Python机器学习和分析工具
一. 矩阵操作函数库(Numpy)
1.np函数运算
import time import math import numpy as np x = [i*0.001 for i in range(1000)] start = time.clock() for i,t in enumerate(x): x[i]=math.sin(t) print('math.sin运行时间:',time.clock()-start) x=[i*0.001 for i in range(1000)] x=np.array(x) start = time.clock() np.sin(x) print('numpy.sin运行时间:',time.clock()-start)
可以发现,numpy.sin比math.sin快得多
2.矩阵运算
Numpy对于多维数组运算,默认情况下不使用矩阵运算,需调用相应函数。在Numpy中同时存在ndarray和matrix对象,不推荐在复杂程序中用matrix
np.dot计算矩阵乘积。矩阵更高级运算在Numpy的linalg(线型代数)中:inv计算逆矩阵,solve()求解多元一次方程组。
a = np.random.rand(10,10) b = np.random.rand(10) x = np.linalg.solve(a,b) z=np.sum(np.abs(np.dot(a,x)-b)) print(z)
二.科学计算核心包(Scipy)
Scipy是科学计算程序的核心包,在Numpy基础上增加了众多数学、科学及工程计算中常用的库函数。如线性代数、常微分方程求加、信号/图像处理、稀疏矩阵。
1.最小二乘法(最小平方法)
最小二乘拟合属于优化问题。如f(x)=kx+b,k,b就是要确定的值,将这些参数用p表示,寻找参数p使得S函数最小
![]()

Scipy的opimize子函数库中,提供leatsq()函数实现
eg.最小二乘法直线拟合,直线方程y=kx+b
import numpy as np
from scipy.optimize import leastsq
#分别定义要拟合的函数形式和误差
def func(p,x):
k,b=p
return k*x+b
def error(p,x,y,s):
print(s)
return func(p,x)-y
# s为提示信息,可根据自身需要定义
s='computing...'
#已知训练数据如下
Xi = np.array([8.9,2.72,6.39,8.71,4.7,2.66,3.78])
Yi = np.array([7.01,2.78,6.47,6.71,4.1,4.23,4.05])
#随机给出初始值
p0=[100,2]
Para = leastsq(error,p0,args=(Xi,Yi,s)) #3个参数:误差函数,参数初始值,数据点
k,b = Para[0] #拟合后的参数
print('k=',k,'\n','b=',b)
#为更直观观察拟合效果,可以使用图形显示
import matplotlib.pyplot as plt
plt.figure(figsize=(8,6))
plt.scatter(Xi,Yi,color='red',label='Sample Point',linewidth=3)
x=np.linspace(0,10,1000) #在指定的间隔内返回均匀间隔的数字。np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
y=k*x+b
plt.plot(x,y,color='orange',label='Fitting Line',linewidth=2)
plt.legend() #legend()显示图例函数,位置为自适应方式(best),也可upper/lower right/left.
plt.show()
out:
computing...
computing...
computing...
computing...
computing...
computing...
computing...
computing...
computing...
k= 0.5805132229725842
b= 1.9102527671496703

eg.使用最小二乘法进行正弦函数拟合
import numpy as np
import args
import matplotlib.pyplot as plt
from numpy import pi
from scipy.optimize import leastsq
def func(x,p):
A,k,theta = p
return A*np.sin(2*k*np.pi*x+theta)
def residuals(p,y,x): #定义误差函数
return y-func(x,p)
#定义训练数据
x=np.linspace(0,-2*np.pi,100)
A,k,theta=10,0.34,np.pi/6
y1=func(x,[A,k,theta]) #100个真实数据
y2=y1+2*np.random.randn(len(x)) #randn()产生一个标准正态分布的随机数,所以y是100个噪声数据
#随机给出3个参数初始值
p0=[7,0.2,0]
#曲线拟合
plsq=leastsq(residuals,p0,args=(y2,x))
#绘制结果图形
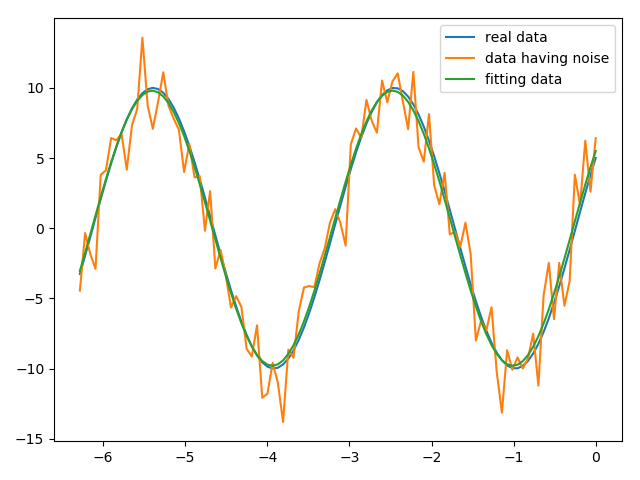
print('真实参数:',[A,k,theta])
print('拟合参数:',plsq[0]) #plsq[0]为实验数据拟合参数
plt.plot(x,y1,label='real data')
plt.plot(x,y2,label='data having noise')
plt.plot(x,func(x,plsq[0]),label='fitting data')
plt.legend()
plt.show()
out:
真实参数: [10, 0.34, 0.5235987755982988]
拟合参数: [-9.80190362 0.34138626 3.73679094]
Tips:Python导入模块的方法有两种:import module 和 from module import,区别是前者所有导入的东西使用时需加上模块名的限定,而后者不要。
2.非线性方程组求解
optimize库中fsolve函数 可用来对 非线性方程组 进行求解.
