


20199120 2019-2020-2 《网络攻防实践》 综合实践大作业
20199120 2019-2020-2 《网络攻防实践》 综合实践大作业
1 论文介绍
本次选取的论文是来自Usenix Security 2020的《Automatic Techniques to Systematically Discover New Heap Exploitation Primitives》,值得注意的是论文发表的时间是2019年,2020年被Usenix Security收录。
1.1 作者介绍
论文完成作者是Insu Yun 、Taesoo Kim和Dhaval Kapil。Insu Yun 和Taesoo Kim来自韩国,Dhaval Kapil来自印度,这三位学者都曾在佐治亚理工学院进行过深造学习,目前Insu Yun 和Taesoo Kim均在佐治亚理工学院工作,Dhaval Kapil目前在Facebook工作。其中Dhaval Kapil(见下图)可谓年少有为,2017年大学毕业之后去Facebook工作,在2017年写了一本名为《Heap Exploitation》的书,是为那些想了解堆内存的内部结构,特别是glibc的malloc和free过程的实现以及相关的漏洞利用的人写的一篇短文,恰巧本篇论文是关于堆利用的问题。

1.2 论文研究背景
堆相关的漏洞是系统软件中最常见的,也是最关键的安全问题来源。根据微软的数据,2017年堆漏洞占其产品安全问题的53%。利用这些漏洞的一种方法是使用堆利用技术,这会滥用底层分配器。有两个特性使这些技术更适合于攻击。首先,堆利用技术往往是独立于应用程序的,这使得在不深入了解应用程序内部结构的情况下编写利用程序成为可能。其次,堆漏洞通常非常强大,攻击者可以通过滥用它们来绕过现代缓解方案。例如,一个看似良性的错误会将一个空字节覆盖到ptmalloc2的元数据中,从而导致Chrome操作系统上的权限提升。
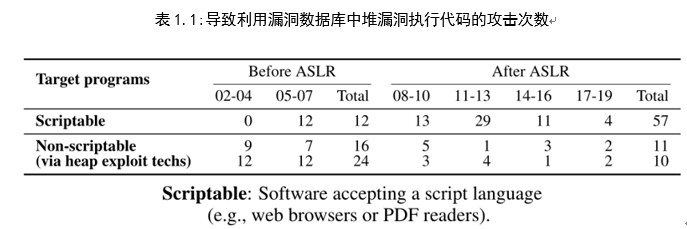
堆利用技术是危害不可编写脚本的程序的常用方法之一,可编写脚本的程序中的错误通常允许使用更简单、更简单的方法进行攻击,不需要使用堆利用技术。目前堆开发技术已经稳定地应用于实际的开发中。论文的作者从著名的exploit数据库exploit-db中收集了导致执行任意代码的堆漏洞的成功利用率。如表1.1所示,当ASLR未实现时,堆利用技术是危害软件的有利方法之一。即使在部署了ASLR之后,不可编写脚本的程序中的堆错误也经常通过堆利用技术来利用。更不用说,流行的软件,如Exim邮件服务器、Whats App和VMware ESXi都在2019年通过堆利用技术被劫持。可编写脚本的程序提供了更简单、更灵活的利用技术,因此攻击者还不喜欢使用堆攻击技术:例如,破坏类似数组的结构以实现任意读写。
大多数人一直在研究针对堆漏洞的可能的攻击技术,但发现此类技术通常被认为是一门“艺术”,因此用于发现这些漏洞的方法最多只能是临时的、手动的和特定于分配器的。以至于这种趋势使得大家很难理解各种堆分配器的安全含义。例如,在ptmalloc2中引入tcache以提高每线程缓存的性能时,其安全性评估不正确(即分配或空闲的完整性检查不足),从而使攻击变得更容易。
基于以上背景,作者提出了一个自动工具ARCHEAP,它可以系统地发现未探索的堆利用原语,而不管它们的底层实现如何。ARCHEAP的核心思想是让计算机自主地探索空间,这在概念上类似于模糊化。
1.3 论文创新点
作者实现了一款自动工具ARCHEAP,能够自动化发现堆利用原语,不需要人工理解堆分配器的内部实现。ARCHEAP采取了与fuzzing类似的技术,通过指定堆分配器和漏洞根本原因,自动化执行堆操作(分配、释放)和读写操作,来发现堆利用原语。作者的贡献在于展示了堆分配器的常见设计,并设计了一种高效的、使用影子内存来评估exploit有效性的方法,能够对多种堆分配器,根据漏洞自动化发现其利用方式。ARCHEAP发现了五种针对ptmalloc2的新利用方式,以及针对tcmalloc、 jemalloc、DieHarder等堆分配器的多种利用方式。
应用经典的模糊化技术来发现新的堆利用原语并非易事,原因有三。首先,要成功触发堆漏洞,它必须使用精确的数据生成特定的步骤序列,使用模糊化方法快速解决问题。因此,研究人员试图用符号执行来解决这一问题,但却遇到了众所周知的状态爆炸问题,从而将其范围限制在验证已知的利用技术上。其次,需要设计一种快速的方法来估计堆利用的可能性,因为模糊化需要清晰的信号,比如分段错误,来识别有趣的测试用例。第三,模糊器生成的测试用例通常是冗余和模糊的,因此用户需要花费不可忽视的时间和精力来分析最终结果。
