数据预处理
一.数据预处理概述
常遇到的数据存在噪声、冗余、关联性、不完整性等。
数据预处理常见处理方法:
(1)数据清理:补充缺失值、消除噪声数据、识别或删除离群点(异常值)并解决不一致性。
目标:数据格式标准化、异常数据清除、重复数据清除、错误纠正
(2)数据集成:将多个数据数据源中的数据进行整合并统一存储
(3)数据变换:通过平滑狙击、数据概化、规范化等方式将数据转换成适用数据挖掘的形式
(4)数据归约:针对在数据挖掘时,数据量非常大。数据归约技术指对数据集进行归约or简化,不仅保持原数据的完整性,且数据归约后的结果与归约前的结果相同或几乎相同。
二.数据清理
1.异常数据处理
异常数据也称离群点,指采集的数据中,个别数据值明显偏离其余观测值。对这些数据需采用一定的方法消除,否则对结果产生影响。
(1)异常数据分析
a.统计量判断:max,min,均值,检查数据是否超出合理范围
b.3σ原则:根据正态分布定义,出现距离均值3σ以上数值属于小概率事件,此时,数据和均值的偏差超过3倍标准差的视为异常值。操作参考https://www.cnblogs.com/wd19/p/11195897.html
c.箱型图判断:箱型图反应数据分布。如果数据超出箱型图上界or下界视为异常数据
(2)异常数据处理方法
a.删除:直接把存在的一场数据删除,不进行考虑
b.视为缺失值:按照缺失值处理方法进行操作。如2所示
c.不处理:看作正常数据处理
d.平均值修正:使用前后两个观测值的均值代替,or使用整个数据集的均值。参考spss工具
2.缺失值处理
经常使用数据补插方法代替缺失值,如以下几种:
(1)最近邻插补:使用缺失值附近样本or其他样本代替;or前后数据均值代替
(2)回归方法:建立拟合模型,用该模型预测缺失值
(3)插值法:类似回归法,利用已知数据建立插值函数,用该函数计算近似值代替缺失值。
常见插值函数:拉格朗日插值法、牛顿插值法、分段插值法、样条插值法、Hermite插值法
3.噪声数据处理
处理方法:分箱、聚类、回归
(1)分箱法
把待处理数据(某列属性值)按一定规则放进一些箱子(区间),考察每一个区间里的数据,then采用某方法分别对各个区间数据处理。需考虑2个问题:如何分箱,如何对每个箱子中数据进行平滑处理。
分箱方法如下几种:
a.等深分箱法(统一权重法):将数据集按记录(行数)分箱,每箱具有相同的记录数(元素个数)。每箱记录数称为箱子深度(权重)。
b.等宽分箱法(统一区间法):使数据集在整个属性值的区间上平均分布,即每个箱的区间范围(箱子宽度)是一个常量。
c.用户自定义区间:当用户明确希望观察某些区间范围内的数据时,可根据需要自定义区间。
eg.客户收入属性的数据排序后值如下:800,1000,1200,1500,1500,1800,2000,2300,2500,2800,3000,3500,4000,4500,4800,5000
等深分箱法:设定权重(箱子深度)为4
箱1:800,1000,1200,1500
箱2:1500,1800,2000,2300
箱3:2500,2800,3000,3500
箱4:4000,4500,4800,5000
等宽分箱法:设定区间范围(箱子宽度)为1000元
箱1:800,1000,1200,1500,1500,1800
箱2:2000,2300,2500,2800,3000
箱3:3500,4000,4500
箱4:4800,5000
用户自定义:将客户收入划分为1000元以下,1000-2000元,2000元以上
箱1:800,1000
箱2:1200,1500,1500,1800,2000,
箱3:2300,2500,2800,3000,3500,4000,4500,4800,5000
分箱后对每个箱子中数据进行平滑处理。常见数据平滑方法如下:
a.按均值平滑:对同一箱值中数据求均值,用均值代替该箱子中所有数据
b.按边界值平滑:用距离较小的边界值代替每一个数据
c.按中值平滑:取箱子中的中值,代替箱子中所有数据
(2)聚类法
将物理对的or抽象对象的集合分组为 由类似对象组成的多个类,then展出并清除那些落在簇之外的值(孤立点),这些孤立点称为噪声数据。
(3)回归法
试图发现两个变量之间的相关变化模式,找到这个函数来平滑数据。即通过建立一个数学模型来预测下一个数值,方法一般包括线性回归and非线性回归。
三.数据集成
将多文件or数据库中的异构数据进行合并,然后存放在一个统一数据库中存储。
需考虑的问题:
(1)实体识别:数据来源不同,其中概念定义不同
a.同名异义:数据源A某个数据特征名称 与 数据源B某个数据特征名称 相同,但表示内容不同。
b.异名同义:数据源A某个数据特征名称 与 数据源B某个数据特征名称 不同,但表示内容相同。
c.单位不统一:不同的数据源记录单位不同。如身高,米?l厘米吗?
