面霸之路——数据库之优化索引
1.为什么要使用索引
首先我们了解一下全表扫描,即将整张表的数据全部或者分批次加载到内存当中,而存储的最小单位是块或者页,它们是由多行数据而组成的,将这些块或者页都加载进来,逐个块或者页去轮询,找到目标数据并返回,这种方式普遍认为是非常慢的。因此,在很多情况下,我们要避免全表扫描的情况发生,所以数据库要引入一种更为高效的机制——索引,它的灵感来源于字典,在字典中只要把关键信息组织起来,比如偏旁部首,查询的时候依据这些信息的指引就能查询到页面,很快就定位到要查的字了,而这些关键信息和及这些查找数据的方式便组成了索引。
2.什么样的信息可以作为索引
主键、唯一键及普通键等。
3.索引的数据结构
- 生成索引,建立二叉查找树进行二分查找
- 生成索引,建立B-Tree结构进行查找
- 生成索引,建立B+-Tree结构进行查找
- 生成索引,建立Hash结构进行查找
• 二叉查找树
二叉查找树是每个结点最多有俩个子节点的数据结构,通常子树被称为左子树或者右子树,而且每个结点的左子树均小于该结点,右子树均大于该结点。所以。使用二叉查找树确实能提升查询效率。此树还是一颗平衡二叉树,平衡二叉树就是任意一个结点的左子树和右子树的高度差的绝对值不大于1。二叉查找树用的是二分查找,比如搜索6,6比5大,因此要从5的右孩子查找,此时来到了7,7比6大,因此查7的左孩子,这样就定位到了6,因为是对半搜索,所以时间复杂度为O(logn)。

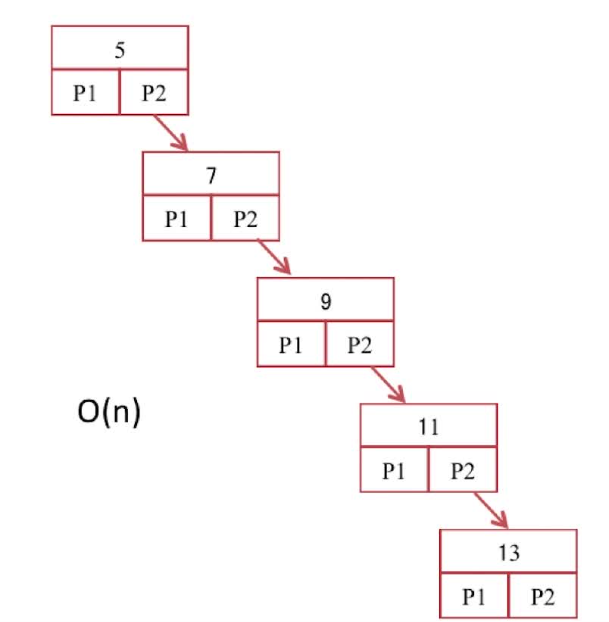
而二叉查找有明显的缺陷,假设数据库中对数据进行增加和删除操作,如果此时将结点2、结点6删除,同时先后增加值为11和值为13的结点,如图所示。根据二叉查找树的特性,会形成线性二叉树,如图所示,查询复杂度会变为O(n),大大降低了查找效率。影响数据检索速率最根本的原因是IO,即数据库文件的读写,就是将硬盘的数据读到内存中,而二叉树在检索深度每次加1后都需要读取一个结点执行一次IO,效率很低。所以我们需要既能降低时间复杂度,又降低IO次数的数据结构,即B树。
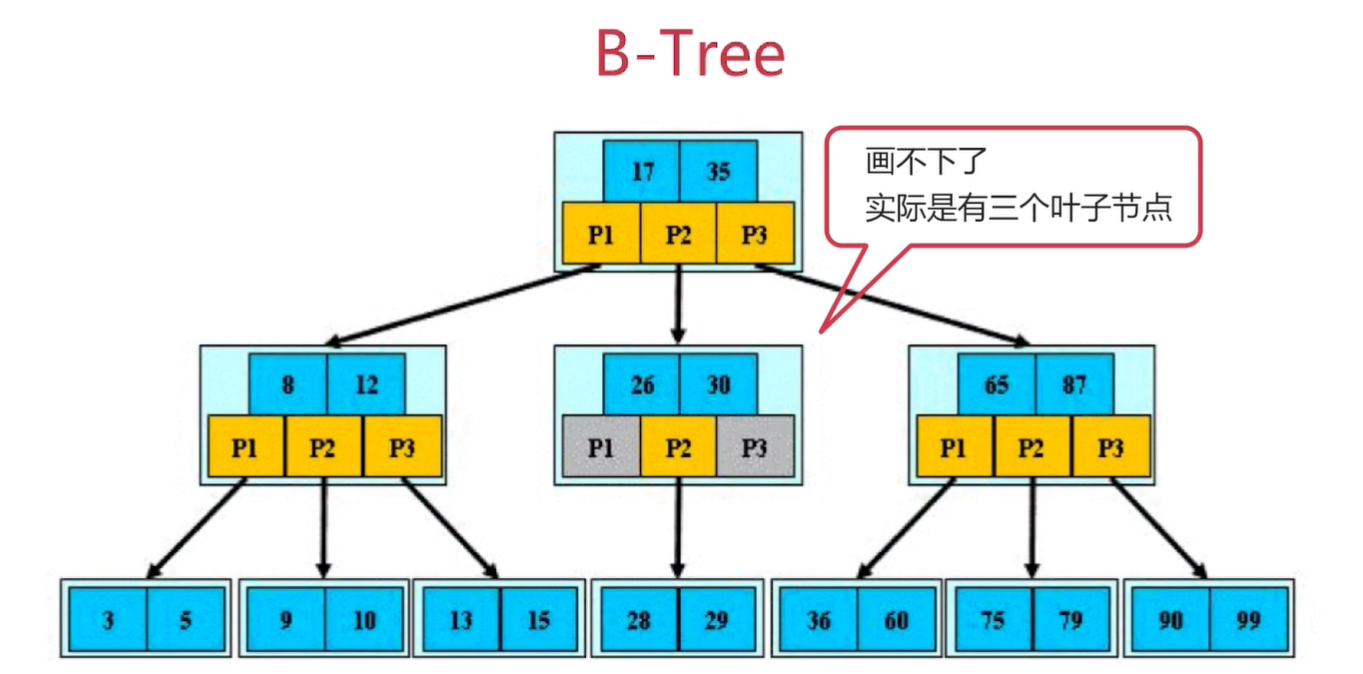
• B-Tree
定义:
- 根节点至少包括俩个孩子
- 树中每个节点最多含有m个孩子(m>=2)
- 除根节点和叶节点外,其他每个节点至少有ceil(m/2)个孩子
- 所有叶子节点都位于同一层
- 假设每个非终端节点中包含有n个关键字信息,其中
a) Ki(i=1...n)为关键字,且关键字按顺序升序排序K(i-1)<Ki