克服这些挑战(即减少搜索空间)的关键直觉是抽象堆分配器的内部结构和堆漏洞的根本原因。特别是,观察到堆分配器共享三个常见的设计组件,即binning, in-placemetadata, 和cardinal data.。在这些模型的基础上,指导ARCHEAP对堆操作和攻击能力进行变异和综合。在探索过程中,ARCHEAP检查生成的测试用例是否可以用于构造开发原语,例如任意写入或重叠块:我们设计了基于阴影内存的检测,以实现有效的评估。每当ARCHEAP发现新的漏洞利用原语时,它会使用增量调试生成一个工作的PoC代码,以将冗余测试用例减少到最小的等效类。
2 基础知识
由于之前没有接触过计算机操作系统等课程,以至于刚开始在读这篇论文时遇到了很多名词或者很多技术不是很理解,有的也已经忘记。虽然有一些关于堆栈的知识在本门课程的第10章有一部分介绍,但为了更好的理解论文的内容,下面对论文中提及的名词或者技术进行介绍。
2.1 相关名词介绍
2.1.1 Metadata
元数据(Metadate),关于数据的数据或者叫做用来描述数据的数据或者叫做信息的信息。这些定义都很是抽象,我们可以把元数据简单的理解成,最小的数据单位。元数据可以为数据说明其元素或属性(名称、大小、数据类型、等),或其结构(长度、字段、数据列),或其相关数据(位于何处、如何联系、拥有者)
2.1.2 POC
POC(Proof of Concept)中文意思是“观点证明”。这个短语会在漏洞报告中使用,漏洞报告中的POC则是一段说明或者一个攻击的样例,使得读者能够确认这个漏洞是真实存在的。
2.1.3 ASLR
ASLR(Address space layout randomization)地址空间布局随机化,是参与保护缓冲区溢出问题的一个计算机安全技术。是为了防止攻击者在内存中能够可靠地对跳转到特定利用函数。ASLR包括随机排列程序的关键数据区域的位置,包括可执行的部分、堆、栈及共享库的位置。
ASLR通过制造更多让攻击者预测目标地址的困难以阻碍一些类型的安装攻击。如果攻击者试图执行返回到libc的攻击必须要找到要执行的代码,而其他攻击者试图执行shellcode注入栈上则必须首先到栈。在这两种情况下,系统将模糊攻击者相关的存储器地址。这些值被猜中,并且错误的猜测由于应用程序崩溃通常是不可恢复的。
例如一些攻击,比如return-oriented programming (ROP)之类的代码复用攻击,会试图得到被攻击者的内存布局信息。这样就可以知道代码或者数据放在哪里,来定位并进行攻击。比如可以找到ROP里面的gadget。而ASLR让这些内存区域随机分布,来提高攻击者成功难度,让攻击者只能通过猜猜猜来进行不断试错的攻击(理想状况下)。
2.1.4 HEAPHOPPER
HEAPHOPPER与本论文中ARCHEAP的作用类似,是一个自动化的方式,基于模型检测和符号执行,来分析内存损坏情况下的堆利用实现。在论文《HEAPHOPPER: Bringing Bounded Model Checking to Heap Implementation Security》中提出,作者通过使用符号执行技术,自动化分析堆分配器,根据配置文件定义的情况可以自动生成不同exploitation primitive 的POC,可帮助安全研究员自动化的分析堆分配器的利用方法。HEAPHOPPER与ARCHEAP非常相似,可以说后者是前者的加强版。
2.1.5 glibc
glibc是GNU发布的libc库,即c运行库。glibc是linux系统中最底层的api,几乎其它任何运行库都会依赖于glibc。glibc除了封装linux操作系统所提供的系统服务外,它本身也提供了许多其它一些必要功能服务的实现。glibc 和 libc 都是 Linux下的C函数库。libc是Linux下的ANSI C函数库;glibc是Linux下的GUNC函数库。ANSI C函数库是基本的C语言函数库,包含了C语言最基本的库函数。GNU C函数库是一种类似于第三方插件的东西。由于Linux是用 C语言写的,所以Linux的一些操作是用C语言实现的,因此,GUN组织开发了一个C语言的库以便让我们更好的利用C语言开发基于Linux 操作系统的程序。
glibc是linux下面C标准库的实现,即GNU C Library。glibc本身是GNU旗下的C标准库,后来逐渐成为了Linux的标准C库,而Linux下原来的标准C库Linux libc逐渐不再被维护。Linux下面的标准C库不仅有这一个,如uclibc、klibc,以及上面被提到的Linux libc,但是glibc无疑是用得最多的。glibc在/lib目录下的.so文件为libc.so.6。
2.1.6 影子内存(Shadow RAM)
影子内存(shadow RAM)是为了提高系统效率而采用的一种专门技术,是基本输入输出操作系统(BIOS)程序在随机访问存储器(RAM)中的一个备份,它们能被更快的访问。
2.1.7 house of lore
house of lore的利用种类是堆溢出,是针对smallbin的利用。利用思的想是利用smallbin为双向链表,每次malloc取了链表最后一个元素,可以通过更改链表指针,使其分配一个刻意构造的地址