(2)冗余属性
a.同一属性多个数据源均有记录
b.同一属性命名不一致引起数据重复
(3)数据不一致:编码使用不一致、数据表示不一致。如日期
四.数据变换
将数据转换成适合机器学习的形式。
1.使用简单的数学函数对数据进行变换
数据较大:取对数、开方 使数据压缩变小
数据较小:平方 扩大数据
时间序列分析:对数变换or 差分运算 使非平稳序列转换为平稳序列
2.归一化(数据规范化)
如比较工资收入,有人每月工资上万元,有人每月才几百元,归一化可消除数据间这种量纲影响。
(1)最小--最大归一化(离散标准化)
对原始数据进行线性变换,使其映射到 [0,1]之间,转换函数如下:
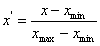
(2) Z-score标准法(零-均值规范法)
使用原始数据均值和标准差,对数据标准化。经过处理的数据符合 标准正态分布,即均值为0,标准差为1。转化函数如下:
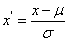
X-μ为离均差,σ表示总体标准偏差 。
要求:原始数据近似为高斯分布(正态分布),否则,归一效果不理想。(可简单做变量散点图观察)
(3) 小数定标规范化
通过移动数据的小数点位置进行规范化。
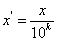
3.连续属性离散化
本质上是将连续属性空间划分为若干个区间,最后用不同的符号or整数值 代表每个子区间中的数据。
离散化涉及两个子任务:确定分类,将连续属性值映射到这些分类中
机器学习常用离散化方法:
(1)等宽法:将数据 划分为具有相同宽度的区间,将数据按照值分配到不同区间,每个区间用一个数值表示。
(2)等频法:把数据划分为若干个区间,按照其值分配到不同区间,每个区间内数据个数相等
(3)基于聚类分析的方法:典型算法K-means算法:
首先从数据集中随机找出k个数据作为k个聚类的中心;
其次,根据其他数据相对于这些中心的欧氏距离,对所有对象聚类。如果数据点x距某个中心近,则将x划归该中心所代表的聚类;
最后,重新计算各区间中心,利用新中心重新聚类所有样本。循环直至所有区间中心不再随算法循环而改变,
五.数据归约
在尽可能保持数据原貌前提下,最大限度精简数据量。与非归约数据相比,在归约的数据上进行挖掘,所需时间和内存资源更少,挖掘更有效,产生几乎相同分析结果。
常用维归约、数值归约等方法。
1.维归约(特征归约)
通过减少属性特征方式压缩数据量,移除不相关属性,提高模型效率。维归约方法很多:
AIC准则:通过选择最优模型来选择属性
LASSO:通过一定约束条件选择变量
分类树、随机森林:通过对分类效果的影响大小筛选属性
小波变换、主成分分析:通过把原数据变换or投影到较小空间来降低维数
2.数值归约(样本归约)
从数据集中选出一个有代表性的样本子集。
子集大小的确定需考虑:计算成本、存储要求、估计量精度、其他与算法有关因素
如:参数法中使用模型估计数据,可只存放模型参数代替存放实际数据:eg,回归模型、对数线性模型
非参数方法可使用直方图、聚类、抽样、数据立方体聚焦等。
六.Pyhton的主要数据预处理函数
1.Python的数据结构
pandas主要两种数据结构
(1)Series
类似一维的数组对象。Series对象主要有两个属性:index、values.