调用形式:fsolve(func,x0),其中function(x)是计算方程组的函数,参数x为矢量,表示一组可能解,func返回将x带入方程后的结果;x0为初始值。
eg.求解非线性方程组
5*x1+3=0
4*x0-2*sin(x1*x2)=0
x1*x2-1.5=0
from scipy.optimize import fsolve
import numpy as np
#定义非线性方程组函数
def f(x):
x0=float(x[0])
x1=float(x[1])
x2=float(x[2])
return [
5*x1+3,
4*x0*x0-2*np.sin(x1*x2),
x1*x2-1.5
]
result=fsolve(f,[1,1,1])
print(result)
print(f(result))
out:
[-0.70622057 -0.6 -2.5 ]
[0.0, -9.126033262418787e-14, 5.329070518200751e-15]
三.Python绘图库(Matplotlib)
1.基本绘图命令
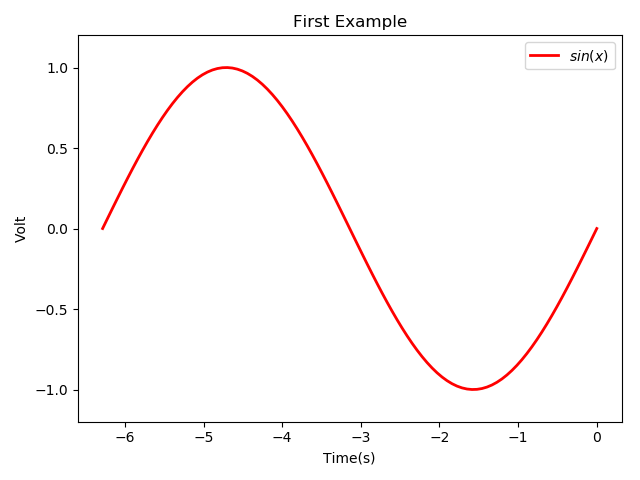
eg.1import matplotlib.pyplot as plt
import numpy as np
from numpy import pi
#数据
x=np.linspace(0,-2*pi,100)
y=np.sin(x)
z=np.cos(np.power(x,2)) #power(x,a)计算x的a次方
#绘图
plt.figure(1) #调用figure创建一个绘图对象,且使其成为当前绘图对象
#也可不创建绘图对象直接plot,Matplotlib会自动创建1个绘图对象。If需同时绘制多个图表,可给figure传递1个整数参数指定绘图序号
plt.plot(x,y,label='$sin(x)$',color='red',linewidth=2)
#label给绘制曲线一个名称,名称在图示(legend)中显示。只要在字符串前后加'$',Matplotlib会使用内嵌latex绘制数学公式
plt.xlabel('Time(s)')
plt.ylabel('Volt')
plt.title('First Example')
plt.ylim(-1.2,1.2)#plt.axis([xstart,xend,ystart,yend])plt.legend()
plt.show() #必须使用 plt.show()显示所有绘图对象
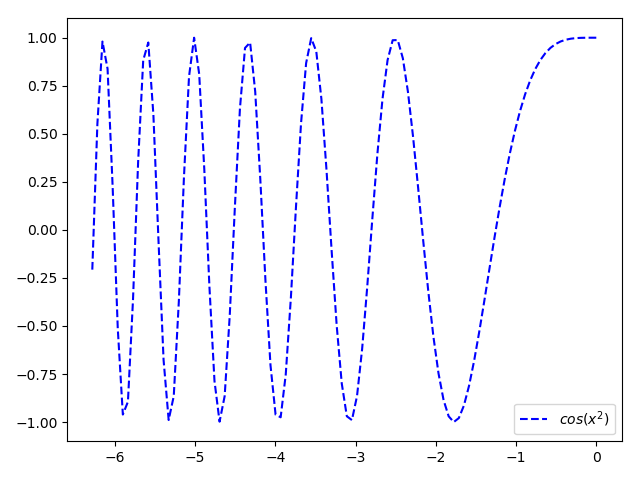
eg.2
plt.figure(2)
plt.plot(x,z,'b--',label='$cos(x^2)$') #蓝色虚线表示
plt.legend()
plt.show()
(1)颜色参数常用取值如下:
b,r,c(青色),m(洋红色),g,y,k(黑色),w
(2)线性参数常用取值如下:
'-'(实线) , '-.'(点画线), '--'(虚线)
(3)marker参数:标记图形数据点,取值如下:
D(菱形),d(小菱形),h(六边形1),H(六边形2),‘p’(5边形),'s'(正方形)
‘.’,*,‘+’,o(圆圈)
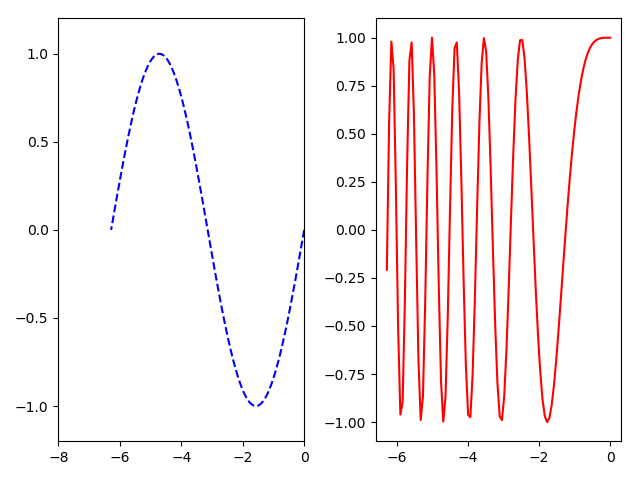
2.绘制多窗口图形
subplot(行数,列数,子图数)
eg.将如上2图合并到一起分成子图显示。
plt.subplot(1,2,1) plt.plot(x,y,'b--') plt.axis([-8,0,-1.2,1.2]) plt.legend() plt.subplot(1,2,2) plt.plot(x,z,'r-') plt.legend() plt.show()
then,创建一个3行2列共6个轴的图形,通过axisbg参数给每个轴(子图)设置不同背景
for idx,color in enumerate('rgbyck'):
plt.subplot(320+idx+1,axisbg=color)
plt.show()
3.文本注释
annotate( '注释内容',xy=(),xytext=(),arrowprops=dict() ):
(1)在图片中使用文字注释图中某特征。
(2)考虑两个点坐标:被注释的地方,xy=(x,y);插入文本的地方,xytext=(x,y)
x=np.arange(0.0,5,0.01)
y=np.cos(2*np.pi*x)
plt.plot(x,y)