2.2 Linux的内存布局
2.2.1 32位模式下内存的经典布局
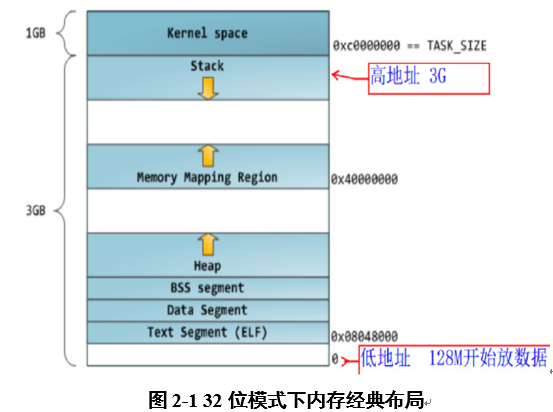
说明:
(1)在32的机器上,loader将可执行文件的各个段次依次载入到从0x80048000(128M)位置开始的空间中。程序能够访问的最后地址是0xbfffffff(3G)的位置,3G以上的位置是给内核使用的,应用程序不能直接访问。
(2)内存布局从低地址到高地址依次为:txet段、data段、bss段、heap、mmap映射区、stack堆栈区。
(3)heap和mmap是相对增长的,也就意味着heap只有1G的虚拟地址空间可供使用。
(4)stack区域不需要映射的,用户可以直接访问该区域。这也是利用堆栈溢出进行攻击的基础。
注:这种内存布局模式是linux内核2.6.7以前的默认内存布局形式
2.2.2 32位模式下内存的默认布局
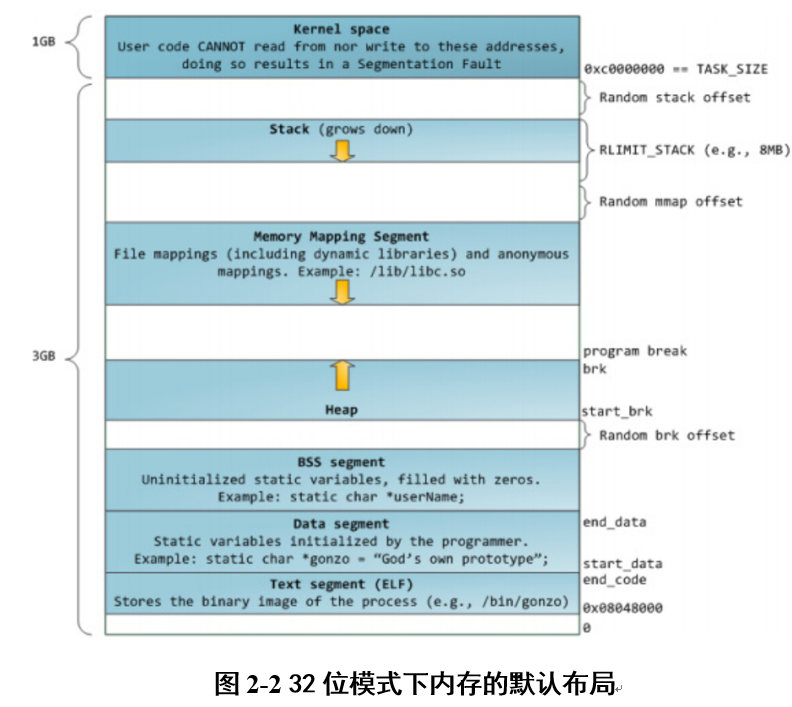
说明:
(1)这种内存布局方式加入了几个Random offset的随机偏移,这样的话内存溢出的攻击就不会那么容易了。
(2)栈是自顶向下扩展的,但是栈是有边界的栈大小就有了限制。堆是自底向上扩展的,mmap映射区自顶向下扩展。故mmap和heap是相对扩展的,直至消耗尽虚拟地址空间中的剩余区域,这种结构便于C运行库使用mmap映射区和堆进行内存分配。
注:这种内存布局是linux内核2.6.7之后32位机器的默认内存布局方式。
2.2.3 64位模式下内存的默认布局
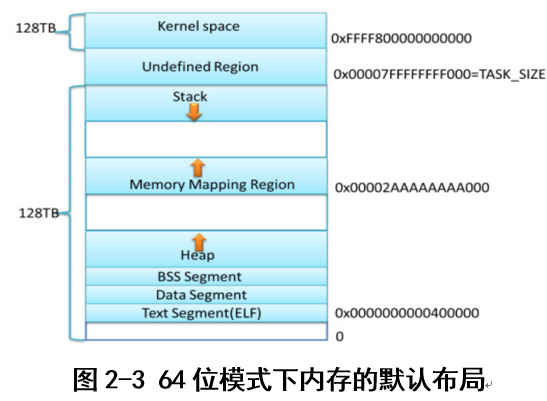
说明:这种内存布局方式沿用的32位模式下内存的经典布局,但是栈和mmap的映射区域不再是从一个固定的地方开始,每次启动时的值都不一样。这样一来,使得使用缓冲区溢出攻击变得更加困难。
2.2 操作系统内存分配的相关函数
heap和mmap映射区域是可以提供给用户程序使用的虚拟内存空间,获得该区域的内存的操作有:
(1)对于heap操作,操作系统提供了brk()系统调用,c运行库提供了sbrk()库函数。
(2)对于mmap映射区的操作,操作系统提供了mmap()和munm()系统调用。
(3)linux内存管理的基本思想:内存延迟分配。即只有在真正访问一个地址的时候才建立这个地址的物理映射。linux内核在用户申请内存的时候,只是给它分配了一个虚拟地址,并没有分配实际的物理地址,只有当用户使用这块内存的时候,内核才会分配具体的物理地址给用户使用。
2.3 chunk的结构
(1)chunk的使用:用户请求分配的空间在ptmalloc中都使用一个chunk来表示。用户调用free函数释放掉的内存也不是立即就返回操作系统,它们会被表示成一个chunk。ptmalloc中使用特定的数据结构管理这些空闲的chunk。
(2)chunk的格式
ptmalloc在给用户分配的空间的前后加上一些控制信息,用这样的方式来记录分配的信息。一个正在使用中的chunk如图2-4所示:
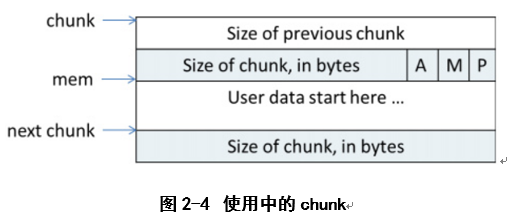
说明:
<1>chunk指针指向chunk开始的地址;mem指针指向用户内存块开始的地址。
<2> p=0时,表示前一个chunk为空闲,prev_size才有效。
<3> p=1时,表示前一个chunk正在使用,prev_size无效。p主要用于内存块的合并操作。
<4> ptmalloc分配的第一个块总是将p设为1,以防止程序引用到不存在的域。
<5> M=1为mmap映射区域分配;M=0为heap区域分配。
<6> A=1为非主分区分配;A=0 为主分区分配。
空闲chunk在内存中的结构:
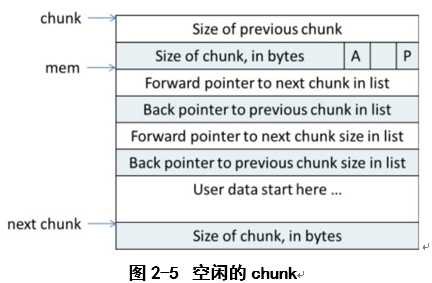
说明:
<1> 空闲的chunk会被放置到空闲的链表bins上。当用户申请内存malloc的时候,会先去查找空闲链表bins上是否有合适的内存。
<2> fp和bp分别指向前一个和后一个空闲链表上的chunk
<3>fp_nextsize和bp_nextsize分别指向前一个空闲chunk和后一个空闲chunk的大小,主要用于在空闲链表上快速查找合适大小的chunk。
<4>fp、bp、fp_nextsize、bp_nextsize的值都会存在原本的用户区域,这样就不需要专门为每个chunk准备单独的内存存储指针了。
2.4 chunk的组织—bins
用户释放掉的内存并不是马上就归还给操作系统,ptmalloc会统一管理heap和mmap映射区中的空闲的chunk,当用户进行下一次请求分配时,ptmalloc会试图从空闲的内存中挑选一块给用户,这样可以避免频繁的系统调用,降低了内存分配的开销。ptmalloc将大小相似的chunk用双向循环链表连接起来,这样的一个链表称为bin。ptmalloc中一共维护了128个bin,并使用一个数组来存储这些bin(数组实际存储的是指针)
