是一杯咖啡,看到这里就大概明白了,这个魔数的固定值是Java之父James Gosling指定的,意为CafeBabe(咖啡宝贝)
(2)版本号
版本号是魔术之后的4个字节,前两个字节表示次版本号(Minor Version),后两个字节表示主版本号(Major Version),上面的0000 0032,次版本号0000转为十进制是0,主版本号0032 转为十进制50,对应下图的版本映射关系,可以看到对应的java版本号是1.6
各个版本的对应关系
| JDK版本号 | Class版本号 | 16进制 |
| 1.1 | 45.0 | 00 00 00 2D |
| 1.2 | 46.0 | 00 00 00 2E |
| 1.3 | 47.0 | 00 00 00 2F |
| 1.4 | 48.0 | 00 00 00 30 |
| 1.5 | 49.0 | 00 00 00 31 |
| 1.6 | 50.0 | 00 00 00 32 |
| 1.7 | 51.0 | 00 00 00 33 |
| 1.8 | 52.0 | 00 00 00 34 |
(3)常量池(Constant Pool)
紧接着主版本号之后的字节为常量池入口,常量池中有两类常量:字面量和符号引用,字面量是代码中申明为Final的常量值,符号引用是如类和接口的全局限定名、字段的名称和描述符、方法的名称和描述符。常量池整体分为两个部分:常量池计数器以及常量池数据区