如果传递给构造器的是一个列表,index值是从0递增的整数;如果传递一个键值对结构,就会生成index-value对应的Series
from pandas import Series,DataFrame s=Series([1,2,3,'abc','def']) #自动生成索引
#指定索引
s=Series(data=[1,2,3,'abc','def'],index=[10,20,30,40,50]) # s=Series([1,2,3,'abc','def'],index=[10,20,30,40,50])
(2)DataFrame
类似一个表格。有行和列索引。
from pandas import Series,DataFrame
data =DataFrame({'id':[100,101,102,103,104],'name':['aa','bb','cc','dd','ee'],'age':[18,19,20,19,18]})
#指定index or columns
data2 =DataFrame({'id':[100,101,102,103,104],'name':['aa','bb','cc','dd','ee'],'age':[18,19,20,19,18]},index=['one','two','three','four','five']) #or data2 =DataFrame(data,index=['one','two','three','four','five'])
print(data2)
2.数据缺失处理函数
Pandas使用浮点值NaN代表缺失数据,Numpy使用nan代表缺失值,Python内置的None也会被当做NA处理。
from pandas import Series,DataFrame
from numpy import nan as NA
data = Series([12,None,34,NA,58])
print(data)
out: 0 12.0
1 NaN
2 34.0
3 NaN
4 58.0
dtype: float64
可使用 isnull() 检测是否为缺失值,该函数返回一个布尔型数组,一般可用于布尔型索引。
print(data.isnull()) out: 0 False 1 True 2 False 3 True 4 False dtype: bool
当数据中存在缺失值时,常用以下方法处理。
(1)数据过滤(dropna)
直接将缺失值数据过滤掉,不再考虑。对Series结构没太大问题;对DataFrame结构,如果过滤掉,至少丢掉包含缺失值所在的一行or一列。
语法格式:dropna(axis=0,how='any',thresh=None)
axis=0表示行,axis=1表示列
how参数可选值为all/any,all表示丢掉全为NA的行
thresh为整数类型,表示删除条件,如thresh=3,表示一行中至少有3个非NA值才将其保留。
from pandas import Series,DataFrame from numpy import nan as NA data = Series([12,None,34,NA,58]) print(data.dropna()) out: 0 12.0 2 34.0 4 58.0 dtype: float64
接下来看一个两维数据情况
from pandas import Series,DataFrame
from numpy import nan as NA
import numpy as np
data = DataFrame(np.random.randn(5,4))
data.ix[:2,1]=NA
data.ix[:3,2]=NA
print(data)
print('---删除后的结果是---')
print(data.dropna(thresh=2))
print(data.dropna(thresh=3))
out:
0 1 2 3
0 0.223965 NaN NaN 0.572505
1 -0.310963 NaN NaN -0.085844
2 -0.174306 NaN NaN -0.160054
3 -0.570029 0.451696 NaN 1.168203
4 -0.918397 -1.249329 -0.61818 0.978389
---删除后的结果是---
0 1 2 3
0 0.223965 NaN NaN 0.572505
1 -0.310963 NaN NaN -0.085844
2 -0.174306 NaN NaN -0.160054
3 -0.570029 0.451696 NaN 1.168203
4 -0.918397 -1.249329 -0.61818 0.978389
0 1 2 3
3 -0.570029 0.451696 NaN 1.168203
4 -0.918397 -1.249329 -0.61818 0.978389
loc——通过行标签索引行数据
iloc——通过行号索引行数据
ix——通过行标签或者行号索引行数据(基于loc和iloc 的混合)
(2)数据填充(fillna)
语法格式:fillna(value,method,axis)
value:除了基本类型外,还可使用字典实现对不同列填充不同值。
method:采用填补数值的方法,默认None
eg.用0代替所有NaN.