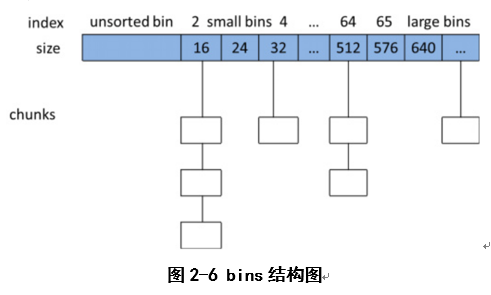
(1)fast bins
fast bins是small bins的高速缓冲区。fast bin使用单向链表实现。当程序运行需要申请和释放一些较小的内存空间。一般对于不大于max_fast(在SIZE_SZ为4B的平台默认是64B)的chunk释放后就会先被放到fast bins中,fast bins中有七个chunk空闲链表(bin),每个bin的chunk大小依次为16B、24B….64B。fast bins中的chunk并不改变它的使用标志P,这样就无法合并他们。当需要给用户分配小于或者是等于max_fast大小的内存时,ptmalloc会首先在fast bins中查找,然后才会去Bins中查找空闲的chunk。有时ptmalloc也会遍历fast bins中的chunk,将相邻的空闲的chunk进行合并,并将合并后的chunk加入到unsorted bin中,然后将unsorted bin中的chunk加入到bin中。
(2)unsorted bin
相当于small bins和large bins的一个缓冲区,unsorted bin是bins数组中的第一个,用双向链表管理chunk,空闲的chunk不排序,所有的chunk在回收时都要先放到unsorted bin中。进行malloc操作时,如果fast_bins中没有找到合适的chunk,则ptmalloc就会在unsorted bin中查找空闲的chunk,如果unsorted bin中没有合适的chunk,就会把unsorted bin中所有chunk分别加入到所属的bin中,然后再在bin中查找合适的chunk。Bins数组中元素bin[1]用来存储unsorted bin的链表头。
(3) small bins
数组中从2号下标开始的到64号下标的62个bin称为small bins。同一个small bin中的chunk具有相同的大小,两个相邻的small bin中的chunk大小在SIZE_SZ为4B的平台上相差 8bytes,在SIZE_SZ为8B的平台上相差 16bytes。small bin 中chunk按照最近使用顺序进行排列,最后释放的chunk被连接到链表的头部,而申请的chunk是从链表尾部开始的。
(4)large bins
在SIZE_SZ为4B的平台上,大于等于512B的空闲的chunk由large bin管理。large bins一共包含63个bin,每个bin中的chunk大小不是一个固定的等差数列,而是分成6组bin,每组bin是一个固定的等差数列。每组bin数量依次为32、16、8、4、2、1,公差依次为64B、512B、4096B、32768B、262144B等。
(5)tcache
在glibc2.27中,tcache的基本结构与fastbin类似,都是根据chunk的大小将chunk放到不同的bins里,也都是通过单链表来存储释放的chunk,但是单链表的链接方式还是有所不同的。
3 论文核心
了解前面的一些基础知识之后,再来读论文会相对比较容易点,下面对论文的核心内容进行介绍。
3.1 堆分配器的常见设计
在分析各种堆分配器时,发现它们的共同设计原则如表3所示:binning, in-place metadata, and cardinal data。许多分配器使用基于大小的分类,称为binning。特别是,它们将整个大小范围划分为多个组,以便根据它们的大小组来有意地管理内存块;小型块关注性能,大块关注分配器的内存使用情况。此外,通过划分大小组,当他们试图找到最适合的块,最小但足够满足给定请求的块时,他们只扫描适当大小组中的块,而不是扫描所有内存块。
此外,许多动态内存分配器将元数据放在称为in-place metadata的有效负载附近,尽管有些分配器会避免这种情况,因为存在内存损坏错误时损坏元数据的安全问题(见表3)。为了最小化内存碎片,内存分配器应该在元数据中维护有关已分配或已释放内存的信息。尽管分配器可以将元数据和有效载荷放在不同的位置,但许多分配器将元数据存储在有效载荷附近(即块的头部或尾部),以增加局部性。特别是,通过连接元数据和有效负载,分配器可以从缓存中获益,从而提高性能。

此外,内存分配器只包含cardinal data,它们不是编码的,对于快速查找和内存使用是必不可少的。特别是,元数据主要是用于其数据结构的指针或大小相关的值。例如,ptmalloc2为一个链接列表存储一个原始指针,用于维护释放的内存块。