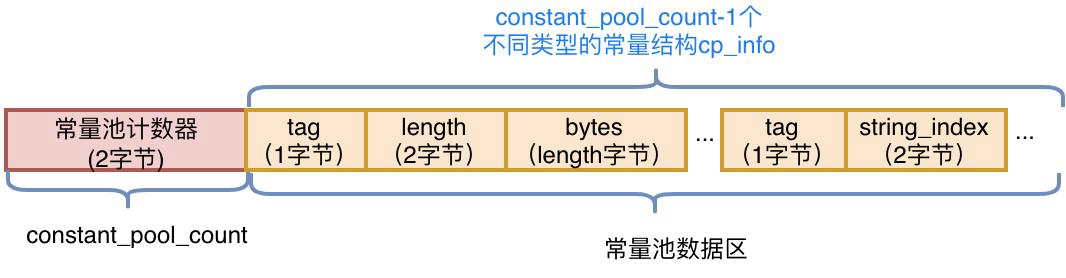
* 常量池计数器(constant_pool_coun):由于常量的数量不固定,需要先放置两个字节来表示常量池容量计数值
cafe babe 0000 0032 0080
第一幅图中的0080转为十进制是128,排除掉下标0,代表这个类文件中一共有127个常量
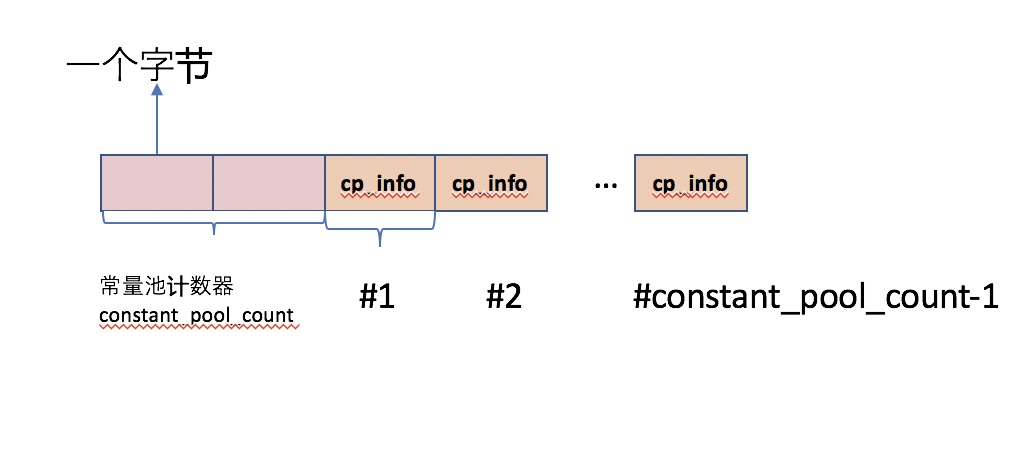
常量池计数器是从1开始的,不是从0开始的,在制定class文件规范的时候,将第0项常量空出来是有原因的,这样做是为了满足某些指向常量池的索引值的数据在特定情况下情况下表达 不引用任何一个常量池数据项,这种情况下可以将索引值设置为0
* 常量池数据区:数据区是由(constant_pool_count-1)个cp_info结构组成,一个cp_info结构对应一个常量,在字节码中共有14种类型的cp_info,每种类型的结构都是固定的
常量池数据区也是从1开始的,第一个常量池项(cp_info)的索引值为1,最后一个常量池项的索引值为constant_pool_count-1
各类型的cp_info结构是:
cp_info{
u1 tag;
u1 info[];
}