plt.annotate('local max',xy=(2,1),xytext=(3,1.5),arrowprops=dict(facecolor='black',shrink=0.05))
#shrink收缩箭头
plt.ylim(-2,2)
plt.show()

4.中文显示问题
import numpy as np
import matplotlib.pyplot as plt
#手动添加中文字体名称
from pylab import *
mpl.rcParams['font.sans-serif']=['SimHei']
#手动加负号
plt.rcParams['axes.unicode_minus']=False_
x=np.arange(0.0,5,0.01)
y=np.cos(2*np.pi*x)
plt.plot(x,y,label='$sin(x)$',color='red',linewidth=2)
plt.xlabel('时间(秒)')
plt.ylabel('电压')
plt.title('正弦波')
plt.legend()
plt.show()
四.数据分析包(Pandas)
Pandas基本数据结构:Series(序列) 和DataFrame(二维数组,每一列都是一个Series)
from pandas import Series,DataFrame import pandas as pd
五.机器学习函数库(Scikit_learn)
1.Scikit_learn库基本功能
(1)分类(识别给定对象所属类别)。应用场景:垃圾邮件检测,图像识别。
目前可实现的算法:SVM、K-nN、逻辑回归,随机森林,决策树,多层感知器(MLP)神经网络。
(2)回归(预测给定对象相关联的连续值属性)。应用场景:预测药物反应,预测股票价格。
目前可实现的算法:支持向量回归(SVR)、脊回归、Lasso回归、弹性网络(Elastic Net)、最小角回归(LARS)、贝叶斯回归、个孩子能够不同的鲁棒回归算法。
(3)聚类(自动识别具有相似属性的给定对象,并将其分组为集合)。应用场景:顾客细分、试验结果分组
目前可实现算法:k-均值聚类、谱聚类、均值偏移、分层聚类、DBSCAN聚类。
(4)数据降维:主成分分析(PCA)、非负矩阵分解(NMF)or 特征选择等降维技术减少要考虑的随机变量个数。
应用场景:可视化处理、效率提升。
(5)模型选择(对给定参数和模型的比较、验证、选择,主要目的是通过参数调整来提升精度)
可实现模块:格点搜索、交叉验证、各种针对预测误差评估的度量函数。
(6)数据预处理(数据的特征提取和归一化)。
归一化:将输入数据转换为一个新变量(零均值,单位权方差),大多数做不到精确到0,因此设置一个可接受的范围(一般为0-1)
特征提取:将文本or图像数据转换为可用于机器学习的数字变量。
2.Scikit-learn数据集
几个自带数据集
| 数据集名称 | 调用方式 | 数据描述 |
| 鸢尾花 | load_iris() | 多分类分析 |
| 波士顿房价 | load_boston() | 经典的回归分析 |
| 糖尿病 | load_diabetes() | 经典的回归分析 |
| 手写数字 | load_digits() | 多分类分析 |
| 乳腺癌 | load_breast_cancer() | 二分类分析 |
| 体能训练 | load_linnerud() | 多变量回归分析 |
调用数据:
from sklearn.datasets import load_iris iris = load_iris()
print(iris.target) #标签:0(setosa),1(versicolor),2(virginica)
print(iris.target_names) #标签名称
print(iris.data.shape) #150个样本,每个样本4个特征(萼片长度、萼片宽度、花瓣长度、花瓣宽度)
out:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
['setosa' 'versicolor' 'virginica']
(150, 4)
3.Scikit-learn的数据集划分
训练集:用来估计模型
验证集:确定网络结构or控制模型复杂程度的参数
测试集:检验最终选择最优模型的性能
(1)train_test_split划分数据集
sklearn.model_selection函数,该函数的train_test_split是交叉验证中常用函数。其作用是从样本中选取train_data 和 test_data