print(data.fillna(0))
out:
0 1 2 3
0 0.083377 0.000000 0.000000 0.147247
1 0.927662 0.000000 0.000000 0.156747
2 -0.054431 0.000000 0.000000 -1.118927
3 -0.237319 2.413680 0.000000 0.196252
4 -0.400624 -0.422343 1.136373 -0.370904
使用字典填充:第1列缺失值用11代替,第2列缺失值用22代替
print(data.fillna({1:11,2:22}))
out:
0 1 2 3
0 0.731801 11.000000 22.000000 0.663891
1 0.617013 11.000000 22.000000 -0.067351
2 0.117183 11.000000 22.000000 -0.048441
3 -1.180875 -0.211674 22.000000 0.026497
4 0.271810 0.836722 0.125407 -0.510306
第一列缺失值用该列均值代替,同理第2列
print(data.fillna({1:data[1].mean(),2:data[2].mean()}))
out:
0 1 2 3
0 1.440942 -0.550534 -0.40254 -0.238328
1 1.177531 -0.550534 -0.40254 0.184064
2 -0.568246 -0.550534 -0.40254 0.286022
3 0.709073 0.082285 -0.40254 -0.808424
4 0.599532 -1.183353 -0.40254 1.894830
(3)拉格朗日插值法

图片来源:https://blog.csdn.net/sinat_22510827/article/details/80972389
此处着重介绍算法的实现。
from scipy.interpolate import lagrange #导入拉格朗日插值函数
import pandas as pd
from pandas import DataFrame
import numpy as np
df = DataFrame(np.random.randn(20,2),columns=['first','second'])
df[(df['first']<-1.5)|(df['first']>1.5)] =None #将异常值变为空值
print(df)
out:
first second
0 0.509865 0.223248
1 0.105383 -0.354727
2 NaN 0.720146
3 NaN 0.254254
4 -0.664651 1.752019
5 NaN 0.379110
6 0.154492 1.358823
7 -0.275848 -0.425088
8 -0.457922 0.653865
9 0.138629 0.215032
10 -0.563553 -0.121851
11 NaN 1.410582
12 -0.879194 0.297789
13 0.216112 -0.038785
14 0.567963 -1.438319
15 0.430648 1.843005
16 1.126694 -0.419329
17 NaN -0.230501
18 0.471433 -0.279679
19 0.960270 0.261889
自定义列向量插值函数。s为列向量,n为被插值位置,k为取前后的数据个数,默认为5
tips补充知识:
a=list(range(2,6))+list(range(0,4)) print(a) out: [2, 3, 4, 5, 0, 1, 2, 3]
from scipy.interpolate import lagrange #导入拉格朗日插值函数
import pandas as pd
from pandas import DataFrame
import numpy as np
df = DataFrame(np.random.randn(20,2),columns=['first','second'])
df[(df['first']<-1.5)|(df['first']>1.5)] =None #将异常值变为空值
print(df)
out:
first second
0 -0.908670 -1.849173
1 -0.014963 -0.294497
2 0.229062 0.765329
3 NaN NaN
4 NaN NaN
5 -0.515293 -0.429553
6 0.109772 0.243534
7 -0.447363 0.827352
8 0.810052 0.960669
9 NaN NaN
10 NaN NaN
11 -0.495736 -0.823449
12 1.433098 0.810218
13 1.238232 -0.752660
14 -0.277956 -1.495663
15 1.367079 -0.653861
16 0.417049 -0.334369
17 0.328512 0.267598
18 0.671522 0.040041
19 0.292779 -1.500854
def ployinterp_column(s,n,k=5):
y=s[list(range(n-k,n)) + list(range(n+1,n+1+k))] #取数,n的前后5个,这里有可能取到不存在的下标,为空
y=y[y.notnull()] #剔除空值
