Kafka
CREATED 2021/08/17 23:13:39
MODIFIED 2021/12/01 21:27:00
Kafka
Apache Kafka is a publish-subscribe based durable messaging system. A messaging system sends messages between processes, applications and servers.
Kafka uses ZooKeeper to manage the cluster. ZooKeeper is used to coordinate the brokers/cluster topology. ZooKeeper is a consistent file system for configuration information.
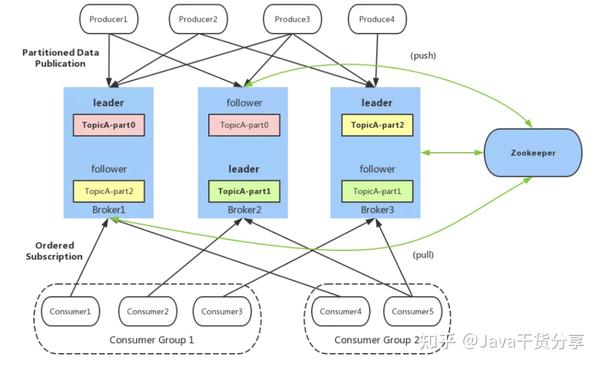
Kafka 将消息以 topic 为单位进行归纳。Kafka遵循了一种大部分消息系统共同的传统的设计:producer将消息推送到broker,consumer从broker拉取消息。
基本组成
Producer :生产者,负责将消息发送到 Broker。
Consumer :消费者,从 Broker 接收消息Consumer。
Group :消费者组,由多个 Consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
Broker :可以看做一个独立的 Kafka 服务节点或 Kafka 服务实例。如果一台服务器上只部署了一个 Kafka 实例,那么我们也可以将 Broker 看做一台 Kafka 服务器。
Topic :一个逻辑上的概念,包含很多 Partition,同一个 Topic 下的 Partiton 的消息内容是不相同的。
Partition :为了实现扩展性,一个非常大的 topic 可以分布到多个 broker 上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
Replica :副本,同一分区的不同副本保存的是相同的消息,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
Leader :每个分区的多个副本中的"主副本",生产者以及消费者只与 Leader 交互。
Follower :每个分区的多个副本中的"从副本",负责实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,从 Follower 副本中重新选举新的 Leader 副本对外提供服务。
ACK机制/可靠性
request.required.acks 有三个值 0 1 -1
ack=0, 生产者发送消息后直接算写入成功,不需要等待响应。这个方案的问题很明显,只要服务端写消息时出现任何问题,都会导致消息丢失。
ack=1,默认为1。生产者发送消息,只要 leader 副本成功写入消息,就代表成功。这种方案的问题在于,当返回成功后,如果 leader 副本和 follower 副本还没有来得及同步,leader 就崩溃了,那么在选举后新的 leader 就没有这条消息,也就丢失了。
ack=-1 或 acks = all。生产者发送消息后,需要等待分区内所有副本都成功写入消息后才认为推送消息成功了。这样数据不会丢失,且毫无疑问这种方案的可靠性是最高的。
数据传输
数据传输的事务定义通常有以下三种级别:
(1)最多一次 at-most-once : 消息不会被重复发送,最多被传输一次,但也有可能一次不传输。
(2)最少一次 at-least-once: 消息不会被漏发送,最少被传输一次,但也有可能被重复传输。
(3)精确的一次(Exactly once): 不会漏传输也不会重复传输,每个消息都传输被一次而且仅仅被传输一次,这是大家所期望的。