这一观察结果被用来设计一种通用的方法来测试各种分配器,而不管它们的实现如何。首先,我们的方法应该考虑使用binning来探索一个分配器的多个大小组。例如,如果我们在264空间中统一选择一个尺寸,那么在ptmalloc2)中选择最小尺寸组的概率几乎为零)。因此,我们需要使用一种更好的考虑分块的抽样方法。此外,其他两个设计原则(in-place metadata和cardinal data)限制了元数据的位置和域,从而减少了搜索空间。在这些设计原则下,我们只需要关注具有特定形式(即指针或大小)的块边界中的元数据。
3.2 Heap Abstract Model
ARCHEAP模型从两个方面抽象了堆技术:1)错误类型(即允许攻击者将程序转移到意外状态)和2)利用漏洞的影响(即描述攻击者可以获得的结果)。
1) 错误类型。 四种常见的与堆相关的错误会实例化攻击:
Overflow (OF):超出对象边界写入
Write-after-free (WF):重用释放的对象
Arbitrary free (AF):释放任意指针
Double free (DF):释放回收的对象
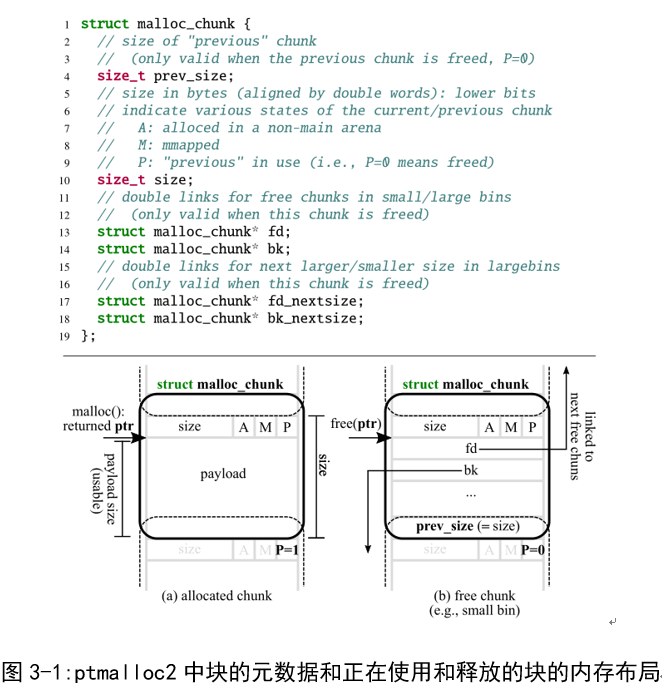
开发人员的每一个错误都允许攻击者以某种方式将程序转移到意外状态:溢出允许修改任何后续块的所有元数据(如图3-1中的struct malloc_chunk);WF允许修改自由元数据(例如,图3-1中的fd/bk),这在实质上与use-after-free相似;DF允许违反内部堆元数据的操作完整性(例如,堆结构中链接的多个回收指针);而任意释放同样会破坏堆管理的操作完整性,但以高度控制的方式释放带有精心编制的元数据的对象。由于溢出支持多种攻击路径,我们根据开发人员的常见失误和错误进一步描述其类型。
Off-by-one (O1):覆盖下一个后续块的最后一个字节(例如,在大小计算中出错时,如CVE-2016-5180[31])
Off-by-one NULL (O1N):与前一个类型类似,但重写空字节(例如,当使用与字符串相关的库时时的sprintf)
值得注意的是,与假设任意读写的典型漏洞利用场景不同,我们排除这些原语的原因有两个:它们对应用程序和执行上下文过于特定,对泛化几乎没有意义,而且它们对攻击者发动更容易的攻击非常强大,降低堆利用技术的积极性。因此,这种强大的原语被认为是堆利用的最终目标之一。
2)利用漏洞的影响。每种堆利用技术的目标都是将常见类型的堆相关bug开发成更强大的攻击原语,以进行全面的攻击。为了系统化堆利用,我们将其最终影响(即已实现的利用原语)分为四类:
Arbitrary-chunk (AC):劫持下一个malloc以返回任意选择的指针。
Overlapping-chunk (OC): 攻击者劫持下一个malloc以返回可控制(例如,可覆盖)块内的块
Arbitrary-write (AW): 将堆漏洞发展为任意写入(写where what primitive)。
Restricted-write (RW): 类似于任意写入,但有各种限制(例如,不可控的“什么”,例如指向全局堆结构的指针)
3.3 设计技术挑战
我们的目标是自动探索新类型的堆利用技术,给定任何堆分配器的实现,其源代码不需要AFL。这样该功能不仅支持自动开发综合,还使一些前所未有的应用成为可能:1)系统地发现未知类型的堆利用方案;2)全面评估流行堆分配器的安全性;3)深入了解什么以及如何提高它们的安全性。然而,实现这种自主能力绝非易事,原因如下。
堆空间的自主推理。 要找到堆利用技术,我们应该满足复杂的约束条件,在由大量可能的顺序、堆api的参数、堆和全局缓冲区中的数据组成的大型搜索空间中绕过安全检查。使用特定于漏洞利用的知识可以大大减少此空间;但是,这不适用于查找新的利用技术。为了解决这个问题,我们使用了一种随机搜索算法,这种算法可以有效地搜索到大的搜索空间。我们还抽象了现代堆分配器的常见设计,以进一步减少搜索空间。
设计开发技术。 在列举利用技术的可能候选项时,系统需要验证候选项是否有价值。评估候选对象的一种方法是自动合成端到端攻击(例如,生成一个shell),但这非常困难且效率低下,尤其是对于堆漏洞。为了解决这个问题,我们使用了剥削影响的概念。特别是,我们在勘探期间估计开采(即AC、OC、AW和RW)的影响,而不是综合整个开采。我们展示了这些影响可以通过使用影子内存在运行时快速检测到。
规范化。 即使随机搜索是有效的在探索大型搜索空间,开发技术该算法发现往往是冗余和无名小格的需要非平凡的时间来分析结果。要修复这个问题,我们利用增量调试技术最小化冗余操作并转换找到的操作结果进入一个基本类。这是非常有效的,我们可以减少84.3%的行动,大大帮助我们分享新的开发技术。
3.4 ARCHEAP
3.4.1概述