形式:X_train,X_test,y_train,y_test = train_test_split(train_data,train_target,test_size=0.4,random_state=0)
train_data:数据集
train_target:目标类别集
test_size:样本占比,即测试集占原数据的比重。如果是整数,就是样本的数量
random_state:随机数种子,即该组随机数编号。种子相同,随机数相同。
X_train:生成训练集的特征
X_test:生成测试集的特征
y_train:生成训练集标签
y_test :生成测试集标签
from sklearn.model_selection import train_test_split from sklearn.datasets import load_iris iris=load_iris() iris.data.shape,iris.target.shape X_train,X_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.4,random_state=0) print(X_train.shape,y_train.shape,X_test.shape,y_test.shape) print(iris.data[:5]) print(X_train[:5])
out:
(90, 4) (90,) (60, 4) (60,)
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
[[6. 3.4 4.5 1.6]
[4.8 3.1 1.6 0.2]
[5.8 2.7 5.1 1.9]
[5.6 2.7 4.2 1.3]
[5.6 2.9 3.6 1.3]]
(2)对数据集进行指定次数的交叉验证,并评测每次验证效果
使用cross_val_score(方法,数据集,目标类别集,cv=5)验证
from sklearn.model_selection import cross_val_score
from sklearn import svm
import numpy
clf = svm.SVC(kernel='linear',C=1)
'''C: float,optional(default=1.0)
错误项的惩罚参数C
Kernel:string,optional(default=’rbf’)
指定在算法中使用的内核类型。 它必须是'linear','poly','rbf','sigmoid','precomputed'或者callable之一。 如果没有给出,将使用'rbf'。 如果给出可调用,则它用于从数据矩阵预先计算内核矩阵。该矩阵应该是一个形状数组(n_samples,n_samples)。
'''
scores = cross_val_score(clf,iris.data,iris.target,cv=5) #5折(将数据集通过5次分割)交叉验证,当cv为int类型,默认KFold or StratifiedKFold进行数据集打乱
print(scores)
print(scores.mean())
out:
[0.96666667 1. 0.96666667 0.96666667 1. ]
0.980000000000000009
除上交叉验证外,可对交叉验证方式进行指定(cv),如验证次数、训练集测试集划分比例等
eg.使用ShuffleSplit将数据集打乱
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
from sklearn import svm
iris=load_iris()
clf = svm.SVC(kernel='linear',C=1)
cv = ShuffleSplit(n_splits=3,test_size=0.3,random_state=0) #数据集分3次,每次训练集大小占原数据70%
scores=cross_val_score(clf,iris.data,iris.target,cv=cv)
print(scores)
out:
[0.97777778 0.97777778 1. ]
(3)k折交叉验证( KFold(n_splits=...) )
通过k次分割,将数据集划分成k份,使所有数据集既在训练集出现过,又在测试集出现过。当然,每次分割中不会有重叠,类似无放回抽样。
from sklearn.model_selection import KFold
import numpy as np
X = ['a','b','c','d','e','f']