读写分离
Kafka 是不支持读写分离的,对于 Kafka 的架构来说,读写分离有两个很大的缺点:
1.数据不一致的问题:读写分离必然涉及到数据的同步,只要是不同节点之间的数据同步,必然会有数据不一致的问题存在。数据从主节点转到从节点必然会有一个延时的时间窗口,这个时间 窗口会导致主从节点之间的数据不一致。某一时刻,在主节点和从节点中 A 数据的值都为 X, 之后将主节点中 A 的值修改为 Y,那么在这个变更通知到从节点之前,应用读取从节点中的 A 数据的值并不为最新的 Y,由此便产生了数据不一致的问题。
2.延时问题:类似 Redis 这种组件,数据从写入主节点到同步至从节点中的过程需要经历 网络→主节点内存→网络→从节点内存 这几个阶段,整个过程会耗费一定的时间。而在 Kafka 中,主从同步会比 Redis 更加耗时,它需要经历 网络→主节点内存→主节点磁盘→网络→从节点内存→从节点磁盘 这几个阶段。对延时敏感的应用而言,主写从读的功能并不太适用。
而Kafka的主写主读的优点就很多了:
-
可以简化代码的实现逻辑,减少出错的可能。
-
将负载粒度细化均摊,与主写从读相比,不仅负载效能更好,而且对用户可控。
-
没有延时的影响。
-
在副本稳定的情况下,不会出现数据不一致的情况。
负载均衡
Kafka 的负责均衡主要是通过分区来实现的,我们知道 Kafka 是主写主读的架构。
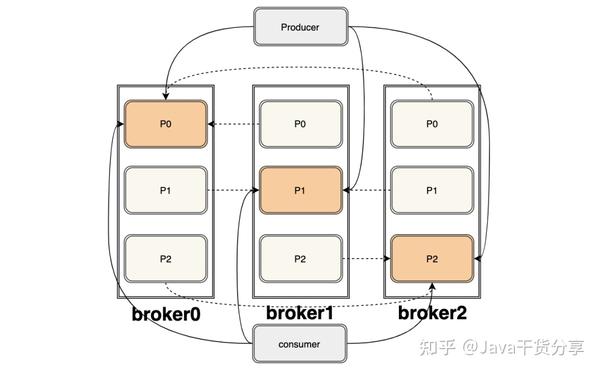
图中共三个 broker,里面各有三个副本,总共有三个partation, 深色的是leader,浅色的是follower,上下灰色分别代表生产者和消费者,虚线代表follower从leader拉取消息。
我们从这张图就可以很明显的看出来,每个 broker 都有消费者拉取消息,每个 broker 也都有生产者发送消息,每个 broker 上的读写负载都是一样的。
这也说明了 kafka 独特的架构方式可以通过主写主读来实现负载均衡。
Offset
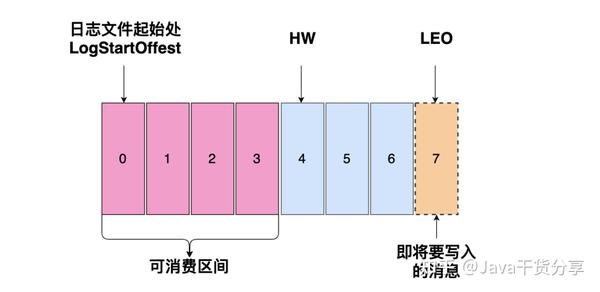
HW(High Watermark) 为4,0~3 代表这个日志文件可以消费的区间,消费者只能消费到这四条消息。
Zookeeper
Zookeeper是分布式协调,不是数据库。
kafka中使用了zookeeper的分布式锁和分布式配置及统一命名的分布式协调解决方案
kafka中broker中的状态数据也是存储在zk中,zk不是数据库,所以存储的属于元数据。
节点必须维护和 ZooKeeper 的连接,Zookeeper 通过心跳机制检查每个节点的连接。如果节点是个 follower,他必须能及时的同步 leader 的写操作,延时不能太久。
瓶颈
I/O
broker持久化数据 使用磁盘的顺序读写
Generally, disk throughput tends to be the main bottleneck in Kafka performance.
However, that’s not to say that the network is never a bottleneck. Network throughput can affect Kafka’s performance if you are sending messages across data centers.
参考
[1] https://zhuanlan.zhihu.com/p/399001842
[2] https://www.datadoghq.com/blog/monitoring-kafka-performance-metrics
[3] 互联网大厂面试都问的Kafka面试题,我悟了 - Java干货分享的文章 - 知乎
https://zhuanlan.zhihu.com/p/399001842

 浙公网安备 33010602011771号
浙公网安备 33010602011771号