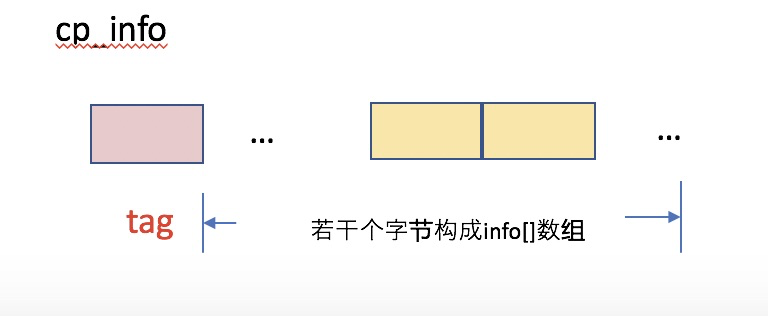
不同类型的cp_info的构成描述:
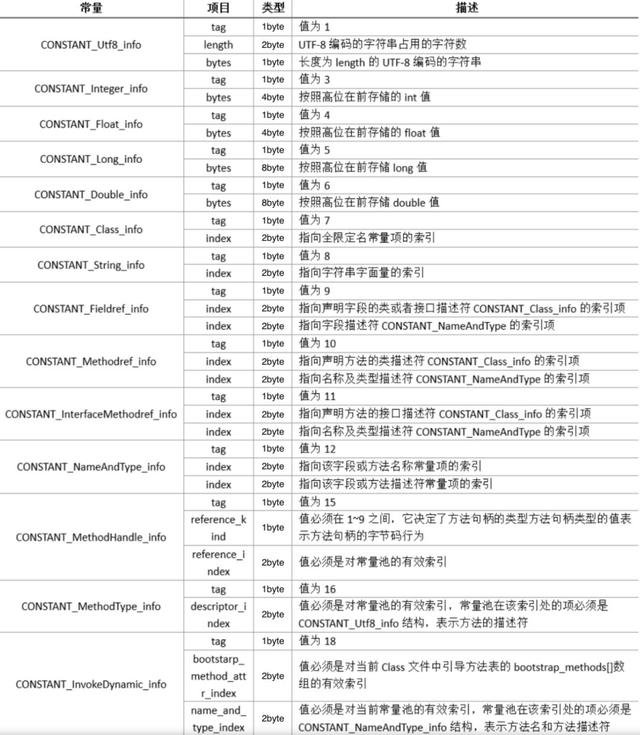
cp_info表示的范围:
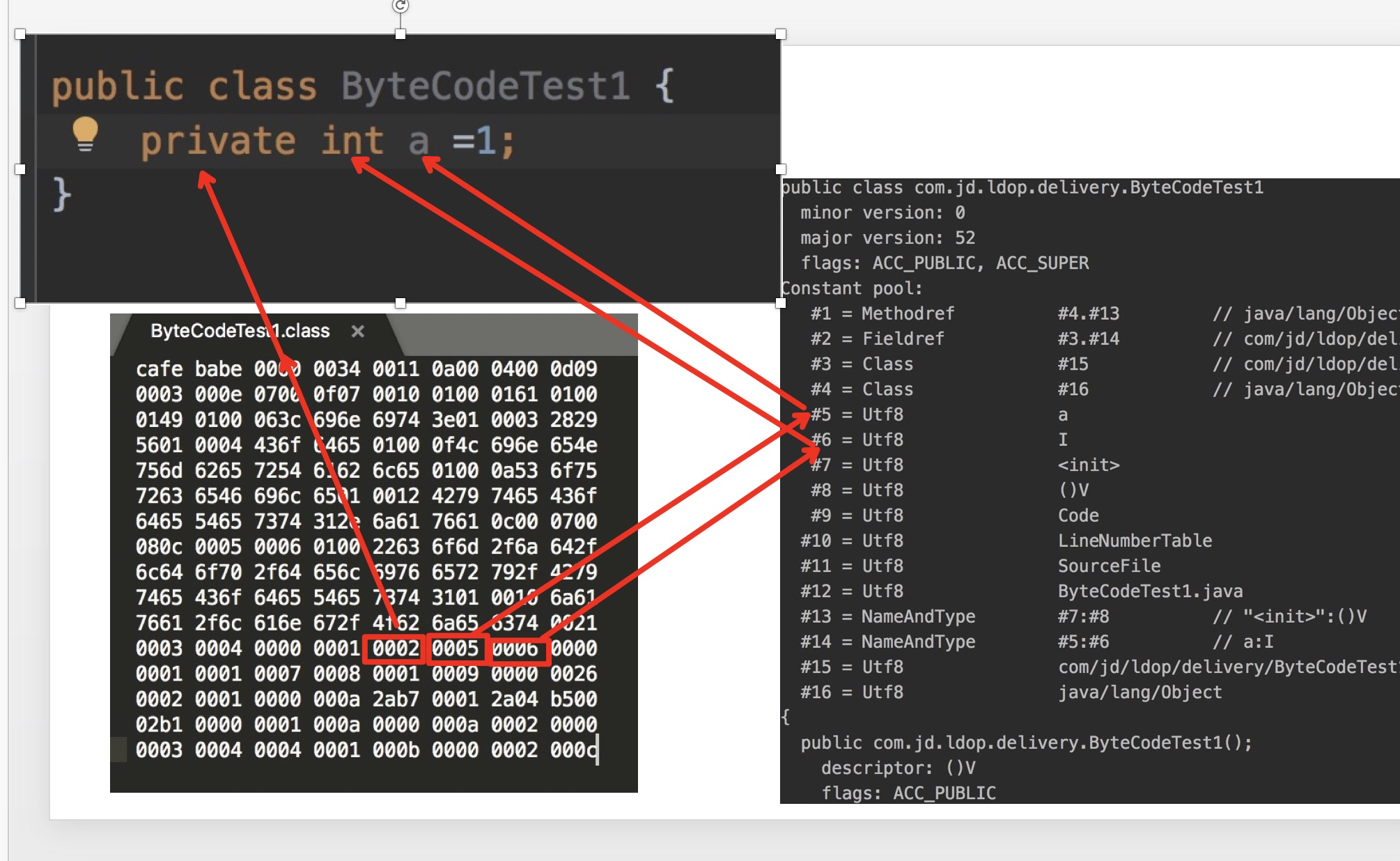
我们新定义一个类: ByteCodeTest1

通过javac编译为class文件,可以看到对应定字节码为:
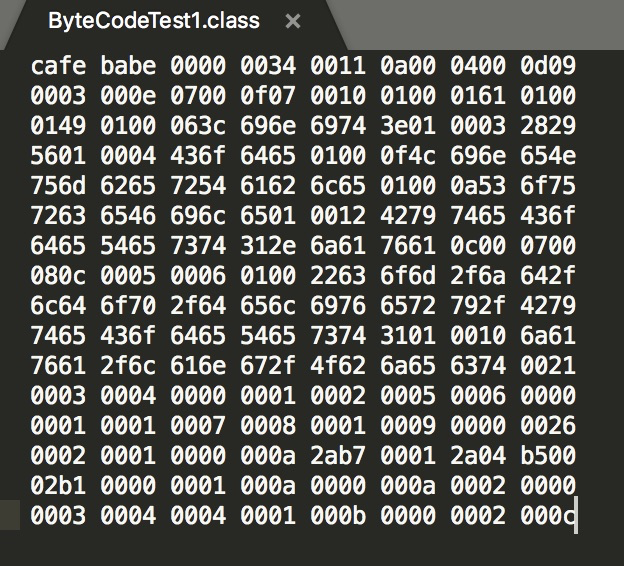
通过上面的介绍我们知道 这个编译的版本是0000 0034 对应的jdk版本是1.8,紧跟其后的两个字节是 0011 转为十进制是17,最终可以确定这个类中的常量总共有17-1=16个
为了方便查看每个cp_info结构类型和值,我们可以使用javap -v ByteCodeTest1.class 命令,查看JVM反编译后的完整的常量池,如下图所示:

可以看到常量池中的常量的索引值总共是到#16,和计算出来的是一致的
我们以CONSTANT_utf8_info为例,具体的结构图解析如下:
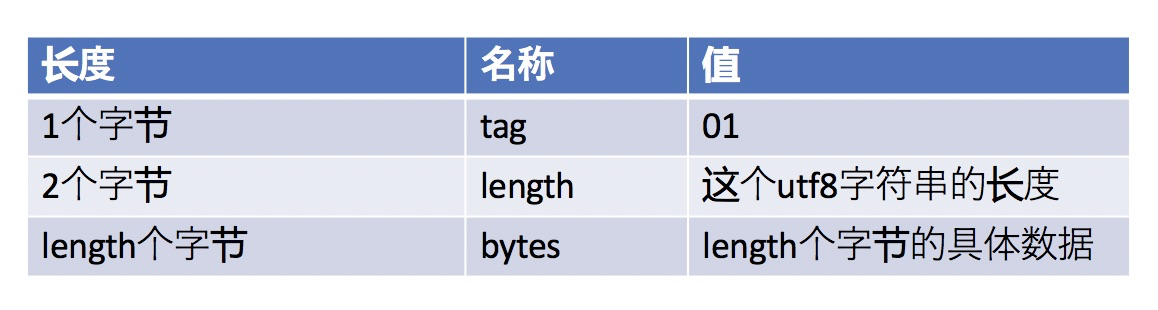
对照上图中的索引位置,我们从#5位置开始的cp_info是utf8_info类型的,取出来:
0100 0161
首先1个字节 表示的是tag ,那么就是 前两个字节01 拿出来,对应的值对比结构图就是01
接着2个字节代表utf8字符串的长度,那么把 紧随气候的4个字节拿出来,00 01,表示后面的1个字节为数据
最后把紧随其后的1个字节拿出来,61,表示的是具体的数据,对应的ascii码为"a"
整体翻译过来就是:该常量类型为utf8字符串,长度为一个字节,具体的数据为"a"
其他类型的cp_info结构也是大概的构造,再来看一下int和float类型的,我们知道int和float在java语言中是占用4个字节,那么在class文件中占用多少呢
先定义一个类ByteCodeTest2:

通过javap -v 查看编译后的:
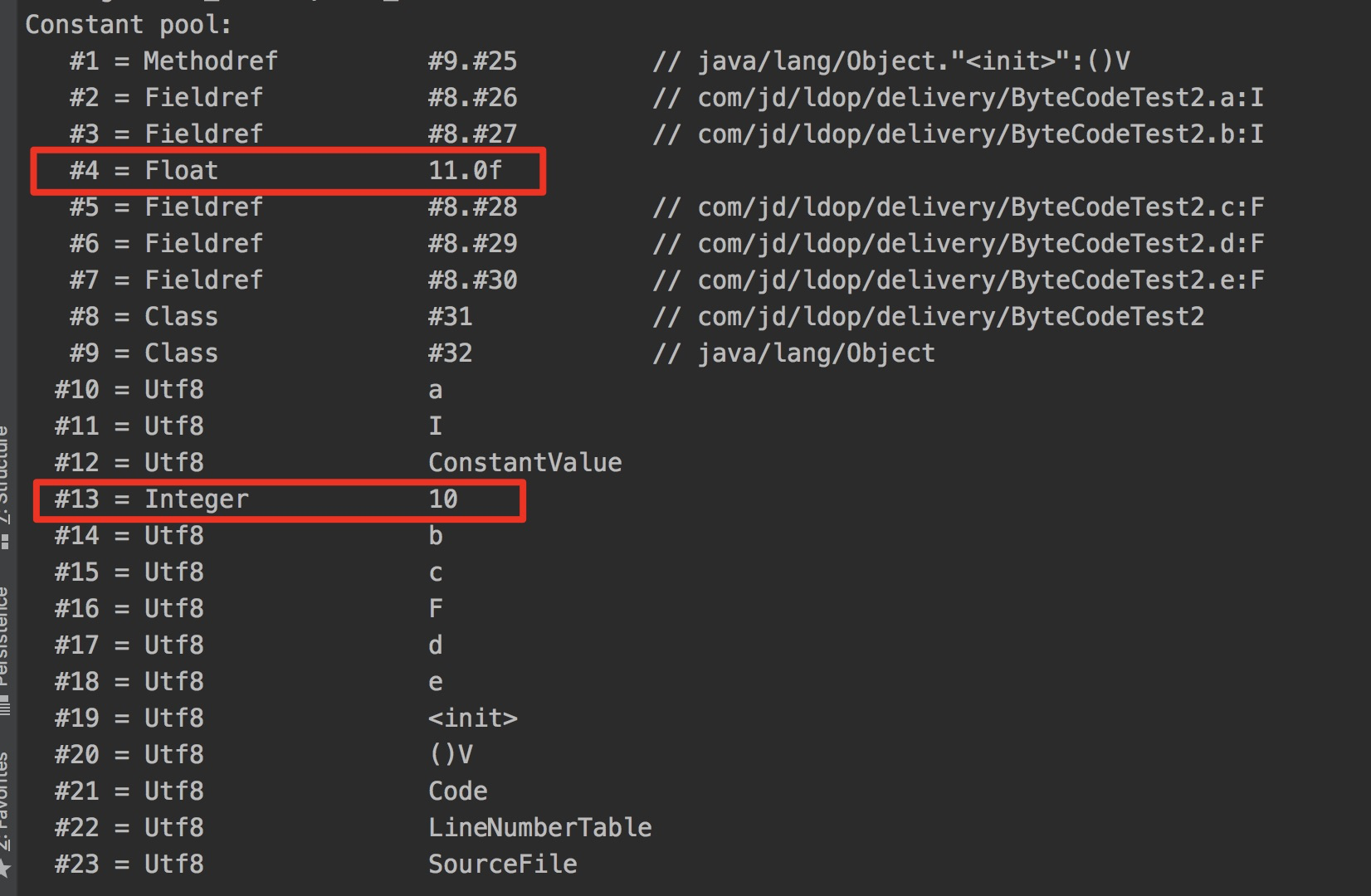
从结果上看常量池中#4个索引值的常量项对应的是CONSTANT_Float_info,值为11,其他的类型的基本都是按照这种方式去识别
(4)访问标志
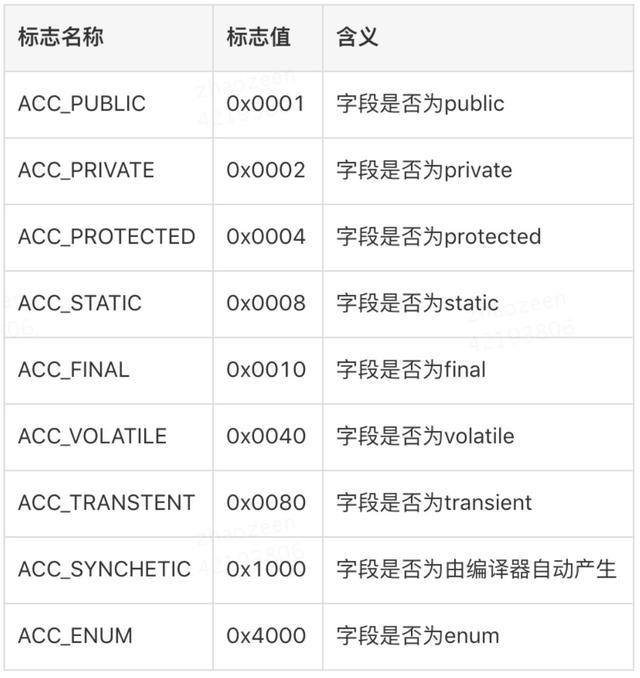
常量池结束后的两个字节,描述的是类还是接口,以及是否被Public、Abstract、Final等修饰符修饰,JVM规范规定了9种访问标示(Access_Flag)