ARCHEAP遵循经典模糊化中的一种常见范式:测试生成、崩溃检测和测试缩减,但它是为堆利用而定制的。它首先根据用户提供的模型规范生成堆操作序列。这个规范是可选的;如果没有给出,ARCHEAP将生成所有可能的操作。ARCHEAP可以制定的堆操作包括堆分配、空闲、缓冲区写入、堆写入和错误调用。在执行过程中,ARCHEAP评估执行的测试用例是否会导致开发的影响,这在概念上类似于检测模糊化中的崩溃。每当ARCHEAP发现新的漏洞利用时,它会最小化堆操作并生成PoC代码。值得注意的是,这种最小化是为了帮助对发现的技术进行后分析,但与误报无关;ARCHEAP在我们的评估过程中不会产生假阳性,这要归功于它在运行时的直接分析。
3.4.2 堆相关操作
ARCHEAP随机生成五种与堆相关的操作:分配、存储单元分配、缓冲区写入、堆写入和错误调用。为了减少搜索空间,ARCHEAP使用现代分配器的常见设计习惯,在抽象堆模型的顶部制定每个操作。下面解释每个操作如何利用设计来减少搜索空间。
分配。ARCHEAP可以执行的第一个操作是通过标准化API malloc()分配内存。分配内存后,ARCHEAP将返回对象的地址存储到其内部数据结构(称为容器)中。它还使用另一个API ,malloc_usable_size()存储对象的块大小及其状态,以便在其他操作中进一步使用(图3-2中的第15-23行),例如释放或错误调用。
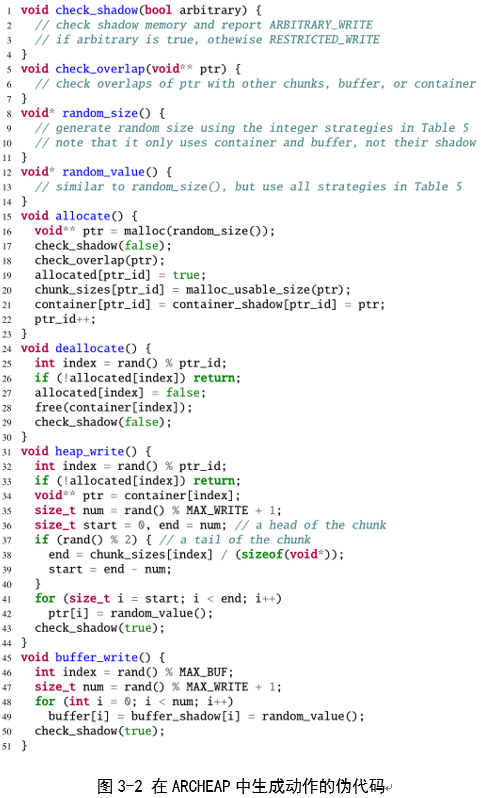
ARCHEAP以随机大小分配内存,但要考虑多个方面来测试分配器。首先,ARCHEAP仔细选择一个对象的大小(表5中的I1)来检查不同容器中的不同逻辑。特别是,ARCHEAP首先随机选择一组大小,然后分配一个大小在该组中的对象。这个组被近似的边界值分开,而不是特定于实现的边界值,以使ARCHEAP与任何分配器兼容。目前,ARCHEAP使用四个边界,指数距离从20到220,例如第一组是[20,25),第二组是[25,210),等等,因此可以选择较小的尺寸。例如,在ptmalloc2中生成快速bin对象的几率将超过1/4(即选择第一组的机会),在均匀采样中为2-57。这种划分是任意的,但足以增加探索各种bin的概率。

ARCHEAP还试图在同一个bin(I2)中分配多个对象,因为一个对象与同一个bin中的其他对象交互。例如,在ptmalloc2中,非fast bin对象与非fast bin对象合并,而不是与fast bin对象合并。为了覆盖这个交互,ARCHEAP分配一个大小与另一个对象大小相关的对象。
为了找到由分配器中常见错误引起的技术,ARCHEAP还使用专门的大小(I3、I4)。特别是,ARCHEAP使用指针之间的差异来查找分配器中的整数溢出漏洞。例如,易受攻击的分配器在声明非常大的块(其大小与缓冲区和堆对象之间的差异相同)时可能返回缓冲区地址。ARCHEAP还利用一些预定义的常量,例如零或负数来评估其边缘大小写处理。这类似于经典的模糊处理,它使用一组固定的整数来检查边界条件。
存储单元分配。ARCHEAP使用free()从堆容器释放随机选择的堆指针。为了避免启动一个双重释放的bug,这将在bug调用操作中模拟,ARCHEAP检查对象的状态。如果ARCHEAP选择了一个已经释放的指针,它会忽略释放操作来避免错误。
堆和缓冲区写入。ARCHEAP可以制定的下一个操作是将随机数据写入堆对象或全局缓冲区。如上所述,要找到堆利用技术,写入的数据应该在其位置和值方面是准确的,这使得经典的模糊处理(即纯随机生成)不可行。为了克服这些限制,ARCHEAP利用堆分配器的就地和基本元数据设计来缩减其搜索空间。特别是,ARCHEAP只从对象的开始或结尾写入有限数量的值,因为分配器将其元数据存储在局部性边界附近(就地元数据)。此外,ARCHEAP生成随机值(见表3-2),这些值可用于分配器中的大小或指针,而不是完全随机的值。
为了探索各种开发技术,ARCHEAP在生成的值中引入了系统噪声。特别是,ARCHEAP根据值的类型使用线性(加法和乘法)或移位变换(仅加法)修改值。例如,堆地址可以按字粒度移动(即,考虑对齐);但是,它不会乘以常量,因为它是指针类型。与释放类似,ARCHEAP只在有效的堆区域中写入数据(即,没有溢出或下溢),以确保操作的合法性。
为了寻找存在堆漏洞时的堆利用技术,ARCHEAP需要执行错误操作。目前,ARCHEAP在堆中处理了6个bug:overflow、write-after-free、off-by-one overflow,、off-by-one NULL overflow、double free、arbitrary free 。ARCHEAP只对威胁模型中描述的限制对手力量的技术执行其中一个错误。此外,ARCHEAP允许重复执行同一个bug,以模拟攻击者重新触发该bug的情况。
ARCHEAP故意构建一个错误动作来确保它的发生。对于overflow和off-by-one,ARCHEAP使用malloc-unu-usable-size-API获取实际堆大小以确保溢出。这是必要的,因为由于对齐或最小大小限制,请求大小可能小于实际大小。特别是对于ptmalloc2,ARCHEAP使用一个专用的单行例程来获取实际大小,因为ptmalloc2的malloc_usable_size()在内存损坏错误存在的情况下是不准确的。此外,在double free和write after free中,ARCHEAP检查目标块是否已经被释放。如果它还没有被释放,ARCHEAP会忽略这个有缺陷的动作,并等待下一个动作。
