【论文阅读】Learning Deep Features for Discriminative Localization
这个是周博磊16年的文章。文章通过实验证明,即使没有位置标注,CNN仍是可以得到一些位置信息,(文章中的显著性图)
-
CNN提取的feature含有位置信息,尽管我们在训练的时候并没有标记位置信息;
-
这些位置信息,可以转移到其他的认知任务当中
文章的实验主要就是证明了,在CNN分类中,不同区域对于最终结果的影响大小是不同的,包含分类信息的部分是可以被定为得到的。(粗略的)
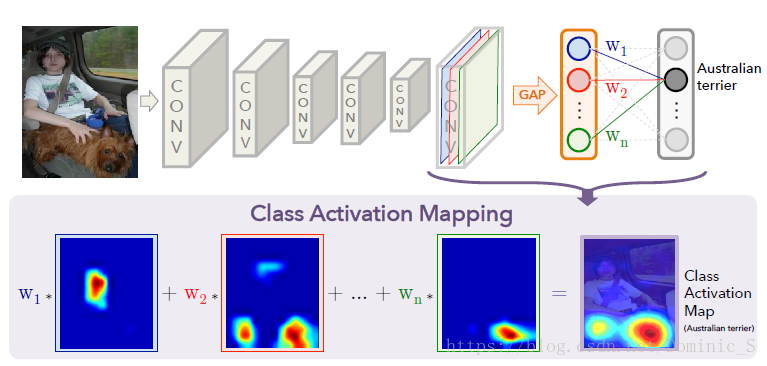
Class Activation Mapping
在传统的CNN分类任务中,最后的通常为全连接层,而FC全连接层是无法得到显著性图的。在论文中使用了GAP(global average pooling)来代替FC。
假设 \(f_{k}(x,y)\) 表示第 \(k\) 个特征图上 \((x,y)\) 位置的值,通过GAP,可以得到结果 \(F_k = \sum_{x,y}{f_k(x,y)}\) 。 那么对于某个类别 \(c\) ,softmax的输入值为
\[s_{c} = \sum_{k}^{}{}w_{k}^{c}F_{k}
\]
最后类别\(c\)的值为
\[P_{c} = \frac{exp(s_{c} )}{\sum_{c}^{}{}exp(s_{c}) }
\]
怎么通过GAP,来生成CAM
通过上面的公式,我们可以将 \(s_{c}\) 展开,如下所示:
\[S_c=\sum_kw_k^c\sum_{x,y}f_k(x,y)=\sum_{x,y}\sum_kw_k^cf_k(x,y)
\]
定义属于某个类别c的CAM为
\[M_c(x,y)=\sum_kw_k^cf_k(x,y)
\]
从上式可以看出,\(M_{c}(x,y)\) 表示的是不同的激活unit(特征图)对识别某个类别c的权重和。具体如下图所示。 最后将生成的 \(M_{c}(x,y)\) 放大到原图的大小,就可以得到对应于某个类别c的CAM了。
最后,把 \(M_{c}(x,y)\) Upsample到指定大小即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号