JVM是通过按位或操作来描述所有的访问标示的,比如类的修饰符是Public Final,则对应的访问修饰符的值为ACC_PUBLIC | ACC_FINAL,即0x0001 | 0x0010=0x0011
我们用javap之后的可以明确的看出来:
(5)当前类名
访问标志后的两个字节,描述的是当前类的全限定名,这两个字节保存的值是常量池中的索引值,根据索引值就能在常量池中找到这个类的全限定名
(6)父类名称
当前类名后的两个字节,描述的父类的全限定名,也是保存的常量池中的索引值

(7)接口信息
父类名称后的两个字节,是接口计数器,描述了该类或者父类实现的接口数量,紧接着的n个字节是所有接口名称的字符串常量的索引值
(8)字段表
用于描述类和接口中声明的变量,包含类级别的变量和实例变量,但是不包含方法内部声明的局部变量,字段表也分为两个部分,第一部分是两个字节,描述字段个数,第二部分是每个字段的详细信息fields_info
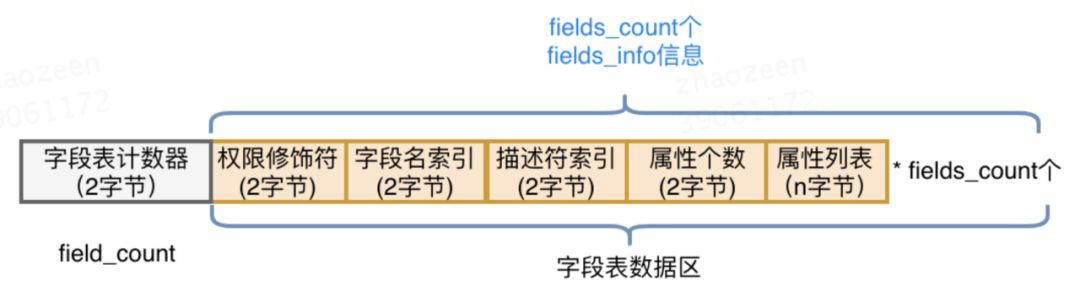
以上面的图示为例:
0001表示字段的个数为1,0002对应的权限修饰符为Private,通过在常量池中的索引值0005找到字段名为a,索引值0006找到描述符为I(表示int),0000表示字段属性个数为0,整体翻译一下就是:
在一个类中声明的变量private int a
(9)方法表