kf = KFold(n_splits=2) #2折交叉验证
for train,test in kf.split(X): #KFold.split()返回索引
print(train,test)
print(np.array(X)[train], np.array(X)[test])
print('\n')
out:
[3 4 5] [0 1 2]
['d' 'e' 'f'] ['a' 'b' 'c']
[0 1 2] [3 4 5]
['a' 'b' 'c'] ['d' 'e' 'f']
(4)LeaveOneOut验证
留一法是KFold的一个特例。一般用于数据集数目较少时。将N个样本打乱,均匀分成N份,轮流选择其中N-1份训练,剩余一份做验证,计算预测误差平方和,最终N次误差平方和做平均 作为选择最优模型结构的依据。
from sklearn.model_selection import LeaveOneOut
import numpy as np
X = ['a','b','c','d','e','f']
loo = LeaveOneOut()
for train,test in loo.split(X):
print(train,test)
print(np.array(X)[train], np.array(X)[test])
out:
[1 2 3 4 5] [0]
['b' 'c' 'd' 'e' 'f'] ['a']
[0 2 3 4 5] [1]
['a' 'c' 'd' 'e' 'f'] ['b']
[0 1 3 4 5] [2]
['a' 'b' 'd' 'e' 'f'] ['c']
[0 1 2 4 5] [3]
['a' 'b' 'c' 'e' 'f'] ['d']
[0 1 2 3 5] [4]
['a' 'b' 'c' 'd' 'f'] ['e']
[0 1 2 3 4] [5]
['a' 'b' 'c' 'd' 'e'] ['f']
如上代码,可以看出数据集个数为6个,每次训练集为5个数据,验证集只有1个数据,反复拆分。
将代码修改成KFold特例,即k=数据集个数N
from sklearn.model_selection import KFold
import numpy as np
X = ['a','b','c','d','e','f']
kf = KFold(n_splits=len(X))
for train,test in kf.split(X):
print(train,test)
print(np.array(X)[train], np.array(X)[test])
六.统计建模包(StatsModels)
StatsModels模块:一般线性模型、离散选择模型、时间序列分析、一系列描述统计学、非参数检验。
七.深度学习框架(TensorFlow)
TensorFlow是Google基于DistBrief进行研发的第二代人工智能学习系统,具备更好的灵活性和可延展性。
TensorFlow支持CNN、RNN、LSTM算法,这都是目前最流行的深度神经网络模型。
应用:语音识别、自然语言理解、计算机视觉、广告。
特点:
(1)高度灵活性:TensorFlow不是一个严格第‘神经网络库’,只要可以将计算表示为一个数据流图,就可使用TensorFlow。
(2)真正可移植性:TensorFlow在CPU 和GPU上运行,可运行在台式机、服务器、手机移动设备
(3)将科研和产品联系在一起:避免大量代码重写工作
(4)自动求微分功能:有利于基于梯度的机器学习算法
(5)多语言支持:有一个C++界面,也有Python界面来构建和执行Graphs
(6)性能最优化:TensorFlow支持线程、队列、异步操作等,将硬件的计算潜能全部发挥出来
import tensorflow as tf
sess = tf.Session() #tf.Session()创建一个会话,当上下文管理器退出时会话关闭和资源释放自动完成。
hello = tf.constant('hello,TensorFlow') #tf.constant()创建一个变量
print(sess.run(hello))
out:
b'hello,TensorFlow'
再测试一个基本数学例子
import tensorflow as tf sess = tf.Session() a = tf.constant(10) b = tf.constant(20) print(sess.run(a+b))
out:
30

 浙公网安备 33010602011771号
浙公网安备 33010602011771号