模型设定。用户可以选择性地提供模型规范,以指示ARCHEAP专注于某种类型的利用技术,或者限制目标环境的条件。它接受五种类型的模型规范:chunk sizes, bugs, impacts, actions, knowledge。前四种类型是不言而喻的,knowledge是关于攻击者破坏ASLR的能力(即某些地址的先验知识)。用户可以指定攻击者可能知道的三种类型的地址:堆地址、全局缓冲区地址和容器地址。
3.4.3检测攻击的影响
ARCHEAP检测四种类型的攻击影响,它们是全链攻击的构建块:arbitrary-chunk (AC), overlapping-chunk (OC), arbitrary-write (AW),and restricted-write (RW)。这种方法有两个好处,即表现力和性能。这些类型在开发控制劫持(攻击者的最终目标)时非常有用。因此,所有现有的技术都会导致这些类型中的一种,即,可以用这些类型来表示。而且,通过简单的隐藏堆空间的数据结构来检测这些类型的存在会导致较小的性能开销。
为了检测AC和OC,ARCHEAP确定每个分配中的任何重叠块(图3-2中的第18行)。为了保证检查的安全性,它会在malloc之后复制块的地址和大小,因为在执行错误操作时它可能会被破坏。使用存储的地址和大小,它可以快速检查块是否与其数据结构(AC)或其他块(OC)重叠。
为了检测AW和RW,ARCHEAP使用称为影子内存的技术安全地复制其数据结构、容器和全局缓冲区。在执行期间,ARCHEAP在执行可以修改其内部结构的操作时同步影子内存的状态:容器的分配和全局缓冲区的缓冲区写入(图3-2第21、49行)。然后,ARCHEAP在执行任何操作时检查阴影内存的分歧或矛盾(图3-2第17、29、43、50行)。由于ARCHEAP保持了显式的一致性,因此只有在以前执行的操作通过堆分配器的内部操作修改ARCHEAP的数据结构时,才会发生分歧。稍后,可以重新制定这些操作,以修改应用程序的敏感数据,而不是用于攻击的数据结构。
ARCHEAP的模糊化策略(表3-2)通过将分析范围限制在其数据结构上,使这种检测变得高效。通常,堆利用技术可以损坏任何数据,导致扫描整个内存空间。然而,ARCHEAP发现的技术只能修改堆或数据结构,因为这些是其模糊化策略中唯一可见的地址。ARCHEAP只检查其数据结构中的修改,但忽略堆中的修改,因为在不深入了解分配器的情况下,很难区分合法的(例如,在释放中修改元数据)和滥用的数据结构(即,堆利用技术)。这在语义上等同于监视分配器的隐式不变量的暴力行为-它不应该修改不受其控制的内存。
ARCHEAP基于导致分歧的堆操作来区分AW和RW。如果在分配或释放中出现分歧,它将得出RW,否则(即在堆或缓冲区写入中)它将得出AW。潜在的直觉是,前一个动作中的参数很难被任意控制,而在后一个动作中则不是。检测到分歧后,ARCHEAP将原始内存复制到其影子中,以停止重复检测。
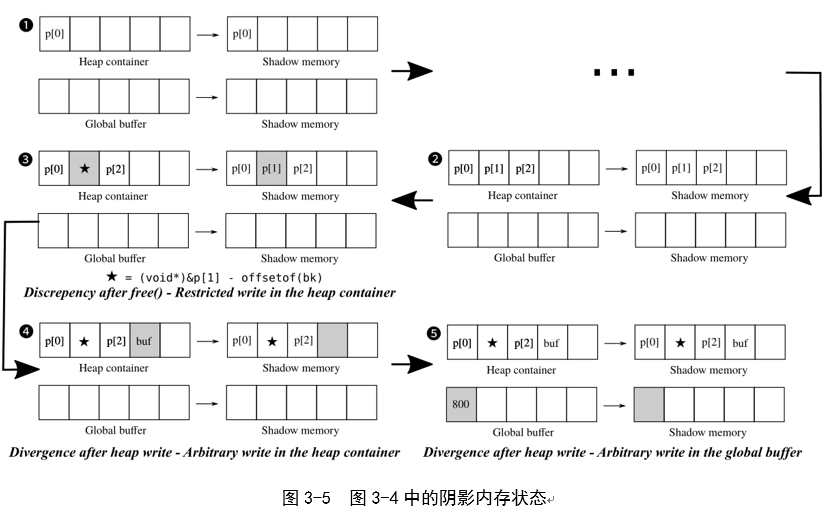
一个典型的例子:图3-5显示了执行图3-4时影子内存的状态。
1 .在第一次分配之后,ARCHEAP更新其堆容器和相应的影子内存,以保持它们的一致性,这可能会受到操作的影响。
2 .它再执行两个分配,因此相应地更新堆容器和影子内存。
3 .取消分配后,由于ptmalloc2中的unlink(),p[1]被改为⋆(图2a)。此时,ARCHEAP会检测到来自原始堆容器的阴影内存的差异。由于这种分歧发生在释放过程中,因此利用漏洞的影响仅限于堆容器中的受限写入。
4 .在这种情况下,由于堆写入导致了分歧,因此这些操作可以触发堆容器中的任意写入。
5 由于这种堆写入在全局缓冲区中引入了分歧,因此这些操作可能导致全局缓冲区中的任意写入。

3.4.4通过 Delta-Debugging生产PoC
为了找到利用漏洞的根本原因,ARCHEAP使用delta调试优化测试用例,如算法1所示。该算法在概念上很简单:对于每个动作,ARCHEAP重新评估在没有它的情况下开发测试用例的影响。如果原始测试用例和新测试用例的影响相等,则认为排除的操作是多余的(即对开发没有任何有意义的影响)。这个决定背后的直觉是,许多操作是独立的(例如,缓冲区写入和堆写入),因此delta调试可以清楚地将非必要的操作从测试用例中分离出来。我们目前的算法仅限于一次评估一个单独的动作。它可以很容易地扩展到使用一个序列或堆操作的组合进行检查。
一旦最小化,ARCHEAP使用每个操作和C代码之间的一对一映射(例如,分配操作→malloc()),将编码的测试用例转换为人们可以理解的PoC,如图3-4所示。