return lagrange(y.index,list(y))(n) #插值并返回插值结果,最后的括号就是我们要插值的n
#逐个元素判断是否需要插值
for i in df.columns:
for j in range(len(df)): #逐个元素判断
if(df[i].isnull())[j]: #如果为空即插值
df[i][j]=ployinterp_column(df[i],j)
df.to_csv('C:/df2',sep=',') #使用DataFrame的to_csv函数保存文件
out:
,first,second
0,-0.9086702668582811,-1.8491728913487913
1,-0.014963260074014563,-0.29449702937867106
2,0.22906199067439614,0.7653293525157804
3,-0.704082936914352,0.3723318613247397
4,-1.1624629170855587,-0.3757317510307674
5,-0.5152933370950362,-0.4295533360082923
6,0.10977175789757533,0.2435336905666214
7,-0.44736256388993095,0.8273521748276524
8,0.8100515665921939,0.9606688385148615
9,1.5460818472129176,-0.0779254312581088
10,-0.041597527502744924,-1.5356986975057225
11,-0.49573605078970445,-0.8234491527470889
12,1.4330980273017377,0.8102181255104398
13,1.2382321456144767,-0.752660056579277
14,-0.2779557239464442,-1.495663200350301
15,1.3670789841095052,-0.6538612478274082
16,0.417048532674513,-0.3343690769844107
17,0.32851231080966964,0.26759821504833575
18,0.6715223467868799,0.04004134652646034
19,0.292779439136057,-1.5008536999322502
(4)检测和过滤异常值(Outlier)
from pandas import Series,DataFrame,np
from numpy import nan as NA
data = DataFrame(np.random.randn(10,4))
print(data.describe())
print('\n...找出某一列中绝对值大小超过1的项...\n')
data1 = data[2] #data的第2列赋值给data1
print(data1[np.abs(data1)>1])
data1[np.abs(data1)>1]=100 #将绝对值大于1的数据修改为100
print(data1)
out:
0 1 2 3
count 10.000000 10.000000 10.000000 10.000000
mean -0.063484 -0.173792 0.446723 0.211679
std 1.032054 1.079380 0.900736 0.863194
min -1.117239 -2.009955 -0.689243 -1.045505
25% -0.832113 -0.689701 -0.165707 -0.338501
50% -0.560831 -0.250178 0.317723 0.184269
75% 0.680691 0.536042 0.844509 0.668352
max 1.799798 1.495253 2.279650 1.703622
...找出某一列中绝对值大小超过1的项...
0 1.318452
8 2.279650
Name: 2, dtype: float64
0 100.000000
1 -0.499920
2 0.407870
3 -0.689243
4 0.861217
5 -0.017720
6 0.227575
7 -0.215036
8 100.000000
9 0.794384
Name: 2, dtype: float64
(5)移除重复数据
在Pandas中使用duplicated方法发现重复值(返回bool型数组,F非重复,T重复),drop_duplicates方法移除重复值
from pandas import Series,DataFrame,np
from numpy import nan as NA
import pandas as pd
import numpy as np
data = DataFrame({'name':['zhang']*3 + ['wang']*4,'age':[18,18,19,19,20,20,21]})
print(data)
print('...重复的内容是...\n')
print(data.duplicated())
print('--删除重复的内容后---')
print(data.drop_duplicates())
out:
name age
0 zhang 18
1 zhang 18
2 zhang 19
3 wang 19
4 wang 20
5 wang 20
6 wang 21
...重复的内容是...