b) 关键字的个数n必须满足:[ceil(m/2)-1]<=n<=m-1
即任意节点的关键字个数上限比它的孩子数上限少一个,且对于非叶子节点来说,任何一个节点的关键字个数比它的指向孩子的的指针个数少一个
c) 非叶子节点的指针:P[1],P[2],.....,P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1],K[i])的子树
当数据发生变动时,必然会存在现有数据结构被打乱的情况,但是B-Tree有5个规定存在,就会使用相应的策略通过合并、分裂、上移、下移节点来保持特征,使树比二叉树矮的多,并且不会经过数据不断地变动后变成线性的情况。B-Tree的目的就是尽可能让每个索引块存储更多的信息,让树的高度尽可能减少IO次数,同样它的查找效率为O(logn)。
•B+-Tree
B+树是B树的变体,其定义基本与B树相同,除了:
- 非叶子节点的子树指针与关键字个数相同
表明B+-Tree可以存储更多的关键字
- 非叶子节点的子树指针P[i],指向关键字值[K[i],K[i+1]]的子树
- 非叶子节点仅用来做索引,数据都保存在叶子节点中
所以每次查找数据都要找到叶子节点为止,非叶子节点只能存储索引,那么存储数据的空间就可以存储更多的关键字,这样B+-Tree就会比B-Tree更矮
- 所有叶子节点均有一个链指针指向下一个叶子节点
作用是可以在叶子节点中做范围统计,即一旦定位到某个叶子节点,便可以从该叶子节点横向跨子树作统计

B+-Tree更适合用来做存储索引的原因
- B+树的磁盘读写代价更低
程序运行往往最消耗的操作就是IO,如果IO次数越少,那么运行也就越快,代价也就越低,非叶子节点结构没有指向关键字对应表记录的指针,只存放索引,因此节点比B树更小,如果把所有内部节点的关键字存放在同一盘块中,盘块所能容纳的关键字数量也就越多,一次性读入内存需查找的关键字也就越多,相对来说IO读写次数降低了。
- B+树的查询效率更加稳定
由于数据存放在叶子节点中,也就意味着每次查询都要经过从根节点到叶节点的查询路径,时间复杂度均为O(logn),比较稳定。
- B+树更有利于对数据库的扫描
B树在提高了磁盘IO性能同时并没有解决元素遍历效率低的问题,而B+树只需要遍历叶子节点就可以解决对全部关键字的扫描,所以查询数据范围有更高的性能。
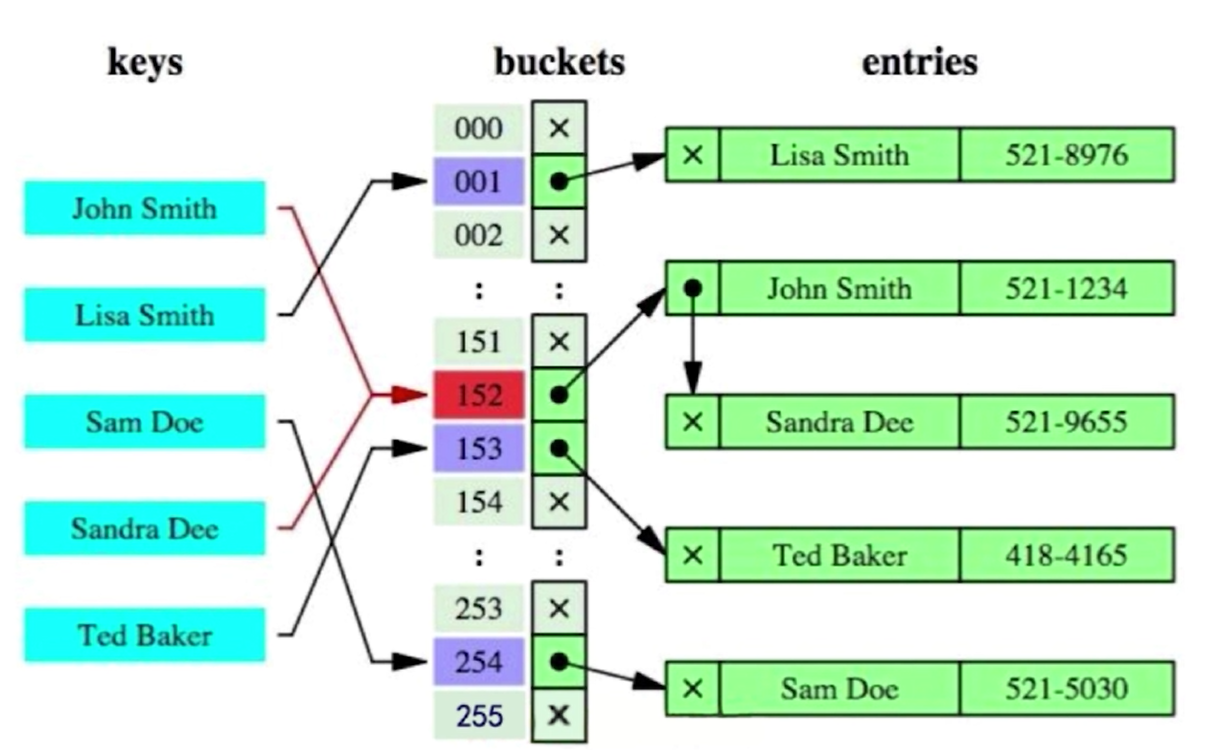
• Hash索引