3.5 新的堆利用技术
Unsorted bin into stack (UBS):此技术重写未排序的bin以链接假块,以便它可以返回假块(即任意块)的地址。这类似于house of lore。然而,Unsorted bin into stack技术只需要一种分配,而不像house of lore,它需要两种不同的分配,将一个块移动到一个小的bin列表中。
House of unsorted einherjar (HUE):这是house of einherjar的一个变体,它使用off-by-one NULL字节溢出并返回任意块。在house of einherjar中,攻击者应该事先知道一个堆地址来破坏ASLR。然而,在house of unsorted einherjar中,攻击者可以在没有这个前提条件的情况下达到相同的效果。我们将这项技术命名为“House of unsorted einherjar”,因为它有趣地将两种技术“house of einherjar”和“unsorted bin”组合到堆栈中,以放宽对众所周知的开发技术的要求。
Unaligned double free (UDF):这是一种非常规的技术,它滥用在一个small bin里的double free,由于全面的安全检查,这通常被认为是一个薄弱的攻击面。为了避免安全检查,双重空闲的受害者块应该有适当的元数据,并被欺骗为正在使用(即下一个块的P位是1)。由于double-free不允许任意修改元数据,现有技术只能滥用fast bin或tcache,后者的安全检查比small bin弱。
Overlapping chunks using a small bin (OCS):这是重叠块(OC)的一种变体,它滥用unsorted bin来生成重叠块,但是这种技术在一个small bin中处理块的大小。与OC不同,它需要更多的操作:三个malloc()和一个free(),但不需要攻击者控制分配大小。当攻击者无法调用任意大小的malloc()时,此技术可以有效地构建重叠块以供攻击。
Fast bin into other bin (FDO):这是另一种有趣的技术,它允许攻击者返回任意地址:它滥用合并功能将受害者块的类型从fast bin转换为另一种类型。首先,它会破坏一个快速的bin-free列表来插入一个假块。然后,在释放过程中,它调用malloc_consolidate() 将假块移动到未排序的bin中。与其他fast bin相关的技术不同,这个假块不必在fast bin中。由于空间限制,排除了这个PoC,但它在存储库中是可用的。
4 论文功能复现
接下来对论文中提出的新的堆利用技术进行复现,使用环境是虚拟机seed。首先编写Makefile文件(如图4-1),通过Makefile文件来描述源程序之间的相互关系并自动维护编译工作,执行命令如图4-2,执行结果如图4-3.
5.课程总结与课堂建议
一学期的课程马上就结束了,依然记得第一次搭建环境的不顺,也记得命令运行成功的喜悦,更记得每次完成老师任务的解脱感,这一路走来有失望、也有惊喜,有忐忑、也有收获,但更多的是感谢与收获。
感谢王老师(强哥)的辛勤付出,虽然布置的任务有时惹来我们的吐槽,但时不时还给我们来一碗“鸡汤”( 优秀的人,不是与生俱来就领先一步,也不一定比别人更加幸运。他们中的多数,只是在任何一件小事上,都对自己有所要求,不因舒适而散漫放纵,不因辛苦而放弃追求。雕塑自己的过程,必定伴随着疼痛与辛苦,那一锤一凿地敲打,终能让我们收获一个更好的自己),现在每周四下午没有了令人“兴奋”又“忐忑”的攻防实践的我们,非常的怀念之前的时光!
感谢各位同学、各位大佬一路、两位辛勤付出的课代表的帮助,“滴水之恩,当涌泉相报”,在实践的过程中,自己遇到解决不了的问题,经常向他们求助,在这里向他们说一声“谢谢”。
站在现在,回往过去,发现自己的能力比之前有了长足进步,这便是收获之处。学到的知识主要有网络信息的收集、网络嗅探技术、TCP/IP协议攻击、入侵检测技术、Linux与Windows操作系统的攻防技术、恶意代码分析、缓冲区溢出与Shellcode、Web应用程序安全攻防、Web浏览器安全攻防。其中印象非常深刻的是Web应用程序那一章(11章)的SQL注入与XSS跨脚本攻击,因为在池老师那门课上,也做了这个实验,发现自己比较快速的做完了实验,这才发现自己的能力提高了,在考试中也考了反射XSS漏洞。
网络攻防与实践是一门非常注重实践的学科,所以老师给的实践时间很多。有一点建议是有的跨专业或者本科期间没有学过计算机网络等基础课程的同学,如果没有老师对的知识原理的讲解,直接对照着课本学习进行实践的话难度会比较大一点。不过话又说回来,研究生注重的是自主学习能力,在老师的提示指导下完成实验也是必须具备的能力。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号