0 False
1 True
2 False
3 False
4 False
5 True
6 False
dtype: bool
--删除重复的内容后---
name age
0 zhang 18
2 zhang 19
3 wang 19
4 wang 20
6 wang 21
duplicated 和drop_duplicates默认保留第一个出现值组合,可修改参数keep='last'保留最后一个
print('--删除重复的内容后---')
print(data.drop_duplicates(keep='last'))
out:
--删除重复的内容后---
name age
1 zhang 18
2 zhang 19
3 wang 19
5 wang 20
6 wang 21
(6)数据规范化
为消除数据之间量纲影响,需对数据进行规范化处理,将数据落入一个有限范围。
常见归一化将数据范围调整到[0,1] or [-1,1]。一般使用方法:最小-最大规范化、零-均值规范化和小数规范化。
import pandas as pd
import numpy as np
data1 = pd.read_csv('C:/Users/Administrator.SC-201905211330/spx.csv') #header=None时,即指明原始文件数据没有列索引,这样read_csv为自动加上列索引,除非你给定列索引的名字。
data=data1['SPX'] # or data1.spx,选取spx列
print('原始数据为:',data[:5] )
min = (data-data.min())/(data.max()-data.min()) #最小-最大规范化
zero = (data-data.mean())/data.std() #零-均值规范化
float = data/10**np.ceil(np.log10(data.abs().max())) #小数定标规范化,np.ceil()向上(正无穷)取整函数
print('最小-最大规范化后数据:\n',min[:5])
print('零-均值规范化后数据:\n',zero[:5])
print('小数规范化后数据:\n',float[:5])
out:
原始数据为: 0 328.79
1 330.92
2 331.85
3 329.66
4 333.75
Name: SPX, dtype: float64
最小-最大规范化后数据:
0 0.026251
1 0.027928
2 0.028661
3 0.026936
4 0.030157
Name: SPX, dtype: float64
零-均值规范化后数据:
0 -1.667805
1 -1.662041
2 -1.659524
3 -1.665451
4 -1.654382
Name: SPX, dtype: float64
小数规范化后数据:
0 0.032879
1 0.033092
2 0.033185
3 0.032966
4 0.033375
Name: SPX, dtype: float64
其他的一些第三方库也有类似预处理函数,如机器学习库sklearn中:最小-最大规范化函数是MinMaxScaler,Z-Score规范化函数是StandardScaler()等
(7)汇总和描述等统计量的计算
max,min,方差,标准差(Standard Deviation)等统计量、
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
df = DataFrame(np.random.randn(4,3),index=list('abcd'),columns =['first','second','third'])
print(df.describe())#对数据统计量进行描述
out:
first second third
count 4.000000 4.000000 4.000000
mean 0.094635 -0.481173 0.239956
std 0.396495 0.379548 1.155269
min -0.408514 -0.914881 -1.393335
25% -0.116806 -0.732928 -0.152447
50% 0.148771 -0.459812 0.586063
75% 0.360212 -0.208057 0.978466
max 0.489511 -0.090186 1.181033
print(df.sum())#统计每列数据的和
print(df.sum(axis=1)) #统计每行(从左到右)数据和
print(df.idxmin()) #统计每列最小数值所在的行
print(df.idxmin(axis=1)) #统计每行最小数值所在的列
print(df.cumsum()) #计算相对于上一行的累计和
print(df.var()) #计算方差
print(df.std())#计算标准差差
print(df.pct_change()) #计算百分数变化
out:
first 0.378540
second -1.924692
third 0.959825
dtype: float64
a 0.151427
b -1.748500
c 0.525172
d 0.485573
dtype: float64
first c
second d
third b
dtype: object
a second
b third
c first
d second
dtype: object
first second third
a -0.019570 -0.090186 0.261183
b 0.297542 -0.762463 -1.132152
c -0.110971 -1.009810 0.048881
d 0.378540 -1.924692 0.959825
first 0.157208
second 0.144056
third 1.334646
dtype: float64
first 0.396495
second 0.379548
third 1.155269
dtype: float64
first second third
a NaN NaN NaN
b -17.204010 6.454375 -6.334713
c -2.288230 -0.632075 -1.847630
d -2.198273 2.698771 -0.228689

 浙公网安备 33010602011771号
浙公网安备 33010602011771号