哈希索引(hash index)基于哈希表实现,只有精确匹配索引所有列的查询才有效。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),哈希码是一个较小的值,并且不同键值的行计算出来的哈希码也不一样。哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。根据哈希函数运算只需经过一次定位便能找到需要查询数据所在的头,效率理论上高于B+-Tree。
但是Hash索引为什么成为不了主流索引呢?原因有以下五点:
- 仅仅能满足“=”、“IN”,不能使用范围查询
- 不能利用部分索引键做查询
- 无法被用来避免数据的排序操作(因为hash索引中存放的是hash运算之后的值,hash值大小关系不一定和运算前的键值完全一样【不同的key可能有相同的hash(key)】,数据库无法利用索引的数据来避免任何排序运算)
- 不能避免表扫面(一个索引可能对应多个记录,这些记录仍然需要进行扫描)
- 遇到大量Hash值相等的情况后性能不一定比B-Tree索引高(在极端情况下所有的key都对应同一个hash(key),在查询最后一个数据的时候就变成线性得了)
•BitMap索引
BitMap索引,即位图索引。当表中的某个字段只有几种值的时候,比如性别,仅仅是为了在这个字段上实行高效的统计,此时用位图索引是最佳的选择。

位图索引结构类似于B+-Tree,其中叶子节点包含指定键值的位图段,位图段和段信息就位于叶子节点上,由于关键字的值是固定的,所以在存储方式上会先按状态值分开,每一种值的空间会存储每一个实际的数据行是否是这个值,如图所示,由于只需要存储0/1,通常只需要一个bit位存放,因此理论上一个块可存放大量bit位表示不同的行。
但是,位图索引存在着一个缺陷,就是锁的力度非常大,举个例子,有这样一个字段busy,记录各个机器的繁忙与否,当机器忙碌时,busy为1,当机器不忙碌时,busy为0。
此时如果使用位图索引索引busy字段,假设用户A使用update更新某个机器的busy值,比如update table set table.busy=1 where rowid=100;但还没有commit,而用户B也使用update更新另一个机器的busy值,update table set table.busy=1 where rowid=12; 这个时候用户B怎么也更新不了,需要等待用户A commit。 原因是用户A更新了某个机器的busy值为1,会导致所有busy为1的机器的位图向量发生改变,因此数据库会将busy=1的所有行锁定,只有commit之后才解锁。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号