字段表结束后为方法表,方法表也分为两个部分,第一个部分是两个字节表述方法的个数,第二部分是每个方法的详细信息
方法的访问信息比较复杂,包括方法的访问标志、方法名、方法的描述符和方法的属性:

方法的权限修饰符也是按照同样的方法可以查询到,方法名和方法的描述符都是常量池中的索引值,可以通过索引值在常量池中找到。而“方法的属性”这一部分较为复杂,直接借助javap -verbose将其反编译为人可以读懂的信息进行解读。可以看到属性中包括以下三个部分:
- “Code区”:源代码对应的JVM指令操作码,在进行字节码增强时重点操作的就是“Code区”这一部分。
- “LineNumberTable”:行号表,将Code区的操作码和源代码中的行号对应,Debug时会起到作用(源代码走一行,需要走多少个JVM指令操作码)。
- “LocalVariableTable”:本地变量表,包含This和局部变量,之所以可以在每一个方法内部都可以调用This,是因为JVM将This作为每一个方法的第一个参数隐式进行传入。当然,这是针对非Static方法而言

(10)附加属性表
字节码的最后一部分,该项存放了在该文件中类或接口所定义属性的基本信息。
在上图中,Code区的红色编号0~17,就是.java中的方法源代码编译后让JVM真正执行的操作码。为了帮助人们理解,反编译后看到的是十六进制操作码所对应的助记符,十六进制值操作码与助记符的对应关系,以及每一个操作码的用处可以查看Oracle官方文档进行了解,在需要用到时进行查阅即可。比如上图中第一个助记符为iconst_2,对应到图2中的字节码为0x05,用处是将int值2压入操作数栈中。以此类推,对0~17的助记符理解后,就是完整的add()方法的实现。
JVM的指令集是基于栈而不是寄存器,基于栈可以具备很好的跨平台性(因为寄存器指令集往往和硬件挂钩),但缺点在于,要完成同样的操作,基于栈的实现需要更多指令才能完成(因为栈只是一个FILO结构,需要频繁压栈出栈)。另外,由于栈是在内存实现的,而寄存器是在CPU的高速缓存区,相较而言,基于栈的速度要慢很多,这也是为了跨平台性而做出的牺牲。
上面说的操作码或者操作集合,其实控制的就是这个JVM的操作数栈。
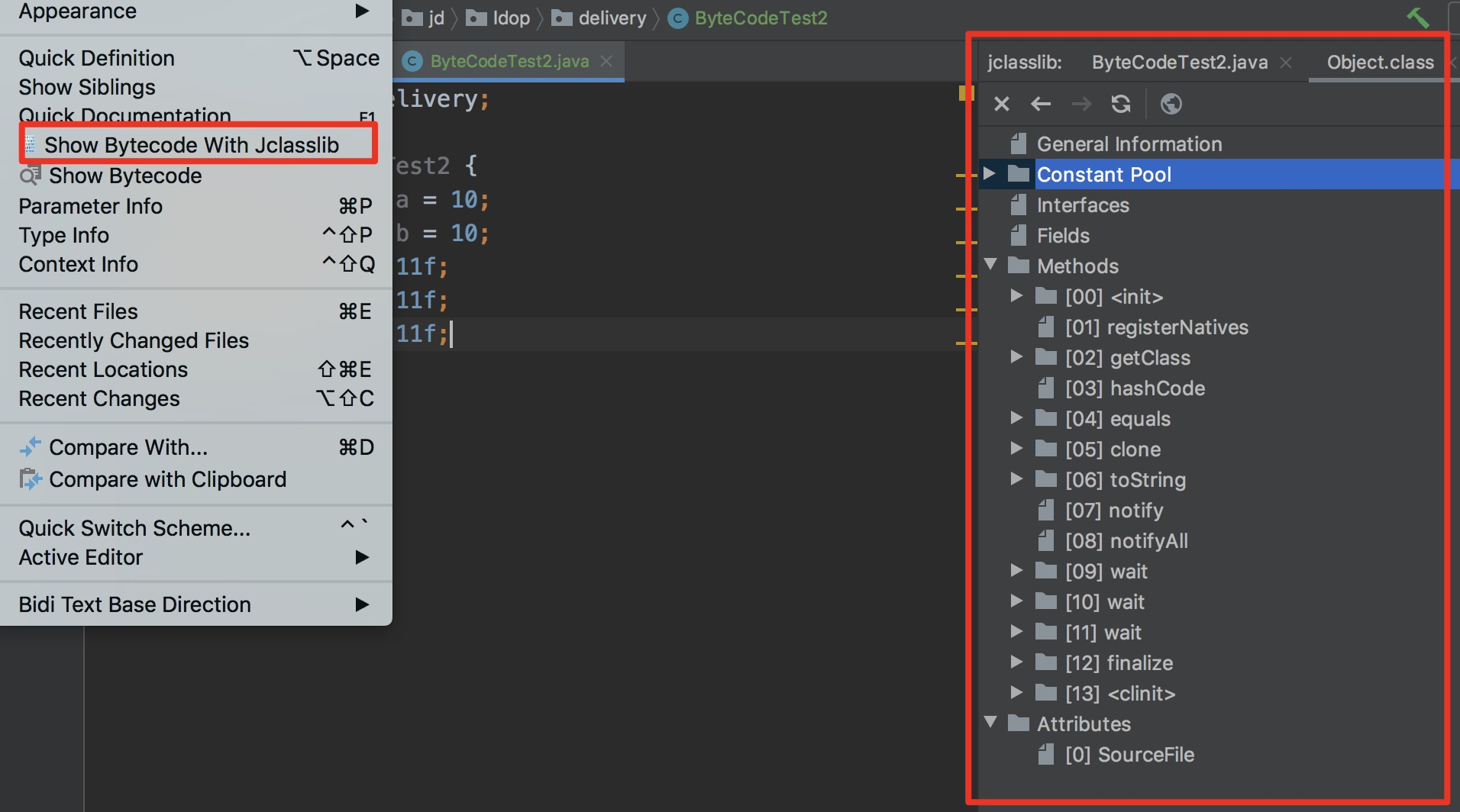
最后,如果每次查看反编译后的字节码都使用javap命令的话,很麻烦。有一个Idea插件:jclasslib。代码编译后在菜单栏"View"中选择"Show Bytecode With Jclasslib",可以很直观地看到当前字节码文件的类信息、常量池、方法区等信息
关于字节码的介绍就到这里了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号